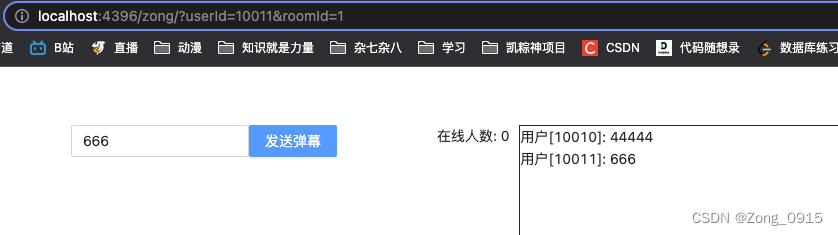
索引: 排好序的数据结构
从磁盘上拿一条记录要和磁盘做一次IO操作,,磁盘的IO性能不高
索引数据结构:
- 二叉树(binary search tree) : 单边增长的数据没有帮助
- 红黑树(red black tree) : 二叉平衡树,表记录很多时,树的高度过高
- b tree : 每个索引下面都有data,导致非叶子节点不能容纳更多的索引,,树的深度比 b+树高
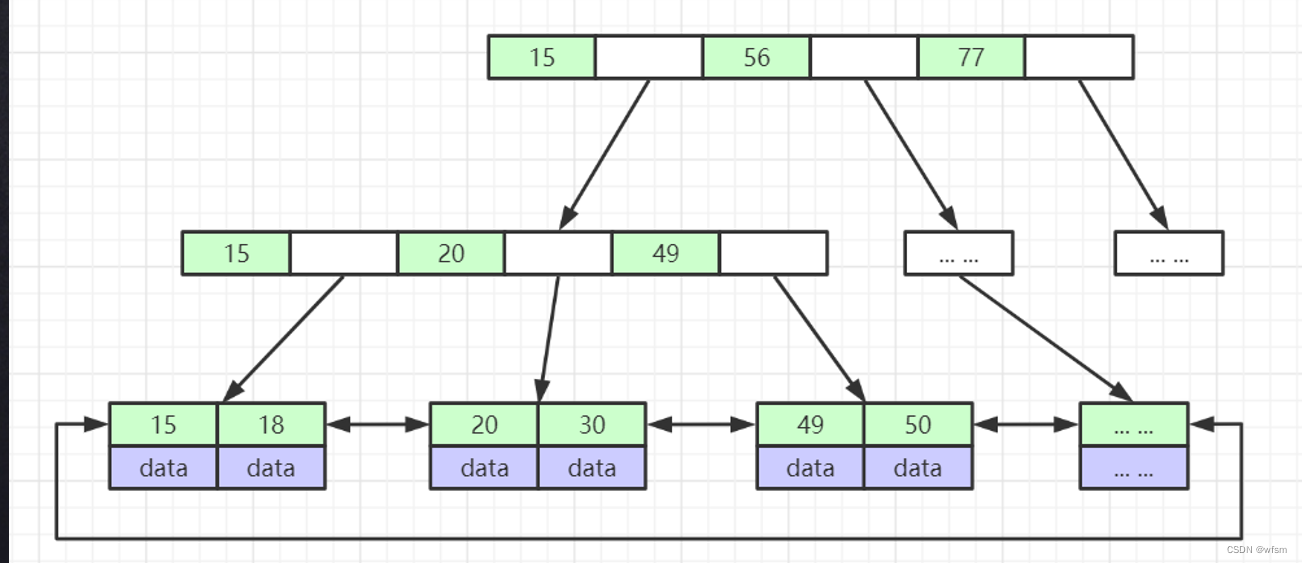
- b+ tree : 数据在叶子节点上,,非叶子节点都是索引,,每个节点存数据
16kb
为什么是16kb?- 假设一张表主键bigint 8字节索引,
- 存放一个元素 = 存放一个索引8字节+下一个节点的地址6字节 = 14字节
- 16kb/14b = 1170 ,一个节点大概能放1170个元素
- 最后一层叶子结点带数据data,假设一行记录大小为1kb,,一个叶子结点可以放16个元素
- 如果这个树有三层,,那么1170117016=两千多万数据,,树的高度为3
在mysql的高版本,,会将非叶子节点load到内存中
查找次数和树的高度紧密相关
b+树查找: 将根节点整个节点的元素,加载到内存中,然后折半查找,,定位下一个节点的磁盘位置,,然后下一个节点加载到内存中,继续比较
存储引擎
存储引擎是针对数据库表的
MyISAM引擎文件:
____.frm:frame ,, 数据表结构相关的信息___.MYD: MyISAM 的data___.MYI: MyISAM的index
___.MYI: 会将b+树组织好,从根节点开始遍历,,叶子结点的data放的是 索引所在行的磁盘文件地址,然后根据这个地址,再去___.MYD去定位具体的数据行
InnoDB文件:
___.frm: 表结构信息___.ibd: 所有数据,也是按照b+树来组织的,,,叶子节点存放的是索引所在行的其他列的数据
MyISAM的主键和非主键索引都是非聚集索引
InnoDB只有一个聚集索引,是主键,,,非主键索引存放的是聚集索引的索引值
为什么非主键索引不存data?
