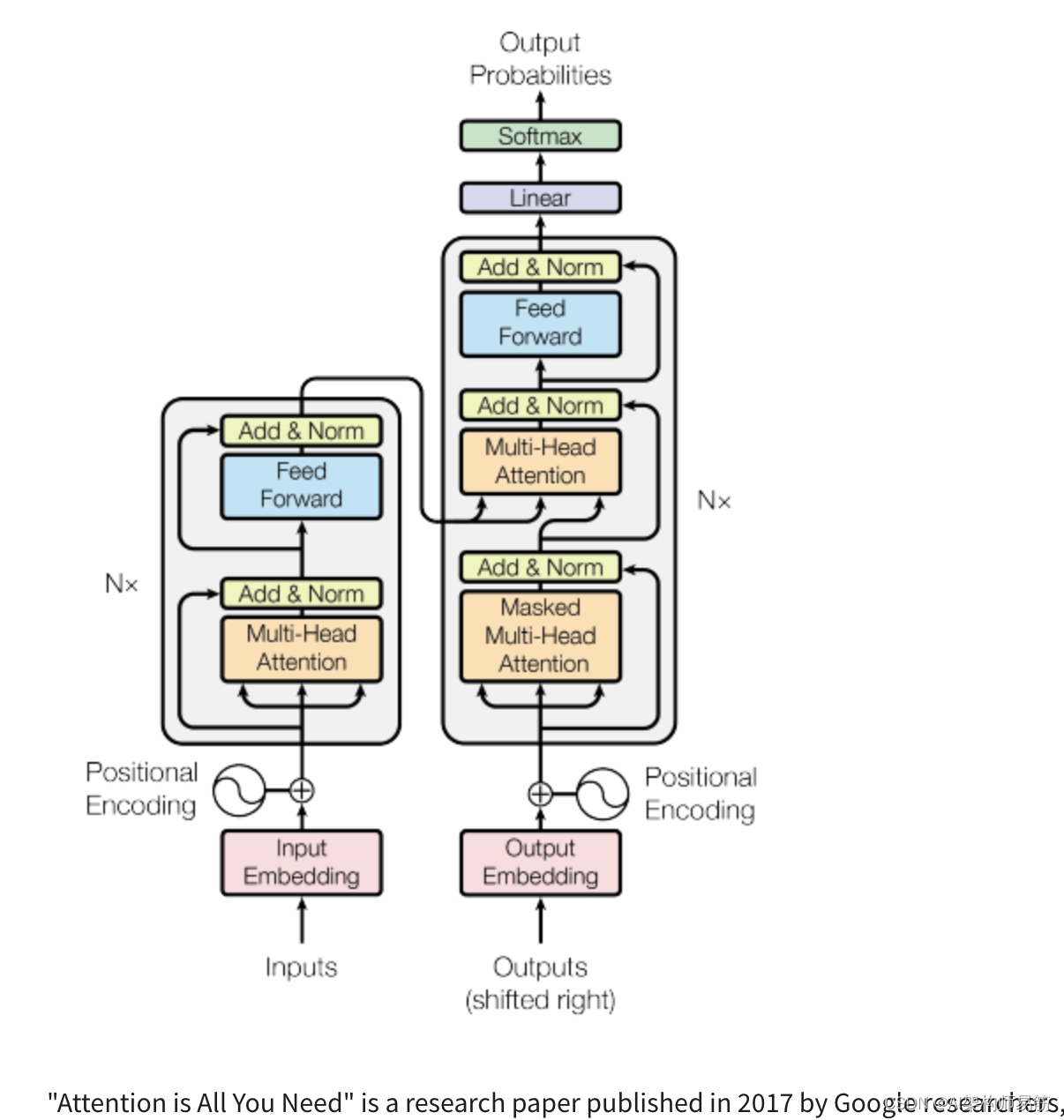
到目前为止,您已经看到了Transformers架构内部的一些主要组件的高级概述。但您还没有看到从头到尾的整体预测过程是如何工作的。让我们通过一个简单的例子来了解。在这个例子中,您将查看一个翻译任务或一个序列到序列的任务,这恰好是Transformers架构设计者的原始目标。
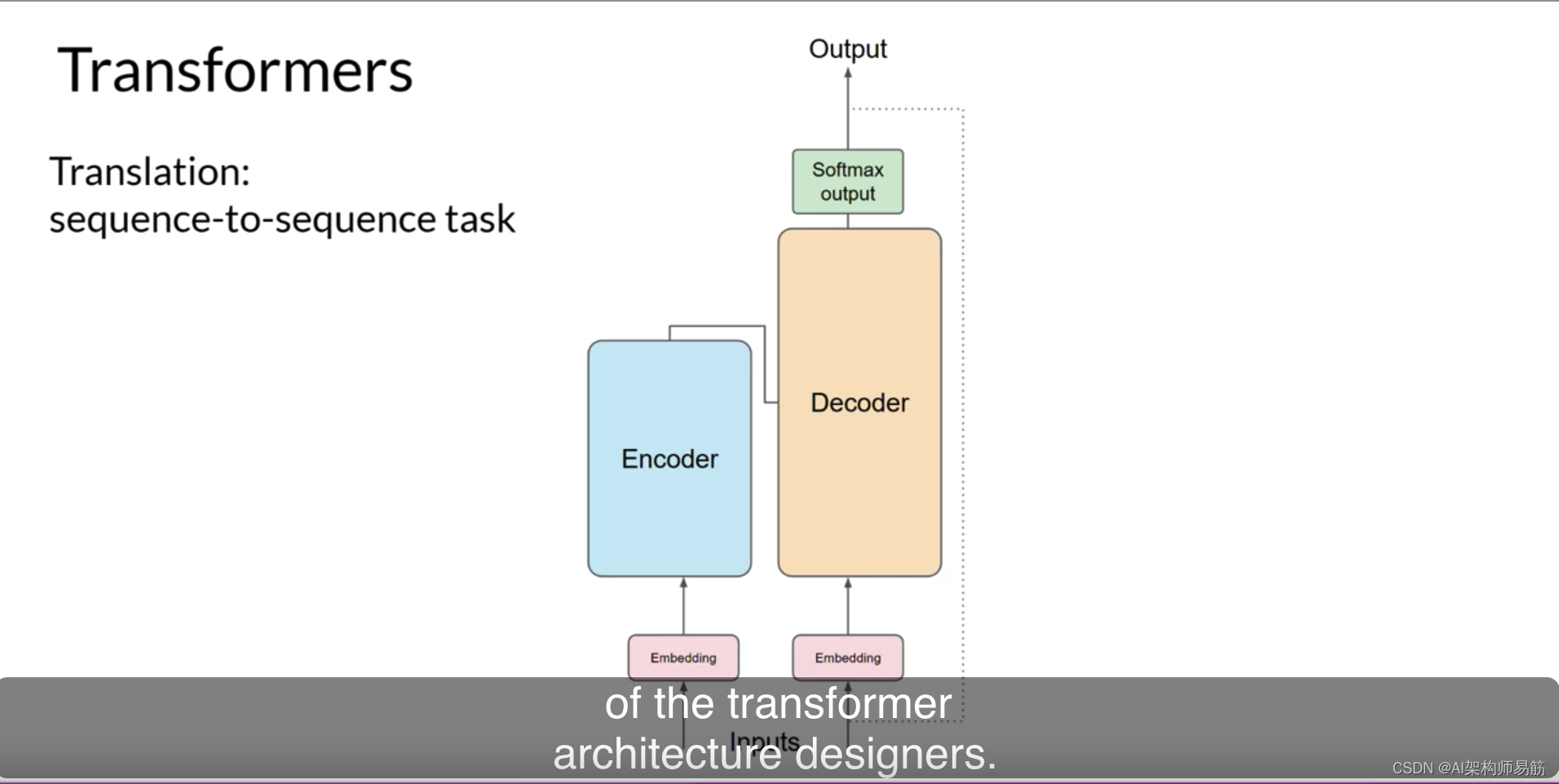
您将使用一个Transformers模型将法语短语[J’aime l’apprentissage automatique]翻译成英语。
