查询执行图


查询顺序

explain 参数说明


Id: MySQL QueryOptimizer 选定的执行计划中查询的序列号。表示查询中执行select 子句或操作表的顺序,id 值越大优先级越高,越先被执行。id 相同,执行顺序由上至下
Select_type: 一共有9中类型,只介绍常用的4种: SIMPLE: 简单的 select 查询,不使用 union 及子查询;PRIMARY: 最外层的 select 查询;UNION: UNION 中的第二个或随后的 select 查询,不依赖于外部查询的结果集;DERIVED: 用于 from 子句里有子查询的情况。 MySQL 会递归执行这些子查询, 把结果放在临时表里
Table: 输出行所引用的表
Type: 从优到差的顺序如下:(* 的是常见的级别。)system–>const *–>eq_ref *–>ref *–>ref_or_null–>index_merge–>unique_subquery–>index_subquery–>range *–>index *–>all *
注:一般需要达到 ref、eq_ref 级别,范围查找需要达到 range
possible_keys : 哪些索引可能有助于查询。如果为空,说明没有可用的索引
key: 实际从 possible_key 选择使用的索引,如果为 NULL,则没有使用索引。其中key为null、all 、index时,需要调整、优化索引。很少的情况下,MYSQL 会选择优化不足的索引。这种情况下,可以在 SELECT语句中使用 USE INDEX (indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len: 使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref: 显示索引的哪一列被使用了
rows: 请求数据返回的大概行数。根据rows可以直观看出优化结果
extra: 其他信息,出现Using filesort、Using temporary 意味着不能使用索引,效率会受到重大影响。应尽可能对此进行优化。三者区别如下:
Using filesort: 没有办法利用现有索引进行排序,需要额外排序,建议:根据排序需要,创建相应合适的索引
Using temporary: 需要用临时表存储结果集,通常是因为group by的列上没有索引。也有可能是因为同时有group by和order by,但group by和order by的列又不一样
Using index :利用覆盖索引,无需回表即可取得结果数据(即数据直接从索引文件中读取),这种结果是好的
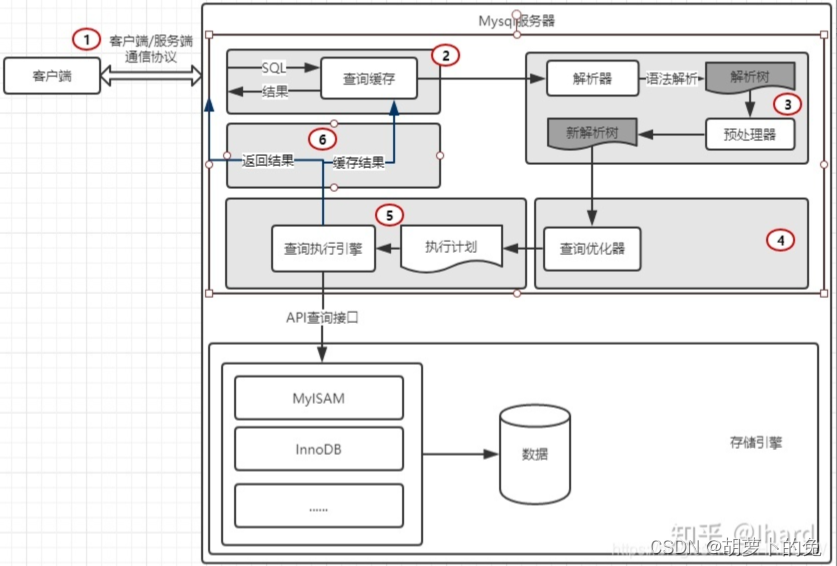
mysql 与客户端通信协议
抛球协议,
mysql与客户端通信是“半双工”模式,

max_allowed_packet
在新增、修改很大数据需要把该配置变大
指mysql服务器端和客户端在一次传送数据包的过程当中最大允许的数据包大小。
max_allowed_packet = 64M
查看mysql状态
show full processlist


查询优化器

last_query_cost

SELECT concat("蒙KD1592", "陕KE7490", "陕KD4582") FROM trade WHERE vehicle_no LIKE concat("蒙KD1592", "陕KE7490", "陕KD4582")
show STATUS LIKE 'Last_query_cost'
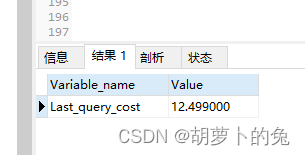
大概需要12数据页的随机查找才能完成上面的查询

![[附源码]Nodejs计算机毕业设计基于的宠物领养管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/a6d2fbbcb561430481b2a6bb1538816f.png)





![[附源码]Node.js计算机毕业设计高校教材管理系统Express](https://img-blog.csdnimg.cn/54bd7bac56cb4a1da59ccbb402d5a635.png)