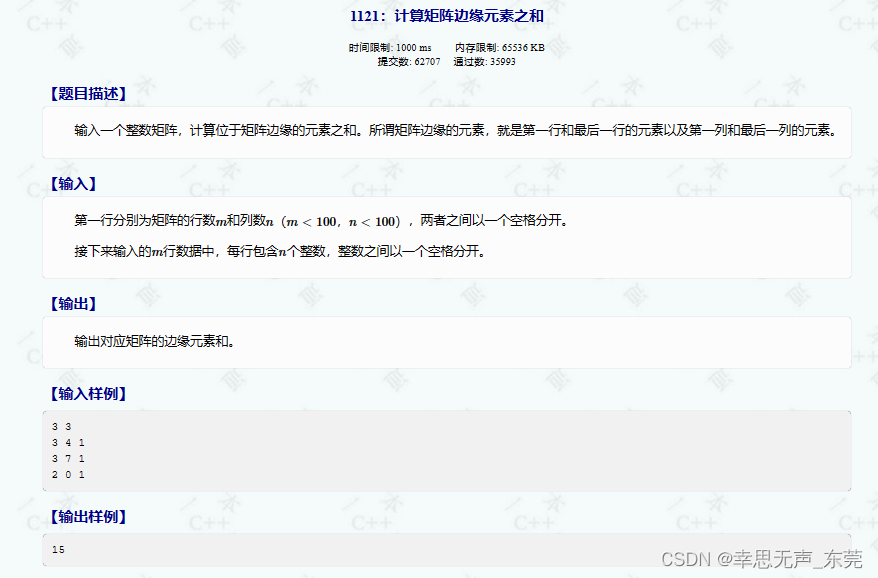
基于WIN10的64位系统演示
一、写在前面
本期内容对等于机器学习二分类系列的误判病例分析(传送门)。既然前面的数据可以这么分析,那么图形识别自然也可以。
本期以mobilenet_v2模型为例,因为它建模速度快。
同样,基于GPT-4辅助编程,后续会分享改写过程。
二、误判病例分析实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
from tensorflow import keras
import tensorflow as tf
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, Activation, Reshape, Softmax, GlobalAveragePooling2D, BatchNormalization
from tensorflow.python.keras.layers.convolutional import Convolution2D, MaxPooling2D
from tensorflow.python.keras import Sequential
from tensorflow.python.keras import Model
from tensorflow.python.keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator, image_dataset_from_directory
from tensorflow.python.keras.layers.preprocessing.image_preprocessing import RandomFlip, RandomRotation, RandomContrast, RandomZoom, RandomTranslation
import os,PIL,pathlib
import warnings
#设置GPU
gpus = tf.config.list_physical_devices("GPU")
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
################################导入数据集#####################################
data_dir = "./MTB"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
batch_size = 32
img_height = 100
img_width = 100
# 创建一个数据集,其中包含所有图像的路径。
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=True)
# 切分为训练集和验证集
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
one_hot = parts[-2] == class_names
return tf.argmax(one_hot)
def decode_img(img):
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, [img_height, img_width])
img = img / 255.0 # normalize to [0,1] range
return img
def process_path_with_filename(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label, file_path
AUTOTUNE = tf.data.AUTOTUNE
# 在此处对train_ds和val_ds进行图像处理,包括添加文件名信息
train_ds_with_filenames = train_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
val_ds_with_filenames = val_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
# 对训练数据集进行批处理和预加载
train_ds_with_filenames = train_ds_with_filenames.batch(batch_size)
train_ds_with_filenames = train_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)
# 对验证数据集进行批处理和预加载
val_ds_with_filenames = val_ds_with_filenames.batch(batch_size)
val_ds_with_filenames = val_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)
# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))
for image, label, path in train_ds_with_filenames.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
print("Path: ", path.numpy())
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")
for images, labels, paths in train_ds_with_filenames.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]])
plt.show()
######################################数据增强函数################################
data_augmentation = Sequential([
RandomFlip("horizontal_and_vertical"),
RandomRotation(0.2),
RandomContrast(1.0),
RandomZoom(0.5, 0.2),
RandomTranslation(0.3, 0.5),
])
def prepare(ds, augment=False):
ds = ds.map(lambda x, y, z: (data_augmentation(x, training=True), y, z) if augment else (x, y, z),
