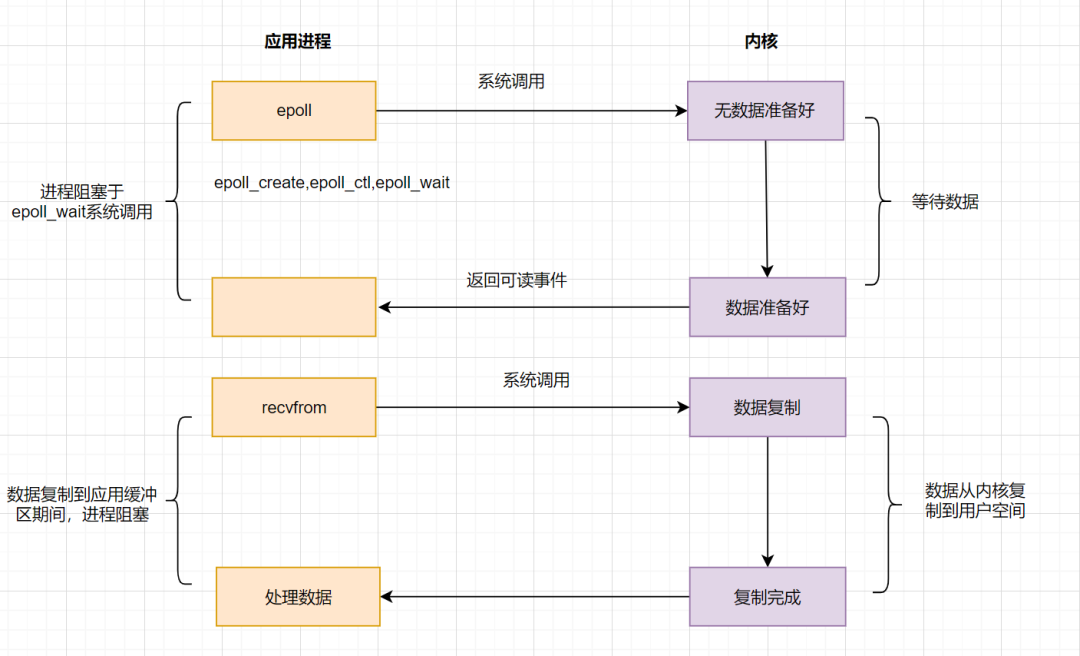
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']# Load all sheets of the Excel file
xl_file = pd.ExcelFile("E:\\数学建模国赛\\2022数学建模赛题\\C题\\附件.xlsx")# Load individual sheets with correct names
sheet1 = xl_file.parse('表单1')# 玻璃文物的基本信息
sheet2 = xl_file.parse('表单2')# 已分类玻璃文物的化学成分比例
sheet3 = xl_file.parse('表单3')# 未分类玻璃文物的化学成分比例# Show the first few rows of each sheet
sheet1.head(), sheet2.head(), sheet3.head()
( 文物编号 纹饰 类型 颜色 表面风化
0 1 C 高钾 蓝绿 无风化
1 2 A 铅钡 浅蓝 风化
2 3 A 高钾 蓝绿 无风化
3 4 A 高钾 蓝绿 无风化
4 5 A 高钾 蓝绿 无风化,
文物采样点 二氧化硅(SiO2) 氧化钠(Na2O) 氧化钾(K2O) 氧化钙(CaO) 氧化镁(MgO) 氧化铝(Al2O3) \
0 01 69.33 NaN 9.99 6.32 0.87 3.93
1 02 36.28 NaN 1.05 2.34 1.18 5.73
2 03部位1 87.05 NaN 5.19 2.01 NaN 4.06
3 03部位2 61.71 NaN 12.37 5.87 1.11 5.50
4 04 65.88 NaN 9.67 7.12 1.56 6.44
氧化铁(Fe2O3) 氧化铜(CuO) 氧化铅(PbO) 氧化钡(BaO) 五氧化二磷(P2O5) 氧化锶(SrO) 氧化锡(SnO2) \
0 1.74 3.87 NaN NaN 1.17 NaN NaN
1 1.86 0.26 47.43 NaN 3.57 0.19 NaN
2 NaN 0.78 0.25 NaN 0.66 NaN NaN
3 2.16 5.09 1.41 2.86 0.70 0.10 NaN
4 2.06 2.18 NaN NaN 0.79 NaN NaN
二氧化硫(SO2)
0 0.39
1 NaN
2 NaN
3 NaN
4 0.36 ,
文物编号 表面风化 二氧化硅(SiO2) 氧化钠(Na2O) 氧化钾(K2O) 氧化钙(CaO) 氧化镁(MgO) 氧化铝(Al2O3) \
0 A1 无风化 78.45 NaN NaN 6.08 1.86 7.23
1 A2 风化 37.75 NaN NaN 7.63 NaN 2.33
2 A3 无风化 31.95 NaN 1.36 7.19 0.81 2.93
3 A4 无风化 35.47 NaN 0.79 2.89 1.05 7.07
4 A5 风化 64.29 1.2 0.37 1.64 2.34 12.75
氧化铁(Fe2O3) 氧化铜(CuO) 氧化铅(PbO) 氧化钡(BaO) 五氧化二磷(P2O5) 氧化锶(SrO) 氧化锡(SnO2) \
0 2.15 2.11 NaN NaN 1.06 0.03 NaN
1 NaN NaN 34.30 NaN 14.27 NaN NaN
2 7.06 0.21 39.58 4.69 2.68 0.52 NaN
3 6.45 0.96 24.28 8.31 8.45 0.28 NaN
4 0.81 0.94 12.23 2.16 0.19 0.21 0.49
二氧化硫(SO2)
0 0.51
1 NaN
2 NaN
3 NaN
4 NaN )
# Normalize the chemical components to sum up to 100%
sheet2[component_cols]= sheet2[component_cols].div(sheet2[component_cols].sum(axis=1), axis=0)*100
sheet2 ['成分总和']= sheet2 [component_cols].sum(axis=1)
sheet2
文物采样点
二氧化硅(SiO2)
氧化钠(Na2O)
氧化钾(K2O)
氧化钙(CaO)
氧化镁(MgO)
氧化铝(Al2O3)
氧化铁(Fe2O3)
氧化铜(CuO)
氧化铅(PbO)
氧化钡(BaO)
五氧化二磷(P2O5)
氧化锶(SrO)
氧化锡(SnO2)
二氧化硫(SO2)
成分总和
0
01
71.027559
0.000000
10.234607
6.474746
0.891302
4.026227
1.782604
3.964758
0.000000
0.000000
1.198648
0.000000
0.0
0.399549
100.0
1
02
36.319952
0.000000
1.051156
2.342577
1.181299
5.736310
1.862048
0.260286
47.482230
0.000000
3.573931
0.190209
0.0
0.000000
100.0
2
03部位1
87.050000
0.000000
5.190000
2.010000
0.000000
4.060000
0.000000
0.780000
0.250000
0.000000
0.660000
0.000000
0.0
0.000000
100.0
3
03部位2
62.408981
0.000000
12.510113
5.936489
