那么你可能会说,是不是我无限制地增加从库的数量就可以抵抗大量的并发呢? 实际上并不是的。因为随着从库数量增加,从库连接上来的 IO 线程比较多,主库也需要创建同样多的 log dump 线程来处理复制的请求,对于主库资源消耗比较高,同时受限于主库的网络带宽,所以在实际使用中,一般一个主库最多挂 3~5 个从库。
当然,主从复制也有一些缺陷, 除了带来了部署上的复杂度,还有就是会带来一定的主从同步的延迟,这种延迟有时候会对业务产生一定的影响
2.1.4 数据量增加带来的性能问题
随着业务的增长,数据库中的数据量也会随着增加,由于最早开发时主要是为了赶进度,数据都是单表存储,因此单表数据量增加之后,导致数据库的查询和写入都造成非常大的性能开销,具体体现在。
•单表数据量过大,千万级别到上亿级别,这时即使你使用了索引,索引占用的空间也随着数据量的增长而增大,数据库就无法缓存全量的索引信息,那么就需要从磁盘上读取索引数据,就会影响到查询的性能。•数据量的增加也占据了磁盘的空间,数据库在备份和恢复的时间变长•不同模块的数据,比如用户数据和用户关系数据,全都存储在一个主库中,一旦主库发生故障,所有的模块儿都会受到影响•在 4 核 8G 的云服务器上对 MySQL5.7 做 Benchmark,大概可以支撑 500TPS 和 10000QPS,你可以看到数据库对于写入性能要弱于数据查询的能力,那么随着系统写入请求量的增长,对于写请求的耗时也会增加(更新数据操作需要同步更新索引,数据量较大的情况下更新索引耗时较长)
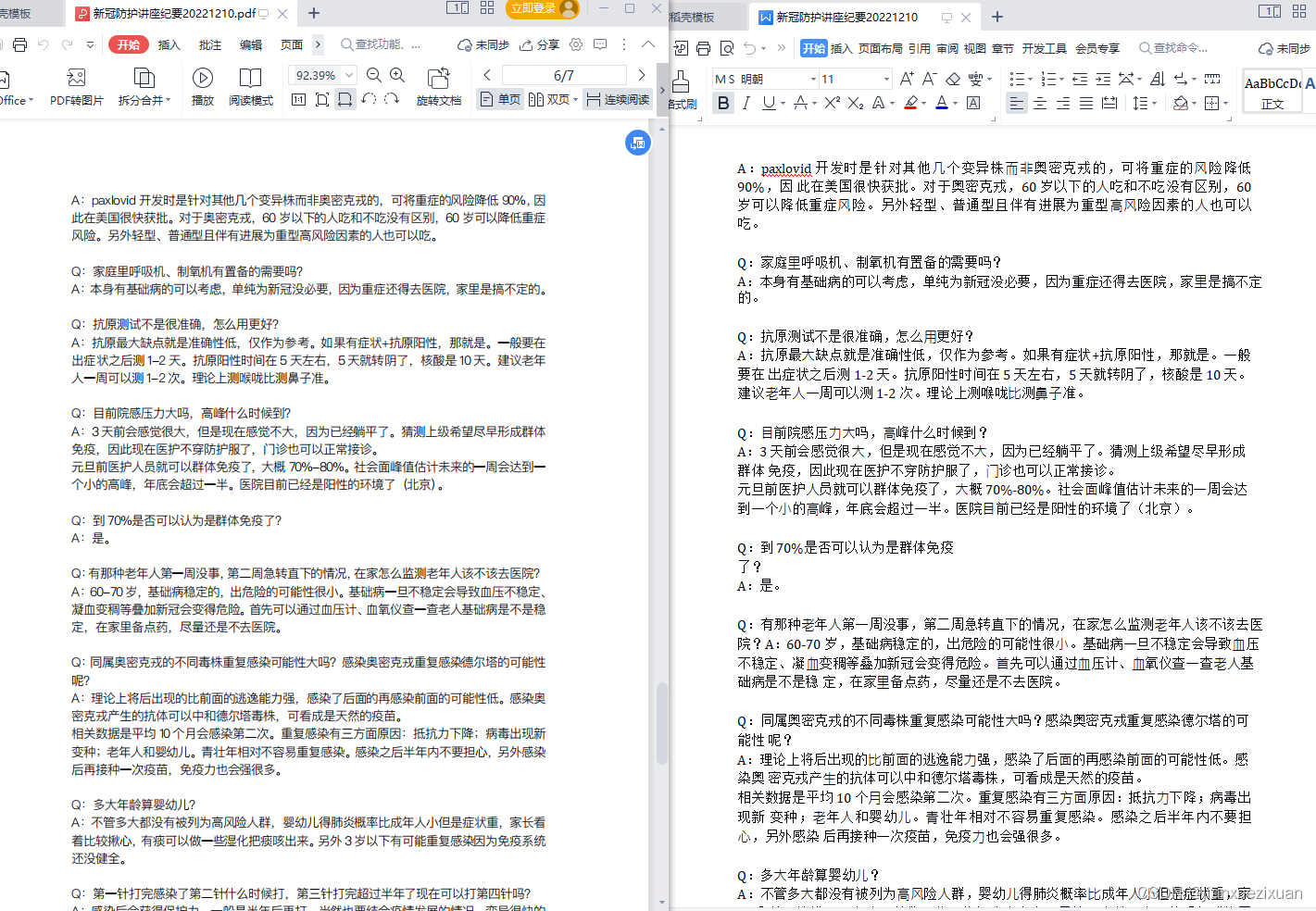
在这类场景中,解决方案就是对数据进行分片,也就是分库分表的机制,如图2-4所示。数据拆分的核心降低单表和单库的数据IO压力,从而提升对数据库相关操作的性能。
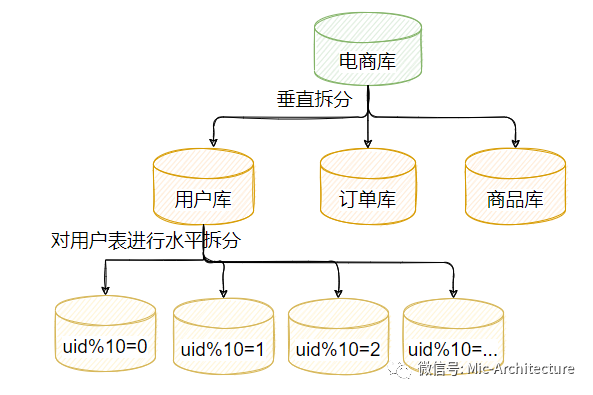
