更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
本文整理自火山引擎开发者社区技术大讲堂第四期演讲,主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。
数据湖仓开源趋势
趋势一:数据架构向 LakeHouse 方向发展
LakeHouse 是什么?简言之,LakeHouse 是在 DataLake 基础上融合了 Data Warehouse 特性的一种数据方案,它既保留了 DataLake 分析结构化、半结构化、非结构化数据,支持多种场景的能力,同时也引入了 Data Warehouse 支持事务和数据质量的特点。LakeHouse 定义了一种叫我们称之为 Table Format 的存储标准。Table format 有四个典型的特征:
-
支持 ACID 和历史快照,保证数据并发访问安全,同时历史快照功能方便流、AI 等场景需求。
-
满足多引擎访问:能够对接 Spark 等 ETL 的场景,同时能够支持 Presto 和 channel 等交互式的场景,还要支持流 Flink 的访问能力。
-
开放存储:数据不局限于某种存储底层,支持包括从本地、HDFS 到云对象存储等多种底层。
-
Table 格式:本质上是基于存储的、 Table 的数据+元数据定义。
具体来说,这种数据格式有三个实现:Delta Lake、Iceberg 和 Hudi。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在存储介质上面。这三者相似的需求以及相似的架构,导致了他们在演化过程中变得越来越相似。
可以看到,三种数据格式都基本能覆盖绝大部分特性。
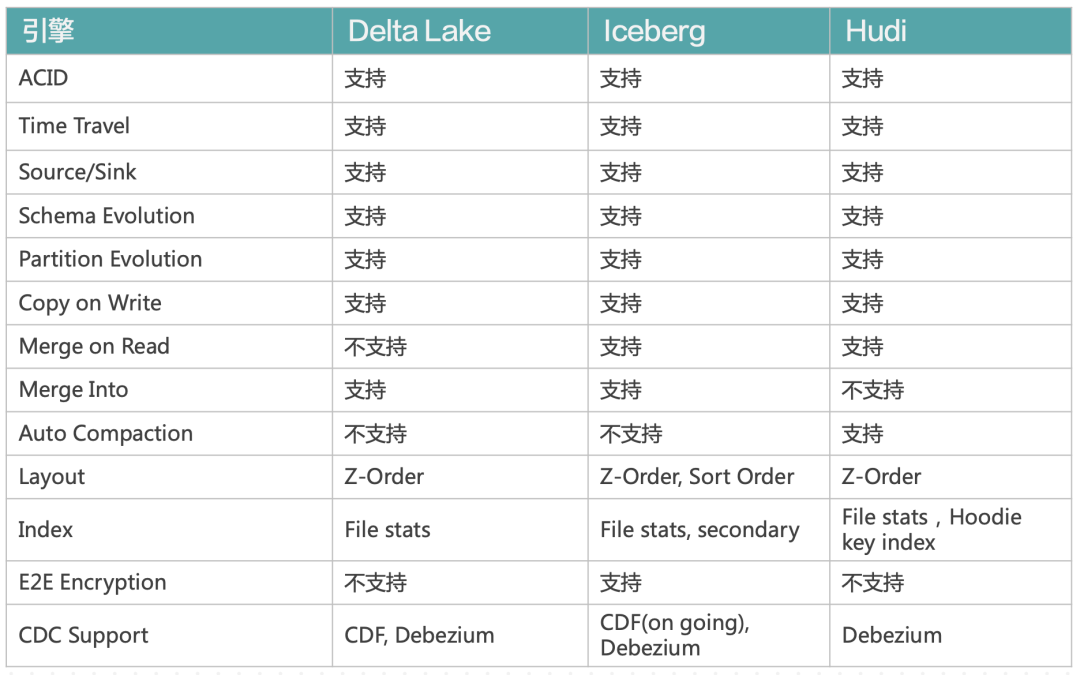
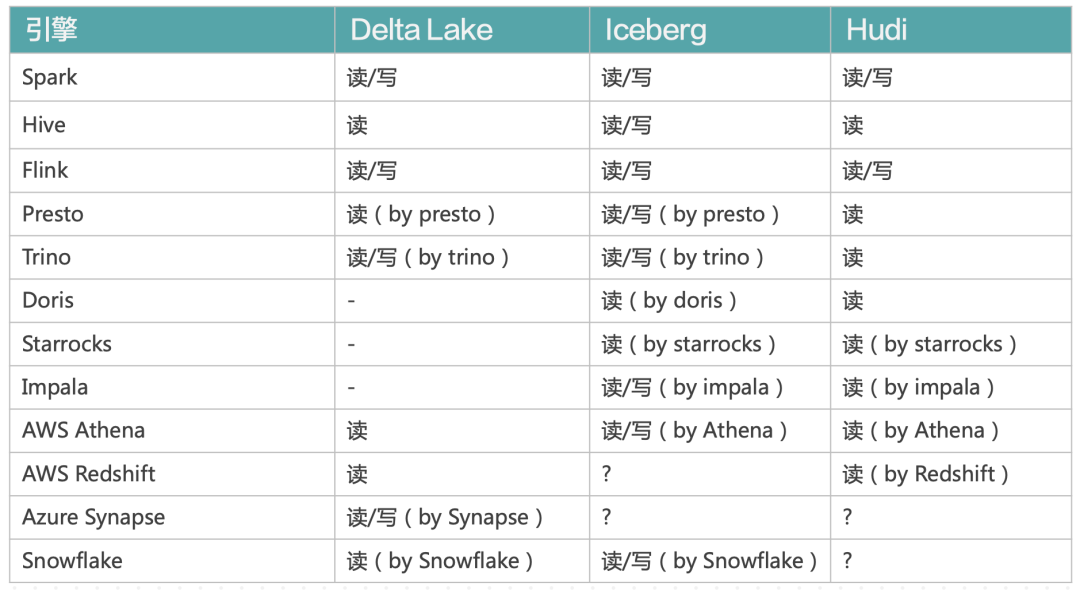
下表给出了三种格式在生态方面的支持情况(截止 2022/8/18):