num_parallel_calls=AUTOTUNE)
return ds
train_ds_with_filenames = prepare(train_ds_with_filenames, augment=True)
# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
###############################导入mobilenet_v2################################
#获取预训练模型对输入的预处理方法
from tensorflow.python.keras.applications import mobilenet_v2
from tensorflow.python.keras import Input, regularizers
IMG_SIZE = (img_height, img_width, 3)
base_model = mobilenet_v2.MobileNetV2(input_shape=IMG_SIZE,
include_top=False, #是否包含顶层的全连接层
weights='imagenet')
inputs = Input(shape=IMG_SIZE)
#模型
x = base_model(inputs, training=False) #参数不变化
#全局池化
x = GlobalAveragePooling2D()(x)
#BatchNormalization
x = BatchNormalization()(x)
#Dropout
x = Dropout(0.8)(x)
#Dense
x = Dense(128, kernel_regularizer=regularizers.l2(0.1))(x) # 全连接层减少到128,添加 L2 正则化
#BatchNormalization
x = BatchNormalization()(x)
#激活函数
x = Activation('relu')(x)
#输出层
outputs = Dense(2, kernel_regularizer=regularizers.l2(0.1))(x) # 添加 L2 正则化
#BatchNormalization
outputs = BatchNormalization()(outputs)
#激活函数
outputs = Activation('sigmoid')(outputs)
#整体封装
model = Model(inputs, outputs)
#打印模型结构
print(model.summary())
#############################编译模型#########################################
#定义优化器
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2
optimizer = adam_v2.Adam()
#编译模型
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#训练模型
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
NO_EPOCHS = 5
PATIENCE = 10
VERBOSE = 1
# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-5 * 0.99 ** (x+NO_EPOCHS))
# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)
#
checkpointer = ModelCheckpoint('mtb_jet_best_model_mobilenetv3samll-1.h5',
monitor='val_accuracy',
verbose=VERBOSE,
save_best_only=True,
save_weights_only=True)
train_model = model.fit(train_ds,
epochs=NO_EPOCHS,
verbose=1,
validation_data=val_ds,
callbacks=[earlystopper, checkpointer, annealer])
#保存模型
model.save('mtb_jet_best_model_mobilenet-1.h5')
print("The trained model has been saved.")
###########################误判病例分析#################################
# 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd
# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])
# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):
for images, labels, paths in dataset:
# 使用模型对这一批图片进行预测
probabilities = model.predict(images)
predictions = tf.math.argmax(probabilities, axis=-1)
# 遍历这一批图片
for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):
# 获取图片名称和真实标签
image_name = path.numpy().decode("utf-8").split('/')[-1]
original_label = class_names[label]
# 根据预测结果和真实标签,判定图片所属的组别
group = None
if original_label == "Tuberculosis" and probability[1] >= 0.5:
group = "A"
elif original_label == "Normal" and probability[1] < 0.5:
group = "B"
elif original_label == "Normal" and probability[1] >= 0.5:
group = "C"
elif original_label == "Tuberculosis" and probability[1] < 0.5:
group = "D"
# 将结果添加到dataframe中
result_df = result_df.append({
"原始图片的名称": image_name,
"属于训练集还是验证集": dataset_name,
