【项目背景】
小编一直在尝试着短视频技术,在读文案的时候经常会读错;所以,只能用微软或者剪映的文本转语音软件。
很早之前在Github上也看到过真人人声训练的开源代码,尝试过一番之后,也是以失败告终;就在前几个月歌手语音的训练、个人真人声音的训练又火了一波,新的开源代码小编手上也有,但是无奈自己的N卡太弱,跑pytorch心有余而力不足。
这不,随着国内擅长声音处理的讯飞大模型融合了真人声音训练,小编借此机会对其做了一个小小的封装。
【项目实现】

https://xinghuo.xfyun.cn/desk
首先,需要用讯飞的大模型训练自己的声音,右上角点击创建发音人,这个时候需要录制10段个人语音,云端训练大概需要5~10分钟,训练好之后的界面同上图,可以选择发音人(真人人声)。
然后,就可以将自己的文本投喂给大模型,可以是问题,也可以是自己已经写好的文本,具体例子:
用户:请润色下面文本,并拟定1个吸睛的标题。
文本:
土木工程现在房地产大环境下不是太热门,其实大学的专业作为对于每个人来讲(个人观点),本身就是将来对于自己的一个谋生的手段,这个专业大家最多的印象最多的就是提桶跑路吧,但是每个专业都有每个专业的好处与坏处,这个专业门槛低,就业前期工作收入比较高,就业方向比较多,造价,施工、设计,监理等,适合善于交际的人。坏处大家都应该知道,环境相对别的专业较差,有时候面对的班组劳务的教育水平不是很高,人际关系不好后期发展受限等。
星火大模型回答的文本,就出出现一个语音按钮,点击该按钮就可以听到你的真人发音。但是,该大模型已经禁止浏览使用开发模式,生成的TTS音频无法通过插件工具实现音频导出。
解决方案:通过声卡复制类软件,实现在朗读语音时,对声卡数据进行复制,进而实现音频导出。
请重新输出以下文本:土木工程现在房地产大环境下不是太热门,其实大学的专业作为对于每个人来讲(个人观点),本身就是将来对于自己的一个谋生的手段,这个专业大家最多的印象最多的就是提桶跑路吧,但是每个专业都有每个专业的好处与坏处,这个专业门槛低,就业前期工作收入比较高,就业方向比较多,造价,施工、设计,监理等,适合善于交际的人。

作为一个准程序员,这种方案可以解决问题,但总是差强人意。
于是,在想,能不能通过fiddler分析转换接口,形成API或者封装成一个工具?说干就干,刚好西安周末下雨,宅在家里,对其进行分析,最终封装成一个exe。

使用该工具,需要下载fiddler,获取ID和cookies。
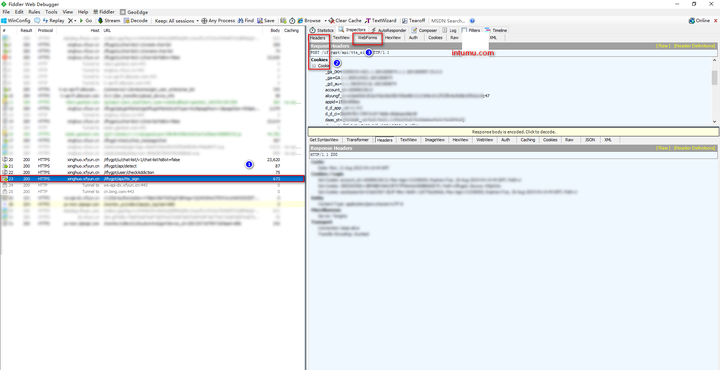
上图,点击①链接,在②处复制header即可获取到cookie,在③处可以获取到ID(tts)。
接下来就可以用剪映工具制作视频(真人原声),从此告别千篇一律的机器声。
【工具下载】
https://intumu.com/article/202
【应用拓展】
真人人声+MD数字人?可以衍生出很多Ideas,感兴趣的小伙伴也可以加小编微信探讨。
学Python并不难,会敲键盘就能学!


![[Docker] Windows 下基于WSL2 安装](https://img-blog.csdnimg.cn/66917c62f683477b97962f7035b7d1ea.png#pic_center)