image-20210625144502558
图2-4
2.2 不同存储设备带来的性能提升
前面我们了解了对于传统关系型数据库的一些优化思路,整体来说,通过优化之后能够提升程序访问数据库的计算性能。但是还是有一些情况,即便是优化之后,使用传统关系型数据库无法解决的,比如。
•当数据量达到TB级别时,传统关系型数据库基本做了分库分表,单表数据量也是非常大的。•对于一些不适合用关系型数据库存储的数据,传统数据库无法做到,所以数据库本身的特性限制了多样性数据的管理。
所以nosql出现了,大家对nosql这个概念已经不陌生了,它是指不同于传统关系型数据库的其他数据库系统的一个统称,它不使用SQL作为查询语言,并且相对于传统关系型数据库来说,
它提供了更高的性能以及横向扩展能力,非常适合互联网项目中高并发且数据量较大的场景中,如图25所示,表示目前比较主流的不同类型的nosql数据库。
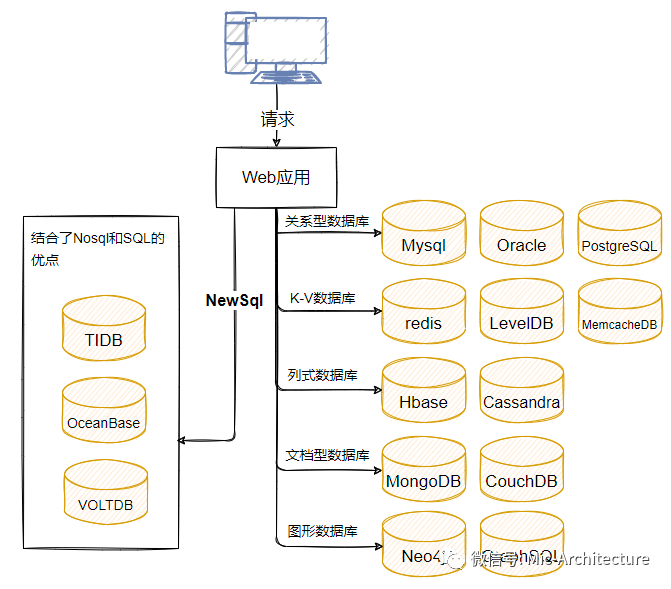
image-20210625164052410
图2-5 不同的NoSql数据库
这个网站上记录了所有的Nosql框架
https://hostingdata.co.uk/nosql-database/
2.2.1 Key-Value数据库
key-value数据库,典型的代表就是Redis、Memcached,也是目前业内非常主流的Nosq数据库。
之所以在IO性能方面比传统关系型数据库高,有两个点
•数据基于内存,读写效率高•KV型数据,时间复杂度为O(1),查询速度快
KV型NoSql最大的优点就是高性能,利用Redis自带的BenchMark做基准测试,TPS可达达到接近10W的级别,性能非常强劲。同样的Redis也有所有KV型NoSql都有的比较明显的缺点:
•查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间•内存是有限的,无法支持海量数据存储•同样的,由于KV型NoSql的存储是基于内存的,会有丢失数据的风险
基于Key-Value数据库的特性,这类数据库比较适用于缓存的场景。
•读多写少•读取能力强•可以接受数据丢失
这类存储相比于传统的数据库的优势是极高的读写性能,一般对性能有比较高的要求的场景会使用,主要使用场景。
•用来做分布式缓存,提升程序处理效率。•用来做会话数据存储•其他功能性特性,比如消息通信、分布式锁、布隆过滤器•微博的feed流,早期就是用了redis实现。(持续更新并呈现给用户内容的信息流。每个人的朋友圈,微博关注页等等都是一个 Feed 流)
2.2.2 列式数据库
我们最早学习数据库,都是基于以二维表形式存储,每一行代表一条完整的数据。大部分传统的关系型数据库中,都是以行来存储数据。不过最近几年,列式存储也逐步被广泛运用在大数据框架中。
行存储和列存储,是数据库底层数据组织的形式的区别,如图2-6所示,数据库表中所有列一次排成一行,以行位单位存储,再配合B+树或者SS-Table作为索引,就能快速通过主键找到相应的行数据。
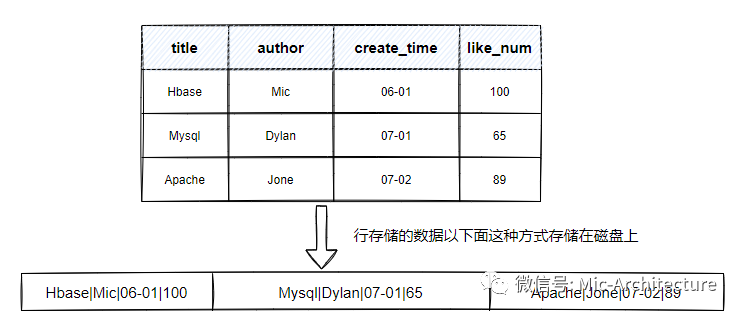
image-20210625202700946
图2-6
在实际应用中,大部分的操作都是以实体(Entity)为单位,也就是大部分CRUD操作都是针对一整行记录,如果需要保存一行数据,只需要在原来的数据后追加一行数据即可,所以数据的写入非常快。
但是对于查询来说,一个典型的查询操作需要遍历整个表,分组、排序、聚合等,对于行存储来说,这样的操作的优势就不存在了,更惨的是,分析型SQL可能不需要用到所有的列,仅仅只需要对某些列进行运算即可,但是那一行中和本次操作无关的列也必须要参与到数据扫描中。
比如,如图2-7所示,现在我想统计所有文章的总的点赞数量,作为行存储的系统,数据库会怎么操作呢?