1.122573
5.562298
2.184466
5.147654
1.425971
2.892395
0.707929
0.101133
0.0
0.000000
100.0
4
04
68.582136
0.000000
10.066625
7.412034
1.623985
6.704143
2.144493
2.269415
0.000000
0.000000
0.822403
0.000000
0.0
0.374766
100.0
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
64
54严重风化点
17.653735
0.000000
0.000000
0.000000
1.145274
3.765993
0.000000
1.382584
60.317788
0.000000
14.579034
1.155592
0.0
0.000000
100.0
65
55
50.850799
2.811787
0.000000
1.172442
0.000000
1.504462
0.000000
0.892301
34.156464
8.248599
0.363146
0.000000
0.0
0.000000
100.0
66
56
31.602342
0.000000
0.000000
1.311795
0.000000
2.005637
0.000000
0.856461
44.720295
16.749783
2.753686
0.000000
0.0
0.000000
100.0
67
57
27.489997
0.000000
0.000000
1.416676
0.000000
2.357521
0.000000
1.254461
48.772575
18.708770
0.000000
0.000000
0.0
0.000000
100.0
68
58
30.771567
0.000000
0.344269
3.533819
0.799919
3.564196
0.870798
3.169299
39.844066
7.756177
9.102876
0.243013
0.0
0.000000
100.0
67 rows × 16 columns
sheet2_copy = sheet2.copy()
sheet2=sheet2_copy
# Define the new column names
new_component_cols =['SiO2','Na2O','K2O','CaO','MgO','Al2O3','Fe2O3','CuO','PbO','BaO','P2O5','SrO','SnO2','SO2']# Create a mapping from old column names to new column names
rename_dict =dict(zip(component_cols, new_component_cols))# Rename the columns
sheet2.rename(columns=rename_dict, inplace=True)# Check the updated column names
sheet2.columns
# Merge sheet1 and sheet2 on 文物编号 (artifact number)# First, we need to extract the 文物编号 from the 文物采样点 in sheet2# We assume that the 文物编号 is the numeric part before any non-numeric character in the 文物采样点# Import regular expression libraryimport re
# Define a function to extract 文物编号 from 文物采样点defextract_number(s):match= re.match(r"(\d+)", s)returnint(match.group())ifmatchelseNone# Apply the function to the 文物采样点 column
sheet2['文物编号']= sheet2['文物采样点'].apply(extract_number)# Merge sheet1 and sheet2
data = pd.merge(sheet1, sheet2, on='文物编号')# nan for zero
data
文物编号
纹饰
类型
颜色
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
...
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
成分总和
0
1
C
高钾
蓝绿
无风化
01
71.027559
0.000000
10.234607
6.474746
...
4.026227
1.782604
3.964758
0.000000
0.000000
1.198648
0.000000
0.0
0.399549
100.0
1
2
A
铅钡
浅蓝
风化
02
36.319952
0.000000
1.051156
2.342577
...
5.736310
1.862048
0.260286
47.482230
0.000000
3.573931
0.190209
0.0
0.000000
100.0
2
3
A
高钾
蓝绿
无风化
03部位1
87.050000
0.000000
5.190000
2.010000
...
