解析语句标签 Select|Update|Insert|Delete
- 一、前言
- 二、语句标签的源码分析
- 三、sql 标签的解析
- 四、总结
一、前言
在阐述解析语句标签之前,得先知道我们的语句标签内容最后被封装到Configuration哪?(都应该知道 Mybatis 通过的是 XMLConfigBuilder 去解析 xml 然后封装到Configuration对象中传递给 SqlSessionFactory 去往下执行)。
而语句标签的解析内容,即被封装到了 Configuration 中的 mappedStatements Map对象中,即如下属性:
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>(
"Mapped Statements collection")
.conflictMessageProducer((savedValue, targetValue) -> ". please check " + savedValue.getResource() + " and "
+ targetValue.getResource());
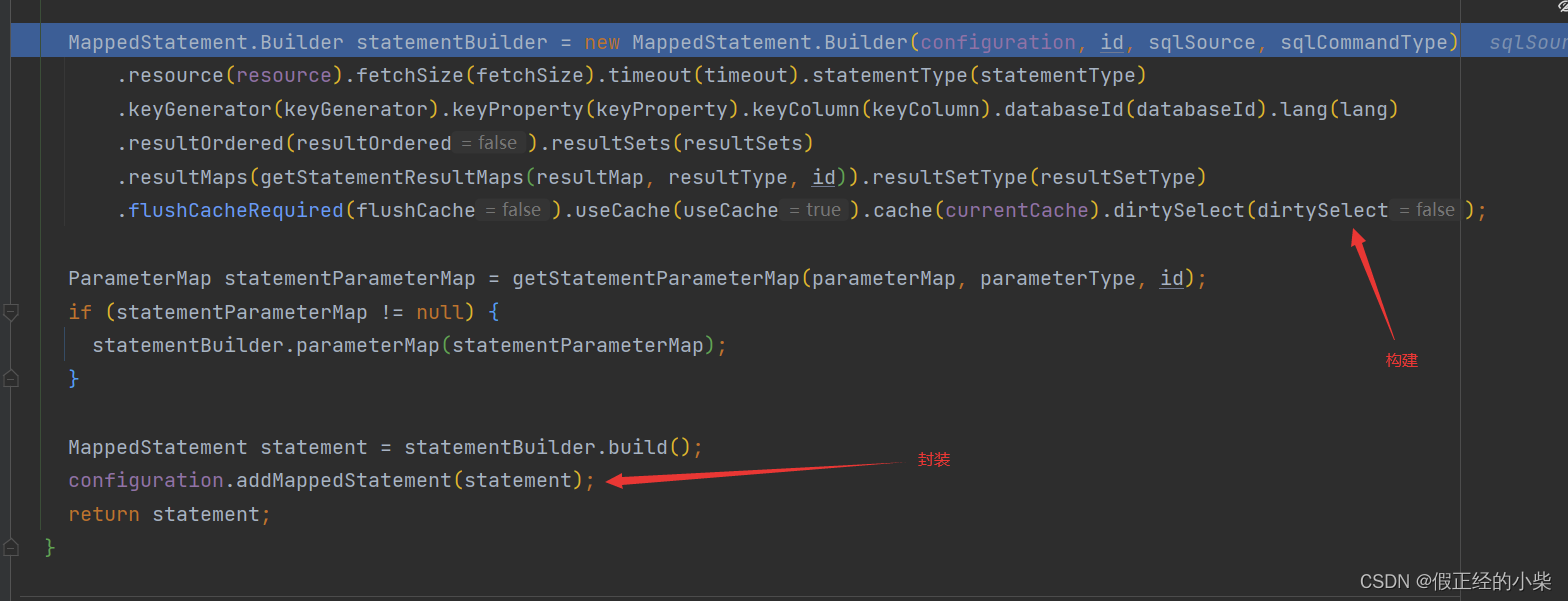
其 key 对应的是标签 id,而 MappedStatement 是对语句标签内容的封装实例类(它是一个 final 类,最终是通过内部的 Builder 类 build 构建出来的,未向外提供构造),你可以理解为一条 Select|Update|Insert|Delete 语句标签映射着一个 MappedStatement,就如同一个ResultMap 字段对应着一个 ResultMapping 一样。内部属性如下:
private String resource;// 源自于哪个mapper文件
private Configuration configuration;// 配置文件
private String id;// id
private Integer fetchSize;// 每次从服务器获取的数量
private Integer timeout;// 最长访问数据库的时间