•首先需要把所有行的数据加载到内存•然后对like_num列做sum操作
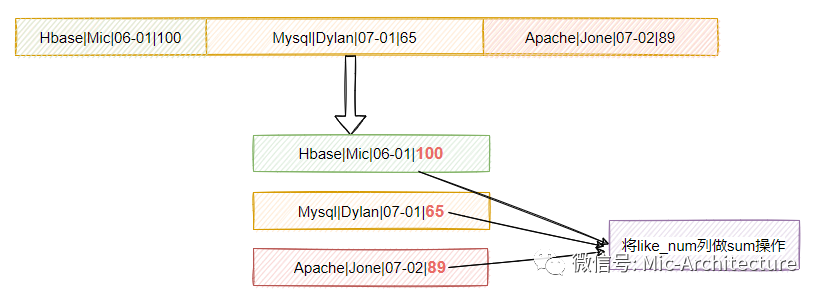
image-20210625204523910
图2-7
行式存储对于OLAP场景而言,优势就不存在了,所以就引入了列式存储。
OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询
如图2-8所示,列式存储是将每一列数据组织在一起,它方便对于列的操作,比如前面说的统计like_num之和,按列存储之后只需要一次磁盘操作就可以完成三个数据的汇总,所以非常适合OLAP的场景。
•当查询语句只涉及部分列时,只需要扫描相关列•每一列数据都是相同类型,彼此间的关联性更大,对列数据压缩的效率较高。
但是对于OLTP来说不是很友好,因为一行数据的写入需要修改多个列。

image-20210625221307500
图2-8
列式存储在大数据分析中使用非常多,比如推荐画像(蚂蚁金服的风控)、是空数据(滴滴打车的归集数据)、消息/订单(电信领域、银行领域)不少订单查询底层的存储。Feeds流(朋友圈类似的应用)等等。
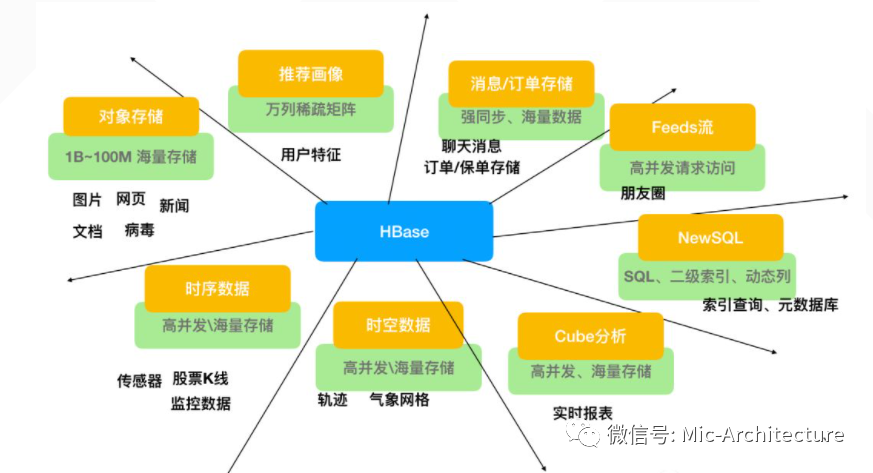
image-20210625220018008
图2-9
2.2.3 文档型数据库
传统的数据库,所有信息会被分割成离散的数据字段,保存在关系型数据库中,甚至对于一些复杂的场景,还会分散在不同的表结构中。
举个例子,在一个技术论坛中,假设对于用户、文章、文章评论表的关系图如图2-10所示。
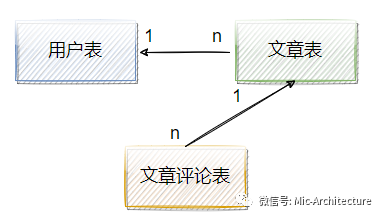
image-20210625225801200
图2-10
那用户点一篇文章,里面要显示该文章的创建者、文章详情、文章的评论,那么服务端要做什么呢?