4.060000
0.000000
0.780000
0.250000
0.000000
0.660000
0.000000
0.0
0.000000
100.0
3
3
A
高钾
蓝绿
无风化
03部位2
62.408981
0.000000
12.510113
5.936489
...
5.562298
2.184466
5.147654
1.425971
2.892395
0.707929
0.101133
0.0
0.000000
100.0
4
4
A
高钾
蓝绿
无风化
04
68.582136
0.000000
10.066625
7.412034
...
6.704143
2.144493
2.269415
0.000000
0.000000
0.822403
0.000000
0.0
0.374766
100.0
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
62
54
C
铅钡
浅蓝
风化
54严重风化点
17.653735
0.000000
0.000000
0.000000
...
3.765993
0.000000
1.382584
60.317788
0.000000
14.579034
1.155592
0.0
0.000000
100.0
63
55
C
铅钡
绿
无风化
55
50.850799
2.811787
0.000000
1.172442
...
1.504462
0.000000
0.892301
34.156464
8.248599
0.363146
0.000000
0.0
0.000000
100.0
64
56
C
铅钡
蓝绿
风化
56
31.602342
0.000000
0.000000
1.311795
...
2.005637
0.000000
0.856461
44.720295
16.749783
2.753686
0.000000
0.0
0.000000
100.0
65
57
C
铅钡
蓝绿
风化
57
27.489997
0.000000
0.000000
1.416676
...
2.357521
0.000000
1.254461
48.772575
18.708770
0.000000
0.000000
0.0
0.000000
100.0
66
58
C
铅钡
NaN
风化
58
30.771567
0.000000
0.344269
3.533819
...
3.564196
0.870798
3.169299
39.844066
7.756177
9.102876
0.243013
0.0
0.000000
100.0
67 rows × 21 columns
data.drop(['颜色','纹饰','文物编号','成分总和'],axis=1,inplace=True)
data
"""
对于某些统计分析,如回归分析,数据的正态性是一种关键的假设。
然而,是否需要进行这种变换取决于数据本身的特性和分析目标。
现在,让我们查看一下数据
对于您的数据,考虑到它是化学成分数据,并且从前面的分析中我们看到数据的分布并不完全是正态的,
我建议在中心化对数比变换后进行分析。这样可以确保数据满足统计分析的假设,并能更好地处理组成数据的特性。
"""# 正态性检验,查看一下这些化学元素的分布。import matplotlib.pyplot as plt
# Select only the columns that are numeric and not categorical
numeric_cols = data.select_dtypes(include='number').columns
2.2.1数据的正态性检验效果图
# Plot histograms for each numeric column
fig, axs = plt.subplots(len(numeric_cols), figsize=(10,len(numeric_cols)*3))for i, col inenumerate(numeric_cols):
axs[i].hist(data[col].dropna(), bins=30, color='skyblue', edgecolor='black', alpha=0.7)
axs[i].set_title(f'Histogram of {col}')
plt.tight_layout()
plt.show()
data_raw=data.copy()
data
类型
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
MgO
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
0
高钾
无风化
01
71.027559
0.000000
10.234607
6.474746
0.891302
4.026227
1.782604
3.964758
0.000000
0.000000
1.198648
0.000000
0.0
0.399549
1
铅钡
风化
02
36.319952
0.000000
1.051156
2.342577
1.181299
5.736310
1.862048
0.260286
47.482230
0.000000
3.573931
0.190209
0.0
0.000000
2
高钾
无风化
03部位1
87.050000
0.000000
5.190000
2.010000
0.000000
4.060000
0.000000
0.780000
0.250000
0.000000
0.660000
0.000000
0.0
0.000000
3
高钾
无风化
03部位2
62.408981
0.000000
12.510113
5.936489
1.122573
5.562298
2.184466
5.147654
1.425971
2.892395
0.707929
0.101133
0.0
0.000000
4
高钾
无风化
04
68.582136
0.000000
10.066625
7.412034
1.623985
6.704143
2.144493
2.269415
0.000000
0.000000
0.822403
0.000000
0.0
0.374766
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
62
铅钡
风化
54严重风化点
17.653735
0.000000
0.000000
0.000000
1.145274
3.765993
0.000000
1.382584
60.317788
0.000000
14.579034
1.155592
0.0
0.000000
63
铅钡
无风化
55
50.850799
2.811787
0.000000
1.172442
0.000000
1.504462
0.000000
0.892301
34.156464
8.248599
0.363146
0.000000
0.0
0.000000
64
铅钡
风化
56
31.602342
0.000000
0.000000
1.311795
0.000000
2.005637
0.000000
0.856461
44.720295
16.749783
2.753686
0.000000
0.0
0.000000
65
铅钡
风化
57
27.489997
0.000000
0.000000
1.416676
0.000000
2.357521
0.000000
1.254461
48.772575
18.708770
0.000000
0.000000
0.0
0.000000
66
铅钡
风化
58
30.771567
0.000000
0.344269
3.533819
0.799919
3.564196
0.870798
3.169299
39.844066
7.756177
9.102876
0.243013
0.0
0.000000
67 rows × 17 columns
"""
正态性检验,们将使用 Shapiro-Wilk 测试来检查每个化学成分的正态性。
这是一种常用的正态性检验方法,它的零假设是数据来自正态分布。
如果 p 值小于 0.05,我们将拒绝零假设,即认为数据不符合正态分布。
"""from scipy.stats import shapiro, levene
# Initialize an empty dataframe to store the test results
test_results = pd.DataFrame()# Loop over each numeric columnfor col in numeric_cols[0:]:# Initialize an empty dict to store the results for this variable
col_results ={'Variable': col}# Normality test# Drop NA values before performing the test
_, p_normal = shapiro(data[col].dropna())
col_results['Normality p-value']= p_normal
col_results['Normal']= p_normal >0.05# Variance equality test (only if the data is normal)if col_results['Normal']:
_, p_equal_var = levene(data.loc[data['表面风化']=='无风化', col].dropna(),
data.loc[data['表面风化']=='风化', col].dropna())
col_results['Equal var p-value']= p_equal_var
col_results['Equal var']= p_equal_var >0.05# Append the results to the dataframe
test_results = test_results.append(col_results, ignore_index=True)# Now, the test_results dataframe contains the p-values for normality and equal variances# for each numeric variable, without any transformation applied to the data.
