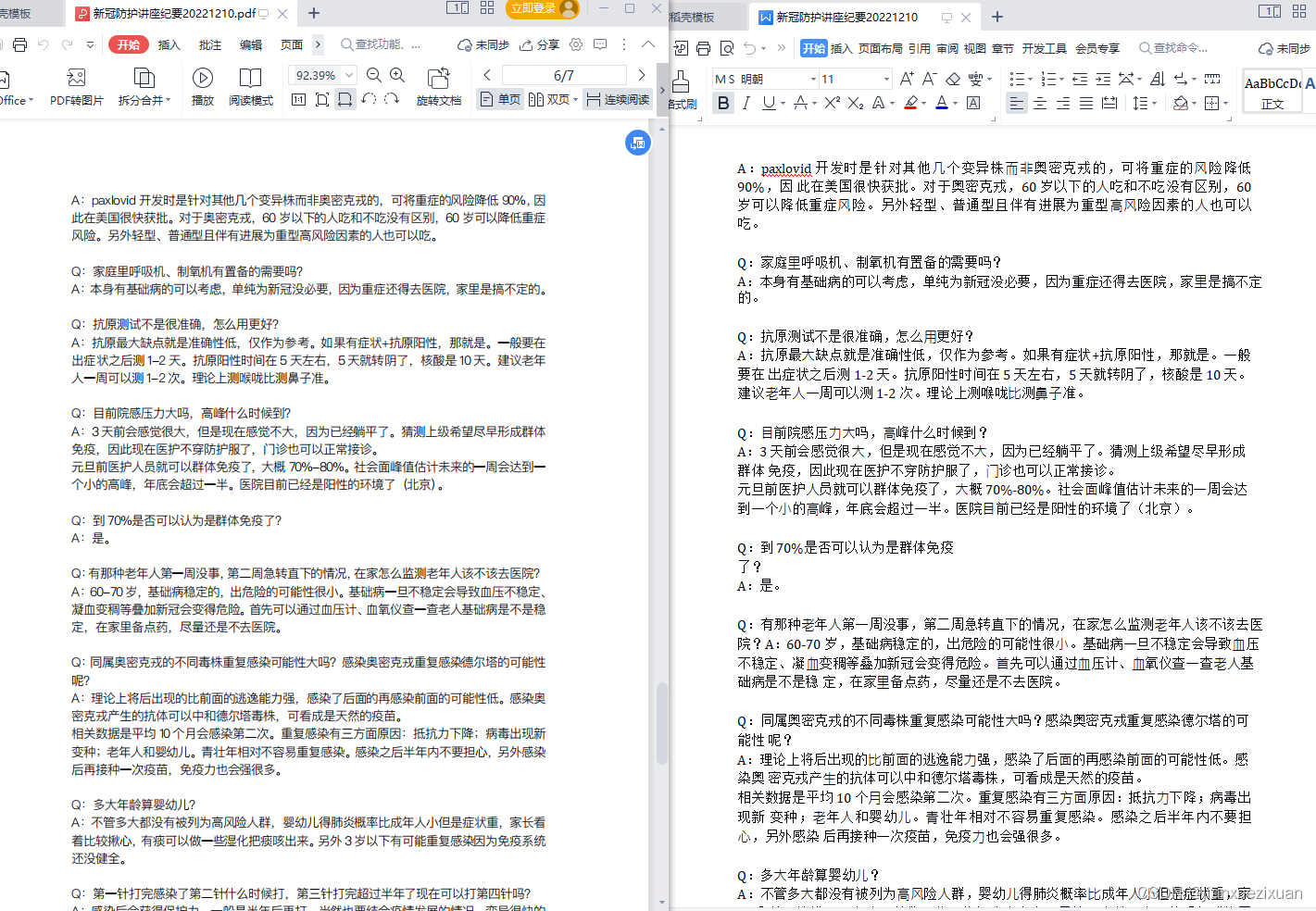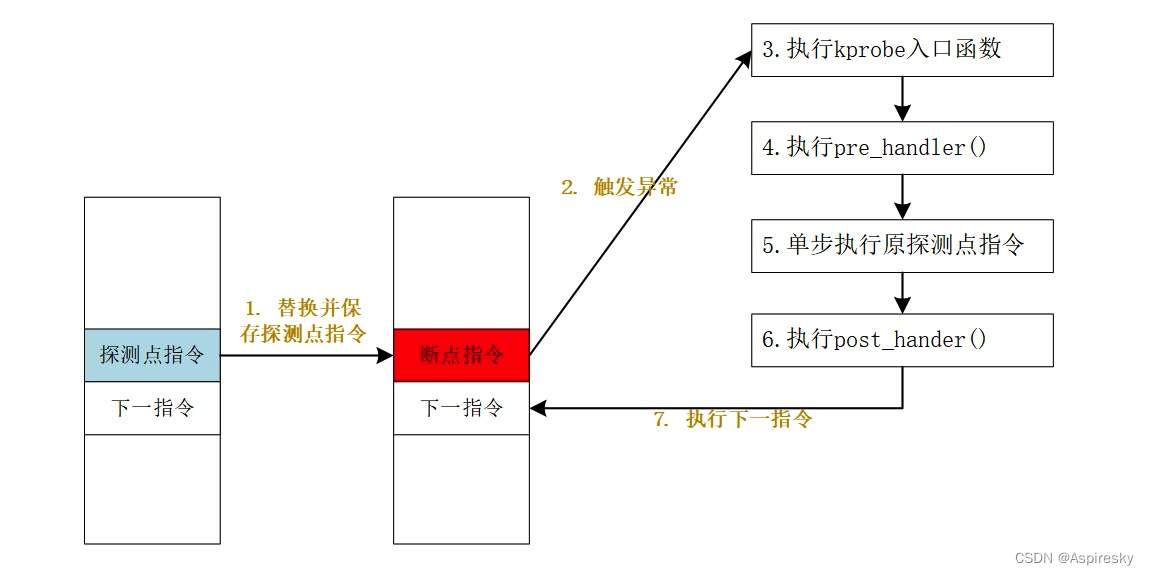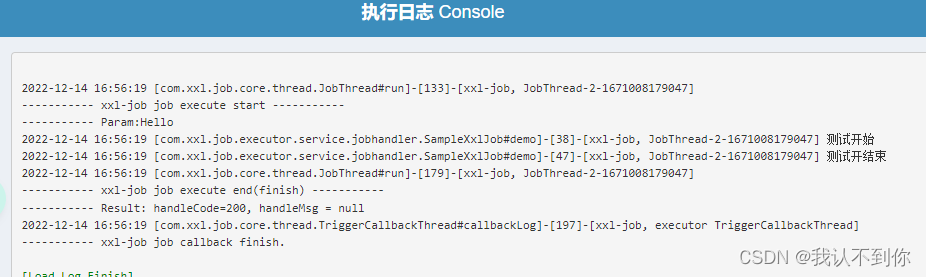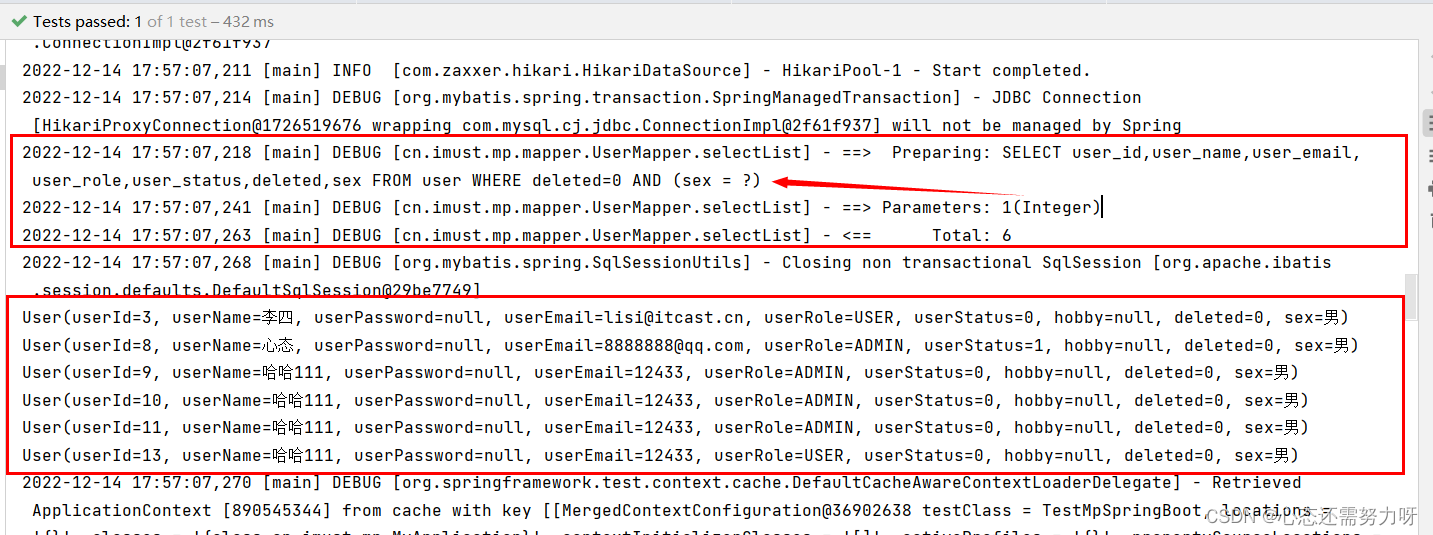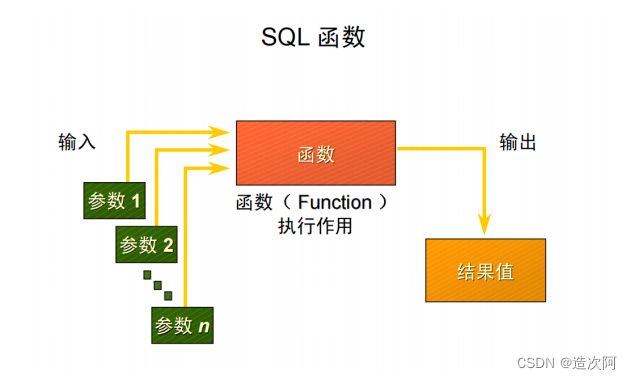
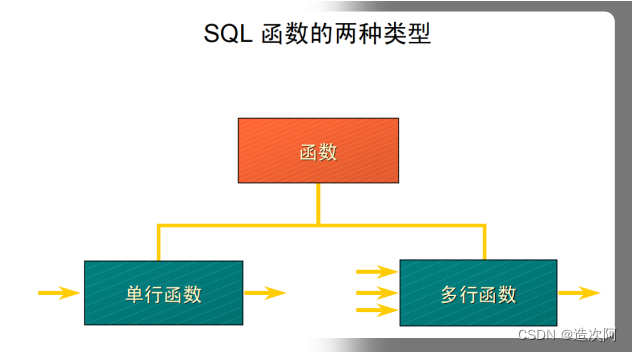
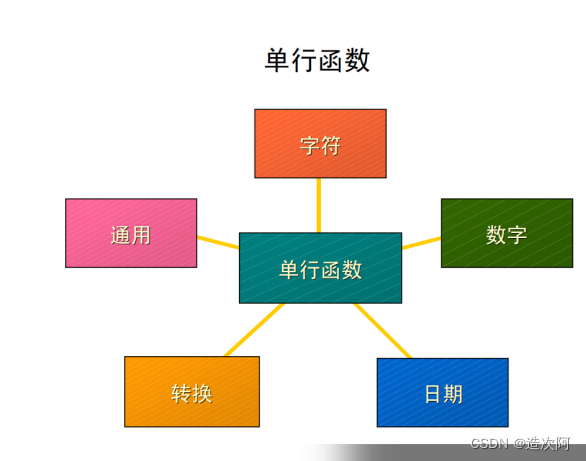
函数是 SQL 的一个非常强有力的特性,函数能够用于下面的目的:
● 执行数据计算
● 修改单个数据项
● 操纵输出进行行分组
● 格式化显示的日期和数字
● 转换列数据类型
SQL 函数有输入参数,并且总有一个返回值。

字符函数
大小写处理函数
| 函数 | 描述 | 实例 |
| LOWER(s)|LCASE(s) |
将字符串
s
转换
为小写
|
将字符串
OLDLU
转换为小写:
SELECT
LOWER("OLDLU")
; --
oldlu
|
| UPPER(s)|UCASE(s) |
将字符串s
转换为大写
|
将字符串
oldlu
转换为大写:
SELECT
UPPER("oldlu")
; --
OLDLU
|
select
employee_id,UPPER(last_name),department_id from employees where last_name = 'davies';