•查找文章详情•根据文章中的uid查找用户信息•查询该文章的所有评论列表•查询每个评论的创建者名字
这个过程要么就是多次数据库查询,要么就是使用一个复杂关联查询来检索,不管怎么做,都不是很方便。而文档数据库就可以解决这样的问题。
文档数据库是以文档单位,具体的文档形式有很多种,比如(XML、YAML、JSON、BSON)等,文档中存储具体的字段和值,应用可以使用这些字段进行查询和数据筛选。
一般情况下,文档中包含了实体中的全部数据,比如图2-10的结构,我们可以直接把一篇文章的基本要素信息构建成一个完整的文档保存到文档数据库中,应用程序只需要发起一次请求就可以获取所有数据。b
Article:{ Creator:{ uid: ‘’, username: ‘’ }, Topic: { title: ‘’, content: ‘’ }, Reply: [ { replyId:, content:‘’ }, { replyId:, content:‘’ } ]``}
MongoDB是目前最流行的Nosql数据库,它是一种面向集合、与模式(Schema Free)无关的文档型数据库。它的数据是以“集合”的方式进行分组,每个集合都有单独的名称并可以包含无线数量的文档,这种集合与关系型数据库中的表类似,唯一的区别就是它并没有任何明确的schema。
在数据库中,schema(发音 “skee-muh” 或者“skee-mah”,中文叫模式)是数据库的组织和结构,schemas 和schemata都可以作为复数形式。模式中包含了schema对象,可以是表(table)、列(column)、数据类型(data type)、视图(view)、存储过程(stored procedures)、关系(relationships)、主键(primary key)、**外键(**foreign key)等。数据库模式可以用一个可视化的图来表示,它显示了数据库对象及其相互之间的关系
如图2-11所示, 将数据存储在类似 JSON 的灵活文档中,这意味着字段可能因具体文档而异,并且数据结构可能随着时间的推移而变化。

img
图2-11
MongoDB没有“数据一致性检查”、“事务”等,不适合存储对数据事务要求较高的场景,只适合放一些非关键性数据,常见应用场景如下:
•使用Mongodb对应用日志进行记录•存储监控数据,比如应用的埋点信息,可以直接上报存储到mongoDB中•MongoDB可以用来实现O2O快递应用,比如快递骑手、快递商家的信息存储在MongoDB,然后通过MongoDB的地理位置查询,方便用来查询附近的商家、骑手等功能

。
2.2.4 图形数据库
图形数据库,表示以数据结构“图”作为存储的数据库。图形数据存储管理两类信息:节点信息和边缘信息。节点表示实体,边缘表示这些实体之间的关系。节点和边缘都可以包含一些属性用于提供有关该节点或边缘的信息(类似于表中的列)。
边缘还可以包含一个方向用于指示关系的性质。
图形数据存储的用途是让应用程序有效执行需遍历节点和边缘网络的查询,以及分析实体之间的关系。如图2-12所示,显示了已结构化为图形的组织人员数据。
实体为员工和部门,边缘指示隶属关系以及员工所在的部门。在此图中,边缘上的箭头表示关系的方向。
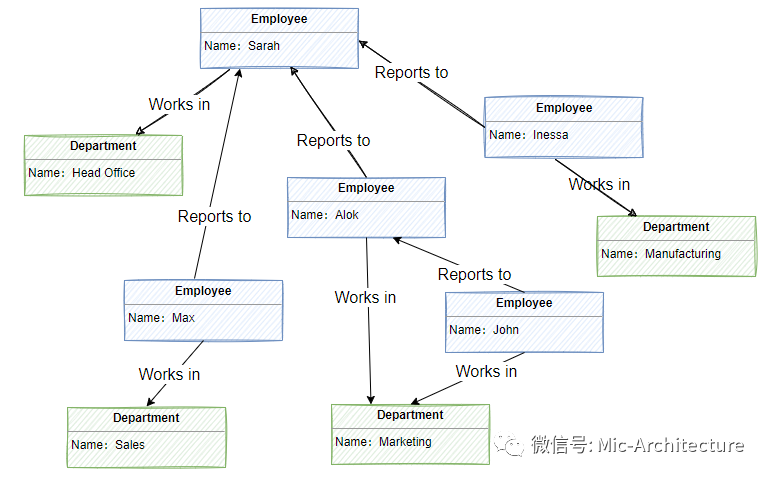
image-20210625180249817
图2-12
使用此结构可以简单直接地执行类似于“查找 Sarah 的直接或间接下属”或“谁与 John 在同一个部门工作?”的查询。对于包含大量实体和关系的大型图形,可以快速执行复杂的分析。多个图形数据库提供一种可用于高效遍历关系网络的查询语言。比如:关系、地图、网络拓扑、交通路线等场景。
2.2.5 NewSql
NewSql也是最近几年出来的概念,想必大家或多或少都有听过,NewSql是Nosql发展之后的下一代数据存储方案。
前面我们了解了Nosql的优势。
•高可用性和可扩展性,自动分区,轻松扩展•不保证强一致性,性能大幅提升•没有关系模型的限制,极其灵活
但是有些优势在某些场景下不是很适合,比如不保证强一致性,对于普通应用来说没有问题,但是对于一些金融级的企业应用来说,