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
C:\Users\chen'bu'rong\AppData\Local\Temp\ipykernel_15024\777781528.py:30: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
test_results = test_results.append(col_results, ignore_index=True)
test_results
Variable
Normality p-value
Normal
Equal var p-value
Equal var
0
SiO2
5.434923e-02
True
0.009129
False
1
Na2O
5.631047e-13
False
NaN
NaN
2
K2O
2.218287e-13
False
NaN
NaN
3
CaO
8.905178e-06
False
NaN
NaN
4
MgO
1.066307e-05
False
NaN
NaN
5
Al2O3
1.085733e-06
False
NaN
NaN
6
Fe2O3
1.809425e-09
False
NaN
NaN
7
CuO
3.633815e-09
False
NaN
NaN
8
PbO
7.531955e-04
False
NaN
NaN
9
BaO
7.773099e-08
False
NaN
NaN
10
P2O5
4.346846e-09
False
NaN
NaN
11
SrO
6.648307e-06
False
NaN
NaN
12
SnO2
8.658932e-17
False
NaN
NaN
13
SO2
5.878219e-17
False
NaN
NaN
data
类型
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
MgO
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
0
高钾
无风化
01
71.027559
0.000000
10.234607
6.474746
0.891302
4.026227
1.782604
3.964758
0.000000
0.000000
1.198648
0.000000
0.0
0.399549
1
铅钡
风化
02
36.319952
0.000000
1.051156
2.342577
1.181299
5.736310
1.862048
0.260286
47.482230
0.000000
3.573931
0.190209
0.0
0.000000
2
高钾
无风化
03部位1
87.050000
0.000000
5.190000
2.010000
0.000000
4.060000
0.000000
0.780000
0.250000
0.000000
0.660000
0.000000
0.0
0.000000
3
高钾
无风化
03部位2
62.408981
0.000000
12.510113
5.936489
1.122573
5.562298
2.184466
5.147654
1.425971
2.892395
0.707929
0.101133
0.0
0.000000
4
高钾
无风化
04
68.582136
0.000000
10.066625
7.412034
1.623985
6.704143
2.144493
2.269415
0.000000
0.000000
0.822403
0.000000
0.0
0.374766
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
62
铅钡
风化
54严重风化点
17.653735
0.000000
0.000000
0.000000
1.145274
3.765993
0.000000
1.382584
60.317788
0.000000
14.579034
1.155592
0.0
0.000000
63
铅钡
无风化
55
50.850799
2.811787
0.000000
1.172442
0.000000
1.504462
0.000000
0.892301
34.156464
8.248599
0.363146
0.000000
0.0
0.000000
64
铅钡
风化
56
31.602342
0.000000
0.000000
1.311795
0.000000
2.005637
0.000000
0.856461
44.720295
16.749783
2.753686
0.000000
0.0
0.000000
65
铅钡
风化
57
27.489997
0.000000
0.000000
1.416676
0.000000
2.357521
0.000000
1.254461
48.772575
18.708770
0.000000
0.000000
0.0
0.000000
66
铅钡
风化
58
30.771567
0.000000
0.344269
3.533819
0.799919
3.564196
0.870798
3.169299
39.844066
7.756177
9.102876
0.243013
0.0
0.000000
67 rows × 17 columns
2.3不满足正态性,进行中心化对数比变换
from scipy.stats.mstats import gmean
data_centralized = data.copy()# 选择数值列
numeric_data = data_centralized.select_dtypes(include='number')# 计算每一行的非零元素的几何均值
geo_means =[]for index, row in numeric_data.iterrows():
non_zero_values = row[row >0]
geo_mean = gmean(non_zero_values)iflen(non_zero_values)>0else1e-6
geo_means.append(geo_mean)# 将每个值除以其所在行的非零元素的几何均值,并取对数for col in numeric_data.columns:
data_centralized[col]= np.log(numeric_data[col]/ geo_means)
data_centralized.head()
D:\py1.1\envs\pytorch\lib\site-packages\pandas\core\arraylike.py:402: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
类型
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
MgO
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
0
高钾
无风化
01
3.045978
-inf
1.108685