- 节约空间
- 数据一致性
名词
聚集索引 : 叶子节点包含整个完整的数据记录,,InnoDB的主键索引就是聚集索引,,或者说是聚簇索引
非聚集索引: MyISAM引擎的主键索引就是非聚集索引,,他的叶子结点,,只包含了data的地址,,没有数据,,,索引和数据分开存储的叫非聚集索引
联合索引: 多个字段共成一个索引,一张表不推荐你建立多个单值索引,两到三个联合索引搞定
索引下推: 5.6之后mysql引入的一个索引优化,,联合索引过滤,,每过滤一条数据,,比较剩下两个索引,,比较完了之后过滤掉数据,,这个过滤完的结果集非常小,然后去回表
文件排序:分为单路排序,双路排序
- 如果sort_buffer设置比较小,,使用双路排序,,,需要回表
- 如果sort_buffer设置比较大,可以单路排序,不用回表
问题
为什么InnoDB必须建一个主键?
__.ibd文件,这些数据必须用一个b+树来组织,如果你没有主键,,mysql会从你的这张表中选择一列数据都不相等的作为主键,,如果没有这样一个列,mysql会给你建一个隐藏列,,来组织你整个表的数据
为什么推荐整形自增作为主键?
- 整形比大小 和 字符串比大小,,整形比大小更快
- 整形比字符串大小 小很多,占用空间小,,一个节点上可以容纳更多的元素
- 因为是b+树,,从中间插入元素,会导致树的分裂和平衡,,自增会在末尾插入
为什么不用哈希索引?
mysql底层有自己的哈希算法
- 哈希冲突
- 哈希只能等值查询,不能范围查找,没有比大小的概念
为什么 大于 不用索引下推?