强一致的需求会比较高。另外,Nosql不支持SQL语句,不同的Nosql数据库都是有自己独立的API来进行数据操作,相对来说比较麻烦和复杂。
所以NewSql出现了,简单来说,newSQL 就是在传统关系型数据库上集成了 noSQL 强大的可扩展性,传统的SQL架构设计基因中是没有分布式的,而 newSQL 生于云时代,天生就是分布式架构。
NewSQL 的主要特性:
•SQL 支持,支持复杂查询和大数据分析。•支持 ACID 事务,支持隔离级别。•弹性伸缩,扩容缩容对于业务层完全透明。•高可用,自动容灾
商用NewSql
•Spanner、F1:谷歌•OceanBase:阿里•TDSQL:腾讯•UDDB:UCloud
2.2.6 总结
在 NoSQL 数据库刚刚被应用时,它被认为是可以替代关系型数据库的银弹,在我看来,也许因为以下几个方面的原因:
•弥补了传统数据库在性能方面的不足;•数据库变更方便,不需要更改原先的数据结构;•适合互联网项目常见的大数据量的场景;
不过,这种看法是个误区,因为慢慢地我们发现在业务开发的场景下还是需要利用 SQL 语句的强大的查询功能以及传统数据库事务和灵活的索引等功能,NoSQL 只能作为一些场景的补充。
2.3 使用Redis优化性能问题
Redis是目前用得非常多的一种Key-Vlaue数据库,我们先来通过一个压测数据了解一下redis和mysql的性能差距。
演示项目:springboot-redis-example
通过jmeter工具分别压测这个项目中的两个url。
•http://localhost:8080/city/{id}•http://localhost:8080/city/redis/{id}
其中,基于mysql访问的接口,吞吐量数据如下,qps=4735/s。

image-20210628143407508
图2-13
基于redis的压测数据,如图2-14所示。

image-20210628143634472
图2-14
可以很明显的看到,在同样的程序中,Redis的QPS要比Mysql的多了1000。
2.3.1 了解Redis
08年的时候有一个意大利西西里岛的小伙子,笔名antirez(http://invece.org/),创建了一个访客信息网站LLOOGG.COM。如果有自己做过网站的同学应该知道,
有的时候我们需要知道网站的访问情况,比如访客的IP、操作系统、浏览器、使用的搜索关键词、所在地区、访问的网页地址等等。在国内,有很多网站提供了这个功能,比如CNZZ,百度统计,国外也有谷歌的Google Analytics。
也就是说,我们不用自己写代码去实现这个功能,只需要在全局的footer里面嵌入一段JS代码就行了,当页面被访问的时候,就会自动把访客的信息发送到这些网站统计的服务器,然后我们登录后台就可以查看数据了。
LLOOGG.COM提供的就是这种功能,它可以查看最多10000条的最新浏览记录。这样的话,它需要为每一个网站创建一个列表(List),不同网站的访问记录进入到不同的列表。如果列表的长度超过了用户指定的长度,它需要把最早的记录删除(先进先出)。
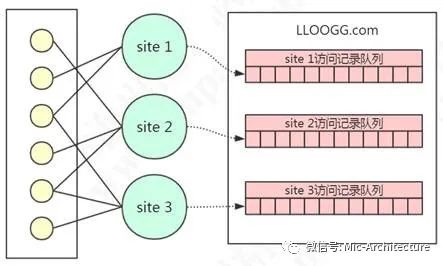
img
图2-15
当LLOOGG.COM的用户越来越多的时候,它需要维护的列表数量也越来越多,这种记录最新的请求和删除最早的请求的操作也越来越多。LLOOGG.COM最初使用的数据库是MySQL,可想而知,因为每一次记录和删除都要读写磁盘,因为数据量和并发量太大,在这种情况下无论怎么去优化数据库都不管用了。
考虑到最终限制数据库性能的瓶颈在于磁盘,所以antirez打算放弃磁盘,自己去实现一个具有列表结构的数据库的原型,把数据放在内存而不是磁盘,这样可以大大地提升列表的push和pop的效率。antirez发现这种思路确实能解决这个问题,所以用C语言重写了这个内存数据库,并且加上了持久化的功能,09年,Redis横空出世了。从最开始只支持列表的数据库,到现在支持多种数据类型,并且提供了一系列的高级特性,Redis已经成为一个在全世界被广泛使用的开源项目。
