目录
1. Redis安装
1.1 单机
1.2 主从
1.3 哨兵
1.4 集群
1.4.1 方式一 redis-cli --cluster命令
1.4.2 方式二 cluster meet/addslots/replicate
2. Redis配置
2.1 基本参数配置
2.2 持久化配置
2.3 内存策略设置
2.4 主从配置
2.5 哨兵配置
2.6 集群配置
2.6.1 集群特有命令
3. Redis数据结构
4. Redis原理
4.1 主从复制
4.2 哨兵
4.2.1 运行流程
4.2.2 Java客户端处理
4.2.3 Redis源码跟踪
4.3 集群
4.3.1 数据分片 / 槽位概念
4.3.2 redis-cli -c 集群模式连接
4.3.3 Java客户端源码
4.3.4 集群模式高可用及故障转移
4.4 哨兵和集群优劣
5. 问题排查
5.1 No way to dispatch this command to Redis Cluster because keys have different slots
5.2 Jedis does not support password protected Redis Cluster configurations!
5.3 项目生产环境aof文件过大(145G)
6. 其他
6.1 集群模式扩容/数据迁移
1. Redis安装
1.1 单机
Index of /releases/
下载redis-6.2.7.tar
上传到linux,进入上传路径
解压文件,指定解压到home路径:tar –zxvf redis-6.2.7.tar –C /home/redis-single
安装gcc, 如果已经安装则忽略,yum –y install gcc
进入解压路径,输入make编译
make成功后输入make install
安装成功,redis-cli和redis-server执行文件在安装目录/src/,此时/usr/local/bin/下也会有redis-server等执行文件,在任意地方输入redis-server即可运行redis,如果不需要这样,删除/usr/local/bin/下redis的相关文件
1.2 主从
为方便,同一台机器安装一主一从
创建另外两个文件夹master和slave,将单机安装好的文件夹,整体复制
cp -RT /home/redis-single/redis-6.2.7/ /home/redis-master1-slave1/master/
cp -RT /home/redis-single/redis-6.2.7/ /home/redis-master1-slave1/slave/
1、进入slave文件夹, vim redis.conf
2、修改端口号配置port 6380(自己定,但需要和master不一样)
3、增加配置 salveof/replicaof <masterip> <masterport> ,例如我的就是 salveof 192.168.146.105 6379
4、如果master中设置了密码requirepass,从配置需要加上 masterauth master密码,例如我的master设置了密码123456,需要再增加一行 masterauth 123456
5、./redis-server redis.conf先后启动主从服务,连接主从进行验证同步效果,从服务只读
注:除了在配置文件配置replicaof之外,还可以启动这两个redis服务,在其中一台上执行salveof <masterip> <masterport> 命令,也可以实现主从复制
例如客户端连接6380从服务 , 执行命令 slaveof no one, 再客户端连接6379 执行命令slaveof 192.168.146.105 6380,即可实现主从服务器的角色互换
1.3 哨兵
在主从中,master异常退出后,slave会报错如下,直到master重启后,主从复制才会恢复正常,这个阶段中redis服务只读

哨兵模式则就是为了master异常时进行master和slave的自动切换,将slave升级为master,保证redis服务的可用
基于上边1.2的一主一从配置
master核心配置
port 6379
requirepass 123456
masterauth 123456 #因为主从会切换,所以master中也需要配置这个参数
slave核心配置
port:6380
requirepass 123456
replicaof 192.168.146.105 6379 #表示自己是master105:6379的从节点
masterauth 123456
因为sentinel本身也是一个redis节点,这里为了方便,进入上边两个其中一个安装目录修改哨兵配置文件中的下边两个参数 vim sentinel.conf,
1:sentinel monitor mymaster 192.168.146.105 6379 1
配置需要sentinel监听的master名字和地址,因为一个sentinel可以监听多个master集群
最后的1表示有多少sentinel认为master已下线,就开始主从切换,因为这里只有一个哨兵节点,所以配置1
2:sentinel auth-pass mymaster 123456
如果master和slave配置了密码,那么哨兵上也得配置master的密码
最后启动哨兵节点 ./redis-server sentinel.conf --sentinel

测试主从切换:
1、将6379的master 进程干掉
2、等待一小会观察sentinel控制台,输出如下

3、将6380的slave切换为master,继续对外服务
4、重启6379,6379将作为slave运行
查看6379和6380的配置文件,发现配置已经被sentinel修改,原6379的配置中增加了replicaof 192.168.146.105 6380,
6380的配置中删除了replicaof参数,sentinel.conf中master地址也已修改
1.4 集群
我单独创建一个文件夹mkdir /home/redis-cluster; cd /home/redis-cluster
将上边单机环境安装好的redis文件复制过来 cp -RT ../redis-single/redis-6.2.7/ ./
因为是一台机器搭建集群,所以得改改配置文件使得每个服务的端口日志文件啥的区别开
1、创建如下文件

