业务模型设计
- 业务模型设计
- 统一语言、术语
- 统一单词
- 业务数据表模型规范
- 数据库范式
- 几个经验
- 业务模型
- 索引
- 主键: 自增id、雪花id、和uuid 差别
- 创建表
- 字符集设置
- myisam 和 innodb 区别
业务模型设计
统一语言、术语
定义:需求分析的过程(系统目标、范围、具体功能达成一致的过程)中提炼领域知识的产出物
意义:在统一语言的前提下可以寻找正确的领域概念,为建立领域模型提供重要参考。 消除领域专家与团队、以及团队成员之间沟通的分歧与误解
统一语言的体现:
-
1 统一的领域术语(描述什么的)
-
2 领域行为描述(干什么的)
化解精通业务的领域专家和善于技术的开发人员 对业务术语理解之间的鸿沟。
统一单词
多团队协作时 业务术语的描述统一
举个栗子:
业务数据表模型规范
表名称、字段名称小写,语义化的表述 。见名知意
使用统一词汇表、统一字典表
自增主键:id
创建和更新: (必须非空等等约束)
create_user
update_time on update current_timestamp not null
create_time current_timestamp
update_time
数据库范式
- 1.第一范式(1NF):列不可再分
每一列属性都是不可再分的属性值,确保每一列的原子性
举例:地址、shiro框架,json字符串 :反例 - 2.第二范式(2NF)属性完全依赖于主键
必须要有主键 - 3.第三范式(3NF)属性不依赖于其它非主属性 属性直接依赖于主键
表与表之间的依赖关系 完全依托于主键字段 没有其他多余字段
范式大都是为了消除冗余而提出的,即尽可能的减少存储成本。
完全消除冗余可以做到,但是不一定是好的数据库设计
几个经验
- 一:字段的原子性
解释:保证每列的原子性,不可分解,意思表达要清楚,不能含糊,高度概括字段的含义,能用一个字段表达清楚的绝不使用第二个字段,必须要使用两个字段表达清楚的绝不能使用一个字段
- 二:主键设计
解释:主键不要与业务逻辑有所关联,最好是毫无意义的一串独立不重复的数字,常见的比如UUID或者将主键设置为Auto_increment;
- 三:状态值
解释:最好用独立的数字或者单个字母表示,不用使用汉字或长字符的英文
- 四:字段长度
解释:建表的时候,字段长度尽量要比实际业务的字段大3-5个字段左右(考虑到合理性和伸缩性),最好是2的n次方幂值。
- 五:关于外键
解释:尽量不要建立外键,保证每个表的独立性。如果非得保持一定的关系,最好是通过id进行关联
- 六:动静分离
解释:最好做好静态表和动态表的分离。这里解释一下静态表和动态表的含义,静态表:存储着一些固定不变的资源,比如城市/地区名/国家(静态表一定要使用缓存)。动态表:一些频繁修改的表
- 七:关于code值
解释:使用数字码或者字母去代替实际的名字。存储时
- 八:关于Null值
解释:尽量不要有null值,可以在建表的时候设置一个默认值!比如设置为:0,-1等
null值无法单独建立索引
- 九:关于引擎的选择
解释:innodb与myisam。
myisam的实际查询速度要比innodb快,因为它不扫面全表,但是myisam不支持事务,没办法保证数据的一致性。
- 十:资源存储
解释:数据库不存储任何资源文件,使用文件存储系统。
比如照片/视频/网站等,可以用文件路径/外链用来代替,这样可以在程序中通过路径,链接等来进行索引
- 十一:与主键相关
解释:根据数据库设计三大范式,尽量保证列数据和主键直接相关而不是间接相关
- 十二:关系映射
解释:多对一或者一对多的关系,关联一张表最好通过id去建立关系。
多对多关系,使用中间表建立关系
而不是去做重复数据,这样做最大的好处就是中间的关系表比较清楚明白。
- 十五:删除数据
设置删除状态!
业务模型
照着原型图或者高保真ui图,设计表模型
梳理,模型之间一对一和一对多,多对多之间的关系

索引
-
普通索引(NORMAL)
仅加速查询,无限制
关键字: INDEX -
唯一索引(UNIQUE)
加速查询 + 列值唯一(可以有null),如果是组合索引,则列值的组合必须唯一
关键字:UNIQUE -
主键索引 (PRIMARY KEY)
加速查询 + 列值唯一(不可以有null)+ 表中只允许有一个主键索引, 是一种特殊的唯一索引
关键字:PRIMARY KEY -
组合索引
多列值组成一个索引,专门用于组合搜索,其效率大于索引合并(索引合并:使用多个单列索引组合搜索)
只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
没有关键字,多个字段使用普通、唯一、主键索引就是组合索引
创建联合索引时,应该仔细考虑下列的顺序,区分度大的放在前面 -
全文索引
关键字:FULLTEXT
主键: 自增id、雪花id、和uuid 差别
mysql 官方推荐连续自增的主键 id。考虑自增上界
https://blog.csdn.net