- 索引下推,当你查完第一个还要比较后面的联合索引,,结果集比较小的情况下会使用,,大于是个范围不固定
sql优化
explain

explain中的列:
- partitions : 这张表是否用分区
- select_type :
- simple : sql语句比较简单,没有子查询,关联查询
- derived : 衍生的,在
from之后的查询生成出来的临时表,叫衍生表 - subquery: 在
select后面查出来的表 - primary : 复杂查询,他的查询要关联其他好几个查询
- table :数据从哪里来的,比如:derived3(衍生表id为3)
- id : 执行顺序,id越大,,优先执行,id出现相等,谁排在前面,谁先执行
- type : sql的访问类型
type为null,执行的sql不一定会查表和数据,比如数据有序排列,就能直接找到min()最小值,不会去扫描表,,在索引优化的时候就拿到结果- system : 从一张表查询,查的那张表本身就只有一条记录
- const : sql查询条件是主键,是唯一索引,查找就像找一个常量一样
- eq_ref : 当前表用主键关联(唯一键),仅次于const
- ref : 你这个查询条件没有用唯一键(主键)去查,,但是还是会用到索引,但不是唯一索引,是普通索引,有可能查出多条结果集,,也有可能是唯一索引的部分前缀
- range : 范围查找
- index : 扫描全索引拿到结果集,,这个索引是指二级索引
- all : 扫描全部索引拿到结果集,,这个索引是指 聚簇索引
- possible_key : 可能会用到的索引
- key : 真正执行的时候用的索引
- key_len : 可以知道用了哪几个索引
- 如果是utf-8,一个数字或者一个字母占一个字节,一个汉字三个字节char(n)就是3n字节,,varchar(n):就是3n+2字节,,加的2字节是用来存储字符串的长度,因为varchar是可变字符
- tinyint:1字节,,smallint:2字节,,,int:4字节,bigint:8字节
- date:3字节,datetime:8字节,timestamp:4字节
索引最大长度是768字节,当字符串过长时,,mysql会将前半部分字符提取出来做索引
- ref: 这个索引关联查询的那个字段
- extra :
- using index: 使用覆盖索引,你查询的字段在索引树中全部包含了,不用回表
- using where : 使用了where,并且没有用到索引
- using index condition : 查询的列不完全被索引覆盖,,比如:联合索引只使用了其中一个并且这一个使用了范围查找索引失效
- using temporary: 使用临时表,效率不高,,比如:distinct去重,,如果查找的字段没有索引,,就会把所有结果弄到临时表中,在临时表去重,,如果有索引,就可以直接将数据取出来,,因为索引是排好序的,去重操作,可以用索引去重
- using filesort : 在排序的时候,,如果order by 后的字段没有索引,就会将结果集放在内存中,如果数据量大放磁盘,,再排序,,如果order by后的字段有索引,使用索引排序
查询的结果集在 主键索引 和 二级索引 都有,会优先扫描小的索引,,type为index,或者all,,相当于 叶子结点从左往右一直去扫,,遍历整个索引
cost成本计算:
trace工具 : 分析执行计划为什么这么走
数据量太少了,没必要走索引,还需要回表,不如全表扫描
like: 不管表大,还是表小,都会走索引
in 或者 or : 表大走索引,,表小,不走
mysql维护自己的总行数:
对于MyISAM 引擎来说,总行数会被存储到磁盘上
对于InnoDB来说,,count需要实时计算
解决:
show table status查出rows大概条数- 写到redis里面
- 整个数据库表来记录它有多少条
mysql优化
- 不要在索引列上做任何操作(计算,函数,手动或者自动类型转换),会导致索引失效
- or有很多的话,会导致 索引树要扫很多次,,还不如全表扫描
- 一个大范围查找,数据量太多了,还不如全表扫描快一些
- 解决: 拆分成多个小范围
- 尽量使用覆盖索引,,减少select * 语句
- mysql在使用不等于(!= 或者 <>) ,not in ,not exists 的时候无法使用索引
- is null ,is not null 一般情况下不能使用索引
- like 通配符开头,索引失效
- 关联字段加索引,,让mysql做join操作的时候尽量选择NLJ算法(嵌套循环连接)
- 小表驱动大表,写多表连接sql是明确知道哪张表是小表可以使用
straight_join连接,省去mysql优化器自己判断的时间
# t2 是小表: `过滤`完成之后,参与join的总数据量最小的那个表
select * from t2 straight_join t1 on t2.a = t1.a
- in 是先执行里面,里面是小表,exists先执行外面,外面是小表
- exists往往用join代替