"预测为Tuberculosis的概率值": probability[1],
"判定的组别": group
}, ignore_index=True)
# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)相比于之前的代码,主要有两处变化:
- 导入数据集部分:由之前的“image_dataset_from_directory”改成“tf.data.Dataset”,因为前者不能保存图片的原始路径和名称。而在误判病例分析中,我们需要知道每一张图片的名称、被预测的结果等详细信息。
- 误判病例分析部分:也就是需要知道哪些预测正确,哪些预测错误。
(b)调教GPT-4的过程
(b1)导入数据集部分:“image_dataset_from_directory”改成“tf.data.Dataset”
让GPT-4帮你改写即可,自行尝试:
################################导入数据集#####################################
data_dir = "./MTB"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
batch_size = 32
img_height = 100
img_width = 100
# 创建一个数据集,其中包含所有图像的路径。
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=True)
# 切分为训练集和验证集
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
one_hot = parts[-2] == class_names
return tf.argmax(one_hot)
def decode_img(img):
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, [img_height, img_width])
img = img / 255.0 # normalize to [0,1] range
return img
def process_path_with_filename(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label, file_path
AUTOTUNE = tf.data.AUTOTUNE
# 在此处对train_ds和val_ds进行图像处理,包括添加文件名信息
train_ds_with_filenames = train_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
val_ds_with_filenames = val_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
# 对训练数据集进行批处理和预加载
train_ds_with_filenames = train_ds_with_filenames.batch(batch_size)
train_ds_with_filenames = train_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)
# 对验证数据集进行批处理和预加载
val_ds_with_filenames = val_ds_with_filenames.batch(batch_size)
val_ds_with_filenames = val_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)
# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))
for image, label, path in train_ds_with_filenames.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
print("Path: ", path.numpy())
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")
for images, labels, paths in train_ds_with_filenames.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]])
plt.show()
######################################数据增强函数################################
data_augmentation = Sequential([
RandomFlip("horizontal_and_vertical"),
RandomRotation(0.2),
RandomContrast(1.0),
RandomZoom(0.5, 0.2),
RandomTranslation(0.3, 0.5),
])
def prepare(ds, augment=False):
ds = ds.map(lambda x, y, z: (data_augmentation(x, training=True), y, z) if augment else (x, y, z),
num_parallel_calls=AUTOTUNE)
return ds
train_ds_with_filenames = prepare(train_ds_with_filenames, augment=True)
# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)代码解读:
数据导入:代码首先指定图像数据的存放路径(data_dir),并统计路径下的图像总数(image_count)。之后,它将图片的高度和宽度分别设定为100,并且指定批量处理的大小为32。
数据集创建:使用tf.data.Dataset.list_files创建一个包含所有图像路径的数据集,并通过洗牌(shuffle)打乱数据。然后,将20%的数据作为验证集,其余的作为训练集。
类别标签获取:根据文件夹名称作为类别标签,其中去除了名为"LICENSE.txt"的文件。
图像和标签处理:定义了几个函数来处理图像和标签。get_label函数通过切割文件路径获取类别标签并转为one-hot编码;decode_img函数将图像解码并调整大小,且将像素值归一化到[0,1]范围内;process_path_with_filename函数则通过调用前两个函数处理图像和标签。
并行处理和预加载:使用tf.data.AUTOTUNE对训练集和验证集进行并行处理和预加载,提高数据读取效率。