private StatementType statementType;// STATEMENT、PREPARED、CALLABLE
private ResultSetType resultSetType;
private SqlSource sqlSource;// 对SQL的包装
private Cache cache;// 缓存
private ParameterMap parameterMap;
private List<ResultMap> resultMaps;// 结果映射
private boolean flushCacheRequired;// 是否需要缓存刷新
private boolean useCache;// 是否使用二级缓存
private boolean resultOrdered;
private SqlCommandType sqlCommandType;// UNKNOWN、INSERT、UPDATE、SELECT
private KeyGenerator keyGenerator;// 主键生成器
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;// 是否存在嵌套查询结果集
private String databaseId;
private Log statementLog;
private LanguageDriver lang;// 语言驱动,永磊解析动态或静态SQL
private String[] resultSets;// resultset
private boolean dirtySelect;
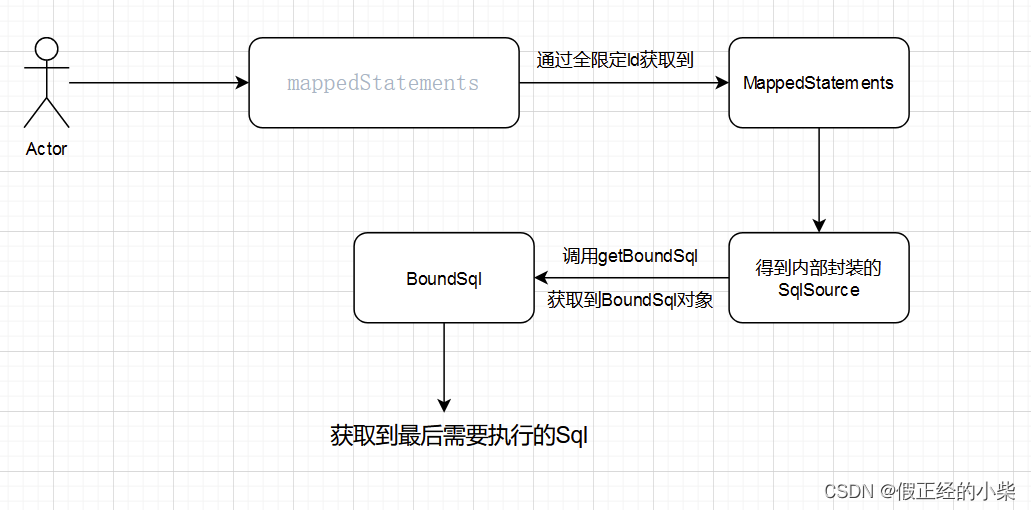
很多属性都是大伙熟知的,像 SqlSource、LanguageDriver 在我之前的博客中也有对其的源码解析,后者是对前者的获取,前者是获取最终要执行的 sql 的封装(boundsql)。【Mybatis源码分析】动态标签的底层原理,DynamicSqlSource源码分析
大概流程就如下图这样:
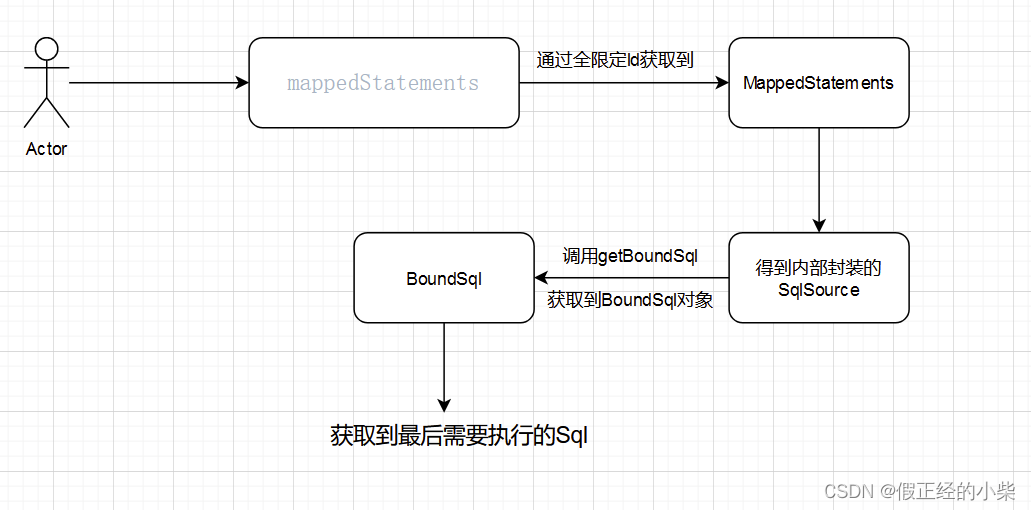
前言先到这,开始真正的源码分析。
二、语句标签的源码分析