最后考虑的问题点:Table Format 是不是一个终极武器?我们认为答案是否定的。主要有几方面的原因:
-
使用体验离预期有差距:由于 Table Format 设计上的原因,流式写入的效率不高,写入越频繁小文件问题就越严重;
-
有一定维护成本:使用 Table Format 的用户需要自己维护,会给用户造成一定的负担;
-
与现有生态之间存在 gap:开源社区暂不支持和 Table format 之间的表同步,自己做同步又会引入一致性的问题;
-
对业务吸引不够:由于以上三点原因,Table Format 对业务的吸引力大打折扣。
如何去解这些问题呢?现在业界已经有基于 Table Format 应用的经验、案例或者商业公司,比如 Data Bricks、基于 Iceberg 的 Tabluar 以及基于 Hudi 的 OneHouse 公司。
通过这些公司的商业产品,底层组件、运维和优化都交由商业产品解决,有效减轻负担。而且商业公司还有能力提供上层的 ETL 管道等产品,使得用户可以更容易从原有架构迁移。因此,LakeHouse 并不等于 Table Format,而是等于 Table Format 加上一些上层建筑。这些上层建筑由商业公司提供,但除此之外也期望能来来自社区。
趋势二:计算向精细化内存管理和高效执行方向发展
数据湖的本质是起 task ,然后做计算。当引擎逐渐完善之后,对于性能需求逐步上升,不可避免地要朝精细化的内存管理以及高效执行方向发展。目前,社区出现了两个趋势:Native 化和向量化(Vectorized)。
第一,Native 化。
Native 化有两个典型的代表。
-
Spark:去年官宣的 Photon 项目,宣称在 tpcs 测试集上达到 2X 加速效果。
-
Presto: Velox native 引擎。Velox 引擎现在不太成熟,但是根据 Presto 社区官方说法,可以实现原来 1/3 的成本。由此可猜测,等价情况下能获得 3X 性能提升。
除了以上两者,近几年热门的 ClickHouse 和 Doris 也是 Native 化的表现。
第二,向量化。