0.650820
-1.332161
0.175740
-0.639014
0.160355
-inf
-inf
-1.035896
-inf
-inf
-2.134508
1
铅钡
风化
02
2.676664
-inf
-0.865813
-0.064452
-0.749089
0.831113
-0.294026
-2.261677
2.944652
-inf
0.357963
-2.575334
-inf
-inf
2
高钾
无风化
03部位1
3.586159
-inf
0.766410
-0.182189
-inf
0.520860
-inf
-1.128785
-2.266618
-inf
-1.295839
-inf
-inf
-inf
3
高钾
无风化
03部位2
3.090699
-inf
1.483527
0.738107
-0.927387
0.673001
-0.261639
0.595531
-0.688158
0.019074
-1.388422
-3.334332
-inf
-inf
4
高钾
无风化
04
2.968764
-inf
1.049957
0.743836
-0.774386
0.643457
-0.496365
-0.439747
-inf
-inf
-1.454794
-inf
-inf
-2.240723
2.3.1 核心步骤-inf用0值替换
# Replace -inf values with NaN for visualization purposes#plt.rcParams['font.family'] = 'DejaVu Sans'
selected_cols=new_component_cols
data_centralized.replace(-np.inf,0, inplace=True)
data_centralized
类型
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
MgO
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
0
高钾
无风化
01
3.045978
0.000000
1.108685
0.650820
-1.332161
0.175740
-0.639014
0.160355
0.000000
0.000000
-1.035896
0.000000
0.0
-2.134508
1
铅钡
风化
02
2.676664
0.000000
-0.865813
-0.064452
-0.749089
0.831113
-0.294026
-2.261677
2.944652
0.000000
0.357963
-2.575334
0.0
0.000000
2
高钾
无风化
03部位1
3.586159
0.000000
0.766410
-0.182189
0.000000
0.520860
0.000000
-1.128785
-2.266618
0.000000
-1.295839
0.000000
0.0
0.000000
3
高钾
无风化
03部位2
3.090699
0.000000
1.483527
0.738107
-0.927387
0.673001
-0.261639
0.595531
-0.688158
0.019074
-1.388422
-3.334332
0.0
0.000000
4
高钾
无风化
04
2.968764
0.000000
1.049957
0.743836
-0.774386
0.643457
-0.496365
-0.439747
0.000000
0.000000
-1.454794
0.000000
0.0
-2.240723
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
62
铅钡
风化
54严重风化点
1.216607
0.000000
0.000000
0.000000
-1.518696
-0.328329
0.000000
-1.330386
2.445287
0.000000
1.025244
-1.509727
0.0
0.000000
63
铅钡
无风化
55
2.673354
-0.221722
0.000000
-1.096453
0.000000
-0.847107
0.000000
-1.369493
2.275410
0.854502
-2.268492
0.000000
0.0
0.000000
64
铅钡
风化
56
1.753603
0.000000
0.000000
-1.428231
0.000000
-1.003666
0.000000
-1.854574
2.100799
1.118757
-0.686688
0.000000
0.0
0.000000
65
铅钡
风化
57
1.386720
0.000000
0.000000
-1.578789
0.000000
-1.069491
0.000000
-1.700396
1.960066
1.001890
0.000000
0.000000
0.0
0.000000
66
铅钡
风化
58
2.316326
0.000000
-2.176597
0.152115
-1.333510
0.160674
-1.248610
0.043246
2.574709
0.938225
1.098326
-2.524904
0.0
0.000000
67 rows × 17 columns
data
类型
表面风化
文物采样点
SiO2
Na2O
K2O
CaO
MgO
Al2O3
Fe2O3
CuO
PbO
BaO
P2O5
SrO
SnO2
SO2
0
高钾
无风化
01
71.027559
0.000000
10.234607
6.474746
0.891302
4.026227
1.782604
3.964758
0.000000
0.000000
1.198648
0.000000
0.0
0.399549
1
铅钡
风化
02
36.319952
0.000000
1.051156
2.342577
1.181299
5.736310
1.862048
0.260286
47.482230
0.000000
3.573931
0.190209
0.0
0.000000
2
高钾
无风化
03部位1
87.050000
0.000000
5.190000
2.010000
0.000000
4.060000
0.000000
0.780000
0.250000
0.000000
0.660000
0.000000
0.0
0.000000
3
高钾
无风化
03部位2
62.408981
0.000000
12.510113
5.936489
1.122573
5.562298
2.184466
5.147654
1.425971
2.892395
0.707929
0.101133
0.0
0.000000
4
高钾
无风化
04
68.582136
0.000000
10.066625
7.412034
1.623985
6.704143
2.144493
2.269415
0.000000
0.000000
0.822403
0.000000
0.0
