经典排序算法总结与实现
经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,这次收集整理并用Python实现了八大经典排序算法,包括冒泡排序,插入排序,选择排序,希尔排序,归并排序,快速排序,堆排序以及基数排序。希望能帮助到有需要的同学。之所以用 Python 实现,主要是因为它更接近伪代码,能用更少的代码实现算法,更利于理解。
本篇博客所有排序实现均默认从小到大。
一、冒泡排序BubbleSort
介绍:
冒泡排序的原理非常简单,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
步骤:
- 比较相邻的元素,如果第一个比第二个大,就交换他们两个;
- 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较;
Python源代码(错误版本):
def bubble_sort(arry):
n = len(arry) #获得数组的长度
for i in range(n):
for j in range(i+1, n):
if arry[i] > arry[j] : #如果前者比后者大
arry[i],arry[j] = arry[j],arry[i] #则交换两者
return arry
注:上述代码是没有问题的,但是实现却不是冒泡排序,而是选择排序(原理见选择排序),注意冒泡排序的本质是“相邻元素”的顺序交换,而非每次完成一个最小数字的选定。
Python源代码(正确版本):
def bubble_sort(arry):
n = len(arry) #获得数组的长度
for i in range(n):
for j in range(1, n-i): # 每轮找到最大数值 或者用 for j in range(i+1, n)
if arry[j-1] > arry[j] : #如果前者比后者大
arry[j-1],arry[j] = arry[j], arry[j-1] #则交换两者
return arry
不过针对上述代码还有两种优化方案。
优化1:
某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了。用一个标记记录这个状态即可。
Python源代码:
def bubble_sort2(ary):
n = len(ary)
for i in range(n):
flag = True # 标记
for j in range(1, n - i):
if ary[j] < ary[j-1]:
ary[j], ary[j-1] = ary[j-1], ary[j]
flag = False
# 某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了
if flag:
break
return ary
优化2:
记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序,不用再排序了。因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。
def bubble_sort3(ary):
n = len(ary)
k = n #k为循环的范围,初始值n
for i in range(n):
flag = True
for j in range(1, k): #只遍历到最后交换的位置即可
if ary[j-1] > ary[j]:
ary[j-1], ary[j] = ary[j], ary[j-1]
k = j #记录最后交换的位置
flag = False
if flag:
break
return ary
注:上面for j in range(1,k),这句很有意思,虽然后面有if ary[j-1] > ary[j]则k = j,但是这个k不会直接就变动,不然试想,当j=1,0与1位置坐了交换之后,k=j=1,j这一步循环直接就挂掉了,事实上,k的改变是在下一轮i坐了改变之后才会真正起作用,所以j可以记录最后交换位置。
二、选择排序SelectionSort
介绍:
选择排序是另一个很容易理解和实现的简单排序算法。学习它之前首先要知道它的两个很鲜明的特点。
- 运行时间和输入无关
为了找出最小的元素而扫描一遍数组并不能为下一遍扫描提供任何实质性帮助的信息。因此使用这种排序的我们会惊讶的发现,一个已经有序的数组或者数组内元素全部相等的数组和一个元素随机排列的数组所用的排序时间竟然一样长!而其他算法会更善于利用输入的初始状态,选择排序则不然。 - 数据移动是最少的
选择排序的交换次数和数组大小关系是线性关系,选择排序无疑是最简单直观的排序。看下面的原理时可以很容易明白这一点。
步骤:
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置;
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾;
- 以此类推,直到所有元素均排序完毕。
源代码:(python实现)
def select_sort(ary):
n = len(ary)
for i in range(0,n):
min = i #最小元素下标标记
for j in range(i+1,n):
if ary[j] < ary[min] :
min = j #找到最小值的下标
ary[min],ary[i] = ary[i],ary[min] #交换两者
return ary
三、插入排序 InsertionSort
介绍:
插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果被扫描的元素(已排序)大于新元素,将该元素后移一位;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5
排序演示
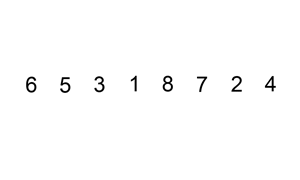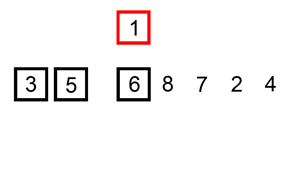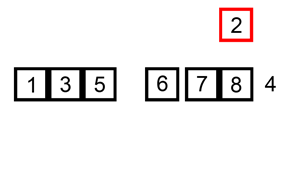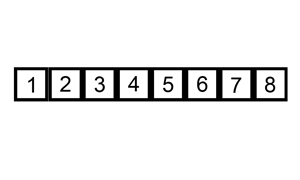
源代码:(python实现)
def insert_sort(ary):
count = len(ary)
for i in range(1, count):
key = i - 1
mark = ary[i] # 注: 必须将ary[i]赋值为mark,不能直接用ary[i]
while key >= 0 and ary[key] > mark:
ary[key+1] = ary[key]
key -= 1
ary[key+1] = mark
return ary
四、快速排序 QuickSort
介绍:
快速排序通常明显比同为Ο(n log n)的其他算法更快,因此常被采用,而且快排采用了分治法的思想,所以在很多笔试面试中能经常看到快排的影子。可见掌握快排的重要性。
步骤:
- 从数列中挑出一个元素作为基准数;
- 分区过程,将比基准数大的放到右边,小于或等于它的数都放到左边;
- 再对左右区间递归执行第二步,直至各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j–;
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结:
- i =L; j = R; 将基准数挖出形成第一个坑a[i];
- j–由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中;
- i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中;
- 再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码.
排序演示
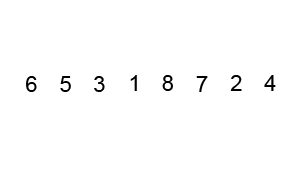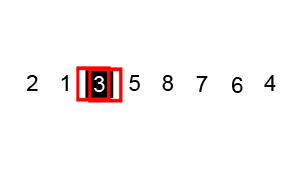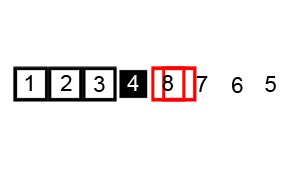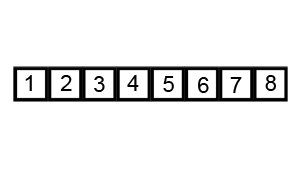
源代码:(python实现)
def quick_sort(ary):
return qsort(ary, 0, len(ary) - 1)
def qsort(ary, start, end):
if start < end:
left = start
right = end
key = ary[start]
else:
return ary
while left < right:
while left < right and ary[right] >= key:
right -= 1
if left < right: # 说明打破while循环的原因是ary[right] <= key
ary[left] = ary[right]
left += 1
while left < right and ary[left] < key:
left += 1
if left < right: # 说明打破while循环的原因是ary[left] >= key
ary[right] = ary[left]
right -= 1
ary[left] = key # 此时,left=right,用key来填坑
qsort(ary, start, left - 1)
qsort(ary, left + 1, end)
return ary
另外一种实现方法
先从待排序的数组中找出一个数作为基准数(取第一个数即可),然后将原来的数组划分成两部分:小于基准数的左子数组和大于等于基准数的右子数组。然后对这两个子数组再递归重复上述过程,直到两个子数组的所有数都分别有序。最后返回“左子数组” + “基准数” + “右子数组”,即是最终排序好的数组。
源代码:(python实现)
实现快排
def quicksort(nums):
if len(nums) <= 1:
return nums
# 左子数组
less = []
# 右子数组
greater = []
# 基准数
base = nums.pop()
# 对原数组进行划分
for x in nums:
if x < base:
less.append(x)
else:
greater.append(x)
# 递归调用
return quicksort(less) + [base] + quicksort(greater)






![[附源码]Python计算机毕业设计SSM基于JAVA快递配送平台(程序+LW)](https://img-blog.csdnimg.cn/2e439d2a12594fc8848e29a3aa357956.png)


![[附源码]Node.js计算机毕业设计高校学生心理健康信息咨询系统Express](https://img-blog.csdnimg.cn/339c36075c39412e8997c2f6ca53e235.png)