简介
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
1)awk命令会逐行读取文件的内容进行处理
2)awk以’:’为分隔符,将第1行数据格式化为7段,每段数据存入$1--$7变量中。$0存储这1行数据
3)一行处理完成继续处理下一行,直到此文件读取结束
awk常见用法
awk 选项 '模式或条件 { 编辑指令 }' 文件1 文件2 …
awk -f 脚本文件 文件1 文件2 …
特殊的内建变量
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
用法示例:输出
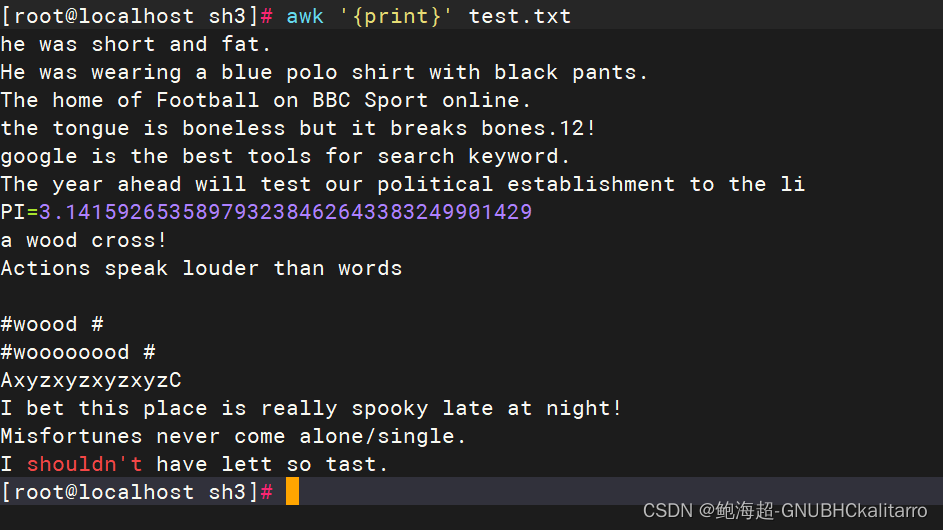
awk '{print}' test.txt
简单的输入全部
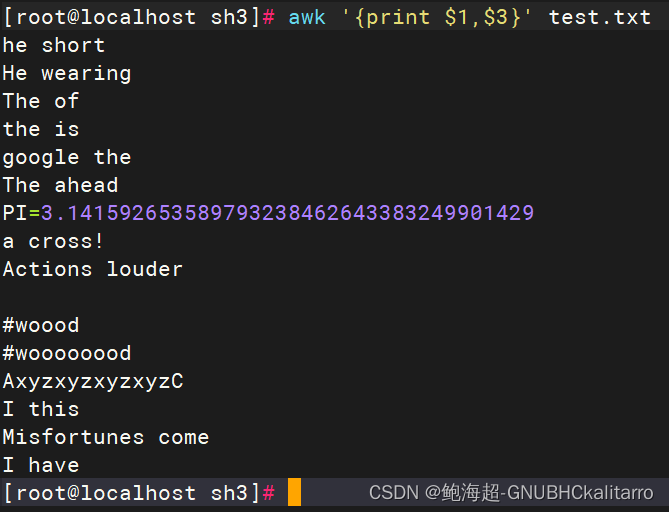
第1,3字段
awk '{print $1,$3}' test.txt
输出奇数行%2求模运算,余数为1是奇数,0为偶数
awk '(NR%2)==1{print}' test.txt
输出偶数行
awk '(NR%2)==0{print}' test.txt
输出以root开头的行
awk '/^root/{print}' /etc/passwd
输出以……结尾的行
awk '/nologin$/{print}' /etc/passwd
统计以/bin/bash结尾的行=== grep -c "/bin/bash$"
awk 'BEGIN {x=0} ; /\/bin\/bash$/{x++};END {print x}' /etc/passwd
统计以空行分割的文本段落数
awk 'BEGIN{RS=""};END{print NR}' /etc/sysctl.conf
按字段输出文本
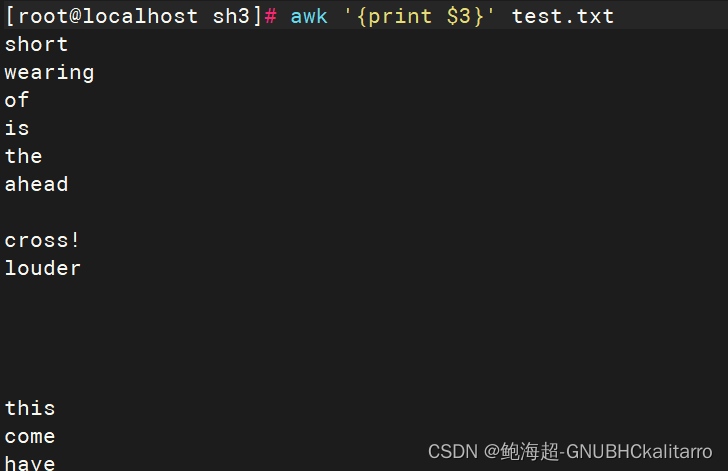
输出每行中以空格或制表位分割的第3个字段
awk '{print $3}' test.txt
密码为空的行
awk -F ":" '$2==""{print}' /etc/shadow