0.374766
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
62
铅钡
风化
54严重风化点
17.653735
0.000000
0.000000
0.000000
1.145274
3.765993
0.000000
1.382584
60.317788
0.000000
14.579034
1.155592
0.0
0.000000
63
铅钡
无风化
55
50.850799
2.811787
0.000000
1.172442
0.000000
1.504462
0.000000
0.892301
34.156464
8.248599
0.363146
0.000000
0.0
0.000000
64
铅钡
风化
56
31.602342
0.000000
0.000000
1.311795
0.000000
2.005637
0.000000
0.856461
44.720295
16.749783
2.753686
0.000000
0.0
0.000000
65
铅钡
风化
57
27.489997
0.000000
0.000000
1.416676
0.000000
2.357521
0.000000
1.254461
48.772575
18.708770
0.000000
0.000000
0.0
0.000000
66
铅钡
风化
58
30.771567
0.000000
0.344269
3.533819
0.799919
3.564196
0.870798
3.169299
39.844066
7.756177
9.102876
0.243013
0.0
0.000000
67 rows × 17 columns
2.3.2中心化对数比变换效果图
# Visual comparison between raw data and centralized log ratio transformed data for selected columns
plt.rcParams['font.family']='DejaVu Sans'
fig, axs = plt.subplots(len(selected_cols),2, figsize=(15,len(selected_cols)*3))for i, col inenumerate(selected_cols):# Plot raw data
axs[i,0].hist(data_raw[col].dropna(), bins=30, color='skyblue', edgecolor='black', alpha=0.7)
axs[i,0].set_title(f'Raw data: {col}')# Plot centralized log ratio transformed data
axs[i,1].hist(data_centralized[col].dropna(), bins=30, color='salmon', edgecolor='black', alpha=0.7)
axs[i,1].set_title(f'Centralized Log Ratio: {col}')
plt.tight_layout()
plt.show()
data=data_centralized
# Count the unique values in the '类型' and '表面风化' columns
glass_types = data['类型'].unique()
weathering_states = data['表面风化'].unique()
glass_types, weathering_states
# Initialize an empty DataFrame to store the results
grouped_stats = pd.DataFrame()
component_cols =['SiO2','Na2O','K2O','CaO','MgO','Al2O3','Fe2O3','CuO','PbO','BaO','P2O5','SrO','SnO2','SO2']# Calculate descriptive statistics for each chemical componentfor component in component_cols:
component_data = data.groupby(['类型','表面风化'])[component]
stats = component_data.agg(['mean','max','min','std','var','skew'])
stats['kurt']= component_data.apply(pd.DataFrame.kurt)
stats['cv']= stats['std']/ stats['mean']# calculate coefficient of variation# Add a level to column names
stats.columns = pd.MultiIndex.from_product([[component], stats.columns])
grouped_stats = pd.concat([grouped_stats, stats], axis=1)
grouped_stats
SiO2
Na2O
...
SnO2
SO2
mean
max
min
std
var
skew
kurt
cv
mean
max
...
kurt
cv
mean
max
min
std
var
skew
kurt
cv
类型
表面风化
铅钡
无风化
3.013743
3.871521
1.859524
0.646195
0.417567
-0.301305
-0.956815
0.214416
0.071131
0.876318
...
3.253187
-2.441987
0.020569
0.267396
0.000000
0.074162
0.005500
3.605551
13.000000
3.605551
风化
2.242329
3.937307
-0.131353
0.923780
0.853370
-0.584811
0.650707
0.411973
0.013371
1.043858
...
13.632917
-3.664983
0.028021
1.369229
-0.796562
0.336451
0.113199
2.108909
9.857280
12.007019
高钾
无风化
3.165687
3.712288
2.266609
0.363205
0.131918
-1.093726
3.036563
0.114732
-0.013585
0.320182
...
12.000000
-3.464102
-0.507620
0.000000
-2.240723
0.925901
0.857292
-1.388056
-0.011455
-1.824002
风化
4.187045
4.372977
3.830498
0.187388
0.035114
-1.731995
3.641136
0.044754
0.000000
0.000000
...