这边的话由于是博客,不会从头到尾对源码进行分析,只对核心部分进行解析,在进行之前,先对 Mybatis 对 xml 解析时,使用到的构造器总览构个图,了解了整体对源码分析更有帮助(自身观看源码后得出来的,如有问题,评论区可以指出)。(图虽然直观,但想出来感觉太酷了,也不知道如果我来设计的话要吃几个核桃才能设计出来)
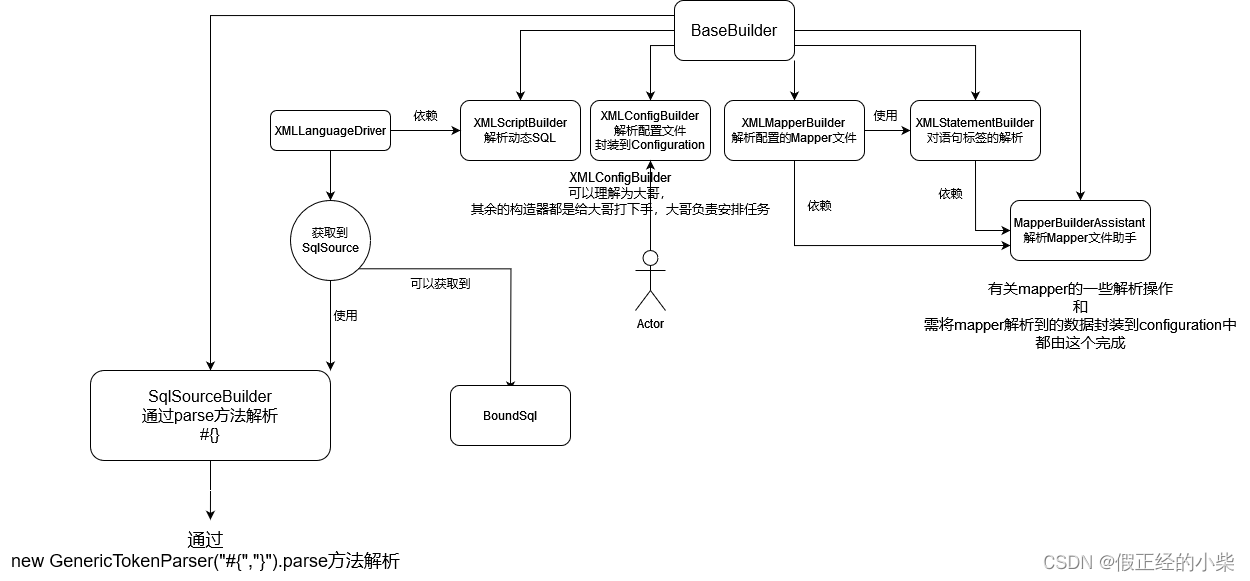
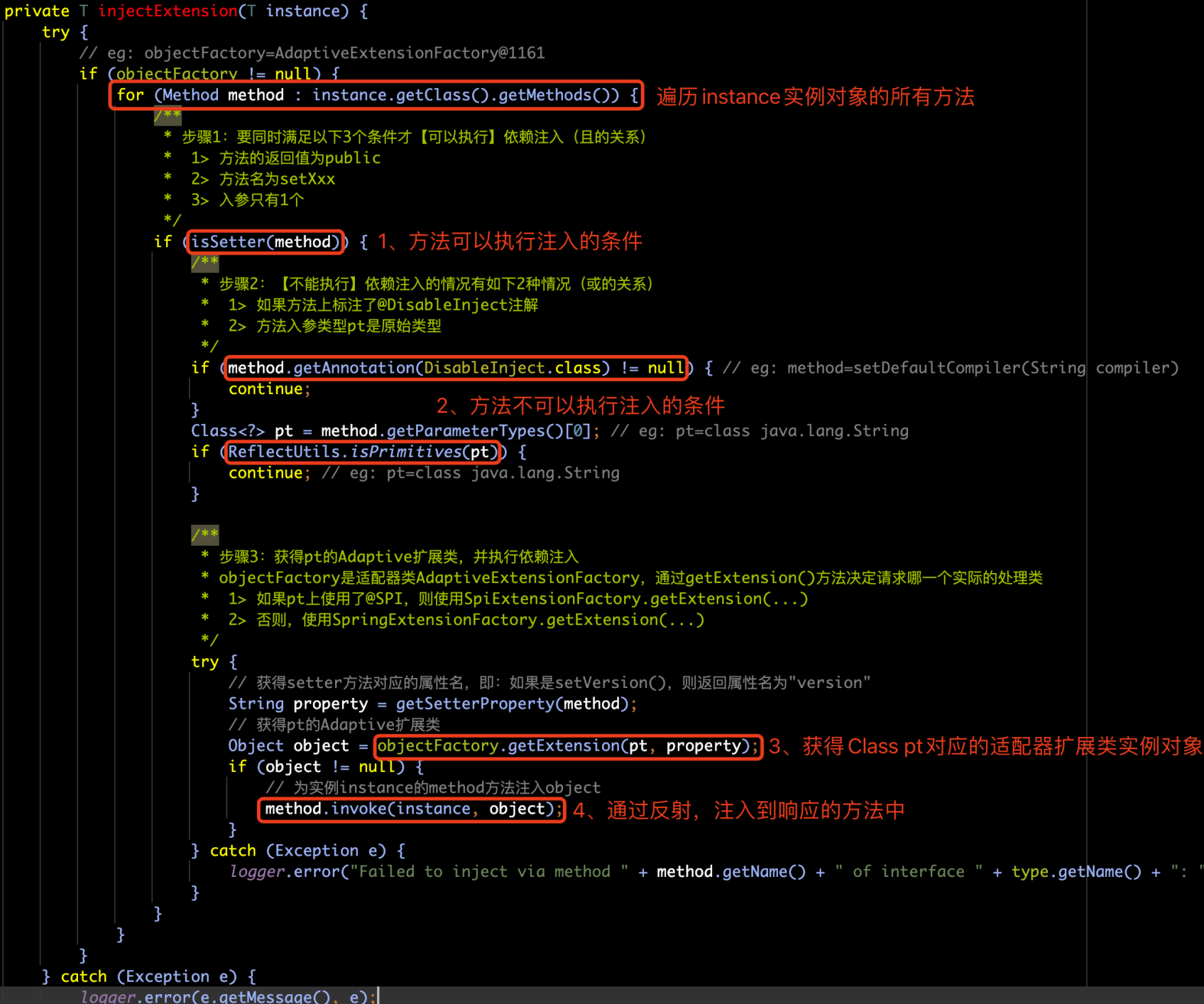
解析语句标签的核心内容在 XMLStatementBuilder.parseStatementNode 方法中,解析完标签内容然后将其通过 MapperBuilderAssistant 对象映射成 MapperStatement 然后封装到 Configuration 中的 mappedStatements 中。
核心源码如下-有删减(可以大致看看,细节或者说主要部分,下面有图片详细解释):
public void parseStatementNode() {
String id = context.getStringAttribute("id");
String nodeName = context.getNode().getNodeName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// Include Fragments before parsing
// 这是对 sql 片段的引用,在下面对 sql 标签进行了源码分析
// 这里是通过 include 标签对 sql 标签内容的引用
// 可以说是替换内容吧
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
// 这里的话可以自定义 LanguageDriver 对象然后去使用然后获取对应的 SqlSource对象
// 这里的话默认是 XMLLanguageDriver
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// 去得到最后执行语句准备使用的语句类型,默认是 PreparedStatement
StatementType statementType = StatementType