字符处理函数
| 函数 | 描述 | 实例 |
| LENGTH(s) | 返回字符串 s 的长度 |
返回字符串
oldlu
的字符数
SELECT
LENGTH("oldlu")
; --
5
;
|
| CONCAT(s1,s2...sn) |
字符串
s1,s2
等多个字符串合
并为一个字符串
|
合并多个字符串
SELECT CONCAT("sxt ",
"teacher ", "oldlu")
; --
sxt teacher oldlu
;
|
| LPAD(s1,len,s2) |
在字符串
s1
的开始处填充字
符串
s2
,使字符串长度达到
len
|
将字符串
x
填充到
oldlu
字符串的开始处:
SELECT LPAD('oldlu',8,'x')
; --
xxxoldlu
|
| LTRIM(s) | 去掉字符串 s 开始处的空格 |
去掉字符串
oldlu
开始处的空格:
SELECT
LTRIM(" oldlu")
;--
oldlu
|
| REPLACE(s,s1,s2) |
将字符串
s2
替代字符串
s
中
的字符串
s1
|
将字符串
oldlu
中的字符
o
替换为字符
O
:
SELECT REPLACE('oldlu','o','O')
; --
Oldlu
|
| REVERSE(s) | 将字符串s的顺序反过来 |
将字符串
abc
的顺序反过来:
SELECT
REVERSE('abc')
; --
cba
|
| RPAD(s1,len,s2) |
在字符串
s1
的结尾处添加字
符串
s2
,使字符串的长度达