0.000000
NaN
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
NaN
4 rows × 112 columns
# Adjusting the code to avoid renaming columns, instead we will capture the group information in the DataFrame index
tables_dict ={}for glass_type in glass_types:for weathering_state in weathering_states:
subset = grouped_stats.loc[glass_type, weathering_state].unstack().T
table_name =f"{glass_type}_{weathering_state}"
tables_dict[table_name]= pd.DataFrame(subset)# 显式地转换为pd.DataFrame# Looping through the tables_dict and outputting each DataFrame
tables_dict
'''
with pd.ExcelWriter('E:\\数学建模国赛\\2022数学建模赛题\\C题\\一二表单合并数据统计性分析.xlsx') as writer:
for sheet_name, df in tables_dict.items():
df.to_excel(writer, sheet_name=sheet_name,index=True)
'''
"\nwith pd.ExcelWriter('E:\\数学建模国赛\\2022数学建模赛题\\C题\\一二表单合并数据统计性分析.xlsx') as writer:\n for sheet_name, df in tables_dict.items():\n df.to_excel(writer, sheet_name=sheet_name,index=True)\n"
import matplotlib.pyplot as plt # or another font that supports the special characterimport seaborn as sns
plt.rcParams['font.family']='DejaVu Sans'# Correct the condition for each DataFrame
data_high_potassium_erosion = data[(data['类型']=='高钾')&(data['表面风化']=='风化')]
data_high_potassium_no_erosion = data[(data['类型']=='高钾')&(data['表面风化']=='无风化')]
data_lead_barium_erosion = data[(data['类型']=='铅钡')&(data['表面风化']=='风化')]
data_lead_barium_no_erosion = data[(data['类型']=='铅钡')&(data['表面风化']=='无风化')]# Create a new DataFrame for boxplot
boxplot_data_high_potassium_erosion = data_high_potassium_erosion.melt(id_vars=['类型','表面风化'], value_vars=component_cols)
boxplot_data_high_potassium_no_erosion = data_high_potassium_no_erosion.melt(id_vars=['类型','表面风化'], value_vars=component_cols)
