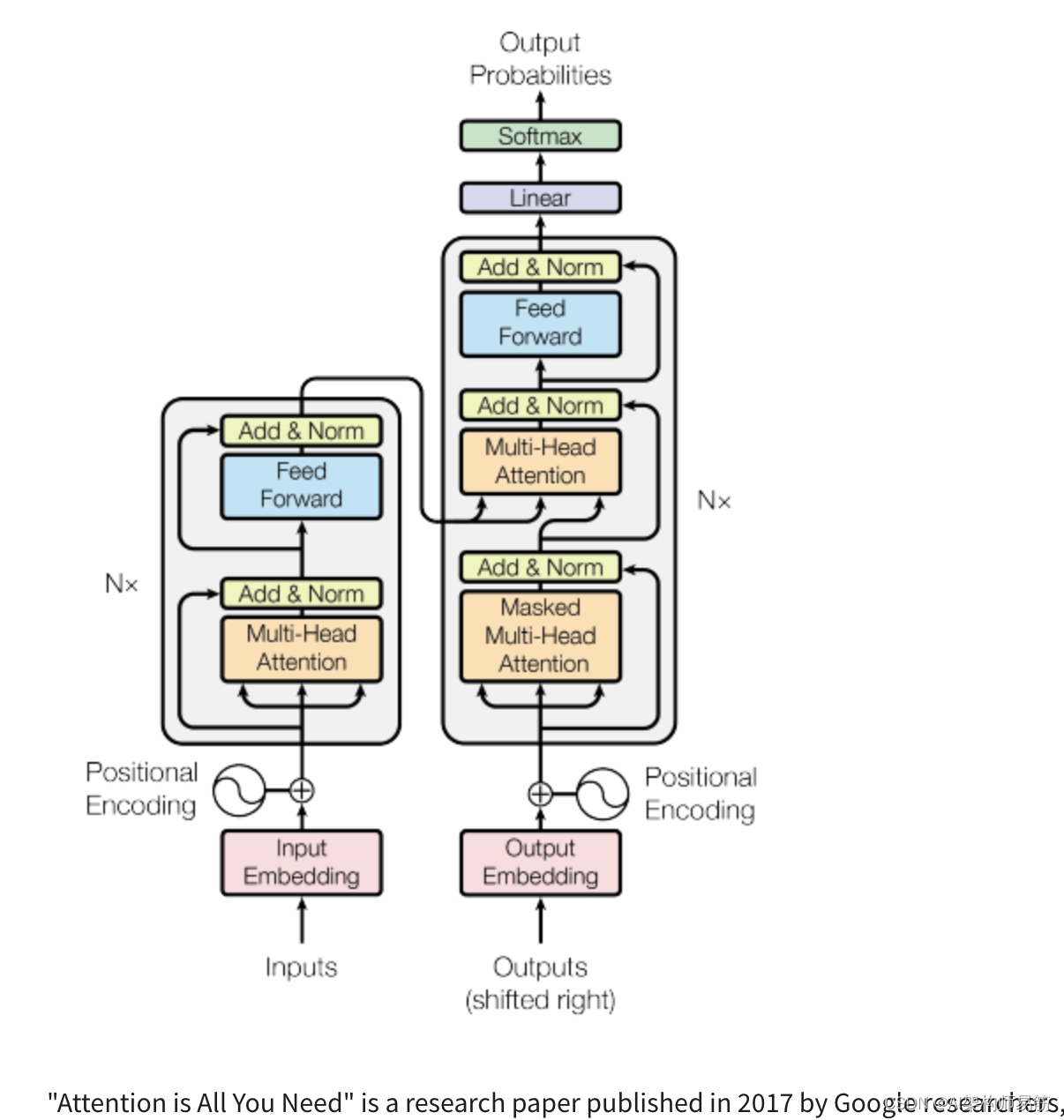
“Attention is All You Need” 是一篇由Google研究人员在2017年发表的研究论文,该论文介绍了Transformer模型,这是一种革命性的架构,它彻底改变了自然语言处理(NLP)领域,并成为我们现在所知道的LLMs的基础 - 例如GPT、PaLM和其他模型。该论文提出了一种神经网络架构,该架构用完全基于注意力的机制替代了传统的循环神经网络(RNNs)和卷积神经网络(CNNs)。
Transformer模型使用自注意力来计算输入序列的表示,这使得它能够捕获长期依赖性并有效地并行计算。作者证明了他们的模型在几个机器翻译任务上都达到了最先进的性能,并且超越了依赖RNNs或CNNs的先前模型。
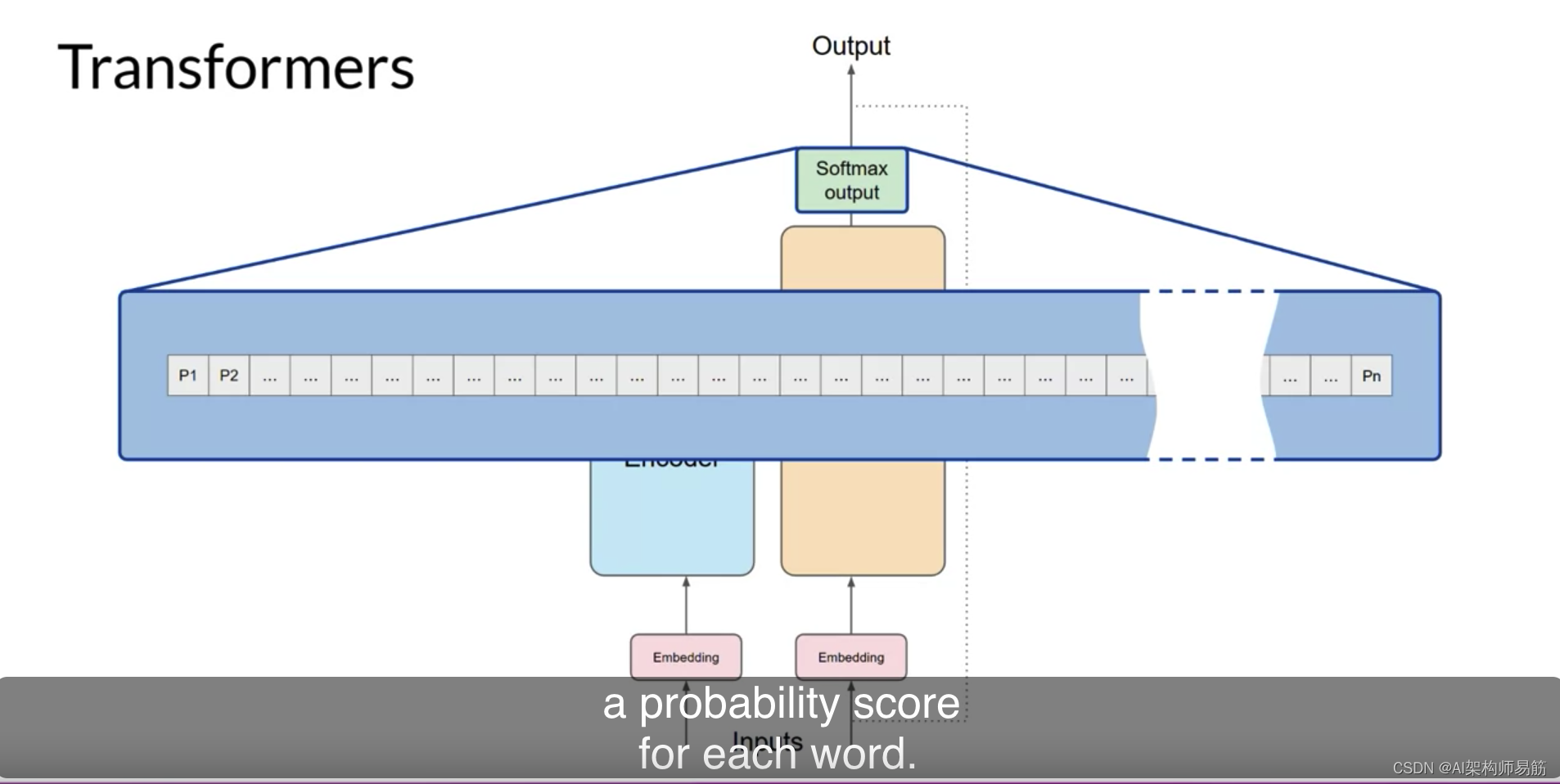
Transformer架构由一个编码器和一个解码器组成,每个部分都由几层组成。每一层都包括两个子层:多头自注意力机制和前馈神经网络。多头自注意力机制使模型能够关注输入序列的不同部分,而前馈网络则对每个位置分别并相同地应用点对点的全连接层。
Transformer模型还使用残差连接和层归一化来促进训练并防止过拟合。此外,作者引入了一个位置编码方案,该方案编码了输入序列中每个令牌的位置,使模型能够捕获序列的顺序,而无需进行循环或卷积操作。
您可以阅读Transformers论文。
参考
- https://www.coursera.org/learn/generative-ai-with-llms/supplement/Il7wV/transformers-attention-is-all-you-need
- https://arxiv.org/abs/1706.03762