首先,您将使用与训练网络相同的标记器对输入词进行标记。

这些令牌然后被添加到网络编码器端的输入中,
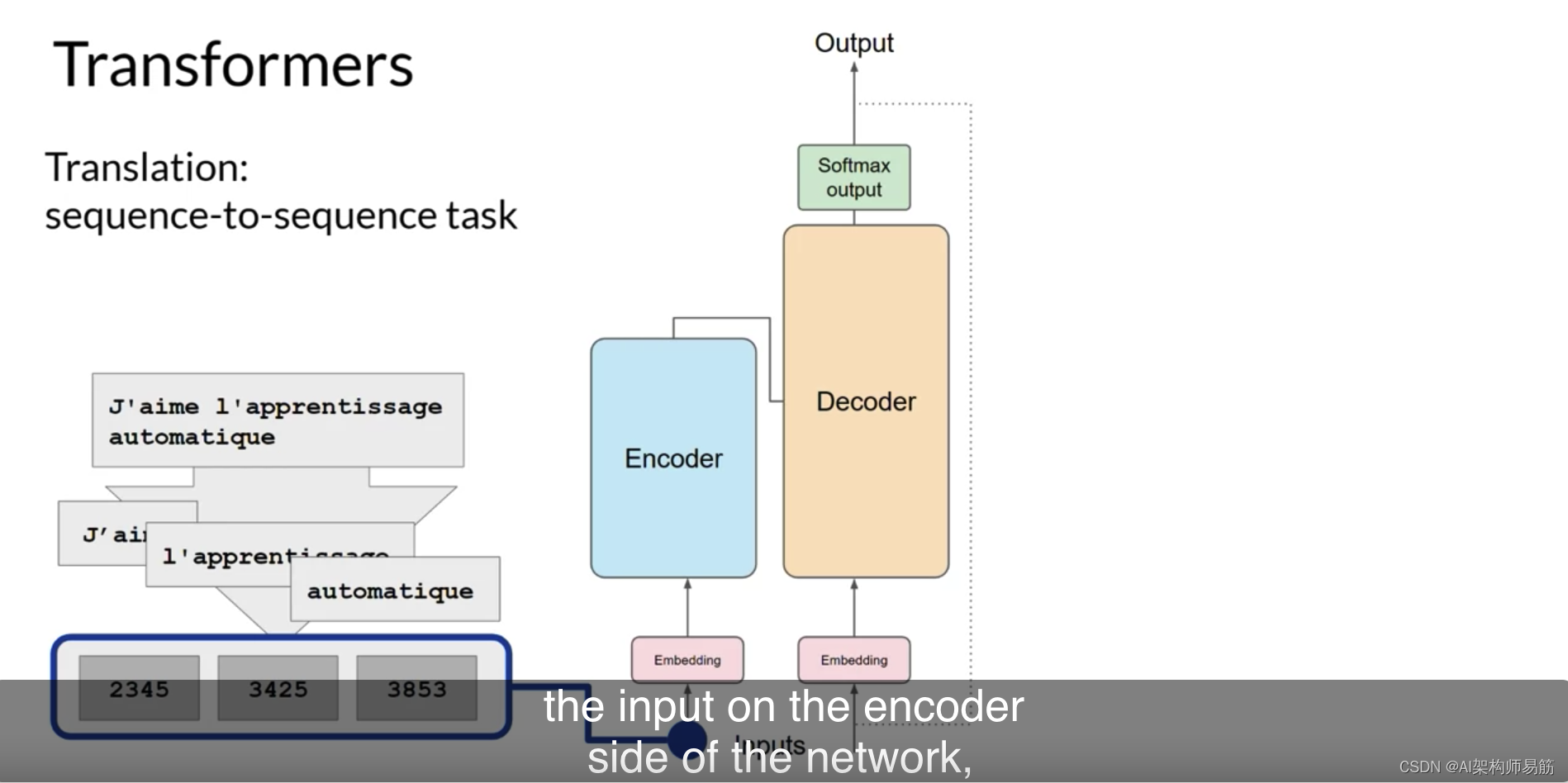
通过嵌入层,然后输入到多头注意力层中。
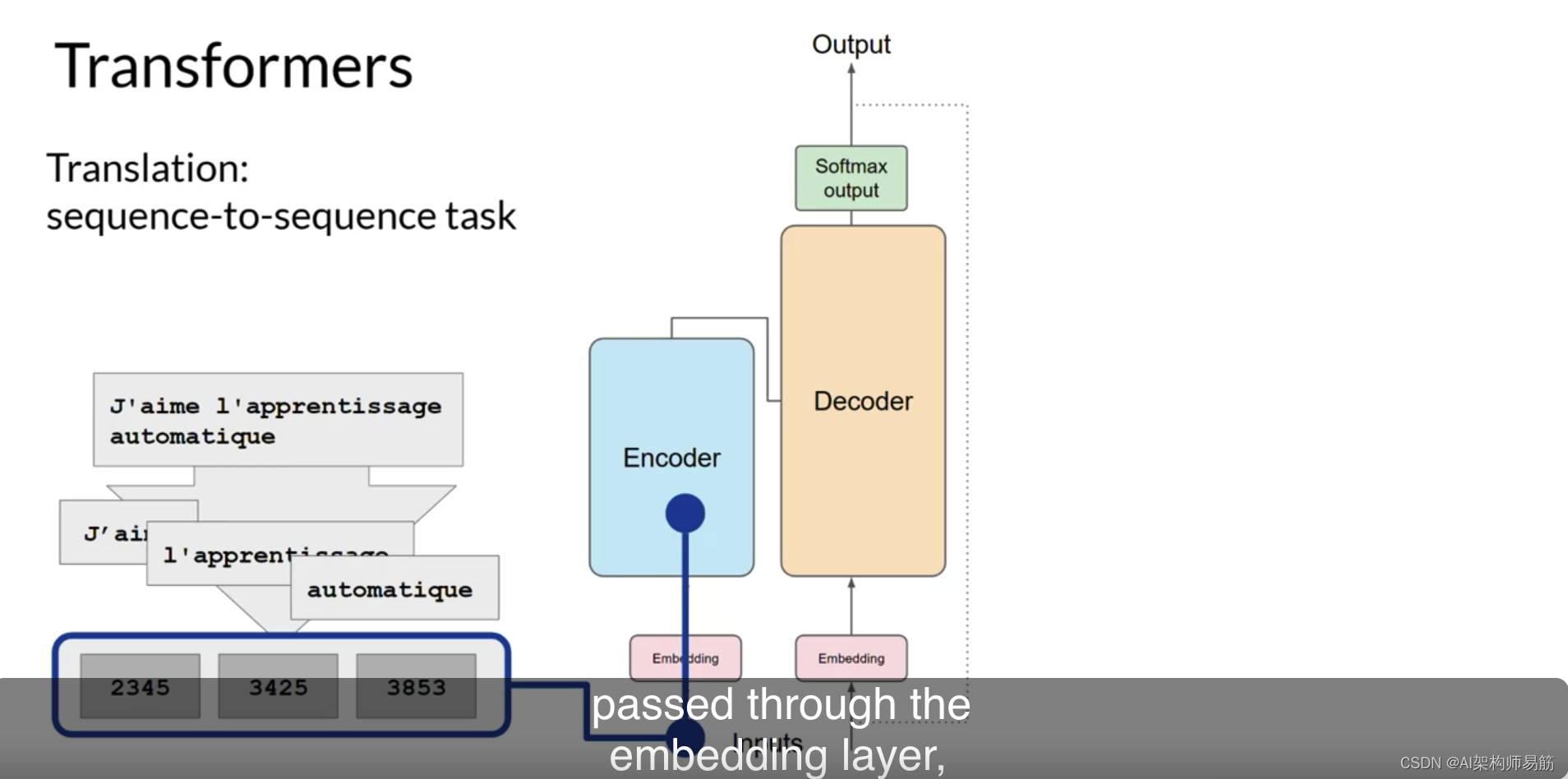
多头注意力层的输出通过前馈网络传递到编码器的输出。
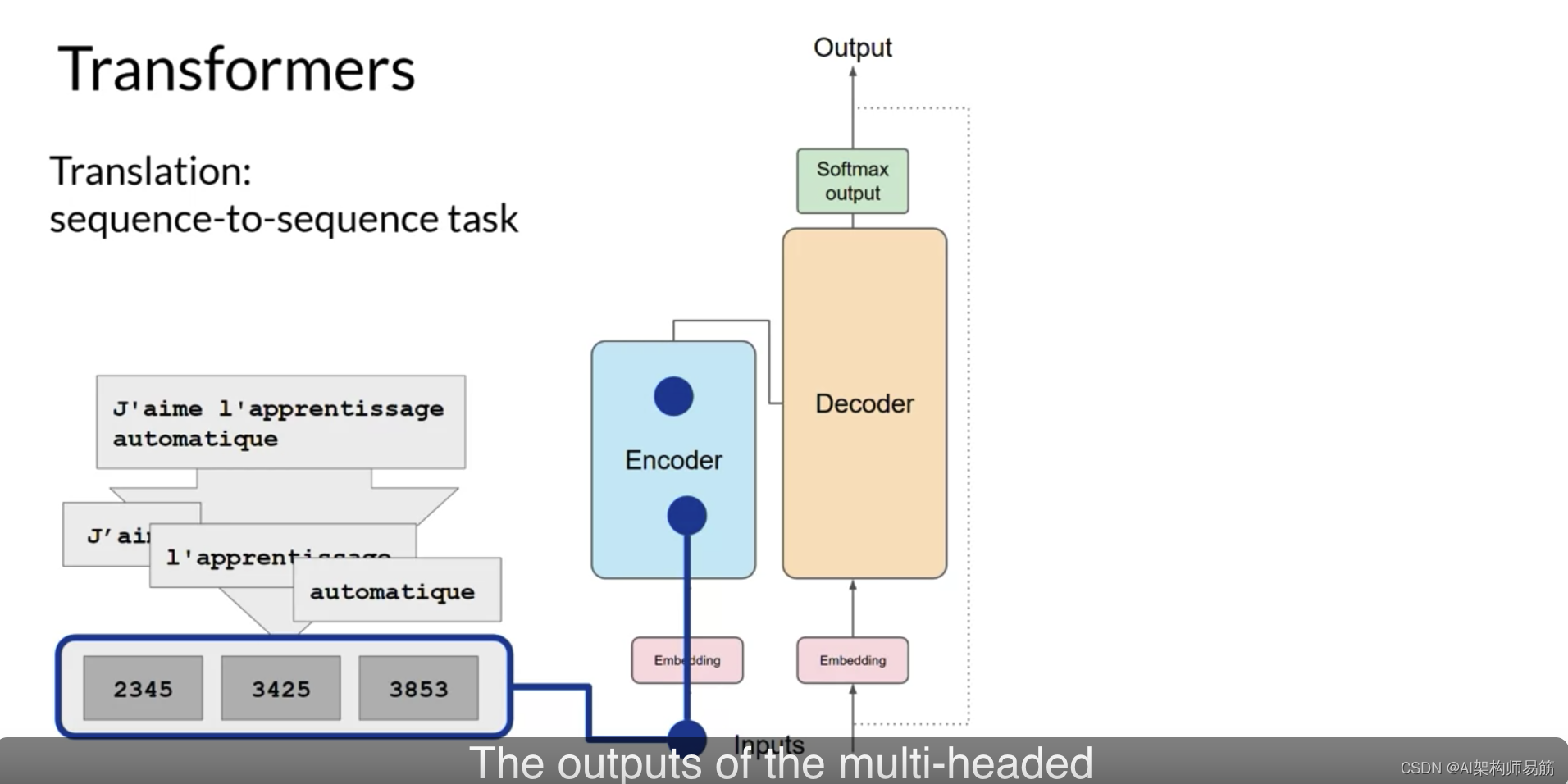
此时,离开编码器的数据是输入序列的结构和含义的深度表示。这种表示被插入到解码器的中间,以影响解码器的自注意力机制。