到
len
|
将字符串
xx
填充到
oldlu
字符串的结尾处:
SELECT RPAD('oldlu',8,'x')
; --
oldluxxx
|
| RTRIM(s) | 去掉字符串 s 结尾处的空格 |
去掉字符串
oldlu
的末尾空格:
SELECT
RTRIM("oldlu ")
; --
oldlu
|
|
SUBSTR(s, start,
length)
|
从字符串
s
的
start
位置截取
长度为
length
的子字符串
|
从字符串
OLDLU
中的第
2
个位置截取
3
个
字符:
SELECT SUBSTR("OLDLU", 2, 3)
; --
LDL
|
|
SUBSTRING(s,
start, length)
|
从字符串
s
的
start
位置截取
长度为
length
的子字符串
|
从字符串
OLDLU
中的第
2
个位置截取
3
个
字符:
SELECT SUBSTRING("OLDLU", 2, 3)
; --
LDL
|
| TRIM(s) |
去掉字符串
s
开始和结尾处的
空格
|
去掉字符串
oldlu
的首尾空格:
SELECT
TRIM(' oldlu ')
;--
oldlu
|
示例:
显示所有工作岗位名称从第 4 个字符位置开始,包含字符串 REP的雇员的ID信息,将雇员的姓和名连接显示在一起,还显示雇员名的的长度,以及名字中字母 a 的位置。
SELECT employee_id, CONCAT(last_name,first_name) NAME,