2、对每个配置文件根据端口号不同添加或修改如下参数,如果是正常环境,6台机器的话,那么只需要开启cluster模式即可

3、启动所有服务,为了方便快捷,编写shell文件来一键启动
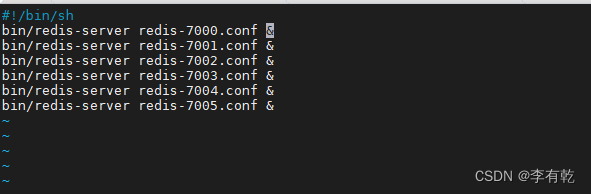
1.4.1 方式一 redis-cli --cluster命令
启动所有节点之后,执行cluster初始化命令
#redis-cli(进入客户端) --cluster(开始集群操作) create(创建集群) --cluster-replicas 1(每一台主机后跟几个从机,这里写1是一主一从)
redis-cli --cluster create --cluster-replicas 1 192.168.146.105:7000 192.168.146.105:7001 192.168.146.105:7002 192.168.146.105:7003 192.168.146.105:7004 192.168.146.105:7005
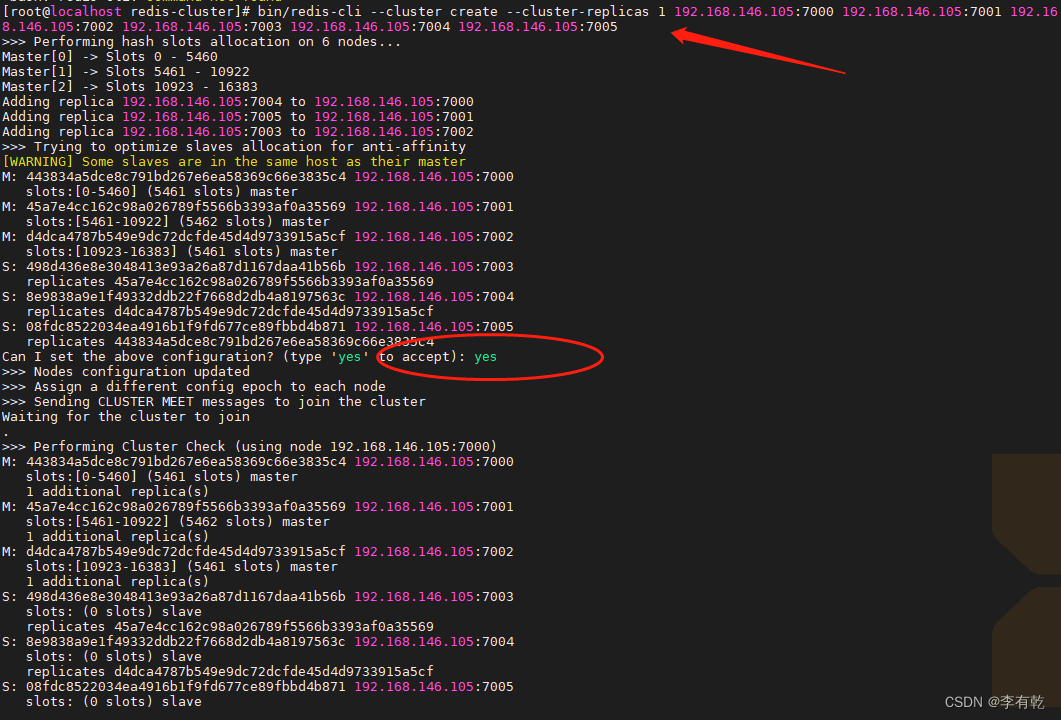
此时集群环境就已经搭建好了
自动产生的配置文件中配置了当前集群中各个节点的信息 vim nodes-7000.conf

测试集群写入
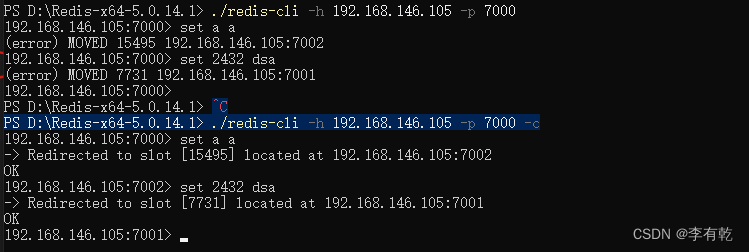
测试集群主从切换
7000为主,7005为从

kill掉7000的进程之后,稍等一会会发现,7005晋升为了主

7000重新上线后,变为从

将7000和7005服务都杀掉,再执行查询写入会返回 cluster已经宕机错误

注:
redis-cli中自动创建集群的步骤如下(源码位置:redis-cli.c --> clusterManagerCommandCreate):
-
根据我们提供的地址以及replicas参数,计算master数量 = 总节点数目/ replicas参数 + 1,master数量必须大于等于3
-
根据master数量取出前几个地址,为master平均分配16384个槽,16384 / master_count
-
将剩下的slave节点分配给每个master
-
打印出各节点槽位信息和主从关系,can i set above configration?
-
循环所有节点,向各节点发送初始化命令,1)cluster replicate 将slave和master建立主从关系 2)cluster addslots 为master指派slots 3) cluster meet 使各节点互相发现
1.4.2 方式二 cluster meet/addslots/replicate
方式一执行的初始化操作
redis-cli(进入客户端) --cluster(开始集群操作) create(创建集群) --cluster-replicas replicas ip:port ip:port ......
其实内部也是利用replicate/meet/addslots这三个命令为我们自动进行的集群初始化,我们其实也可以用这三个命令来自定义集群,但比较麻烦不推荐
启动6个节点之后,先查看集群信息,此时每个节点都是独立的集群,且是下线状态

连接其中一个节点,执行meet命令使得其他节点加入当前集群

集群中已经有三主了,再给每个主节点添加从节点
先meet三个从节点,再依次连接从节点执行cluster replicate <master-node-id> 命令建立主从关系

至此三主三从集群关系建立完成,但是集群目前还是下线状态,因为还未给master节点分配槽位
cluster addslots 0 1 2 3 4 表示将0-4的槽位分给当前节点,因为addslots命令不支持区间输入,所以编写shell脚本来批量添加槽位

表示将3--3000的槽位分配给7000端口的master,依次连接其他master节点,将16384个槽位分配完毕

分配完之后,查看节点和集群信息,发现集群已经可用

2. Redis配置
2.1 基本参数配置
1、daemonize no
默认不能以守护线程启动,yes启用守护线程
参数为no时命令行启动后ctrl+c,redis进程即会退出
如果需要后台启动,如下两种方式:
1)./redis-server redis.conf &
2)将daemonize参数改为yes, ./redis-server redis.conf
2、port 6379
当前服务对外端口
3、bind 127.0.0.1
绑定的本机网卡ip,默认只能本地访问
改为0.0.0.0 或对应网卡ip,才能从别的ip访问此redis服务
4、protected-mode yes
默认开启保护模式, 关闭 no
如果开启保护模式,并且没有自己设置bind参数和设置redis密码,那么只能从127.0.0.1访问redis服务
如果设置了bind或者设置了密码,则这个参数无效
保护模式下,其他ip连接报错如下图:

5、requirepass 123456
设置redis访问密码
6、timeout 0
空闲连接超时时间,Redis多长时间主动清理空闲的客户端连接。默认0表示不断开
7、tcp-keepalive 300
redis探活时间间隔,每隔300s向客户端发送tcp包探活
8、loglevel notice
redis日志级别,四个级别供选择, 依次是debug<verbose<notice<warning,默认notice
9、logfile ""
redis日志文件位置
10、database 16
redis提供的类似多租户概念,一个redis实例默认有16个数据库,默认使用0数据库,每个数据库占用不同的内存空间互不影响。 所以一个redis可以提供给多个不同应用程序使用,每个应用程序连接不同的数据库
命令行通过select 来切换数据库,例如select 1, select 15
11、maxclients 10000
最大允许的客户端连接数
12、dir ./
redis各种文件的保存地址,包括rdb,aof,cluster的配置文件
2.2 持久化配置
1、RDB持久化配置
save <seconds> <changes>
例如 save 900 1 表示 900秒内有至少一次修改即触发rdb持久化
save 60 10000 表示60秒内有至少10000次修改后即触发rdb持久化
若不需要rdb持久化,可以删除所有save配置项
dbfilename dump.rdb rdb文件名
stop-writes-on-bgsave-error yes 默认yes情况下,rdb保存失败则redis拒绝写入,直到rdb恢复正常
手动持久化命令:
save:同步,在主线程中执行,会导致阻塞;
bgsave:异步,创建一个子进程,专门用于写入 RDB 文件,是 Redis RDB 文件生成的默认配置。
2、AOF持久化配置
appendonly yes 默认no不启用aof持久化,启用aof之后,redis重启优先使用aof进行数据恢复
appendfilename "appendonly.aof" aof文件名
appendfsync everysec 控制命令保存到缓冲区后采用何种方式进行刷盘,分为三种模式,如下
no 不强制操作系统刷盘,由操作系统在合适的时候刷入磁盘
always 每次有数据写入缓冲区,则强制刷盘
everysec 每秒,默认策略
aof文件较大,所以redis会在某些时候对aof文件进行重写rewrite,来压缩文件大小。
auto-aof-rewrite-percentage 100 默认aof文件大小增长为上次rewrite两倍(100%)时,进行rewrite
auto-aof-rewrite-min-size 64mb 64M以下不进行rewrite
aof-use-rdb-preamble yes 开启rdb和aof混合持久化
RDB 和 AOF 持久化各有利弊,RDB 可能会导致一定时间内的数据丢失,而 AOF 由于文件较大则会影响 Redis 的启动速度,为了能同时使用 RDB 和 AOF 各种的优点,Redis 4.0 之后新增了混合持久化的方式。
在开启混合持久化的情况下,AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾。
2.3 内存策略设置
1、maxmemory <bytes> 设置redis最大内存,单位字节
2、maxmemory-policy noeviction 当redis达到内存最大值后,进行淘汰key的策略,如下几种
volatile-lru 从设置了超时时间的key中使用近似LRU算法
allkeys-lru 从所有key中使用近似LRU算法
volatile-lfu 从设置了超时时间的key中使用近似LFU算法
allkeys-lfu 从所有key中使用近似LFU算法
volatile-random 从设置了超时时间的key中随机删除
allkeys-random 从所有key中随即删除.
volatile-ttl 从设置了超时时间的key中,优先删除ttl小的
noeviction 不淘汰key,返回客户端报错
3、maxmemory-samples 5 LRU和LFU的样本数,默认5
Redis的LRU和LFU算法都是近似算法,因为记录每个键的使用次数和时间,然后全部比较进行选择性能消耗太大,redis采用的是每次随机选取默认5个样本key,在5个key中根据相应淘汰策略删除最老或最少使用的键,并将剩余key放入淘汰池,在后续淘汰时将随机选出的样本key与淘汰池结合比较,删除最老或最少使用的键,将较老的键重新放入淘汰池等待下一轮循环。以此来达到近似LRU/LFU的效果。
4、replica-ignore-maxmemory yes 启用主从复制之后,从服务器将忽略内存淘汰相关配置,所有key的淘汰由主服务器将DEL命令同步到从服务器
2.4 主从配置
1、replicaof <masterip> <masterport> / slaveof <masterip> <masterport>
在slave配置文件上设置master的ip + 端口,例如 replicaof 192.168.146.105 6379,或者slaveof 同样效果
附:在slave上执行slaveof no one 或者replicaof no one 即可切换slave转为master模式运行,同样执行slaveof 192.168.146.105 6379 或 replicaof 192.168.146.105 6379 转为slave运行
2、masterauth <master-password> 在slave上设置master的访问密码,例如masterauth 123456
3、replica-serve-stale-data yes 默认yes,当从节点和主节点的连接断开或者复制正在进行中,如果设置为yes,那么继续提供查询服务,如果设置为no,那么返回报错