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。
Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。
但现在,向量化是一个更好的选择,因为向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的特性,如 SIMD,Pipeline 执行等。
趋势三:多模计算,即组件边界逐渐模糊,向全领域能力扩展
Spark ,最早为批处理引擎,后补了 Streaming 和 AI 的能力;Trino 为 OLAP 引擎,现在也在大力发展批式计算;Flink 为流引擎,后补了批式计算和 AI 能力;Doris 则在加强 multi-catalog……
各家引擎都在拓展用户场景。这种多模计算产生的结果是,对于各个领域内差别不大的场景,技术会逐渐收敛到一个最优解,最终只有一两个引擎获得成功。差别比较大的场景,则在每个场景形成一两个寡头,寡头跨场景的能力则竞争力很弱。
趋势四:分析实时化
大数据最早是批式计算的形式,但理想状态是纯流式方式。分析实时化的表现有(近)实时引擎和流引擎。
-
(近)实时引擎
ClickHouse:近实时 OLAP 引擎,宽表查询性能优异
Doris:近实时全场景 OLAP 引擎
Druid:牺牲明细查询,将 OLAP 实时化,毫秒级返回
-
流引擎
Flink:流计算逐步扩大市场份额
Kafka SQL:基于 Kafka 实现实时化分析
Streaming Database:Materialize 和 RisingWave 在开发的一种产品形态,效果类似于 Data Bricks 的 Data Live Table
企业构建数据湖仓的挑战
企业在构建数据湖仓时面临的挑战分为以下 5 个方面:
-
整体数据链路复杂:即使是开发一个小的 APP,要搭建整个数据链路也很复杂,比如数据回流需要写数据库;日志要回流,要基于回流数据做指标计算,回流数据还需要转储以及 CDC;基于转储数据还要做 ETL 分析。
-