- 如果整型数据没有负数,如ID,建议指定为UNSIGNED无符号类型,容量扩大一倍
- 建议使用tinyint 代替 enum,bitenum,set
- 避免使用整数的显示宽度,,也就是说int(10),直接用int
- decimal最适合保存准确度要求高,而且用于计算的数据
- 整数通常是最佳数据类型,因为速度快,并且能auto_increment
- 关联的那张大的表,一定要走索引,被驱动的表必须走索引
- join表最多不超过3张
- count(字段) 会将那个字段拿到内存,最后统计内存有多少个。。count()不会将
*读取到内存中,,,count()会计算null值,,count(列名)不会计算null - 单表超过500w,超过2GB,分库分表
- 严禁左模糊,和全模糊,,走搜索引擎
- in 能避免就避免,,in里面的数据不能太多,,控制在1000以内
- 禁止使用存储引擎
- 使用编码utf-8,如果存储表情,使用utf8m64,笑脸表情–》4个字节
怎么设计索引:
- 代码先行,索引后上
- 联合索引,尽量覆盖你要查询的sql语句,尽量建联合索引,,唯一索引可以建,规避字段重复,,考虑 where,order by,group by 是否最左前缀
- 不要在小基数上建立索引,没有意义,,做一个distinct的结果很小,如sex
- 几百个字符建索引varchar(255),对于这种比较长的字段,可以建一个前缀索引
key index(name(20),age,position),这样之后order by,group by 不能使用,,,大部分情况下前面20个字符的区分度已经很高了 - 慢sql,,mysql默认慢sql为10s,,会将sql写在文件里,自己分析,是否走索引
set global long_query_time=4修改慢sql时间,开启mysql慢查询会影响性能 - 范围查找之后不会走索引,,尽量建在最后面
- 对于基数比较小的,,又是索引,,又要使后面的索引生效可以使用
sex in (所有可能)使用in,,in在大数据量下走索引 - 如果有多个范围,都需要被索引,,可以将其中一个返回变成一个确定的值,,比如 查找最近7天的用户 变成
是否活跃,,添加索引,,再搞一个定时任务,去刷新这个是否活跃 字段 - 如果有特殊需求,可以新建其他的联合索引
- 尽量通过1-2个复杂的多字段联合索引,将80%的场景覆盖掉,然后用1-2个辅助索引尽量抗下剩余的20%
数据类型的选择:
小数用decimal,定长char ,不定长varchar
datetime : 8字节 范围1000-9999
timestamp : 4字节 范围 1970-2038 : 小公司用timestamp
阿里要求一张表必须具备三个字段 id,create_time,modify_time
char(n) : 存数据的时候,会在后台,用空格补充,,查询的时候又将空格去掉,不影响查询
varchar(n) : 最大列长度
能确定长度的就用char。
想blob和 text, 占用空间比较大的,推荐单独存入一个表,,用主键关联
优化场景
分页
select * from employees limit 10000,10
表示从employees表中读取10010条记录,,然后抛弃前面10000条,然后读到后面10条,如果查询一张大表比较靠后的数据,执行效率非常低
select * from employees order by name limit 90000,5
虽然走了name索引,但还是会全表扫描,不用回表
优化:
select * from employees e inner join (select id,name from emplyees order by name limit 90000,5) ed on e.id=ed.id
将全表扫描变成了 全表扫二级索引,,扫出来的数据很小,然后在和 employees表关联,,关联用的索引,也很快
mysql表关联常见的两种算法
嵌套循环连接算法 Nested_Loop Join(NLJ)
读取驱动表,每一次读取一行,,然后根据相关联的字段去另一张表(被驱动表)中取出满足条件的行
使用了NLJ算法,,一般join语句中,如果执行计划Extra中未出现using join buffer则表示join算法是 NLJ
如果被驱动表的关联字段没有索引,,使用NLJ算法性能会比较低
基于块的嵌套循环连接算法Block Nested_Loop Join (BNL)
把驱动表读取到 join_buffer 中,,被驱动表的每一行和驱动表中所有数据依次做对比,
如果驱动表很大的话,join_buffer_size 默认256k,,放不下驱动表数据的话,就会分段放,,然后执行完第一个块的记录之后,清空join_buffer,将剩余的驱动表数据加载进去,,继续比较
为什么要选择BNL而不用NLJ
NLJ是磁盘扫描
BNL磁盘扫描次数很少,,相比于磁盘扫描,BNL内存计算会快很多
总结
- b+树叶子节点有双向指针,叶子节点从左到右排好序,,,如果范围查找的数据量很大,会很慢