创建表
CREATE TABLE
[IF NOT EXISTS] tb_name -- 不存在才创建,存在就跳过
(column_name1 data_type1 -- 列名和类型必选
[ PRIMARY KEY -- 可选的约束,主键
| FOREIGN KEY -- 外键,引用其他表的键值
| AUTO_INCREMENT -- 自增ID
| COMMENT comment -- 列注释(评论)
| DEFAULT default_value -- 默认值
| UNIQUE -- 唯一性约束,不允许两条记录该列值相同
| NOT NULL -- 该列非空
], ...
) [CHARACTER SET charset] -- 字符集编码
[COLLATE collate_value] -- 列排序和比较时的规则(是否区分大小写等)
复制表结构创建表: CREATE TABLE tb_name LIKE tb_name_old
查询结果创建表: CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options
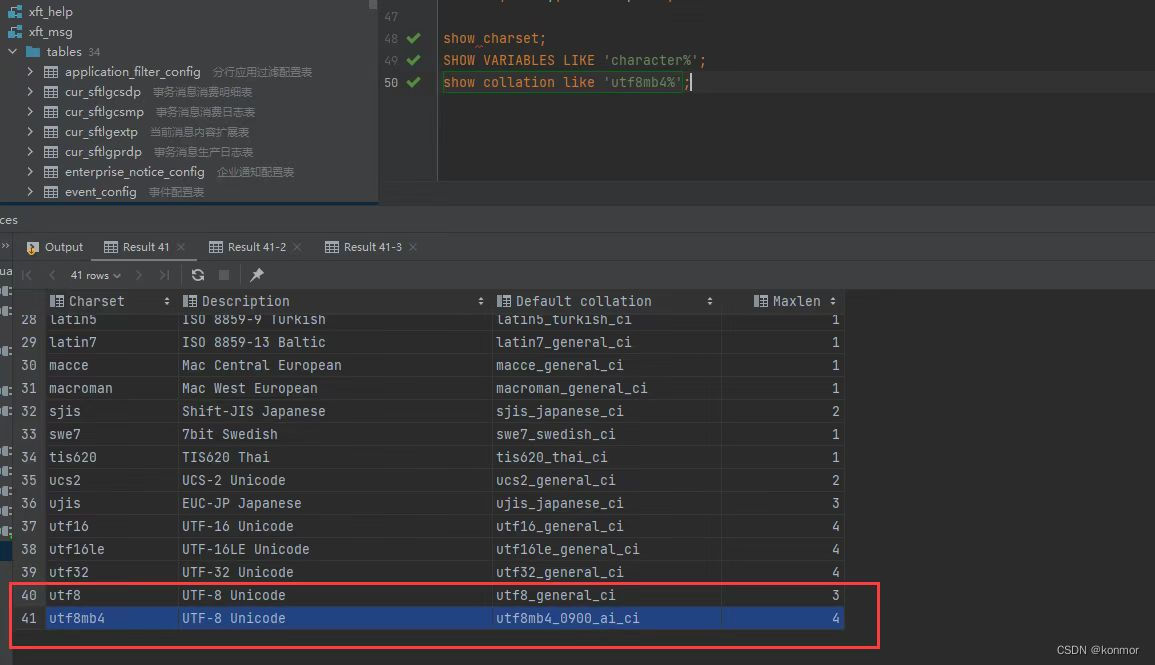
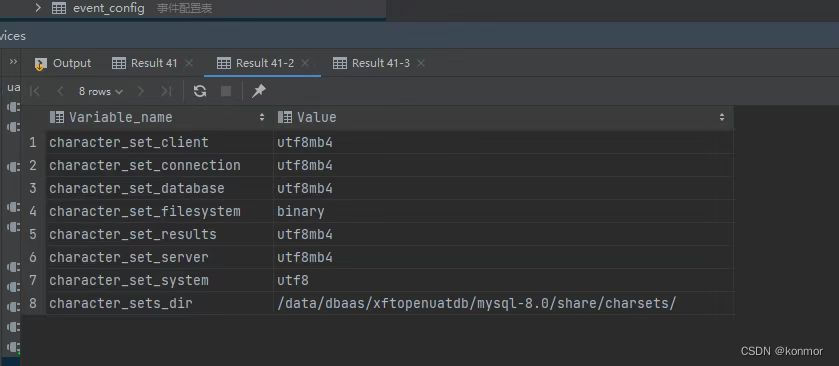
字符集设置
show charset;
show variables like 'character%';
show collation like 'utf8mb4%';
https://zhuanlan.zhihu.com/p/471370773

myisam 和 innodb 区别
一般选择innodb