为什么叫REDIS呢?它的全称是Remote Dictionary Service,直接翻译过来是远程字典服务。
2.4.2 key-value数据库使用排名
对于Redis,我们大部分时候的认识是一个缓存的组件,当然从它的发展历史我们也可以看到,它最开始并不是作为缓存使用的。只是在很多的互联网应用里面,它作为缓存发挥了最大的作用。所以下面我们来聊一下,Redis的主要特性有哪些,我们为什么要使用它作为数据库的缓存。
大家对于缓存应该不陌生,比如我们有硬件层面的CPU的缓存,浏览器的缓存,手机的应用也有缓存。我们把数据缓存起来的原因就是从原始位置取数据的代价太大了,放在一个临时存储起来,取回就可以快一些。
如果要了解Redis的特性,我们必须回答几个问题:
1、为什么要把数据放在内存中?
1.内存的速度更快,10w QPS2.减少计算的时间
2、如果是用内存的数据结构作为缓存,为什么不用HashMap或者Memcache?
1.更丰富的数据类型2.进程内与跨进程;单机与分布式3.功能丰富:持久化机制、过期策略4.支持多种编程语言5.高可用,集群
https://db-engines.com/en/ranking/key-value+store
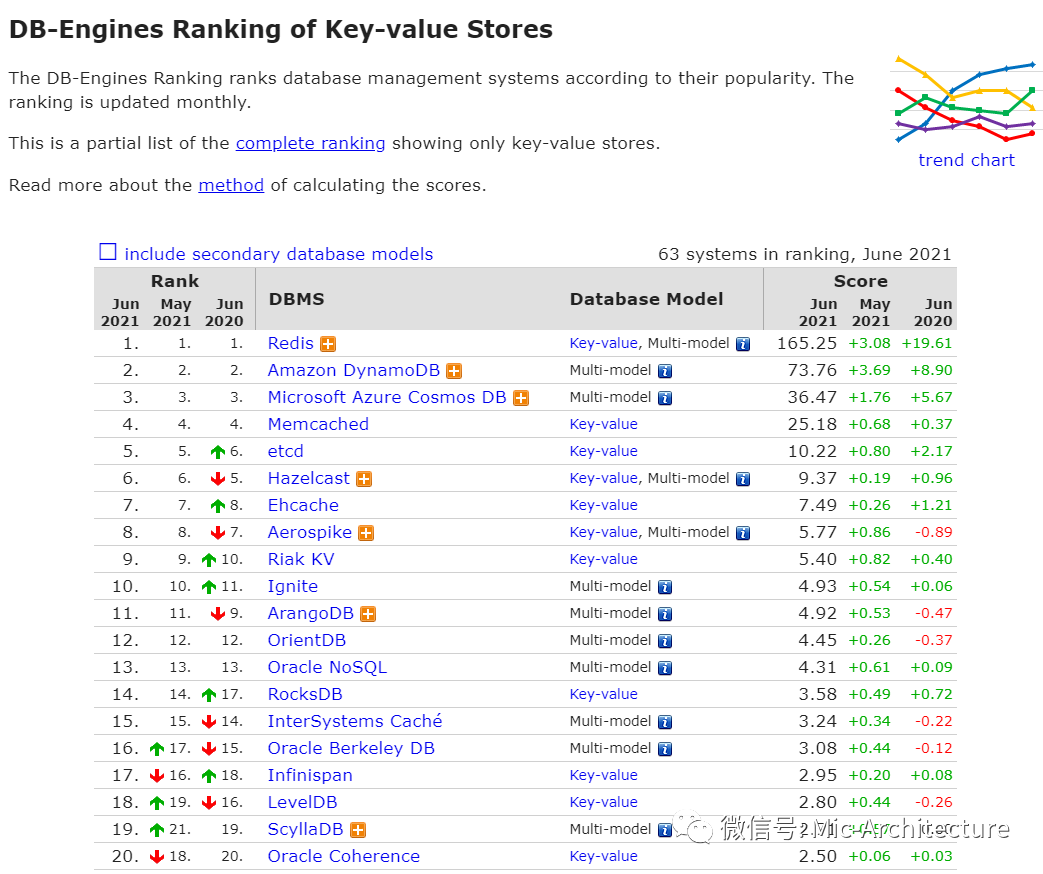
image-20210626202902337
图2-16
2.4.1 Redis 6 安装
注意事项,Redis6安装需要gcc版本大于5.3以上,否则安装会报错。
升级到gcc 9.3:yum -y install centos-release-sclyum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutilsscl enable devtoolset-9 bash# 需要注意的是scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本。# 如果要长期使用gcc 9.3的话:echo -e “\nsource /opt/rh/devtoolset-9/enable” >>/etc/profile
开始安装
cd /usr/local/wget http://download.redis.io/releases/redis-6.0.9.tar.gztar -zxvf redis-6.0.9.tar.gzcd redis-6.0.9makemake testmake install PREFIX=/data/program/redis cp redis.conf /etc/redis/redis.conf
添加成系统服务并开启默认启动
配置redis环境变量。
vi /etc/profileexport REDIS_HOME=/data/program/redisexport PATH=
P
A
T
H
:
PATH:
PATH:REDIS_HOME/bin
执行安装命令
cd /data/program/redis-6.2.4/utils/``./install_server.sh
可能会得到如下错误
This systems seems to use systemd.``Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!
解决办法, vim /install_server.sh,将下面代码注释
#_pid_1_exe=“KaTeX parse error: Expected 'EOF', got '#' at position 29: …/proc/1/exe)"``#̲if [ "{_pid_1_exe##*/}” = systemd ]#then# echo “This systems seems to use systemd.”# echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"# exit 1#fi#unset _pid_1_exe
再次执行./install_server.sh。