湖仓需求多样:如果存在机器学习需求,即要完成特征工程等一系列步骤,这些步骤也催生了数据湖仓的多种需求,包括支持批式、流失计算和交互式数据科学等各种场景。
-
湖仓数据来源广泛:包括业务交易数据、业务资产数据、用户行为数据、上下游产生的中间数据等。
-
数据开发中参与角色众多:包括管理者、一线业务人员、业务开发、基础设施参与人员等等。
-
企业往往需要根据平台进行二次开发:基础设施无法直接对接业务,根据业务特点灵活定制平台,解决方案平台化、产品化等。
由此衍生出一系列问题,包括稳定性、扩展性、功能、性能、成本、运维、安全、生态这 8 个方面。企业如果要单方面解决这些问题,哪怕是其中一个,可能也要花费巨大的人力物力。
火山引擎 EMR 即是这样一个平台。下一部分将主要介绍,火山引擎 EMR 如何帮助用户解决这些挑战以及如何基于 EMR 构建企业级数据湖仓。
基于火山引擎 EMR 构建企业级数据湖仓
火山引擎 EMR
一句话总结,火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。火山引擎 EMR 有以下 4 个特点:
-
开源兼容 &开放环境:100% 兼容社区主流版本,满足应用开发需求;同时提供半托管的白盒环境,支持引导操作与集群脚本能力。
-
引擎企业级优化:引入了 Spark、Flink 等核心引擎的企业级特性优化及安全管理。
-
Stateless 云原生湖仓:把状态外置做成存算分离的架构。
-
云上便捷运维:提供一站式云托管运维的能力与组件,让用户能够分钟级地创建和销毁集群,同时提供精细化的集群运维监控告警能力。
Stateless、瞬态集群
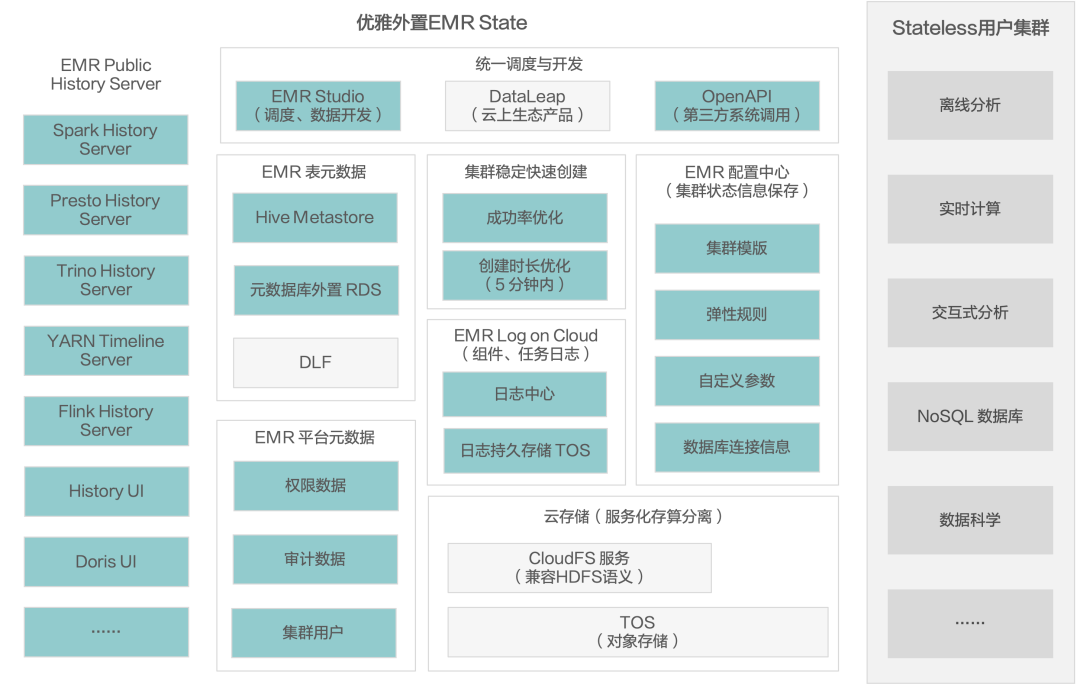
Stateless 是指把所有有状态的数据外置,让用户的计算集群变成无状态的集群。这些有状态的组件包括:History Server、表的元数据、平台的元数据、审计日志、中间数据等。完全外置的 Stateless 集群可以达成极致的弹性伸缩状态。状态外置有两个重要的组件,Hive Metastore 和 各个 Public History Server。