.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
String parameterMap = context.getStringAttribute("parameterMap");
// 获取返回值类型
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
String resultMap = context.getStringAttribute("resultMap");
if (resultTypeClass == null && resultMap == null) {
resultTypeClass = MapperAnnotationBuilder.getMethodReturnType(builderAssistant.getCurrentNamespace(), id);
}
// 通过助手去构建 MappedStatement,
// 并且封装进 configuration 中的 mappedStatements中
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap,
parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets, dirtySelect);
}
测试的 xml:
<sql id="person_test">
id,name,age,sex
</sql>
<select id="hhh" resultType="com.ncpowernode.mybatis.bean.Person">
select <include refid="person_test"/>
from t_person
</select>
下面我认为构建过程中几个主要的属性解析特地说明一下:
你没配置 lang 属性的话,默认就是通过 XMLLanguageDriver 进行解析的。
 按照测试的语句的话,我是没用使用动态SQL的,所以SQLSource解析结果应该是RawSQLSource对象。
按照测试的语句的话,我是没用使用动态SQL的,所以SQLSource解析结果应该是RawSQLSource对象。
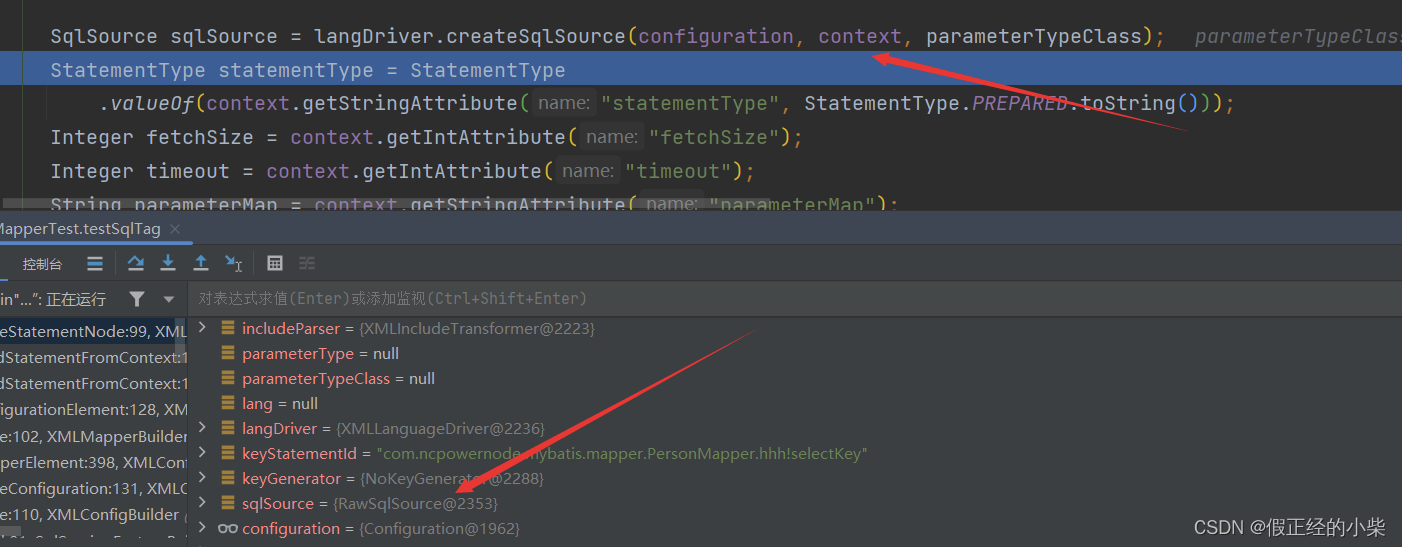
没有去指定对应的 StatementType 语句类型的话,默认就是使用 PreparedStatement。

如果是 Select 语句标签的话,需要指定 resultType 属性或 resultMap 的原因(都没指定的话,就把 namespace 指定的类当做返回对象):

而后就通过 Mapper 助手去构建 MappedStatement 对象,并且映射咯。

即通过 MappedStatement.Builder 进行构建,然后封装到 configuration 中。
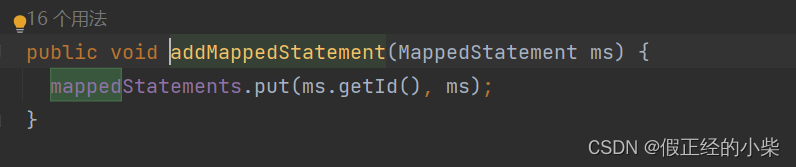
封装的话,就直接 put(全限定id,MappedStatement对象咯)
三、sql 标签的解析
测试代码如下:
<sql id="person_test">
id,name,age,sex
</sql>
<select id="hhh" resultType="com.ncpowernode.mybatis.bean.Person">
select <include refid="person_test"/>
from t_person
</select>
@Test
public void testSqlTag(){
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory sqlSessionFactory = builder.build(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatis-config.xml"));
SqlSession sqlSession = sqlSessionFactory.openSession();
PersonMapper mapper = sqlSession.getMapper(PersonMapper.class);
List<Person> xx = mapper.hhh();
}
核心解析源码如下(本质就是将 sql 片段的内容封装到 sqlFragments 这个 map 中,然后后续供语句标签里使用)
