致力于解决细节分割不好的情况,可以理解为sam的精细分割的微调版本,但是对原始的分割能力也没有丢失,有点像目标检测中的小目标检测优化算法。总的来说,在原始的sam上增加了hq-features和hq output token以及mlp,来做hq mask预测,最终是hq feature和hq output token预测出来的mlp权重相乘得到mask。相当于sam的一个微调版本。
1.introduction
sam存在两个问题:1.粗糙的mask边界,经常会忽略对细物体结构的分割;2.在具有挑战性的场景下,存在错误的损坏的预测,主要与sam对细小结构的错误理解有关,本文主要在解决这两个问题,同时他是基于sam的,不对sam的原始分割能力造成退化和影响,在sam的基础上增加了两个模块来额外处理细小结构分割问题,但是由于保留了原始sam的结构,肯定是比sam要慢的,但是如果结合上mobilesam的vit_t的话,可能效果能平衡一下,增加了不到0.5%的参数。

上面这张图,原始的sam对结构的理解要差一点,最后一张图sam错误的理解了线。
2.method
数据:由于sam_hq实在sam基础上训练的三个小模块,hq output token,三层mlp以及小的特征融合模块,因此准备的是一部分精细的数据,原始sam在sa-1b上训练的,1100w图和11亿mask,256个gpu,batch为256。sam_hq在HQSeg-44k数据上训练,包括44000个高精度mask合并而来,包括1000个语义类别。
2.1 preliminaries:sam
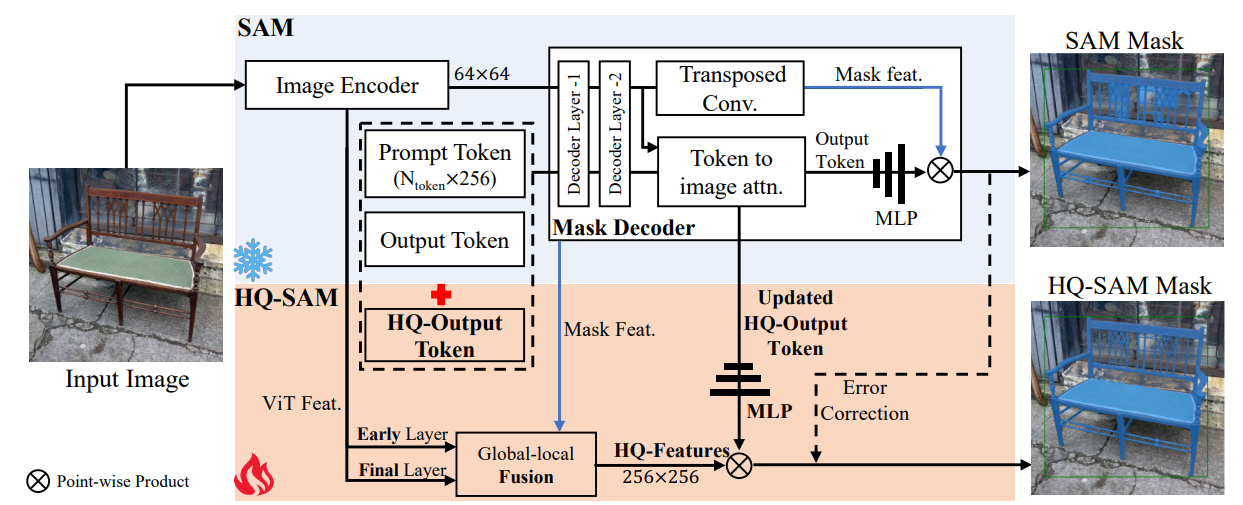
图像编码器:基于vit,得到64x64的image embedding,prompt编码器:编码来自点框和mask的位置信息,mask解码器:双层transformer的解码器同时使用image embedding和prompt进行最终的mask预测,output token用于mask预测,类似与detr中的learnable object,它预测mlp的权重,然后和mask feat进行逐点乘积。
2.2 hq-sam
引入了hq output token和一个新的用于神女郭恒高质量mask预测的mask预测层(三层mlp),不是直接使用sam的粗糙mask作为输入。
通过重用和固定sam的mask decoder,将一个可学习的hq output token(1x256)与sam的output token(4x256)和prompt token(Nx256)连结在一起,作为输入传递给sam的mask decoder,与原始的output token类似,在每个注意力层中,hq output token先与其它token进行自注意力计算,然后进行token to image和image to token的反向注意力已更新其特征,hq output token在每个解码器层中使用和其他token共享的逐点mlp,进过两个解码器层后,更新后的hq output token可以访问全局图像上下文,prompt token的重要几何类型信息以及其他输出token的隐藏mask信息。最后添加一个新的三层mlp,用于从更新后的hq-output token生成动态卷积核权重,然后和融合的hq特征进行逐点乘积,用于生成高质量的mask。
与直接微调sam或者进一步添加复杂的后处理不同,hq-sam只允许对hq output token及其三层的ml进行训练,已修正sam的output token中的错误mask。
精确的分割还需要输入具有丰富全局语义上下文和局部边界细节的图像特征,不直接使用sam的mask decoder特征,而是从sam模型的不同阶段提取和融合特征来组合新的高质量特征hq-eatures,1.san的vit早期局部特征,大小为64x64,捕获更多通用图像边缘细节,具体来说,提取vit的第一个全局注意力块之后的特征,vit-large的sam,共有24个块,第6个块的输出;2.sam的vit编码器最终层的全局特征,64x64,3.sam的mask decoder中的mask特征,256x256,包含mask形状信息,为了获得输入的hq-features,先通过转置卷积将早期层和最终编码层上采样到256x256,然后进行求和。
3.training
固定sam参数,只让hq output token以及与之关联的三层和mlp和三个简单的用于hq features融合的卷积进行训练。
采用和sam相同的推断流程,但使用hq output token的mask预测作为高质量的mask预测,在推断中奖sam的mask和hq-sam的mask进行logits相加,已修正,分辨率为256x256,在上采样到1024x1024。