Hive Metastore Service: 中心化元数据托管服务
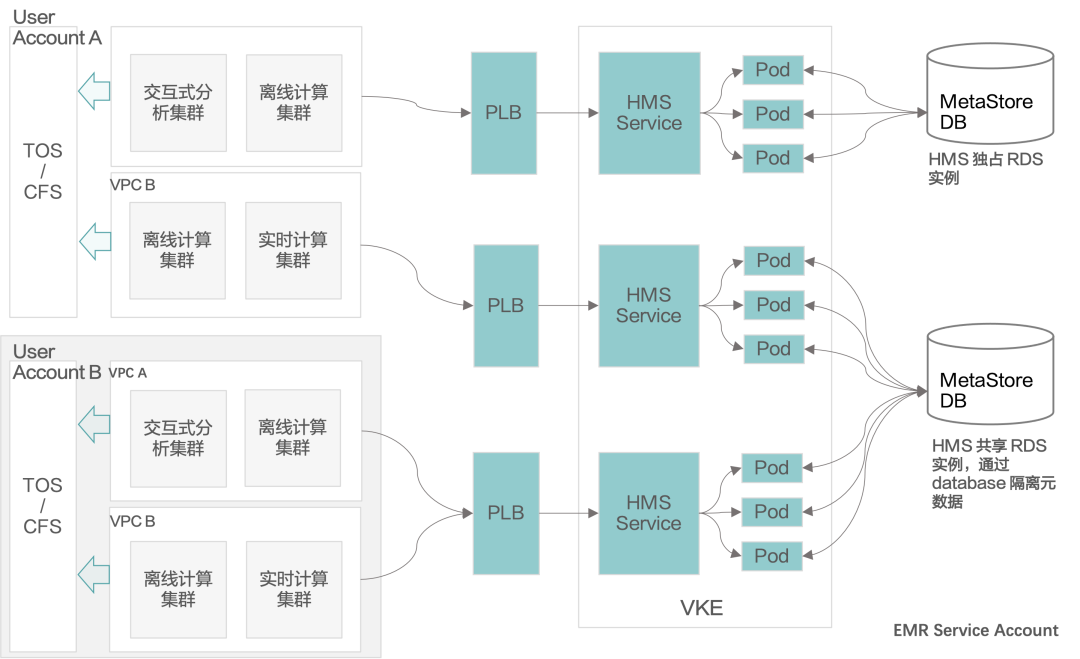
Hive Metastore 定位为公共服务,用户可以选择独占或共享 Metastore 实例。如果用户期望节省成本,或者为公司用户,那么两个部门之间可以使用一个 Hive Metastore service;而对于一些要求比较高的部门,可以单独建一个 Metastore Service 的实例。
持久化的 History Server 服务
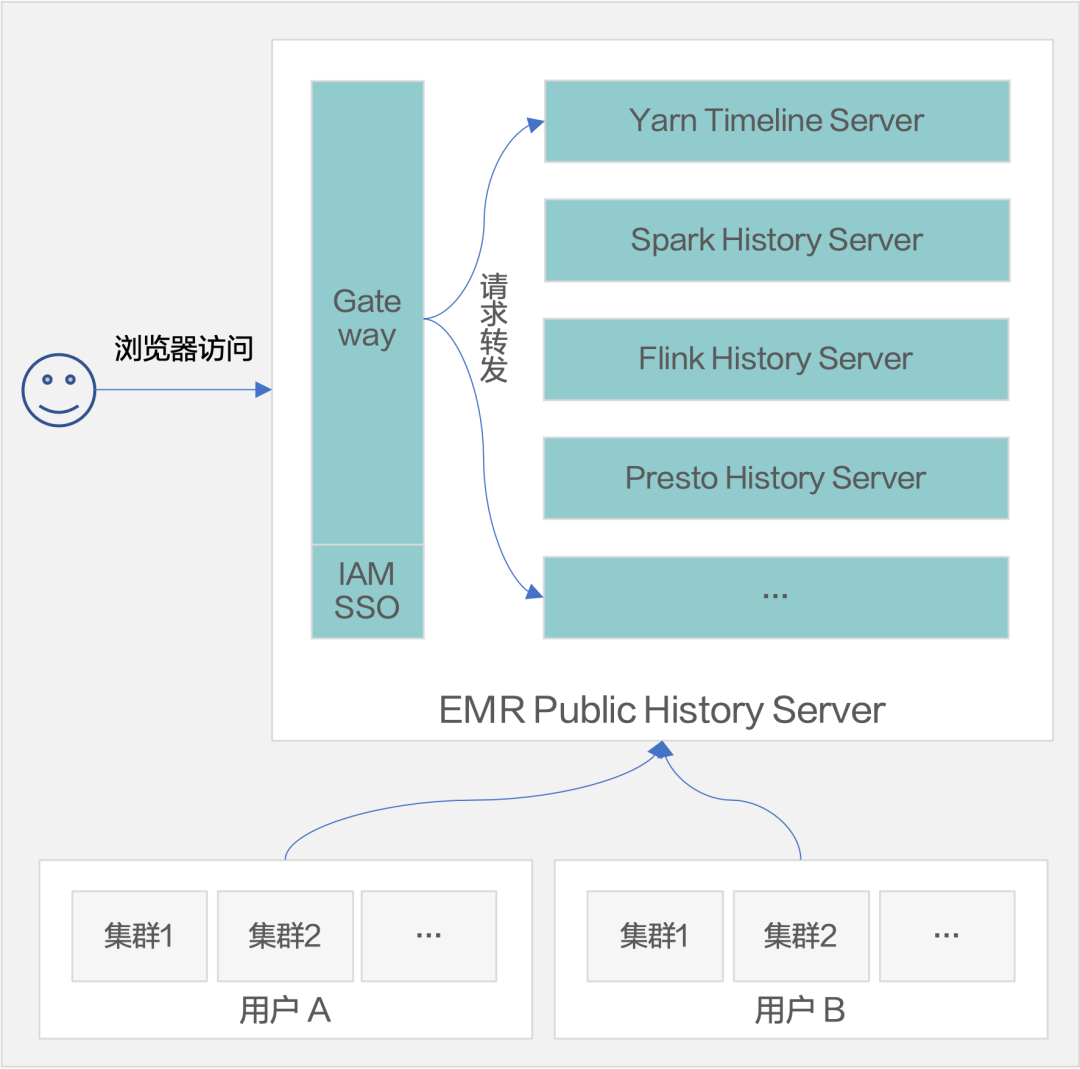
YARN、Spark、Flink、Presto 等几种 History Server 都从引擎中被剥离出来,形成 Public History Server 服务。该服务有几个特点:
-
独立于集群之外运行的常驻服务;
-
提供持久化的 History 数据存储。当该集群销毁之后,历史数据还可保存 60 天;
-
提供原生 History Server UI,用户不会感觉生疏;
-
租户间 History 数据隔离;
-
更友好的使用体验:相对于组件内置 History Server, 独立服务需要绑定公网并开放 8443 端口才能访问,Public History Server 真正做到了开箱即用,无需其它额外配置。同时集成 IAM SSO 准入认证,通常情况下用户从 EMR 管控端跳转到 Public History Server 可以实现无感 SSO 认证登录,无需再次输入用户登录凭证。
存算分离,弹性伸缩
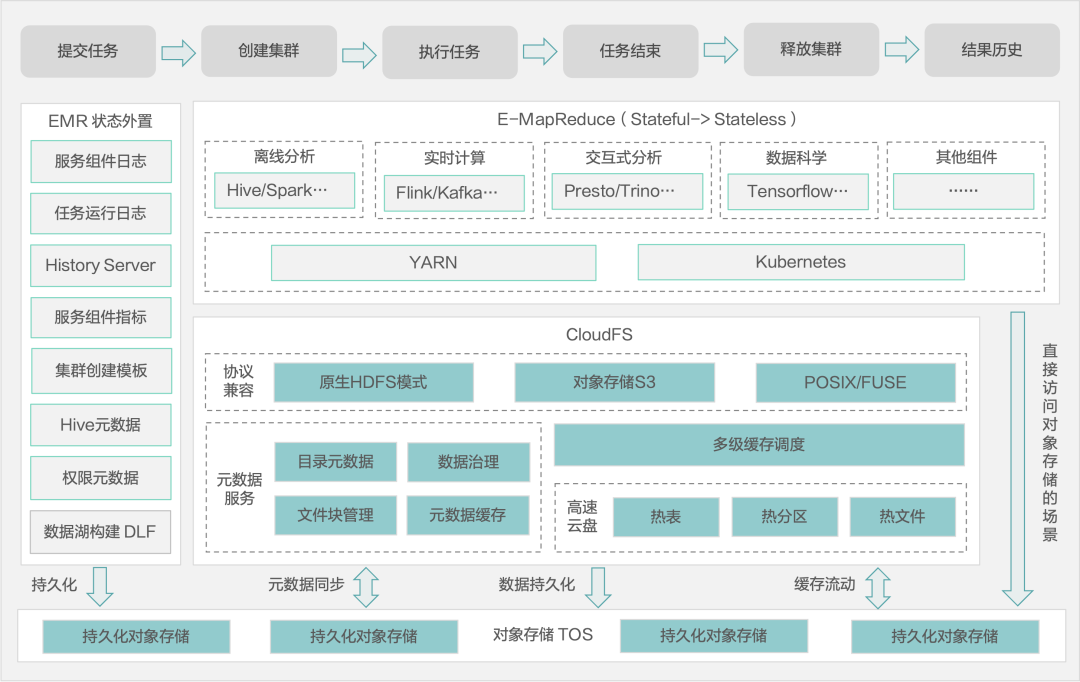
火山引擎 EMR 具备 CloudFS 和 TOS 两个数据存储层,冷数据可以存储在对象存储 TOS 上。CloudFS 则构建在 TOS 层之上,提供兼容 HDFS 语义存储,提供缓存加速功能,可以把温数据放在 CloudFS 。在引擎内部内置一些本地缓存,用于缓存热数据。分层缓存能够弥补企业上云之后,数据因保存在对象存储所造成的性能损失。另外 Cloud FS 提供 HDFS 的语义,可便于开源组件切入。