boxplot_data_lead_barium_erosion = data_lead_barium_erosion.melt(id_vars=['类型','表面风化'], value_vars=component_cols)
boxplot_data_lead_barium_no_erosion = data_lead_barium_no_erosion.melt(id_vars=['类型','表面风化'], value_vars=component_cols)
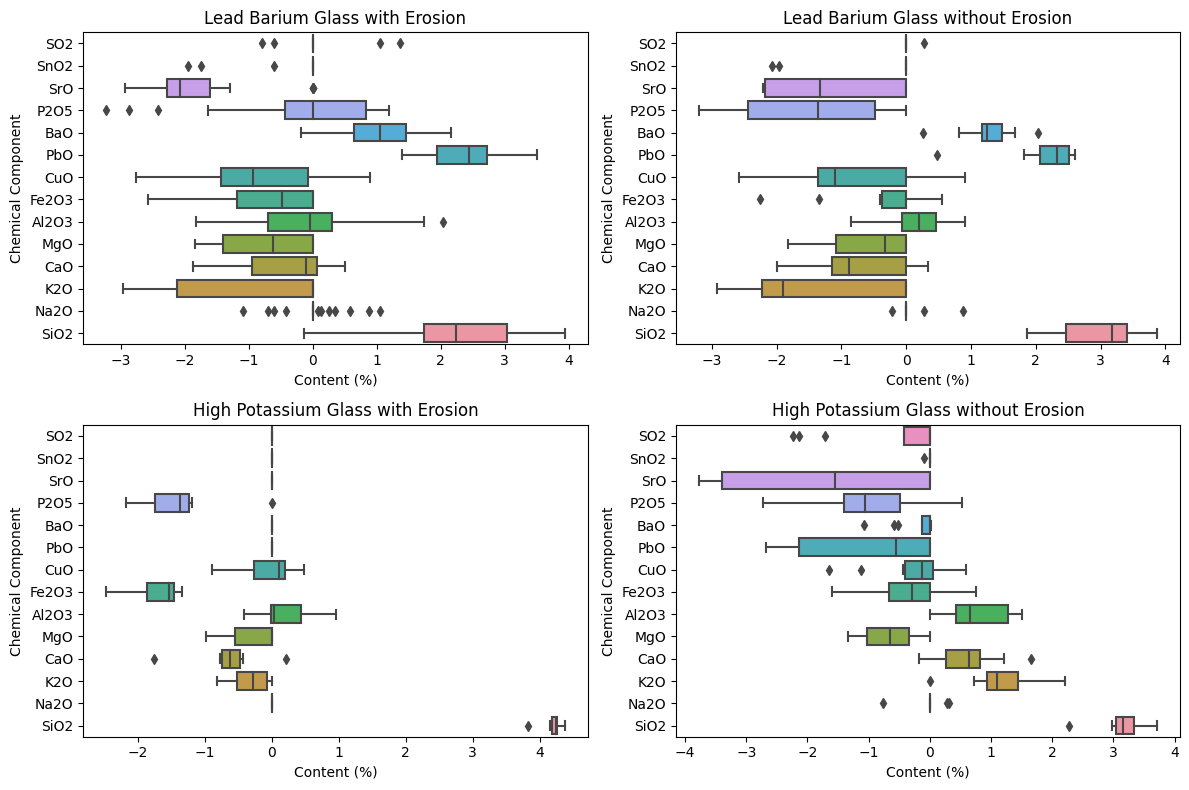
# Set the figure size
plt.figure(figsize=(20,45))# Create subplots
fig, axs = plt.subplots(2,2, figsize=(12,8))# Reorder the data and titles to switch the positions of the plots
data_list =[boxplot_data_lead_barium_erosion, boxplot_data_lead_barium_no_erosion, boxplot_data_high_potassium_erosion, boxplot_data_high_potassium_no_erosion]
titles =['Lead Barium Glass with Erosion','Lead Barium Glass without Erosion','High Potassium Glass with Erosion','High Potassium Glass without Erosion']# Generate boxplots for each conditionfor ax, data, title inzip(axs.flatten(), data_list, titles):
sns.boxplot(y='variable', x='value', data=data, ax=ax, orient="h")
ax.set_ylabel('Chemical Component')
ax.set_xlabel('Content (%)')
ax.set_title('{}'.format(title))
ax.invert_yaxis()# Invert the y-axis labels# Adjust layout
plt.tight_layout()
plt.show()
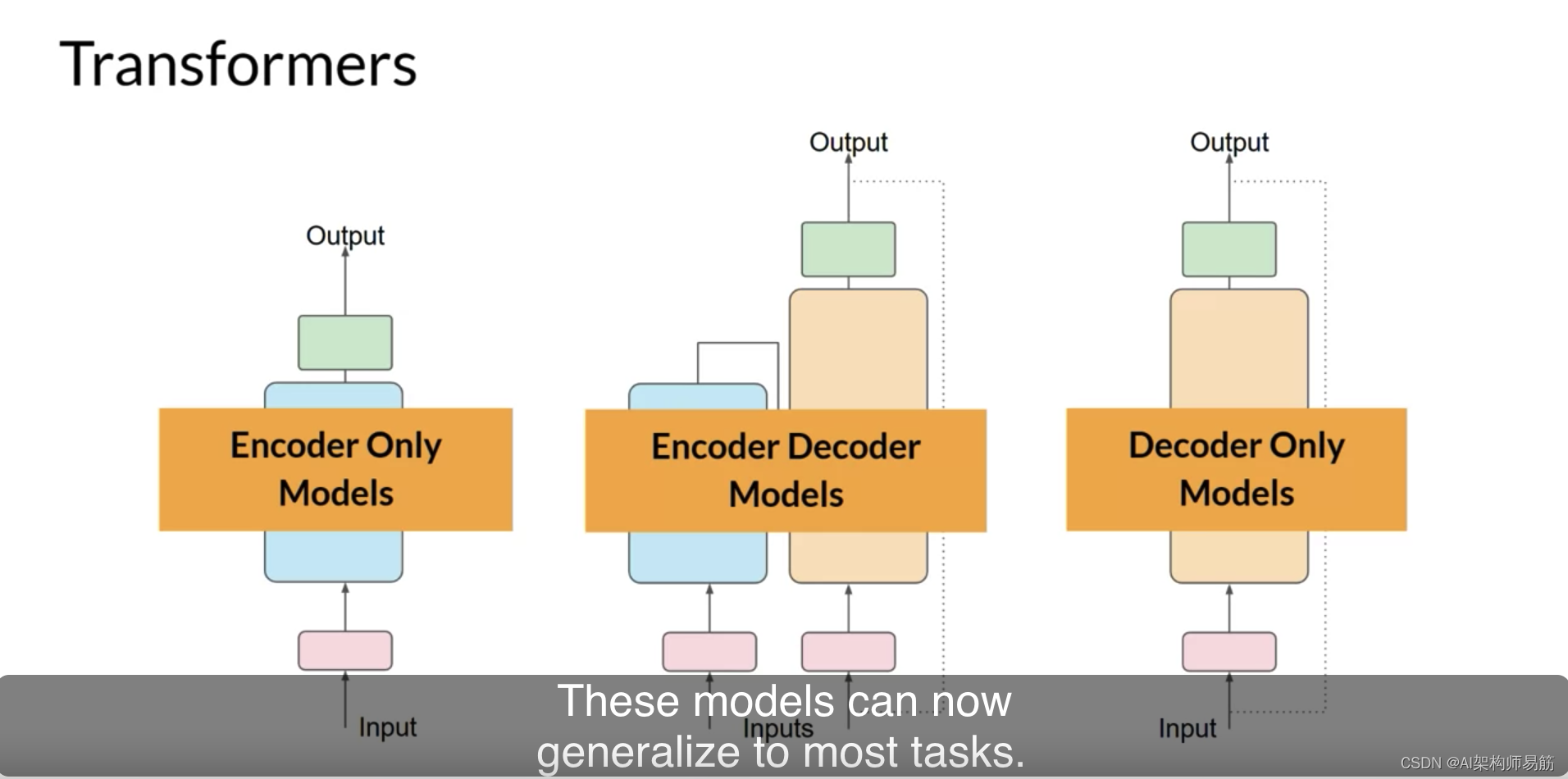
“Attention is All You Need” 是一篇由Google研究人员在2017年发表的研究论文,该论文介绍了Transformer模型,这是一种革命性的架构,它彻底改变了自然语言处理(NLP)领域,并成为我们现在所知道的LLMs的基础…
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lY1y3UDY-1692511618307)(output_12_0.png)]](https://img-blog.csdnimg.cn/d907740696c14d7d86c1f8c2bcb9eb8d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wvnwbDlV-1692511618309)(output_21_0.png)]](https://img-blog.csdnimg.cn/a6eb7ef293884e258d4de219c808a299.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VjubA0SS-1692511618310)(output_33_1.png)]](https://img-blog.csdnimg.cn/a9c334d27ca24ee48b47ac7aa35f9271.png)