范围for语句
C语言部分学习过了for语句,在C++11中for语句的能力被进一步扩展,引入了范围for语句,用于遍历一个序列。看看如下范例:
int v[]{12,13,14,16,18};
//数组ⅴ中每个元素依次放入x并打印x值。相当于把ⅴ的每个元素值复制到x中,然后打印
for (auto x : v)
{
cout << x << endl;
}
//{}中是一个元素序列,for就是应用于任意的这种元素序列
for(auto x : {11,34,56,21,34,34})
{
cout << x << endl;
}
上面范例中第一个for语句的写法有个缺点,多了一个复制的动作,也就是把数组v中的元素值依次复制(赋值)到了x中,然后循环输出x值。那如何修改一下以避免这种复制动作,提高程序运行效率呢?非常简单,只需要把for这行代码修改成如下即可:
for (auto &x : v) //使用引用的方式,避免数据的复制动作
一般来讲,一个容器只要其内部支持begin和end成员函数用于返回一个迭代器,能够指向容器的第一个元素和末端元素的后面,这种容器就可以支持范围for语句(容器后面讲)。
动态内存分配问题
在C++中,把内存进一步更详细地分成5个区域:
(1)栈。函数内的局部变量一般在这里创建,由编译器自动分配和释放。(2)堆。由程序员使用malloc/new申请,free/delete释放。malloc/new申请并使用完毕后要及时free/delete以节省系统资源,防止资源耗尽导致程序崩溃。如果程序员忘记free/delete,程序结束时会由操作系统回收这些内存。
(3)全局/静态存储区。全局变量和静态变量放这里,程序结束时释放。
(4)常量存储区。存放常量,不允许修改,如用双引号包含起来的字符串。(5)程序代码区。相当于C语言中的程序代码区。
这5个区域重点关注堆和栈,其他几个区域简单理解即可。堆和栈都相当于C语言部分所说的动态存储区,但用途不同。下面总结一下堆和栈的区别:
(1)栈空间有限(这是系统规定的),使用便捷。例如代码行inta=4;,系统就自动分配了一个4字节给变量a使用。分配速度快,程序员控制不了它的分配和释放。
(2)堆空间是程序员自由决定所分配的内存大小,大小理论上只要不超出实际拥有的物理内存即可,分配速度相对较慢,可以随时用new/malloc分配、free/delete释放,非常灵活。
下面介绍new/malloc与free/delete。
1.malloc和free
在C语言(不是C++)中,malloc和free是系统提供的函数,成对使用,用于从堆(堆空间)中分配和释放内存。malloc的全称是memoryallocation,翻译成中文含义是“动态内存分配”。一般形式为:
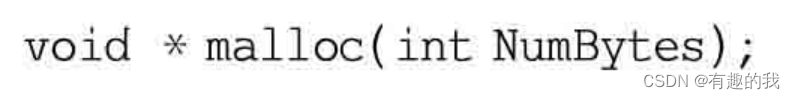
说明:malloc向系统申请分配指定NumBytes字节的内存空间。返回类型是void类型。void表示未确定类型的指针。C/C++规定,void*类型可以强制转换为任何其他类型的指针。如果分配成功则返回指向被分配内存的指针,如果分配失败则返回空指针NULL。分配成功后且当内存不再使用时,应使用free()函数将内存释放。
free函数的一般形式为:
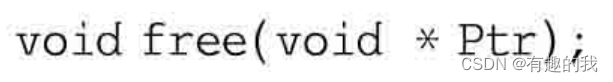
说明:该函数是将之前用malloc分配的内存空间还给程序或者操作系统,也就是释放先前分配的内存,这样这块内存就被系统回收并在需要的时候由系统自由分配出去再使用。
看看如下范例:
int *p = NULL;
p = (int*)malloc(10 * sizeof(int)); //分配了40字节
if (p != NULL)
{
*p=5; //这种写法其实只会用到分配的40字节中的4字节
cout << *p << endl;
free(p); //千万不要忘记,否则就是内存泄漏。如果泄漏多了,程序就会崩溃
}
再继续看范例:
int *p = (int*)malloc(sizeof(int)*100); //分配可以放得下100个整数的内存空间
if (p != NULL)
{
int *q = p;
*q++=1;
*q++=5;
cout << *p << endl; //1
cout << *(p+1) << endl; //5
free(p);
}
2.new和delete
new和delete是运算符,不是函数。C++中使用new和delete从堆中分配和释放内存,两者成对使用。
首先读者要理解一点,那就是new/delete做了和malloc/free同样的事情——分配和释放内存,同时,new/delete还做了更多的事情。这里先看一看,new/delete在分配内存方面的用法。new一般使用格式有如下几种:

看看如下范例:
int * myint = new int;
if (myint != NULL) //其实如果new失败可能不会返回NULL,而是直接报异常
{
*myint = 8; //myint代表指针指向的变量
cout << *myint << endl; //8
delete myint; //释放
}
再继续看范例:
int * myint = new int(18); //分配内存同时将该内存空间的内容设置为18
if (myint != NULL)
{
*myint = 8; //myint代表指针指向的变量
cout << *myint << endl; //8
delete myint; //释放
}
再继续看范例:
int* a = new int[100]; //开辟一个大小为100的整型数组空间
if (a != NULL)
{
int * p = a;
*p++=12;
*p++=18;
cout << *a << endl; //12
cout << *(a + 1) << endl; //18
//new时用了[],delete时就要用[],否则回收的内存就是第一个数组元素空间而不是整个数
//组,[]起了回收整个数组的作用,delete中[]内不用写数组中元素个数,保持空着,系统有办
//法知道这个数组大小,写了数字也会被系统忽略
delete[] a; //释放int数组空间
}
有几点说明:
(1)配对使用,有malloc成功必有free,有new成功必有delete。
(2)free/delete不要重复调用,因为free/delete的内存可能被系统立即回收后再利用,再free/delete一次很可能把不是自己的空间释放掉了,导致程序运行出现异常甚至崩溃。
nullptr
nullptr是C++11引入的新关键字,代表“空指针”。
看看如下范例:
char* p = NULL; //NULL实际就是0
char* q = nullptr; //设置断点观察发现p和q都是0x00000000,似乎都一样
int *a = nullptr;
if (p == nullptr)
//条件成立
{
cout << "nullo" << endl;
}
有资料指出:使用nullptr能够避免在整数和指针之间发生混淆。但笔者认为这句话说得有点模棱两可。看看下面的演示范例:
cout << typeid(NULL).name()<< endl; //int
cout << typeid(nullptr).name()<< endl; //std:nullptr_t
上面范例中,typeid先不深入解释,后面章节会详细学习,这里只理解成“用于取类型”。然后.name()可以打印出类型名,通过结果可以看到,NULL和nullptr两者的类型是不同的。
在后面学习函数重载时,因为NULL和nullptr类型不同,所以如果把这两者当函数实参传递到函数中去,则会导致因为实参类型不同而调用不同的重载函数。看看如下范例:

给出一些结论:(1)对于指针的初始化,能用nullptr的全部用nullptr。(2)以往用到的与指针有关的NULL的场合,能用nullptr取代的全部用nullptr取代。






![[计算机入门] 个性化设置系统](https://img-blog.csdnimg.cn/7da324a8128846949178b42c1cd45adb.png)