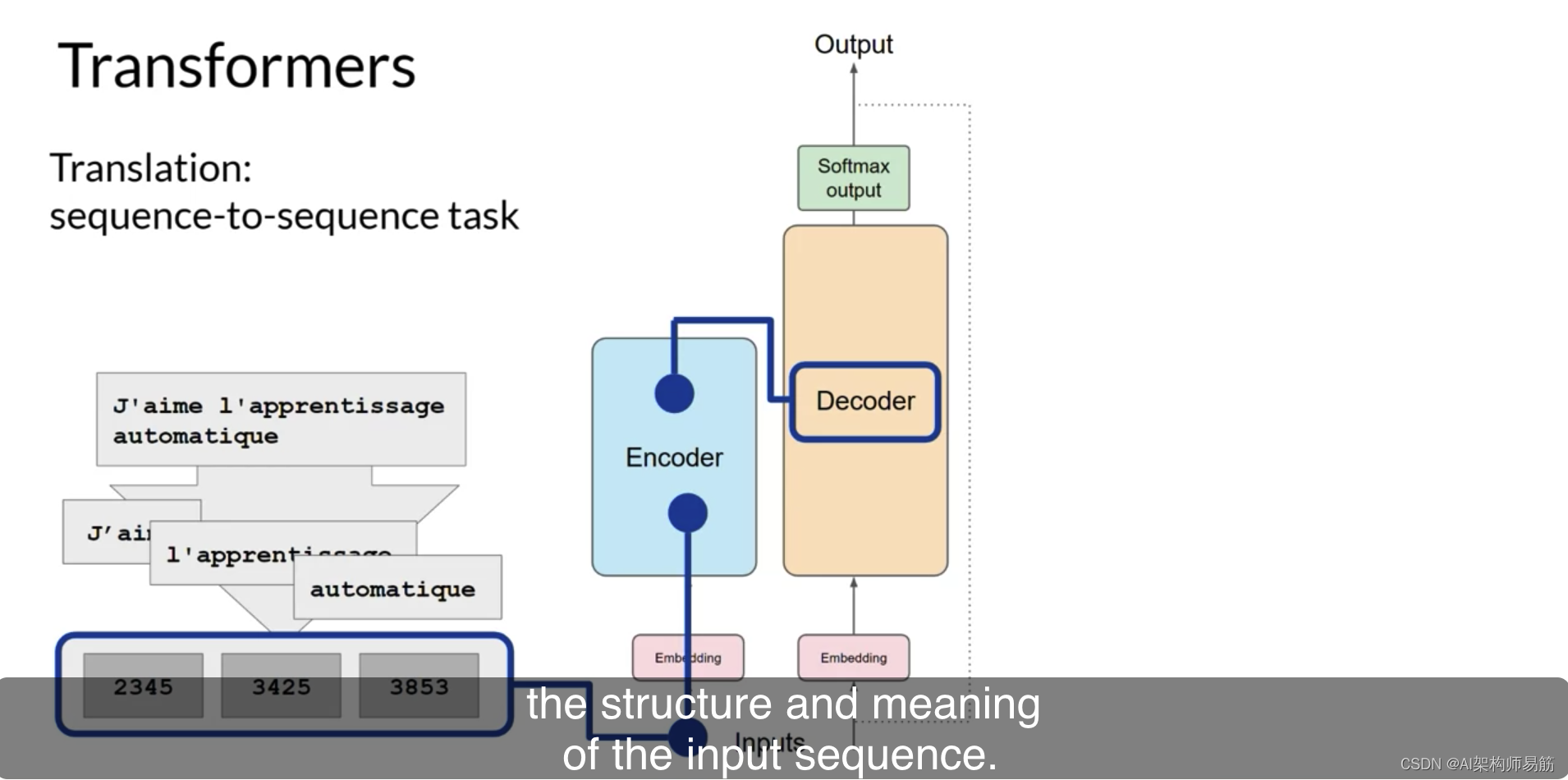
接下来,一个序列开始的令牌被添加到解码器的输入中。
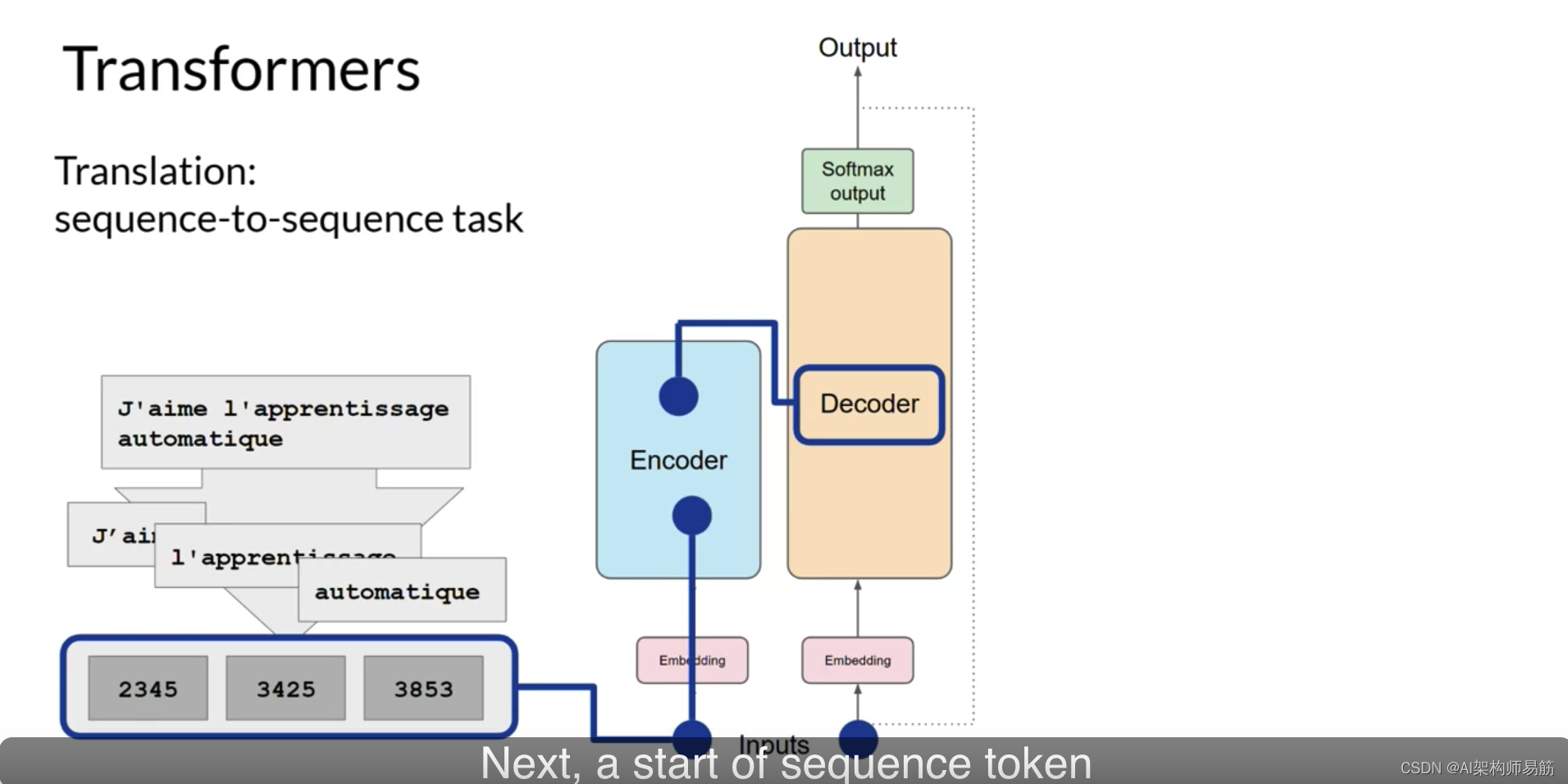
这触发了解码器预测下一个令牌,它是基于从编码器提供的上下文理解来做的。
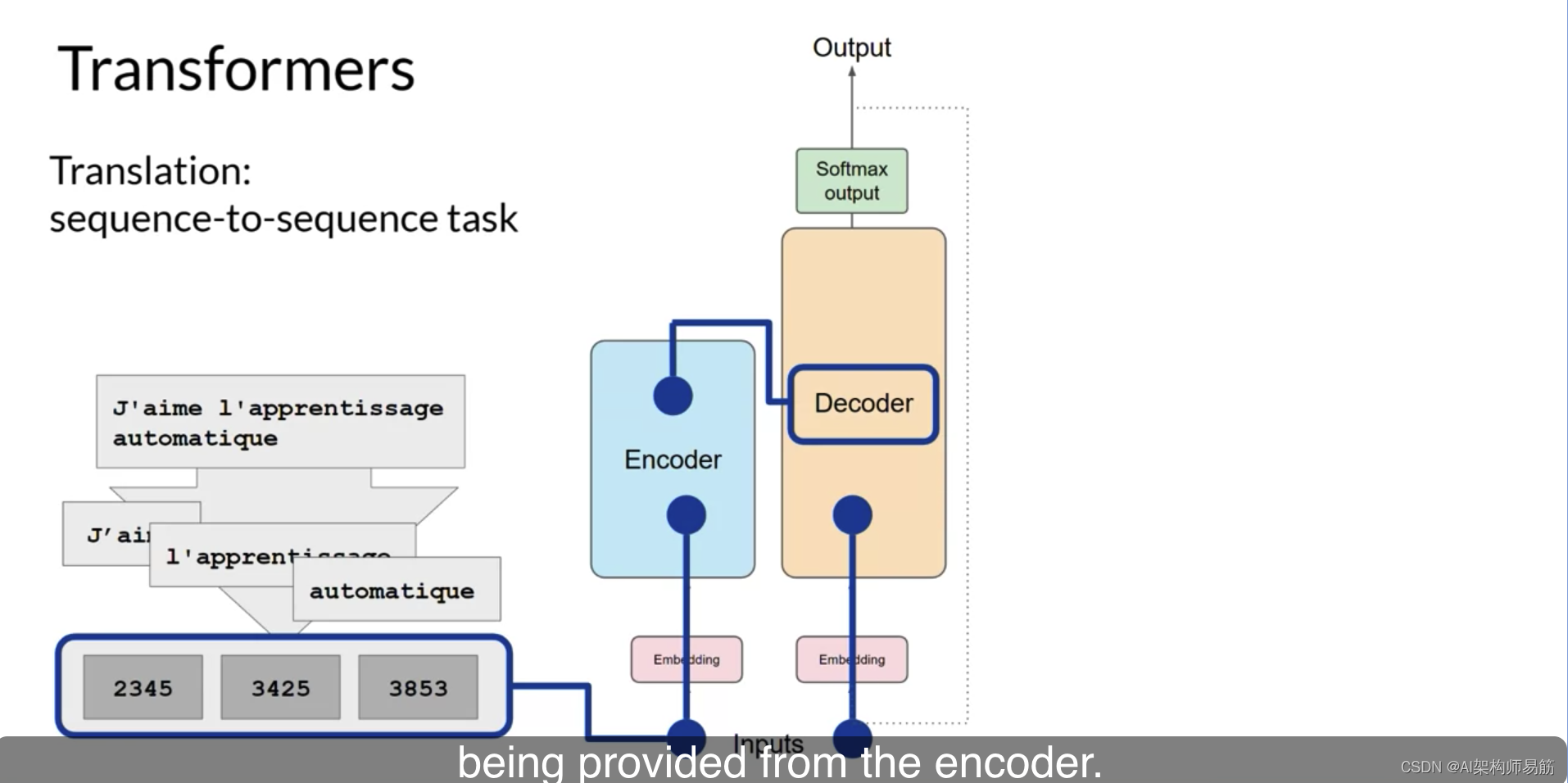
解码器的自注意力层的输出通过解码器的前馈网络和一个最终的softmax输出层。
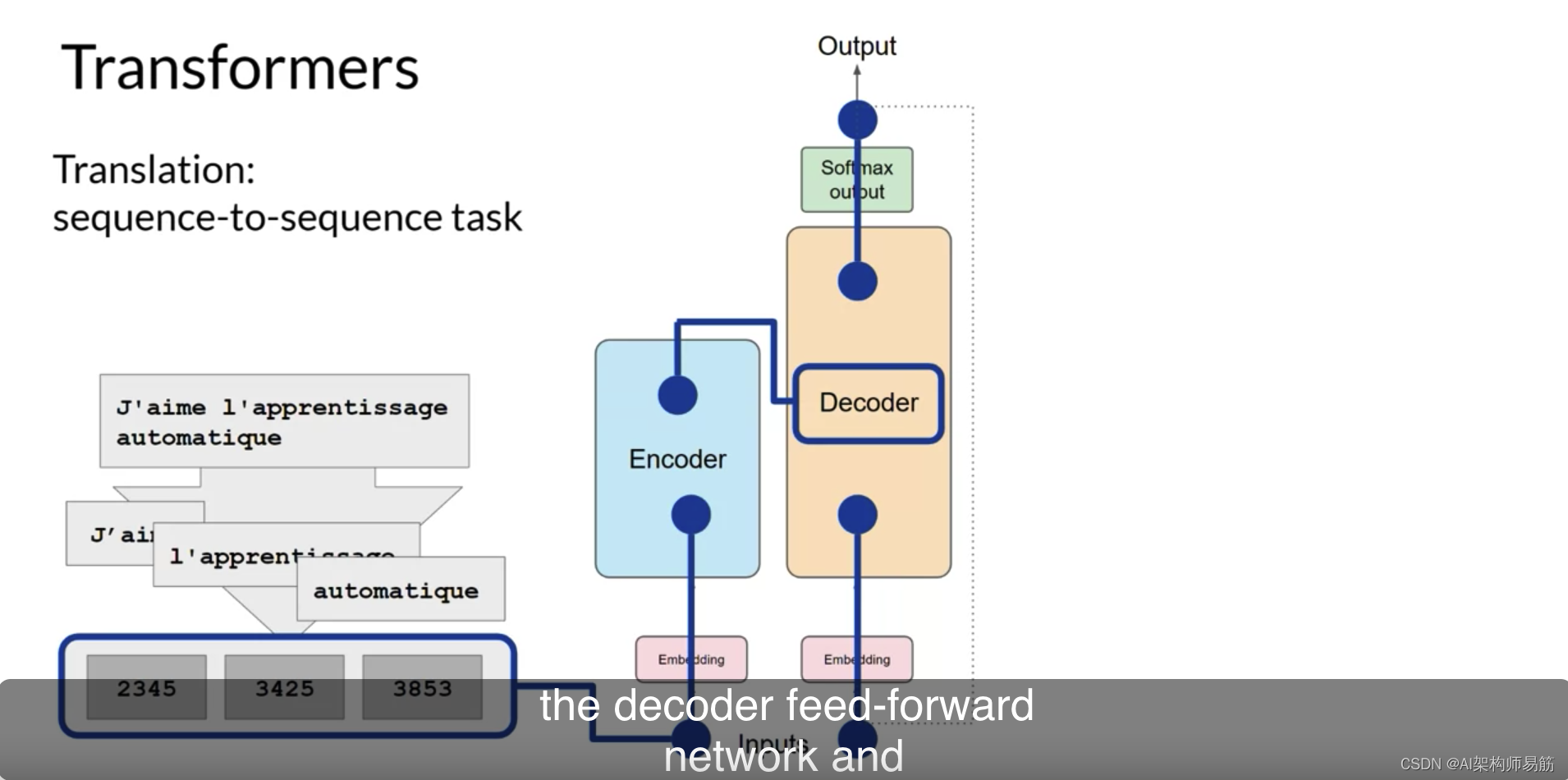