4、replica-priority 如果master宕机,sentinel哨兵模式进行主从切换时,需要挑选一个slave晋升,这个参数表示该salve的优先级,越小越优先选择,为0表示该节点永不晋升,默认都是100
5、client-output-buffer-limit replica 缓冲区保护机制,主从复制期间,master可以继续接收写请求,增量新数据写在缓冲区内等待slave加载rdb文件完成之后,再发送给slave,如果缓冲区溢出,master会立即断开此次复制连接,默认配置如下,表示某个复制缓冲区大小超过256M或者持续60秒占用超过64M内存 立即断开连接
client-output-buffer-limit replica 256mb 64mb 60
2.5 哨兵配置
1、sentinel monitor <master-name> <ip> <redis-port> <quorum>
配置需要sentinel监听的master名字和地址,因为一个sentinel可以监听多个master集群
quorum表示有多少sentinel认为master已下线,就开始主从切换
示例:三个节点的sentinel集群,需要至少2个sentinel认为master下线才能进行切换,
sentinel monitor mymaster 127.0.0.1 6379 2
2、sentinel auth-pass <master-name> <password>
配置master对应的密码
3、sentinel down-after-milliseconds mymaster 30000
主观下线超时时间,当master连续多长时间没有向sentinel正常回复,就认为master已经下线,默认30s,值越大,对主观下线的判定会越宽松,好处是误判的可能性小,坏处是故障发现和故障转移的时间变长,客户端等待的时间也会变长,例如,如果应用对可用性要求较高,则可以将值适当调小,当故障发生时尽快完成转移;如果网络环境相对较差,可以适当提高该阈值,避免频繁误判
4、sentinel parallel-syncs mymaster 1
sentinel parallel-syncs与故障转移之后从节点的复制有关:它规定了每次向新的主节点发起复制操作的从节点个数。例如,假设主节点切换完成之后,有3个从节点要向新的主节点发起复制;如果parallel-syncs=1,则从节点会一个一个开始复制;如果parallel-syncs=3,则3个从节点会一起开始复制。
parallel-syncs取值越大,从节点完成复制的时间越快,但是对主节点的网络负载、硬盘负载造成的压力也越大;应根据实际情况设置。例如,如果主节点的负载较低,而从节点对服务可用的要求较高,可以适量增加parallel-syncs取值。parallel-syncs的默认值是1。
2.6 集群配置
1、cluster-enabled yes
开启cluster模式,默认为no
2、cluster-config-file nodes-7000.conf
cluster对于每个节点的配置文件名,不需要我们修改和创建,内容是当前cluser各个节点的地址、runid、主从关系等
3、cluster-node-timeout 15000
判断一个cluster节点下线超时的时间
4、cluster-require-full-coverage yes
当集群中某个master宕机且没有slave可以切换,会导致一部分的slot不可用,配置为yes的话会导致集群宕机,对外不可用,
如果配置为no,那么除了这一部分slot不可用,其他slot的redis节点还可以继续响应
5、cluster-allow-replica-migration yes
如果一个master没有任何可用的从节点,是否允许将其他master的从节点转移一个到该master下,例如三主六从的集群,每台master两台slave,masterA的两台slave先后挂掉,此时如果masterA也挂掉会导致集群宕机。
该参数如果配置为yes,会从其他master上分出一个slave来与masterA建立主从关系,如果配置为no,则不允许这样转移
6、cluster-migration-barrier 1
与上边参数cluster-allow-replica-migration配合使用,默认为1表示当masterA没有可用slave,masterB的slave需要转移给A时,必须保证masterB还有至少1个slave可用,不能因为保护A伤害了B
7、cluster-replica-no-failover no
如果配置为no,则从服务器会在主服务器宕机时自动切换,如果配置为yes,则不允许从机切换为主机
2.6.1 集群特有命令
cluster info :打印集群的信息

cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。

cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <master_node_id> :将当前节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
cluster addslots [slot …] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots [slot …] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
cluster keyslot :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot :返回 count 个 slot 槽中的键 。
3. Redis数据结构
。。。
4. Redis原理
4.1 主从复制
。。
4.2 哨兵
4.2.1 运行流程
哨兵配置:sentinel monitor <master-name> <ip> <redis-port> <quorum>
4.2.1.1 单哨兵
-
配置master地址,监控master状态(定时心跳),判断是否下线
-
获取该master集群下属slave地址等信息
-
检测到master下线,选择一个slave进行主从切换(故障转移)
-
通知客户端master地址已经改变

1、配置master地址,监控master状态(定时心跳),判断是否下线
通过配置中的master地址,sentinel节点与master节点建立连接,默认每秒向master节点发送一次PING命令。一旦master超过某个时间间隔没有正常回复则认为已经下线

2、获取该master集群下属slave地址等信息
默认每10秒发送一次INFO命令,获取到slave地址之后,与slave建立连接,也同样定时发送INFO和PING

3、检测到master下线,选择一个slave进行主从切换(故障转移)

故障转移第一步就是选择合适的slave来充当新master
-
从当前所有slave列表中先过滤掉已经下线、连接断开的、replica-priority参数为0的、近期没有回复过INFO和PING命令的、sentinel发现master下线之前很早就与master连接断开的
-
对剩下的排序,replica-priority参数小的优先,主从复制偏移量offset大的优先,比较runid
第二步向选出来的slave发送 slaveof on one
第三步向剩下的slave发送 slaveof 新ip 新port
第四步原master重新上线,sentinel会重新连接,向原master发送 slaveof 新ip 新port
4、通知客户端master地址已经改变
sentinel向+switch-master频道发送消息,客户端需要有专门的订阅监听处理逻辑
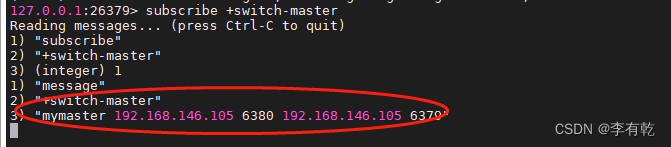
4.2.1.1 哨兵集群
哨兵也是一个redis节点,有单点问题,所以一般部署集群
另一方面原因,因为网络问题比如sentinel和master网络不通,master还在线,会导致sentinel误认为master下线开始主从切换,所以部署集群也为了减少对master下线的误判
但是集群部署也相应的带来一些问题

sentinel集群节点的互相发现
跟zookeeper直接在配置中写死集群节点的方式不同,sentinel集群较为灵活,每个sentinel节点初始情况下不知道其他sentinel节点信息,使用redis的发布订阅机制互相发现
sentinelA与master建立连接后,默认每2秒向master的 __sentinel__:hello 频道发布一条消息,消息内容有sentinelA节点的ip,port等,其他sentinel节点建立连接之后,订阅 __sentinel__:hello 这个频道消息,以此来发现其他监控节点并建立连接
消息内容如下图

sentinel集群如何判断master下线
一台sentinel节点发现master长时间没有正常回复,它需要向sentinel集群其他节点询问你怎么看?直到集群中一定数量的节点同样回复master下线(quorum参数,通常设置为半数+1),那么才认为master是真的下线,此时才会启动故障转移流程进行slave/master的切换
两个概念:
-
主观下线,该sentinel长时间未接收到节点的正常心跳回复,主观的认为这个节点已经下线
-
客观下线,只针对master节点,sentinel节点判断主观下线之后,会向其他sentinel节点发送命令(is-master-down-by-addr)询问该节点状态,quorum数量的节点(配置文件)都认为master已经下线,则是客观下线
is-master-down-by-addr命令请求参数
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> 
is-master-down-by-addr命令响应参数