云托管,易运维
在管控层面,火山引擎 EMR 提供了很多工具,便于管理员管理整个集群,包括集群管理、服务管理、节点管理、日志中心、配置中心、用户权限、弹性伸缩等,用户可以到火山引擎上建一个最小规格集群体验。
用户友好
在用户侧,火山引擎 EMR 提供了作业管理界面,提供全局视角查看集群资源消耗、异常情况等。同时该界面提供一键查看作业详情,作业诊断等功能,包括不限于异常探测、运行资源消耗、优化建议等。未来,期望能够基于作业提供优化建议,比如参数调整等。
构建企业级数据湖仓的最佳实践
接下来我们通过几个案例来看看基于火山引擎 EMR 构建的企业级数据湖仓最佳实践。
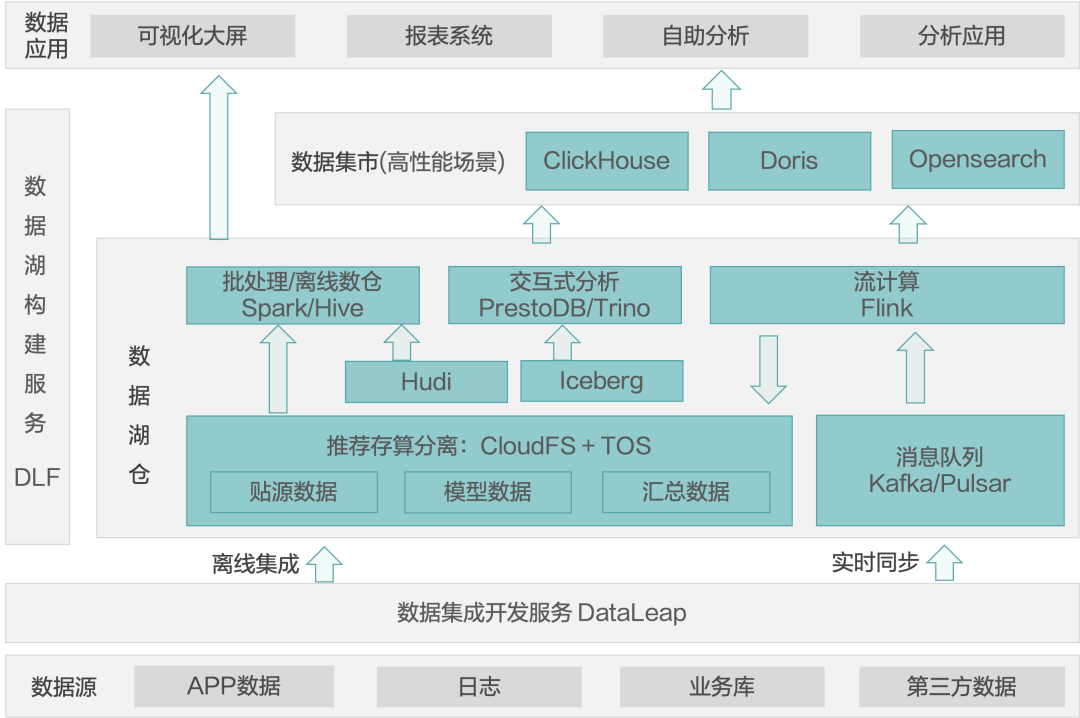
案例 1:多元化分析平台
多元化分析指兼具离线分析场景与交互式分析的场景,以及高性能场景,以便支持应用层直接使用数据集市中的数据。以某互联网企业平台部门距离,用户期望基于业务数据构建分析平台,支持多种分析负载,包括可视化大屏、报表系统、自助分析以及开发分析应用等。
要搭建这种多元化分析平台,用户可以通过 DataLeap 进行数据开发,让数据通过离线方式或实时同步的方式流入数据库仓。然后,基于 Spark/Hive/Presto/Trino 进行批式数据分析和交互式分析。对于流式处理,可以把数据转储到 Cloud FS 和 TOS,基于流式做出一个计算结果,上传到 Clickhouse 和 Doris 来满足一些高性能分析的场景。
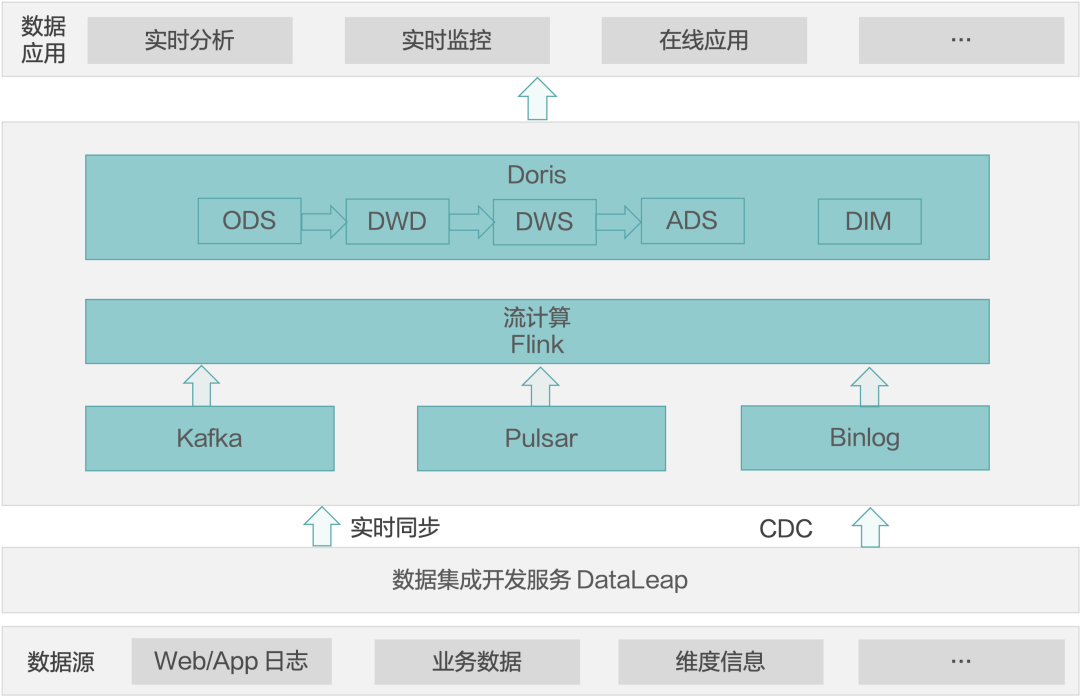
案例 2:高性能实时数仓
某头部直播业务的实时数仓 达到 100+W/s 数据入仓速度,且支持横向扩展。通过流式计算引擎计算后,明细数据进入 Doris 集群 ODS 层,数据聚合计算后进入 DWS 层,数据指标经计算后存入 ADS 层,且数据支撑在线更新。由 Doris 对数据应用层提供服务,支持在线、离线查询分析,支持几十万级 QPS。