此时,我们有了我们的第一个令牌。
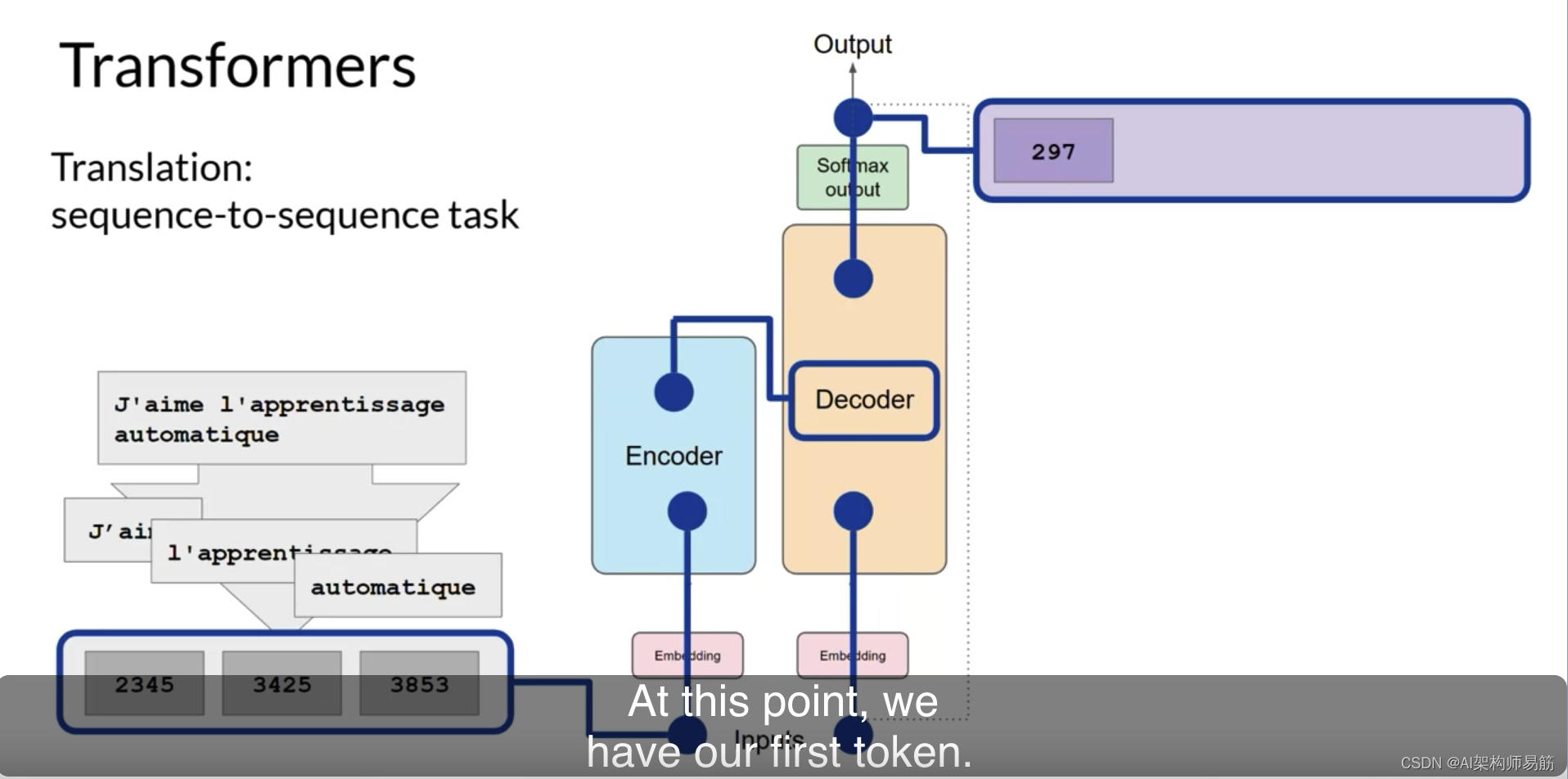
您将继续这个循环,将输出令牌传回输入以触发下一个令牌的生成,
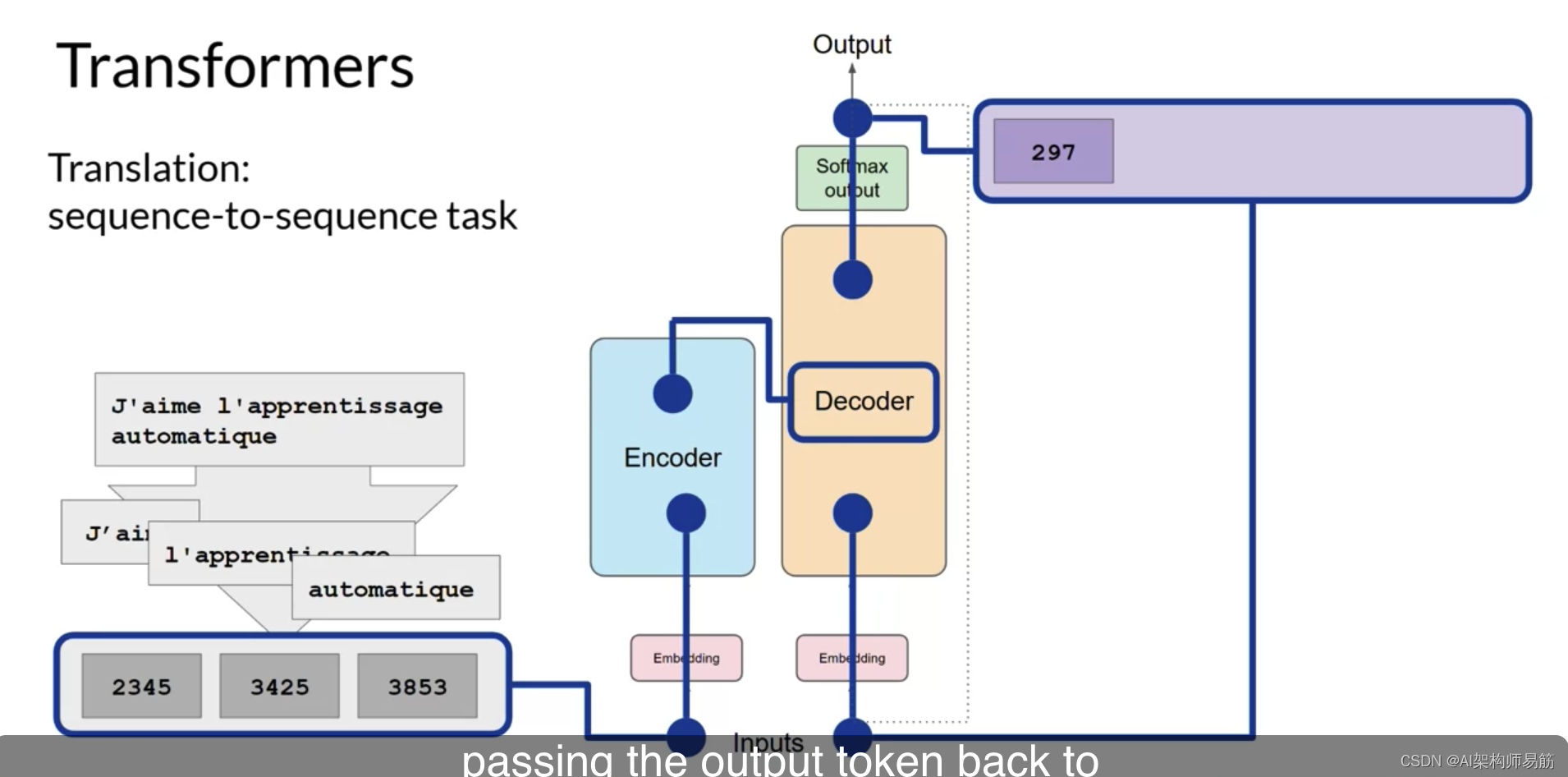
直到模型预测一个序列结束令牌。
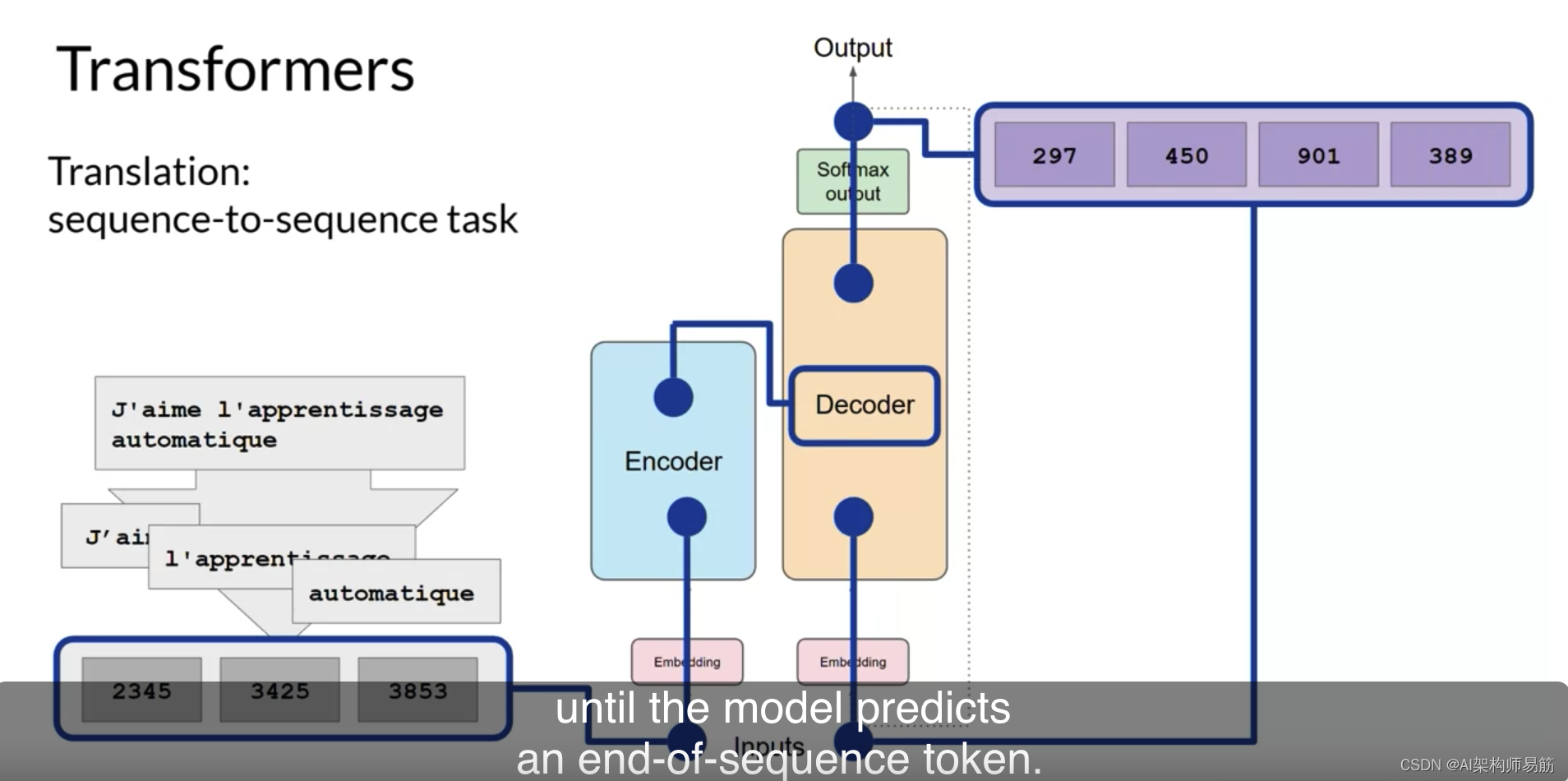
此时,最终的令牌序列可以被反标记为单词,您就有了您的输出。在这种情况下,I love machine learning 我爱机器学习。
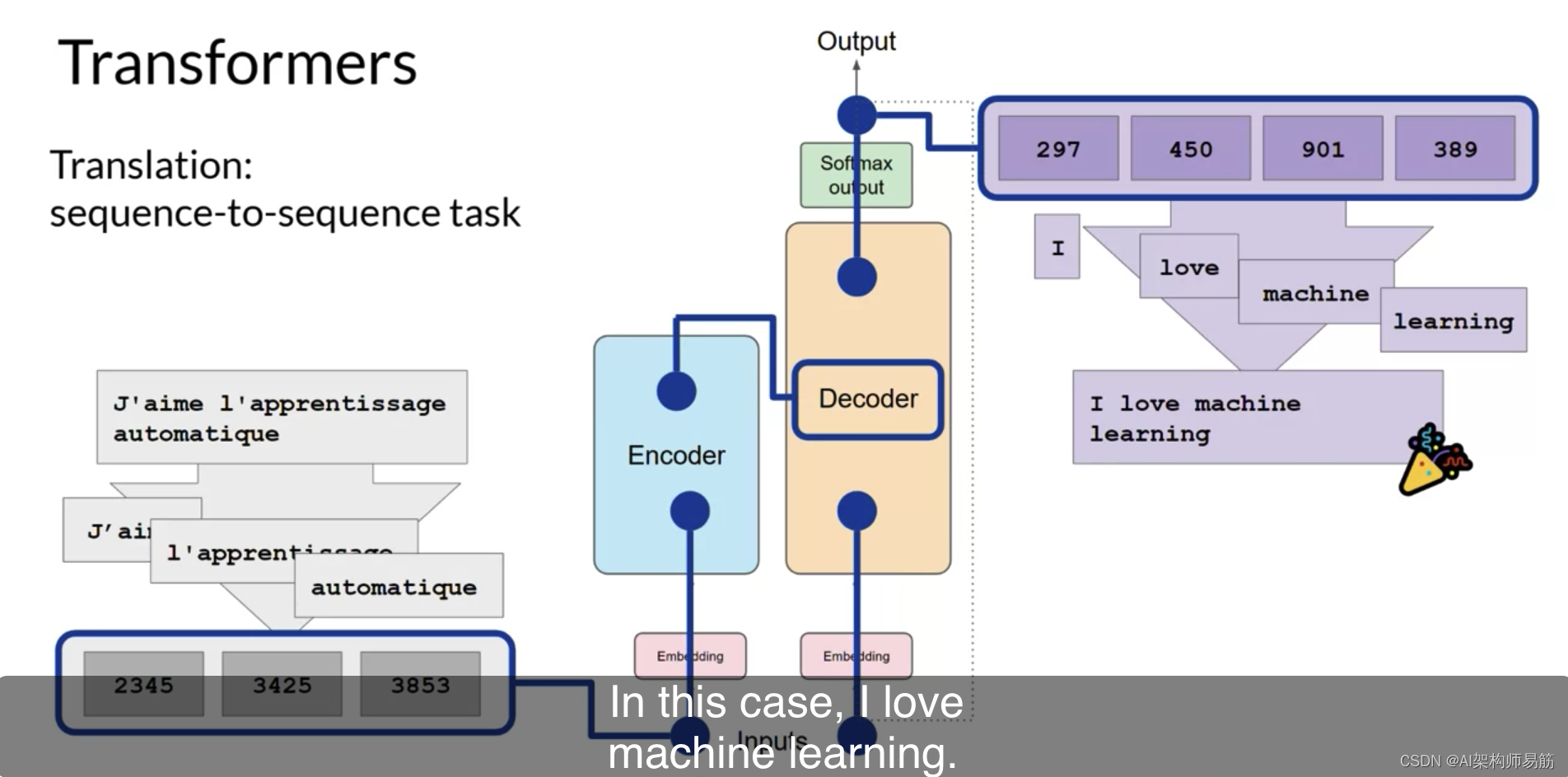