示例如下

sentinel集群票选leader
故障转移流程一个sentinel节点就能完成,所以集群中会有一个选举leader的过程,由leader来主导本次故障转移
epoch:选举纪元,类似版本号、计数器,每次 选举流程不论成功失败都+1
每个发现master客观下线的sentinel节点,会发起选举流程
1)当前选举纪元epoch+1
2)向其他sentinel节点发送is-master-down-by-addr 命令, 带上自己的epoch,且此时命令最后一个参数runid不为 *,而是当前sentinel节点的runid,如下图,这表示当前sentinel节点请求当选leader,要对方把选票投给自己
 而对方节点是否投票的判断在同一个纪元epoch中遵循先到先得原则
而对方节点是否投票的判断在同一个纪元epoch中遵循先到先得原则
比如SentinelA和SentinelC同时发现master客观下线,A的is-master-down-by-addr命令率先发送给B节点,B节点将选票投给A之后,如果再接收到C的is-master-down-by-addr就会拒绝C的选票。
如果A或C接收到的投给自己的选票数量满足(大于等于 quorum && 大于等于 半数+1),则选举结束当选leader,主导后续的故障转移流程;如果选举耗时超过某个时间,则会再发起新一轮选举投票(epoch+1)
4.2.2 Java客户端处理
配置文件

创建连接池
org.springframework.data.redis.connection.jedis.JedisConnectionFactory#createPool


初始化连接池的时候,会先从sentinel中获取到master的ip + port ,然后初始化连接池

向sentinel发送get-master-addr-by-name 命令获取master地址,图略不重要
监听sentinel消息
redis.clients.jedis.JedisSentinelPool#initSentinels
启动监听sentinel线程

redis.clients.jedis.JedisSentinelPool.MasterListener#MasterListener(java.lang.String, java.lang.String, int)
订阅 +switch-master 消息,如果接收到,则重新初始化连接池

sentinel发布的消息内容如下,表示名称为mymaster的redis服务集群,master地址从146.105:6380改为146.105:6379

4.2.3 Redis源码跟踪
server.c --> initServer --> serverCron --> sentinel.c --> sentinelTimer --> sentinelHandleDictOfRedisInstances

4.2.3.1 sentinelHandleRedisInstance

4.2.3.2 sentinelSendPeriodicCommands
向节点发送INFO,PING,HELLO等命令
-
发送INFO命令,回调方法为sentinelInfoReplyCallback,根据返回的信息更新sentinel内部监听节点的数据结构,一般情况下10秒一次INFO,如果master被客观下线,那么每秒都会发送INFO命令来同步信息


sentinelInfoReplyCallback --> sentinelRefreshInstanceInfo
处理INFO命令返回信息,这个方法代码太长操作太多,只列举几点重要的操作
获取角色

获取master下属的slave信息

更新故障转移状态、将原master转为salve

2)发送PING命令探活,回调方法为sentinelPingReplyCallback,更新节点的最后可用时间

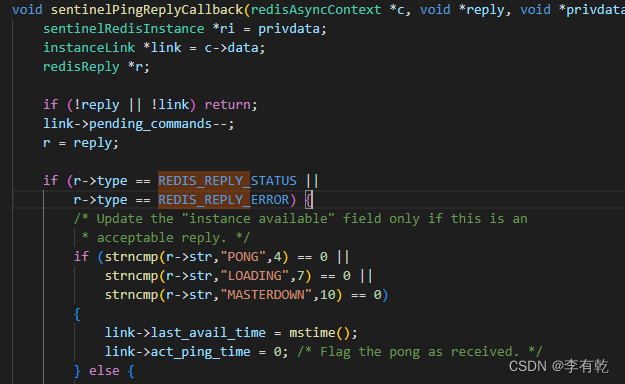
sentinelPingReplyCallback
更新last_avail_time字段,除了返回PONG, LOADING, MASTERDOWN这三种回复之外,其余回复都视为无效回复
3)发送HELLO消息,用于发现其他监听该master的sentinel节点

消息内容如下图,从前到后分别是
源Sentinel的IP地址、端口号、运行ID、配置纪元、源Sentinel正在监视的主服务器的名字、IP地址、端口号、配置纪元
其他sentinel根据订阅接受到的消息参数,发现其他sentinel节点,并对相应数据结构进行更新

4.2.3.3 sentinelCheckSubjectivelyDown
主观下线判断,判断距离上次响应PING命令的时间,大于配置中的参数down-after-milliseconds时间,设置为主观下线,默认30s

4.2.3.4 sentinelCheckObjectivelyDown
客观下线判断

4.2.3.5 sentinelAskMasterStateToOtherSentinels
向其他sentinel节点发送is-master-down-by-addr命令,一是来判断是否主观下线,二是在故障转移开始后向其他节点要选票


4.2.3.6 sentinelFailoverStateMachine
开始故障转移流程

sentinelFailoverWaitStart --> sentinelGetLeader 选举leader

sentinelFailoverSelectSlave --> sentinelSelectSlave 选择合适的salve作为新master


4.3 集群
4.3.1 数据分片 / 槽位概念
类似数据库分库分表,Redis集群也将缓存数据根据槽位分散到不同服务节点上,以此来提高系统稳定性和横向扩展能力,
将一个 Redis 集群分成 16384 个哈希槽(hash slot),集群中的每个节点在集群搭建时会被分配一部分的槽位,它就只负责处理这一部分哈希槽。
数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽,。
例如一个集群可以有三个节点, 其中:
节点 A 负责处理 0 号至 5000 号哈希槽。
节点 B 负责处理 5000 号至 10000 号哈希槽。
节点 C 负责处理 10000 号至 16383 号哈希槽。
节点B接受到客户端的get key1 命令,先计算key1的槽位,如果key1属于自己负责处理的槽,例如6000,那么执行get命令返回结果给客户端,如果不是则返回客户端MOVED错误,指引客户端连接正确的节点