该业务数据量比较大,同时对数据分析的时间性要求高,希望业务人员能通过实时查看业务指标的变化快速做出反应,达到精准营销的效果。
该方案是通过 Flink 把数据直接流入 Doris,即原始数据直接到 Doris 的 ODS 层。由于 Doris 本身性能可以提供时延很短的查询体验,因此基于 Doris 完成 ODS > DWD > DWS > ADS 的转化。
案例 3:实时计算
对性能要求高的场景,目前推荐使用实时计算方式,让数据省略中间各层。在 Flink 里完成计算,结果直接写入 RDS/ Redis。以某车联网公司为例,实时采集运营的 500 辆新能源汽车行驶和电池数据进行实时分析和告警,每 5 分钟采集一次,日增量在 10GB,数据通过消息队列 Kafka 或 Pulsar 汇聚到大数据平台,使用 Flink 流计算引擎进行毫秒级实时指标计算,计算结果存储到 RDS 中供平台进行实时数据展示。
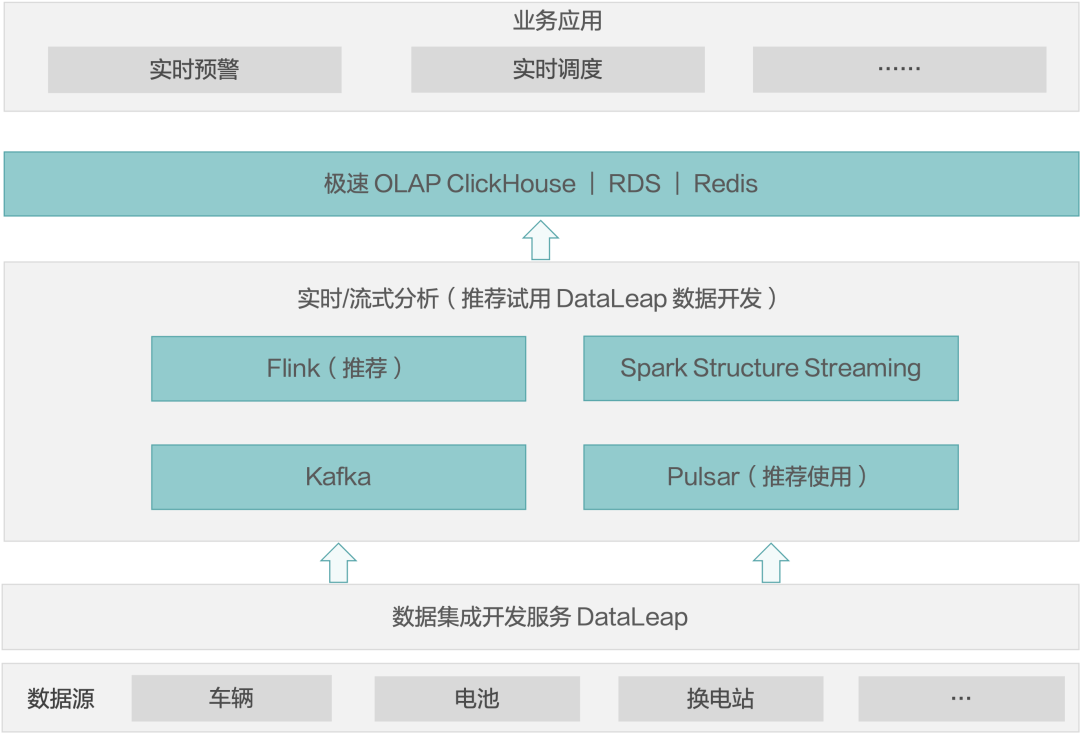
案例 4:在线机器学习
在在线机器学习场景下,数据通过离线的方式存到数据湖仓。离线数据可以通过 Spark 进行特征抽取及特征工程,并把提取出来的特征返存到湖仓或者 HBase 等键值存储。
基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型服务中。在在线方面,数据通过 Kafka 流入 Flink 进行在线特征抽取,然后把在线特征放在 Redis。同时在线部分的增量数据可用 TensorFlow 进行增量训练,把增量模型也导入模型服务里。模型服务根据原来批式训练出来的模型和增量模型做成实时的 AI 服务,可满足实时风控等对时间要求比较高的场景。
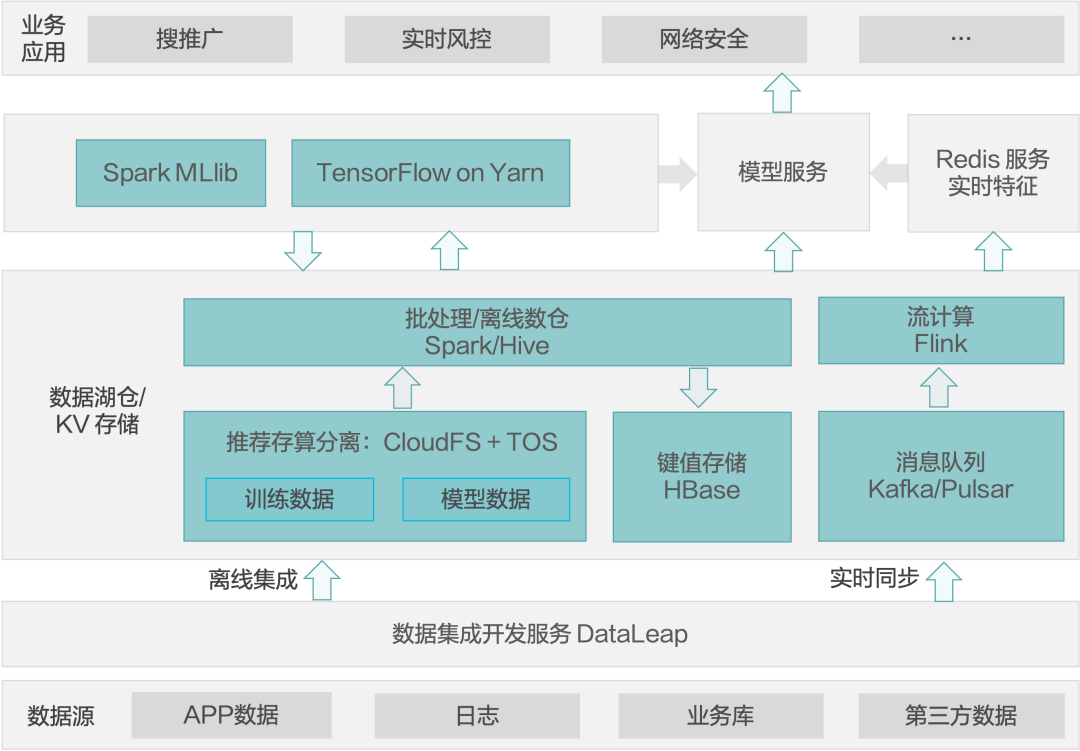
火山引擎 EMR 湖仓方向未来规划
最后与大家分享火山引擎 EMR 在湖仓方向未来的规划。
-