有多种方式可以使用softmax层的输出来预测下一个令牌。这些可以影响您生成的文本的创造性。您将在本周晚些时候更详细地了解这些。
让我们总结一下您到目前为止看到的内容。完整的Transformers架构由编码器和解码器组件组成。编码器将输入序列编码为输入的结构和含义的深度表示。解码器从输入令牌触发器开始工作,使用编码器的上下文理解来生成新的令牌。它在达到某个停止条件之前一直这样做。
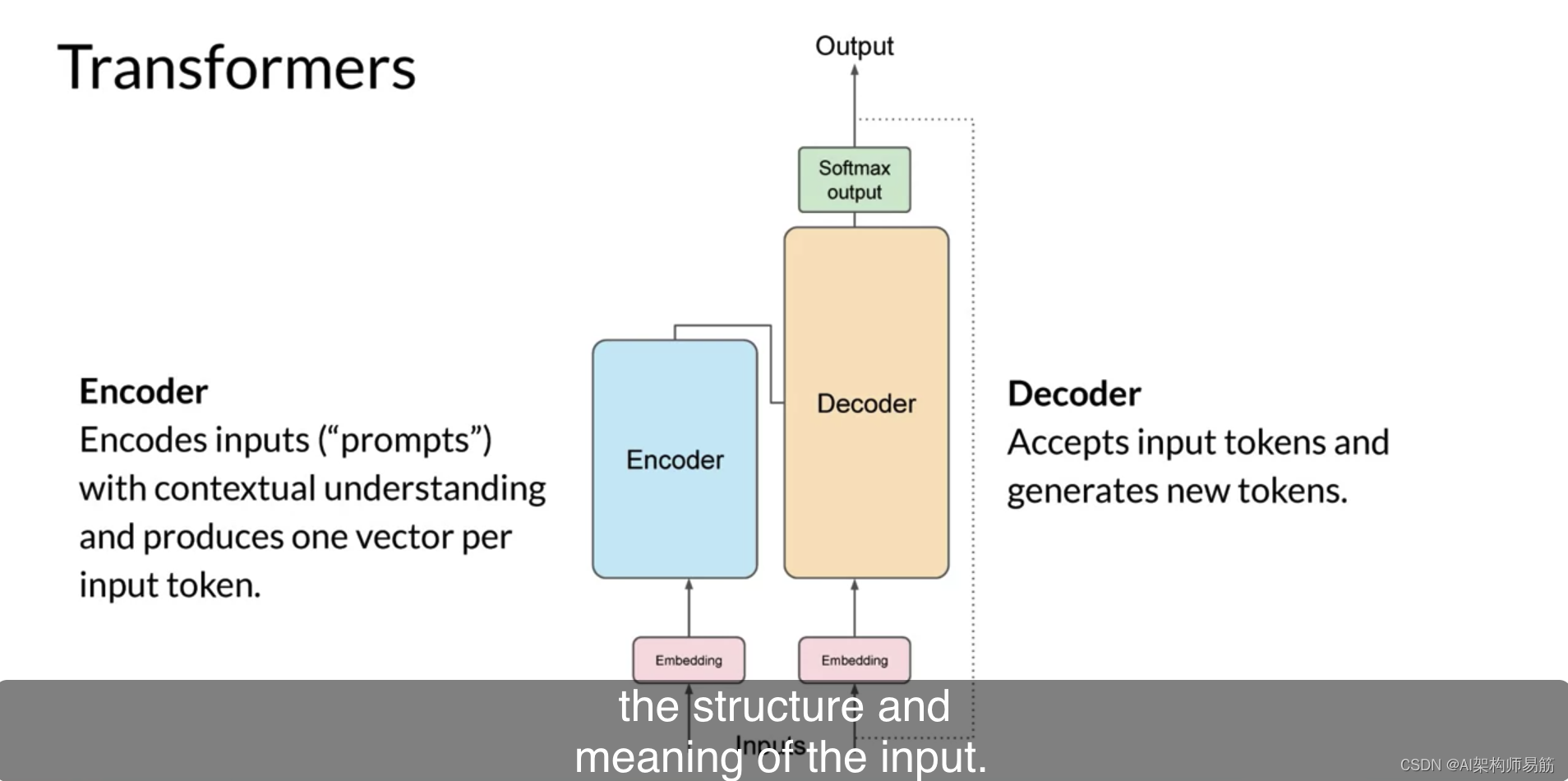
虽然您在这里探索的翻译示例使用了Transformers的编码器和解码器部分,但您可以为架构的变体分开这些组件。