4.3.2 redis-cli -c 集群模式连接
redis-cli连接redis集群,不加-c参数的话,在查询的key不属于该节点的时候,会报错如下图,MOVED后边跟的是该key所在的节点地址

而加上-c的话,查询同样的key,会提示如下,正常返回value

redis-cli.c --> issueCommandRepeat
原理代码就是while true循环,如果服务器返回正常则break,如果返回Moved错误,再次循环建立连接发送命令

cliSendCommand --> cliReadReply
解析服务端返回值,如果加了-c参数,且服务器返回MOVED,做如下操作
1、将cluster_reissue_command标志位改为1
2、用MOVED返回信息中的ip和端口,覆盖掉我们最开始的ip port
然后在最外层再次循环,重新向新ip端口发送命令

4.3.3 Java客户端源码

初始化槽位缓存
org.springframework.data.redis.connection.jedis.JedisConnectionFactory#afterPropertiesSet

redis.clients.jedis.BinaryJedisCluster#BinaryJedisCluster


redis.clients.jedis.JedisClusterConnectionHandler#initializeSlotsCache
连接所有cluster node,创建连接池以及获取对应的槽位范围进行缓存

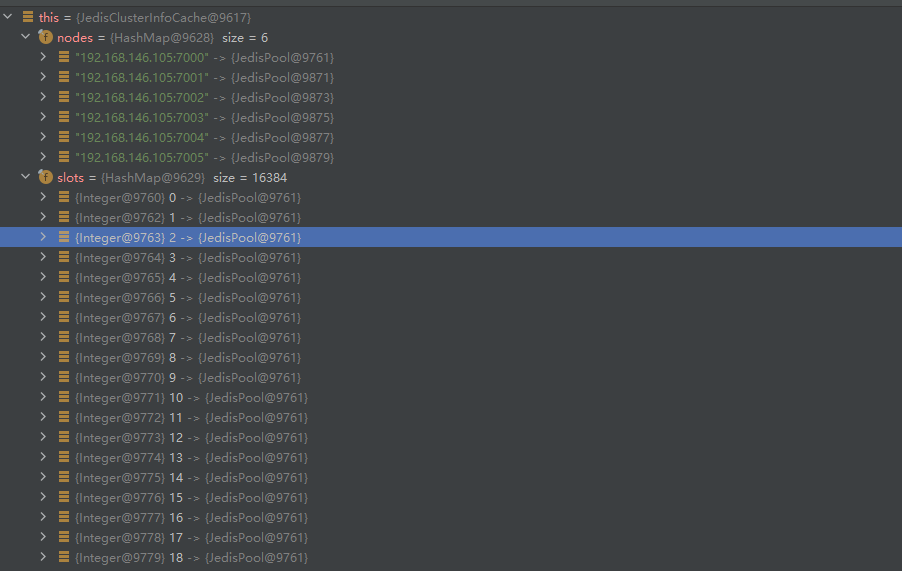
redis.clients.jedis.JedisClusterInfoCache#discoverClusterNodesAndSlots

cluster slots命令返回内容如下

缓存Map结构如下,key为槽位数字,value为具体master节点的连接池
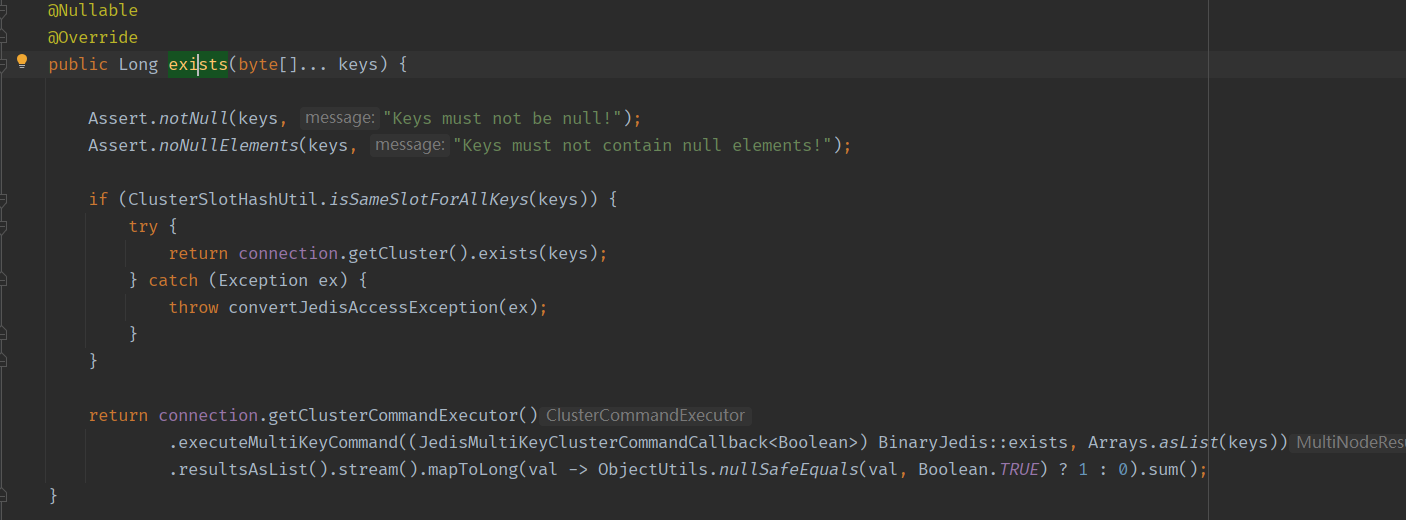
查询key,RedisTemplate#hasKey