数据加速:期望进一步加速数据分析。企业上云之后,痛点之一为数据放到对象存储之后性能是否会下降。要解决该问题,主要在数据缓存(包括文件级 Cache 和 Page 级 Cache)和索引方面(包括 Bitmap、Bloom Filter)做一些工作。
-
解决刚需痛点场景:分析 CDC 数据和多路径,解决数据湖仓割裂的问题。对于后者,可以尝试:
Doris 直接加速访问 HMS 中的 Hive/Iceberg/Hudi 表,实现湖仓互通。
持续优化基于 Iceberg 数据湖方案,使得性能接近仓的体验。
-
拥抱开源:希望将工作合入到开源社区,包括 Data Block Alluxio 的功能和性能优化;Doris MultiCatalog、元数据服务化、冷热分离优化;Iceberg 二级索引等。
-
AI4Data(数据智能管家):我们长期规划是成为一个智能数据管家,具体包括:
自动诊断高频低性价比 SQL 及作业;
自动优化用户 SQL 及作业,智能地从数据分布、Cache、Index、物化视图等维度来优化用户账单;
智能运维:
集群负载过高时,自动扩容;负载降低时,自动收缩。
集群节点故障时,做到用户完全无感知地 Failover。
自动地实现数据均衡分布。
-
产品打磨:在产品侧,第一目标是打磨产品,先把产品底座做坚实,并在管控方面(包括创建集群体验优化、弹性伸缩优化等)、作业开发与管理方面与周边生态方面做进一步打磨。
活动推荐
12 月 20 日 19:00,《火山引擎 VeDI 数据中台架构剖析与方案分享》
本期直播分享将聚焦字节跳动数据中台建设经验,在存算分离、湖仓一体、ServerLess 等技术发展趋势下,从企业数仓架构选择、数据湖解决方案与应用实践,以及一站式数据治理等角度,为企业构建自身数据中台提供思路和启发。
戳链接,立即进群、观看直播、赢取好礼:11dr.cn/d/5xvloe9D7

点击跳转火山引擎 E-MapReduce官网
了解更多


![[附源码]Python计算机毕业设计飞羽羽毛球馆管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/a3b15daef2cb4ab881d9ee97f7ebbb57.png)