Welcome to the redis service installer``This script will help you easily set up a running redis server``This systems seems to use systemd.``Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!``[root@localhost utils]# vim install_server.sh [root@localhost utils]# ./install_server.sh Welcome to the redis service installer``This script will help you easily set up a running redis server``Please select the redis port for this instance: [6379] Selecting default: 6379``Please select the redis config file name [/etc/redis/6379.conf] /data/program/redis.conf``Please select the redis log file name [/var/log/redis_6379.log] Selected default - /var/log/redis_6379.log``Please select the data directory for this instance [/var/lib/redis/6379] Selected default - /var/lib/redis/6379``Please select the redis executable path [/data/program/redis/bin/redis-server]
注意,运行install_server脚本后,默认会启动一个redis实例,我们可以通过下面命令关闭。
1.redis-cli shutdown2.redis-cli -p 6379 shutdown
elp you easily set up a running redis serverPlease select the redis port for this instance: [6379]` `Selecting default: 6379Please select the redis config file name [/etc/redis/6379.conf] /data/program/redis.confPlease select the redis log file name [/var/log/redis_6379.log]` `Selected default - /var/log/redis_6379.logPlease select the data directory for this instance [/var/lib/redis/6379] Selected default - /var/lib/redis/6379``Please select the redis executable path [/data/program/redis/bin/redis-server]`
注意,运行install_server脚本后,默认会启动一个redis实例,我们可以通过下面命令关闭。
1.redis-cli shutdown2.redis-cli -p 6379 shutdown
![[附源码]Python计算机毕业设计飞羽羽毛球馆管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/a3b15daef2cb4ab881d9ee97f7ebbb57.png)










![[附源码]Python计算机毕业设计SSM基于JAVA线上订餐系统(程序+LW)](https://img-blog.csdnimg.cn/6223f5ae9b4b4c8d8f2caf7ae599a5fd.png)