org.springframework.data.redis.connection.jedis.JedisClusterKeyCommands#exists
如果经过槽位计算后所有key的slot都是一样的,那么从缓存中获取槽位对应的连接池发送命令(JedisClusterConnectionHandler-->JedisClusterInfoCache)
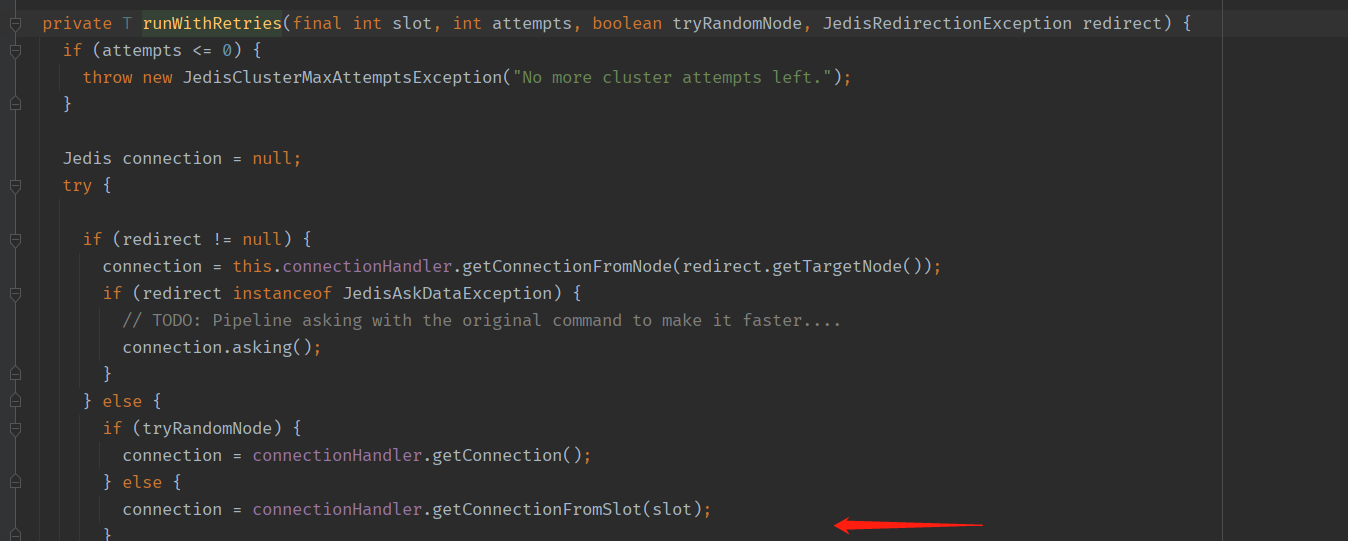
如果槽位不同,将各槽位的节点查询出来,向不同节点同时发送命令,Future等待所有节点回复之后返回结果

注:如果是lua脚本有多key问题,那么上边这种方式也无法处理,会报错。可以用大括号将lua脚本中的多个key括起来,这样计算槽位时只会计算大括号内的字符,详见下文问题排查1
4.3.4 集群模式高可用及故障转移
4.3.4.1 故障检测和故障转移
发现master节点宕机之后,slave自动晋升为master,主要两点,如何发现主节点宕机(故障检测),以及slave如何发起切换(故障转移)
故障检测
集群间会互相发送心跳包,当节点A发现节点B长时间未曾回复心跳,则认为节点B可能下线,将节点B的状态改为PFAIL(probably fail)
cluster.c --> clusterCron

A节点在与其他master节点心跳交互时,会将B节点的PFAIL状态发送给其他节点,其他节点接收到B节点的PFAIL状态后,会生成该节点的下线报告保存到list,等到接收到半数以上master提交过来的下线报告之后,将B节点的状态改为FAIL,并将B节点的下线消息广播给集群所有节点,之后B节点的从节点得知master下线之后,开始故障转移过程
心跳处理相关函数如下 cluster.c --> clusterProcessGossipSection


故障转移
cluster --> clusterHandleSlaveFailover
判断故障转移条件

当前待晋升的slave节点必须足够新,不能过早的与master断开连接

向剩余master发送请求故障转移申请

等待其他节点响应请求之后,根据票数判断是否自己能够晋升为master
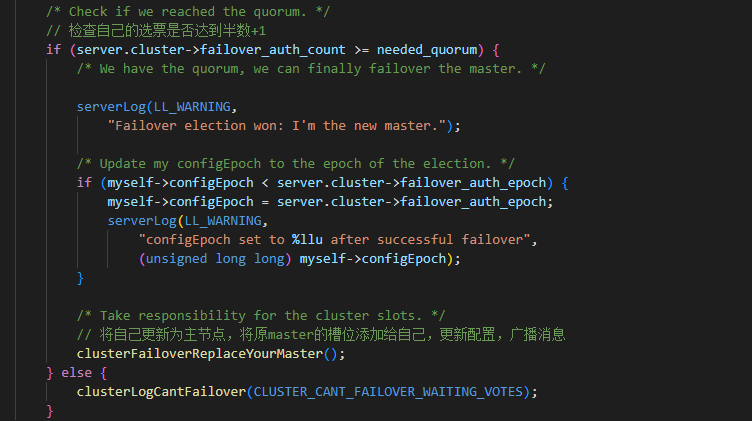
4.3.4.2 孤立master的slave转移
孤立master指的时没有任何可用的slave的master,如果检测到存在孤立master,那么其他节点如果有多余的slave,则该slave自动转移到孤立master下
有两个参数涉及
cluster-allow-replica-migration yes 是否允许slave自动转移,默认允许
cluster_migration_barrier 1 默认为1,表示slave被转走的master必须还剩下至少一个slave
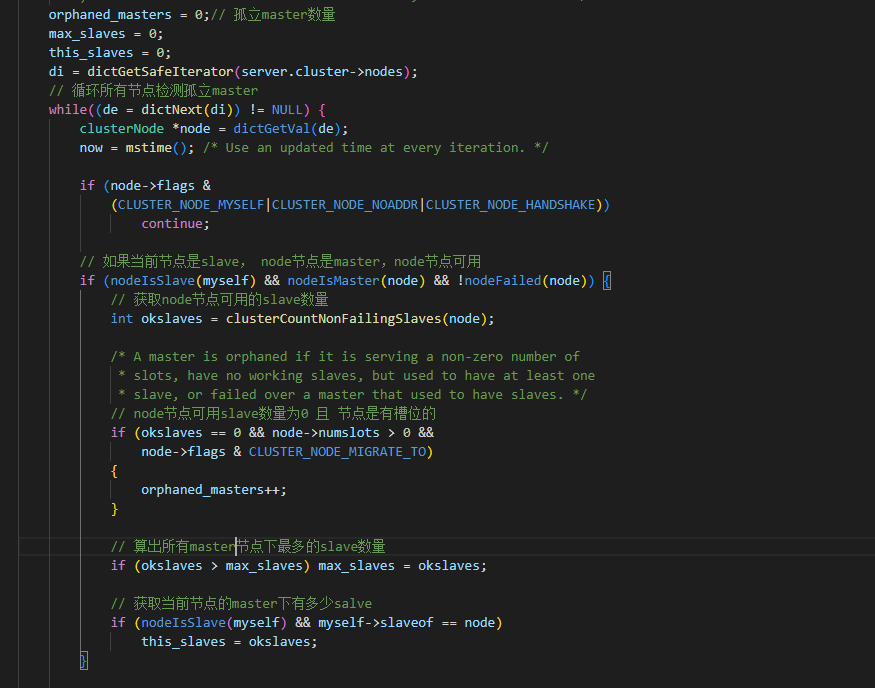