仅编码器模型也可以作为序列到序列模型工作,但在没有进一步修改的情况下,输入序列和输出序列或相同长度。这些日子里,它们的使用不太常见,但通过向架构中添加额外的层,您可以训练仅编码器模型来执行分类任务,如情感分析,BERT是一个仅编码器模型的例子。

编码器-解码器模型,如您所见,表现良好,适用于序列到序列任务,例如翻译,其中输入序列和输出序列可以是不同的长度。您还可以扩展并训练这种类型的模型来执行一般的文本生成任务。编码器-解码器模型的例子包括BART(与BERT相对)和T5,这是您在本课程中的实验室中将使用的模型。
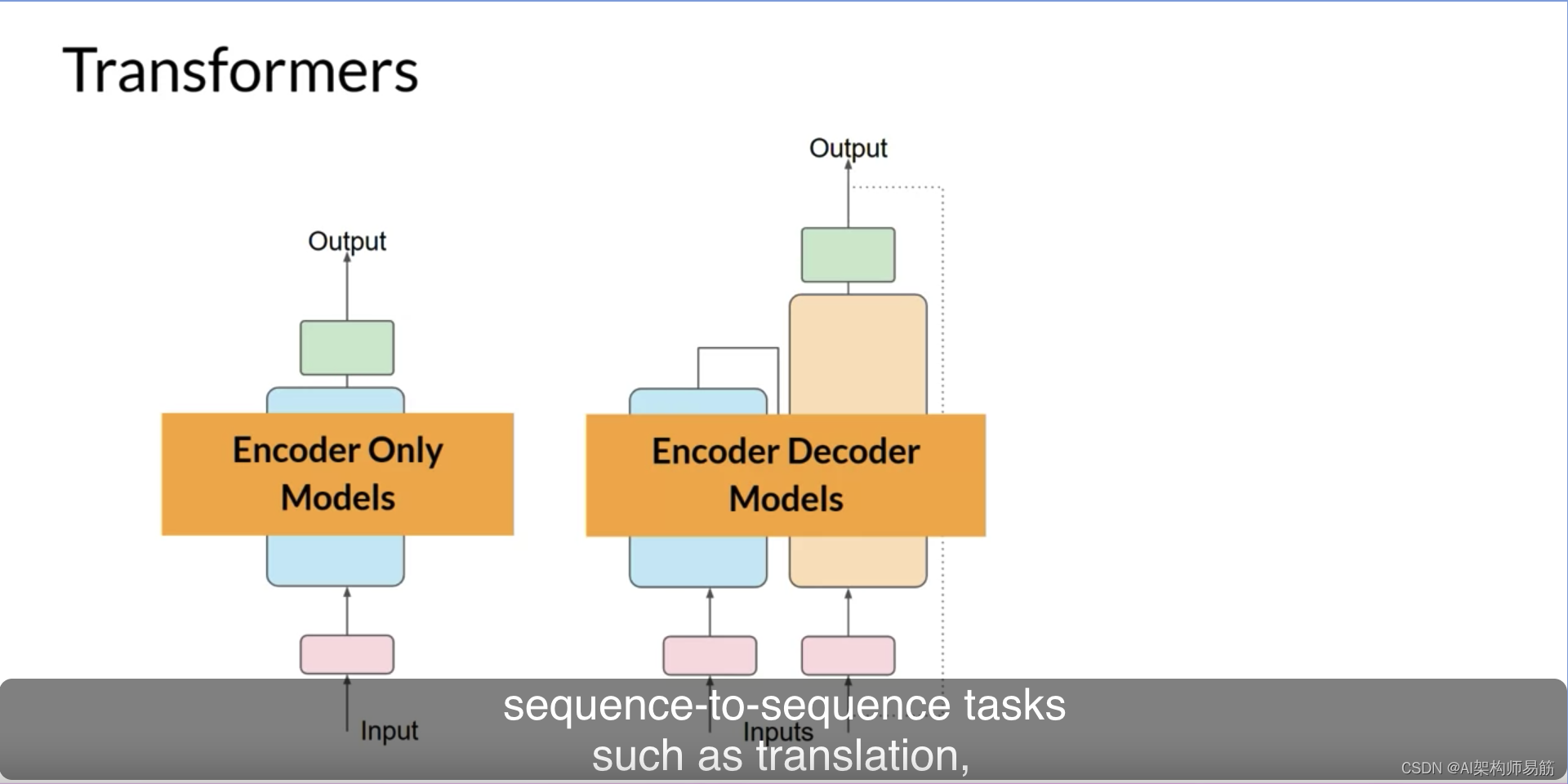
最后,仅解码器模型是当今最常使用的。再次,随着它们的扩展,它们的能力也增长了。这些模型现在可以推广到大多数任务。流行的仅解码器模型包括GPT模型家族,BLOOM,Jurassic,LLaMA等等。您将在本周晚些时候了解更多关于Transformers的不同种类以及它们是如何被训练的。这是相当多的。
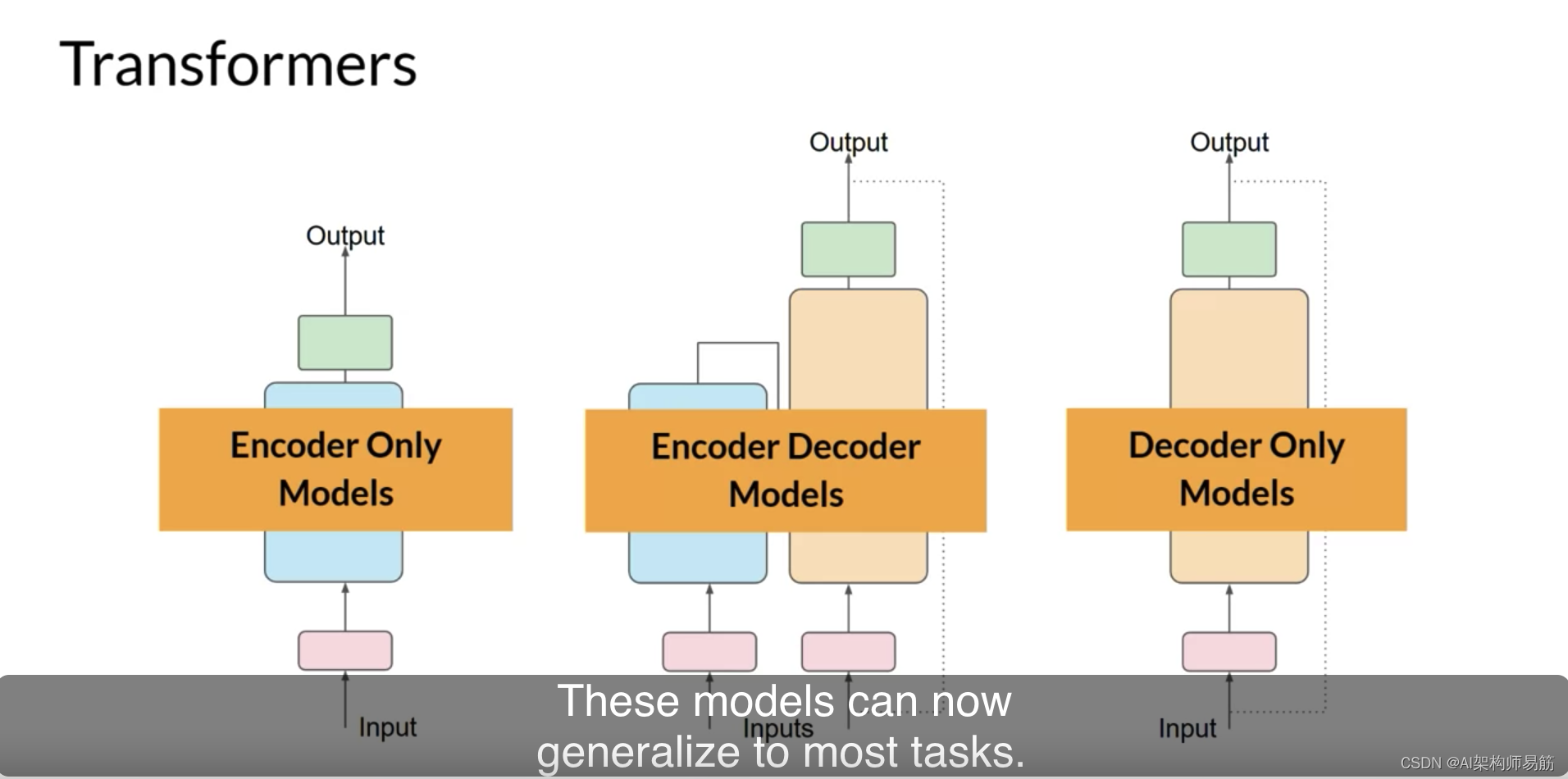
这个Transformers模型的概述的主要目标是为您提供足够的背景,以了解世界上使用的各种模型之间的差异,并能够阅读模型文档。
我想强调,您不需要担心记住您在这里看到的所有细节,因为您可以根据需要多次回到这个解释。
请记住,您将通过自然语言与Transformers模型互动,使用书面单词而不是代码创建提示。
您不需要了解底层架构的所有细节来做到这一点。这被称为提示工程,这是您将在本课程的下一部分中探索的。让我们继续下一个视频,了解更多。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/R0xbD/generating-text-with-transformers