《Learning Transferable Visual Models From Natural Language Supervision》
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系,预训练模型在未知数据集上实现zero-shot。
1. CLIP模型架构
1.1 文本-图像的预训练方法
CLIP的模型结构其实非常简单:包括两个部分,即文本编码器(Text Encoder)和图像编码器(Image Encoder)。Text Encoder选择的是Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。
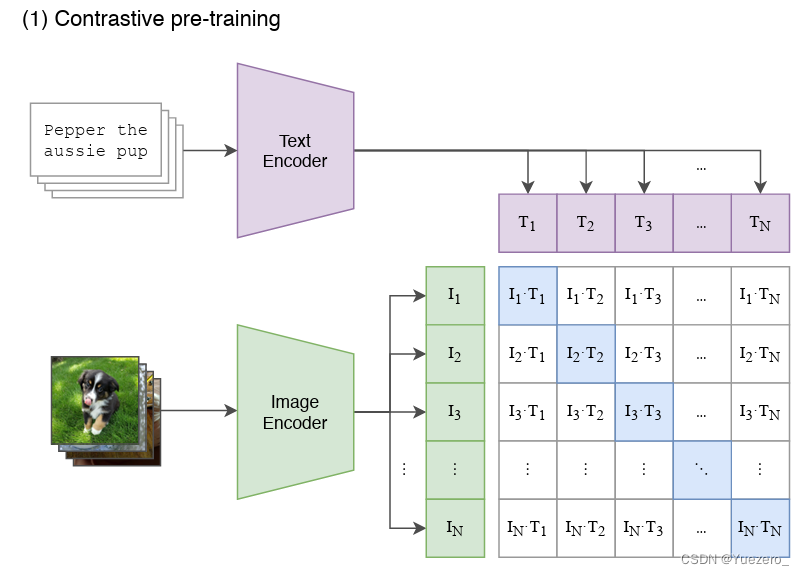
CLIP在文本-图像对数据集上的对比学习训练过程如下:
- 对于一个包含N个<文本-图像>对的训练batch,使用Text Encoder和Image Encoder提取N个文本特征和N个图像特征。
- 这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的 N 2 − N N^2-N N2−N个文本-图像对为负样本。
- 将N个文本特征和N个图像特征两两组合,CLIP模型会预测出 N 2 N^2 N2 个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。
- 那么CLIP的训练目标就是最大化N个正样本的相似度,同时最小化 N 2 − N N^2-N N2−N个负样本的相似度,即最大化对角线中蓝色的数值,最小化其它非对角线的数值: m i n ( ∑ i = 1 N ∑ j = 1 N ( I i ⋅ T j ) i ! = j − ∑ i = 1 ( I i ⋅ T j ) ) min(\sum_{i=1}^{N}\sum_{j=1}^{N}(I_i \cdot T_j)_{i!=j}-\sum_{i=1}(I_i \cdot T_j)) min(∑i=1N∑j=1N(Ii⋅Tj)i!=j−∑i=1(Ii⋅Tj))
对应的伪代码实现如下所示:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度。

1.2 迁移预训练模型实现zero-shot
可以看到训练后的CLIP其实是两个模型:视觉模型+文本模型,与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
经过在文本-图像对数据上训练的模型,有能力判断给定的文本和图像是否匹配。这时CLIP已经完成了其全部训练过程,完全不需要Imagenet或其它数据集中的图像-类别标签,即可以直接做图像分类了。
这也是CLIP这个模型最大的亮点:zero-shot图像分类。这是如何实现的呢,其实也非常简单:
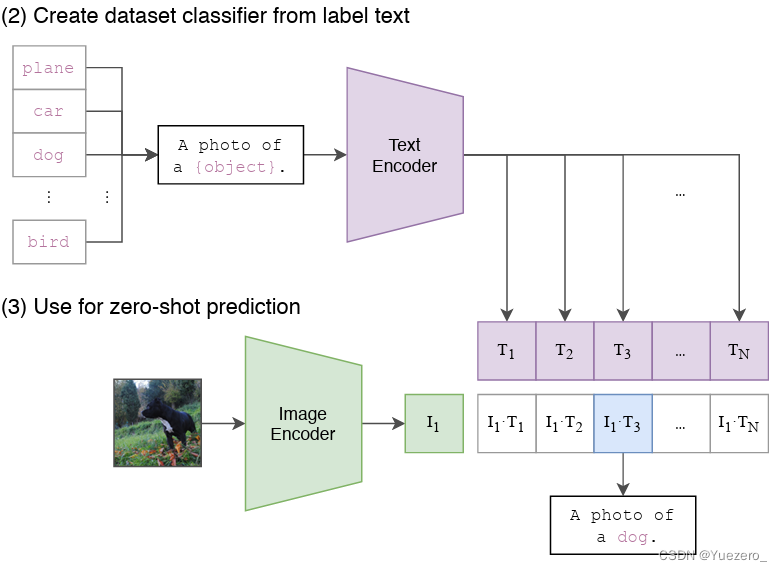
- 根据任务的分类标签构建每个类别的描述文本(以Imagenet有N=1000类为例):
A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;
# 首先生成每个类别的文本描述(例如6个类别文本)
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()
# 提取文本特征
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
- 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
# 读取待预测图像
original_images = []
images = []
texts = []
for label in labels:
image_file = os.path.join("images", label+".jpg")
name = os.path.basename(image_file).split('.')[0]
image = Image.open(image_file).convert("RGB")
original_images.append(image)
images.append(preprocess(image))
texts.append(name)