4.4 哨兵和集群优劣
哨兵用来自动主从切换,保证系统的高可用,集群也支持自动故障转移主从切换,我认为主要的区别点就在于是否分布式,哨兵模式下,主服务只有一台,并发量以及数据总量受限于硬件,如果并发大或者缓存数据多的情况下,可能存在性能瓶颈或者导致其他问题。
例如主从复制,数据量大时,master生成rdb文件,slave进行加载,master此时可以接收写请求,假如写请求量大,复制缓冲区很快溢出,master此时就会断掉与slave的复制连接,slave发现复制失败,又重新发起全量复制,进入恶性循环。
而集群模式基于数据分片,可以方便的进行水平扩展,也可以支持更大的并发量、支撑起更大的数据量,但有一点,只能使用db0,不支持select命令
还是根据具体系统的应用环境和实际使用情况来选择
5. 问题排查
5.1 No way to dispatch this command to Redis Cluster because keys have different slots
集群环境Jedis执行命令报错,命令涉及多个key
如果同一命令涉及到的多个key属于不同的槽位,那么会报错
解决方法可以使不同key拥有统一前缀,用大括号括起来
解决示例


在java客户端计算槽位算法代码也有体现,只使用大括号中的字符来计算槽位
redis.clients.jedis.util.JedisClusterCRC16#getSlot(byte[]) 计算槽位算法代码

5.2 Jedis does not support password protected Redis Cluster configurations!
jedis2.8之前不支持集群设置密码,升级jar包后解决
我的报错jar包版本:
jedis-2.8.1.jar
spring-data-redis-1.7.1.RELEASE.jar
升级后版本:
jedis-2.9.0.jar
spring-data-redis-1.8.6.RELEASE.jar
5.3 项目生产环境aof文件过大(145G)
随着命令不断写入AOF,文件会越来越大,这个问题Redis引入AOF重写机制压缩文件体积。
AOF文件重写是把Redis进程内的数据转化为写命令并同步到新AOF文件的过程
AOF重写会降低了文件占用空间,新的AOF文件会比原来的小
在生产环境发现问题redis节点aof文件占用硬盘大小高达145G,查看redis持久化相关配置如下
只用aof进行持久化,aof重写自动触发参数64mb和100%都是默认的无修改

默认redis也开启了混合持久化
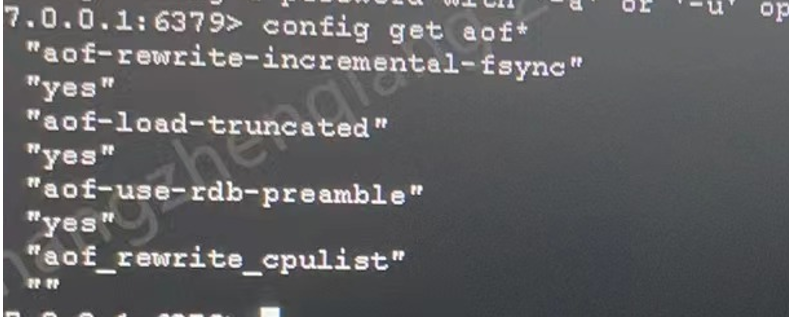
内存数据量不大,只有200m

所以按说定时aof重写的情况下,不可能出现aof持续增大的情况,查看持久化信息,看到其中aof_base_size和aof_current_size都为145G+,可见重写触发过,但是没有有效减少文件大小,可能失败了

考虑为什么重写失败,重写是将内存快照数据写入新的aof文件,重写完成后使用新aof文件来替换旧文件,可能无权限创建新文件导致重写失败,查看了redis目录下的权限,redis以redis用户启动,但目录为root权限,无法创建临时文件也无法删除原文件,导致aof大小不断增长

本机模拟测试redis日志报错如下

6. 其他
6.1 集群模式扩容/数据迁移
1、将新节点加入集群
bin/redis-cli --cluster add-node 192.168.146.105:8000 192.168.146.105:7000
192.168.146.105:8000 为新节点, 7000端口为已经存在的集群节点

查看集群节点情况,可以看到新加入的节点为master节点,但是还没有分配槽位

2、连接一个master,重新进行槽位分配
redis-cli --cluster reshard 192.168.146.105:7000

回车之后,会打印出槽位分配,输入yes开始执行,之后等待槽位和数据迁移完成即可

验证新节点是否已经有了迁移的数据


![[附源码]Python计算机毕业设计SSM基于JAVA快递配送平台(程序+LW)](https://img-blog.csdnimg.cn/2e439d2a12594fc8848e29a3aa357956.png)


![[附源码]Node.js计算机毕业设计高校学生心理健康信息咨询系统Express](https://img-blog.csdnimg.cn/339c36075c39412e8997c2f6ca53e235.png)