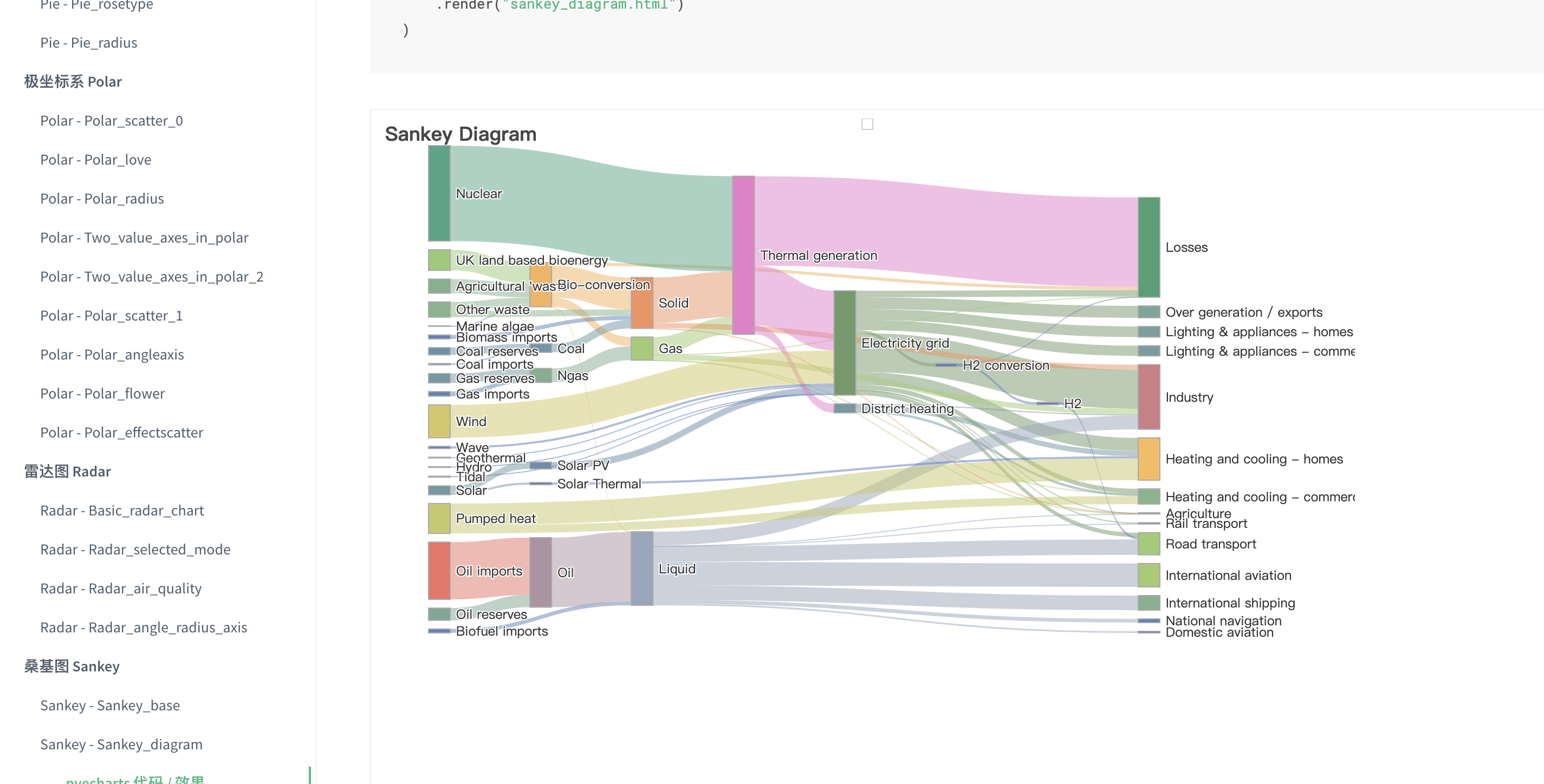
📌 关键词:随机森林、变量重要性、建模、分类、回归、R语言、可解释性
🎯 一、随机森林到底是什么?
随机森林(Random Forest)是由 Breiman 于 2001 年提出的集成学习方法,本质是由多个决策树模型组成的“森林”,通过投票或平均的方式提高预测精度和泛化能力。
✅ 支持分类与回归
✅ 可评估变量重要性
✅ 对缺失值、异常值不敏感
✅ 对高维数据表现稳定
它尤其适用于地理与农学中变量多、关系复杂的建模任务,如:
-
土壤性质预测
-
农业产量估算
-
土壤重金属空间建模
-
土地利用类型识别
🧪 二、基本原理与核心思想
随机森林是典型的 “Bagging + 随机特征选择” 模型:
-
Bagging(Bootstrap Aggregation):从原始数据中随机有放回地抽样,构造多个训练集
-
建树:对每个训练集训练一棵决策树,但每次分裂节点只在随机选择的变量子集上进行
-
集成预测:分类任务用多数投票法,回归任务用平均值
💡 这样做提升了模型的多样性,减少过拟合,提高预测稳定性!