image_input = torch.tensor(np.stack(images)).cuda()
# 提取图像特征
with torch.no_grad():
image_features = model.encode_image(image_input).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
# 计算余弦相似度(未缩放)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
# 对得到的余弦相似度计算softmax,得到每个预测类别的概率值
logit_scale = np.exp(model.logit_scale.data.item())
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
2. 实验分析
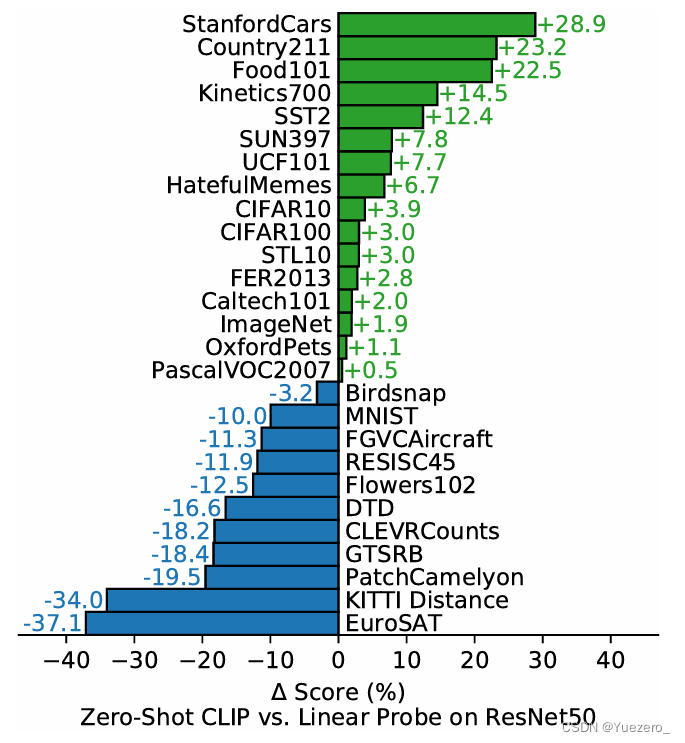
我们从左图中看到,CLIP在16个数据集上可以超过全监督的ResNet50;但是在一些较为特殊的数据集上,CLIP表现差于ResNet50,例如MNIST等。这个原因来自于MNIST中手写体数字图片,在其搜集的4亿文本-图像对中很少出现,导致CLIP没有学习到这么特殊的图像/文本。而ResNet50采取全监督的训练方式,将数据集的特殊性都学习到了,因此分类准确率较高。(个人猜测: 如果Open AI收集一些相似于特殊数据集中的图像,加入其文本-图像对数据集中,也可以在这些特殊数据集上提升效果)
同时,我们从右图中看到,CLIP和全监督训练的ResNet101在ImageNet验证集上都能达到76.2%的准确率,而在下面一些分布漂移(数据集中不同类别图像的数量分布不均衡)的数据集上,CLIP更是远超全监督训练的ResNet101。最明显的是,在ImageNet-A数据集上,CLIP可以达到77.1%,而ResNet只有2.7%(基本属于瞎猜)。这证明了使用文本-图像做预训练的CLIP具备更强的鲁棒性。
除了图像分类任务,CLIP还实现了文本-图像的预训练。这也为其后续做文本-图像生成及更多下游任务做了铺垫。
2.1 局限性
论文的最后也对CLIP的局限性做了讨论,这里简单总结其中比较重要的几点:
- CLIP的zero-shot性能虽然和有监督的ResNet50相当,但是还不是SOTA,作者估计要达到SOTA的效果,CLIP还需要增加1000x的计算量,这是难以想象的;
- CLIP的zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等;
- CLIP在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差;
- CLIP并没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据;
2.2 总结
CLIP 的最大贡献在于打破了固定种类标签的桎梏,让下游任务的推理变得更灵活,并且在 zero-shot 的情况下,它的效果很不错。
-
有监督预训练模型仍需微调,无法实现zero-shot:在计算机视觉领域,最常采用的迁移学习方式就是先在一个
较大规模的数据集如ImageNet上预训练,然后在具体的下游任务上再进行微调。这里的预训练是基于有监督训练的,需要大量的数据标注,因此成本较高。 -
很多自监督预训练模型也需要下游微调:近年来,出现了一些基于自监督的方法,这包括
基于对比学习的方法如MoCo和SimCLR、基于图像掩码的方法如MAE和BeiT,自监督方法的好处是不再需要标注,但是无论是有监督还是自监督方法,它们在迁移到下游任务时,还是需要进行有监督微调,而无法实现zero-shot。 -
CLIP解决了自监督预训练模型需要下游微调的现状!
在这篇工作发表之后,涌现出了一大批在其他领域的应用,包括物体检测、物体分割、图像生成、视频动作检索等。在创新度、有效性、影响力方面都非常出色。如扩展到文本-视频,VideoCLIP就是将CLIP应用在视频领域来实现一些zero-shot视频理解任务。







![[已解决]SpringBoot 返回日期时间格式不正确](https://img-blog.csdnimg.cn/d15bf979356c4f329826baf157440091.png)