private void sqlElement(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
String databaseId = context.getStringAttribute("databaseId");
String id = context.getStringAttribute("id");
// 合并成全id,namespace.id 这种形式,全限定id
id = builderAssistant.applyCurrentNamespace(id, false);
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
sqlFragments.put(id, context);
}
}
}
四、总结
- 其实通过这些源码分析也知道了:为什么默认是使用 XMLLanguageDriver 去获取 SQLSource;为什么默认是使用 PreparedStatement 去操纵最后的 SQL;查询Select语句中,不指定resultType 、resultMap 属性行不行?行,但默认就是返回你 namespace 指定的类。
- 我们可以通过配置标签的 lang 属性,来指定对应的
LanguageDriver实现类去获取 SqlSource.当然我觉得默认的已经很棒了,这个应该用不着自己写。 - 在 mapper 文件中,使用了 sql 标签,可以使用 include 标签去使用 sql 标签中的内容。
下面我画的俩图感觉还挺形象:
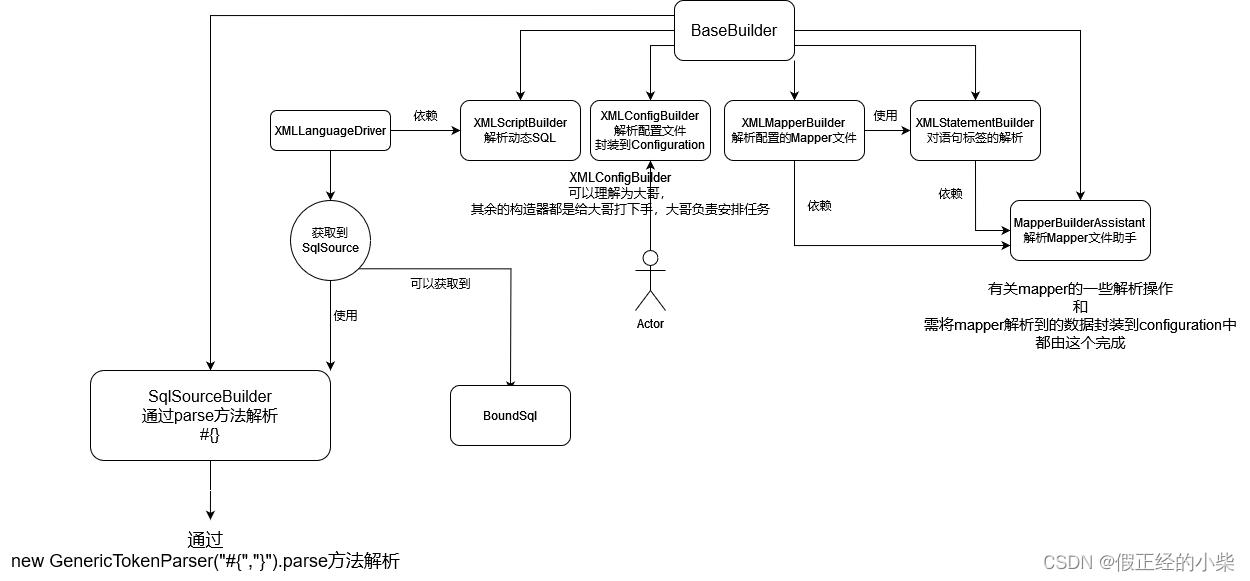
这里说点题外话:在 XMLScriptBuilder 中解析动态标签时,${} 也是被解析成动态sql,对应的动态 SQLNode 是 TextSqlNode,内部 apply 方法是通过 GenericTokenParser 解析完然后封装到 DynamicContext 中的。而解析 #{} 时是不被算作为动态 sql 的,这是因为不管是 RawSqlSource 还是 DynamicSqlSource,都会通过 SqlSourceBuilder.parse 方法对 #{} 进行处理。(在上次博客中我自己也是理解的模模糊糊,这里明确后所以再指明一下)