数据展示:展示了部分训练数据的图片、类别和文件路径,帮助我们对数据有个初步了解。
数据增强:定义了一个数据增强管道,其中包含了随机翻转、旋转、对比度调整、缩放和平移等操作。然后在训练集上应用这个数据增强管道。
(b2)误判病例分析部分
咒语:在{代码1}的基础上续写代码,达到下面要求:
(1)首先,提取出所有图片的“原始图片的名称”、“属于训练集还是验证集”、“预测为Tuberculosis的概率值”;文件的路劲格式为:例如,“MTB\Normal\Normal-690.png”属于Normal,也就是0标签,“MTB\Tuberculosis\Tuberculosis-680.png”属于Tuberculosis,也就是1标签;
(2)其次,由于模型以0.5为阈值,因此可以样本分为三份:(a)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测正确,判定为A组;(b)本来就是Normal的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为B组;(c)本来就是Normal的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测错误,判定为C组;(d)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为D组;
(3)居于以上计算的结果,生成一个名为result.csv表格文件。列名分别为:“原始图片的名称”、“属于训练集还是验证集”、“预测为Tuberculosis的概率值”、“判定的组别”。其中,“原始图片的名称”为所有1600张图片的图片名称;“属于训练集还是验证集”为这个图片属于训练集还是验证集;“预测为Tuberculosis的概率值”为模型预测该样本是Tuberculosis的概率值;“判定的组别”为根据步骤(3)判定的组别,A、B、C和D四组。
(4)需要把所有的图片都进行上面操作,注意是所有图片,而不只是一个批次的图片。
代码1为:{XXXX}
主要是把需求写清楚即可,代码及其解读:
# 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd
# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])
# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):
for images, labels, paths in dataset:
# 使用模型对这一批图片进行预测
probabilities = model.predict(images)
predictions = tf.math.argmax(probabilities, axis=-1)
# 遍历这一批图片
for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):
# 获取图片名称和真实标签
image_name = path.numpy().decode("utf-8").split('/')[-1]
original_label = class_names[label]
# 根据预测结果和真实标签,判定图片所属的组别
group = None
if original_label == "Tuberculosis" and probability[1] >= 0.5:
group = "A"
elif original_label == "Normal" and probability[1] < 0.5:
group = "B"
elif original_label == "Normal" and probability[1] >= 0.5:
group = "C"
elif original_label == "Tuberculosis" and probability[1] < 0.5:
group = "D"
# 将结果添加到dataframe中
result_df = result_df.append({
"原始图片的名称": image_name,
"属于训练集还是验证集": dataset_name,
"预测为Tuberculosis的概率值": probability[1],
"判定的组别": group
}, ignore_index=True)
# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)代码解读:
首先,代码创建了一个名为result_df的pandas DataFrame,用于存储预测结果。这个DataFrame有四个列,分别为"原始图片的名称"、"属于训练集还是验证集"、"预测为Tuberculosis的概率值"、"判定的组别"。
然后,代码开始遍历训练集和验证集中的每一批图片。对于每一批图片,首先使用训练好的模型进行预测,得到每个样本属于每个类别的概率值(probabilities)。然后,通过取概率值最大的类别作为预测结果(predictions)。
在对一批图片进行预测后,代码遍历这批图片。对于每个图片,代码首先从图片路径中获取图片名称(image_name),并从标签中获取图片的真实标签(original_label)。
然后,代码根据预测结果和真实标签判断图片属于哪个组别("A"、"B"、"C"、"D")。这里假设"Tuberculosis"和"Normal"是所有类别中的两个类别,而且概率值中的第二个元素表示的是预测为"Tuberculosis"的概率。具体的判断规则如下:
--如果真实标签是"Tuberculosis",且预测为"Tuberculosis"的概率值大于等于0.5,则图片属于组别"A"。
--如果真实标签是"Normal",且预测为"Tuberculosis"的概率值小于0.5,则图片属于组别"B"。
--如果真实标签是"Normal",且预测为"Tuberculosis"的概率值大于等于0.5,则图片属于组别"C"。
--如果真实标签是"Tuberculosis",且预测为"Tuberculosis"的概率值小于0.5,则图片属于组别"D"。
最后,代码将预测结果添加到result_df中,其中包含图片名称、数据集名称(训练集或验证集)、预测为"Tuberculosis"的概率值以及判定的组别。当所有图片都进行完预测后,将result_df保存为一个CSV文件。
三、输出结果

有了这个表,又可以水不少图了。
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf



![[已解决]SpringBoot 返回日期时间格式不正确](https://img-blog.csdnimg.cn/d15bf979356c4f329826baf157440091.png)