密码为空的行
awk 'BEGIN {FS==":"}; $2==""{print}' /etc/shadow
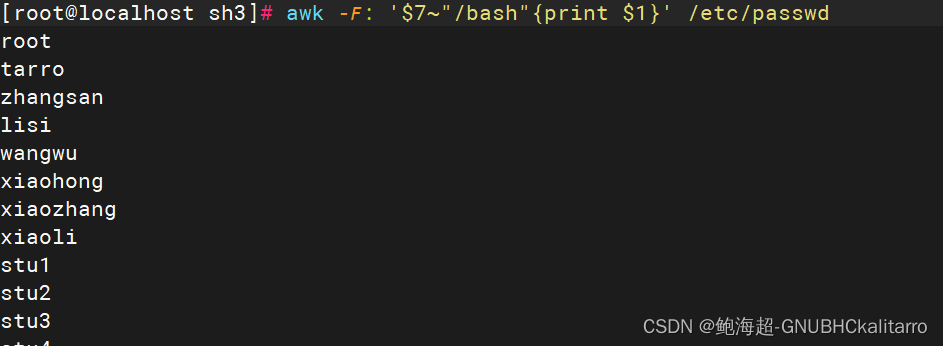
输出以‘:’分割,第7字段包含/bash,的行的第1个字段
awk -F: '$7~"/bash"{print $1}' /etc/passwd
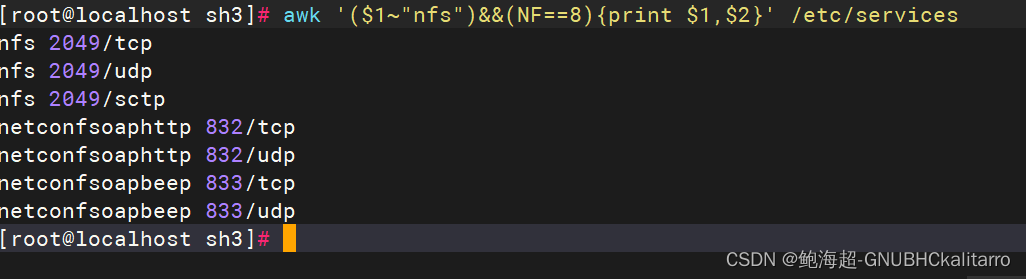
输出第1个字段包含nfs;并且包含8个字段的行的第1,2字段
awk '($1~"nfs")&&(NF==8){print $1,$2}' /etc/services
输出第7个字段不是/bin/bsh也不是/sbin/nologin的行
awk -F: '($7!="/bin/bsh")&&($7!="/sbin/nologin"){print}' /etc/passwd
通过管道、双引号调用Shell命令
调用wc -l 命令统计使用bash的用户个数
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
===等同于下列命令
grep -c "bash$" /etc/passwd
调用w命令,统计在线用户数
awk 'BEGIN {while ("w" |getline) n++; {print n-2}}'
调用hostname,并输出当前主机名
awk 'BEGIN { "hostname" |getline ; print $0}'


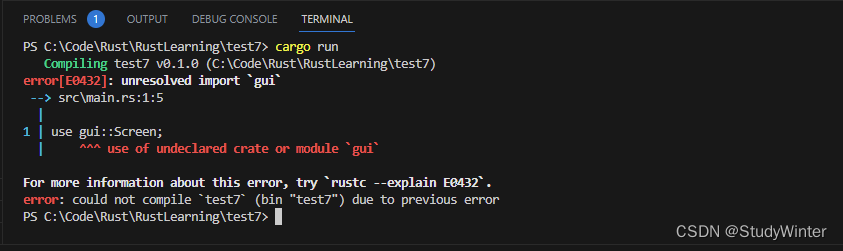


![[计算机入门] 个性化设置系统](https://img-blog.csdnimg.cn/7da324a8128846949178b42c1cd45adb.png)