job_id, LENGTH(last_name),INSTR(last_name,'a') "Contains 'a'?" FROM employees WHERE SUBSTR(job_id, 4) = 'REP';
|
函数名
| 描述 | 实例 |
| ABS(x) | 返回 x 的绝对值 | 返回 -1 的绝对值: SELECT ABS(-1) -- 返回1 |
| ACOS(x) | 求 x 的反余弦值(参数是弧度) | SELECT ACOS(0.25); |
| ASIN(x) | 求反正弦值(参数是弧度) | SELECT ASIN(0.25); |
| ATAN(x) | 求反正切值(参数是弧度) | SELECT ATAN(2.5); |
| ATAN2(n,m) | 求反正切值(参数是弧度) | SELECT ATAN2(-0.8, 2); |
| AVG(expression) |
返回一个表达式的平均值,
expression
是一个字段
|
返回
Products
表中
Price
字段的平均值:
SELECT AVG(Price)
AS AveragePrice FROM Products
;
|
| CEIL(x) | 返回大于或等于 x 的最小整数 | SELECT CEIL(1.5) -- 返回2 |
| CEILING(x) | 返回大于或等于 x 的最小整数 | SELECT CEILING(1.5); -- 返回2 |
| COS(x) | 求余弦值(参数是弧度) | SELECT COS(2); |
| COT(x) | 求余切值(参数是弧度) | SELECT COT(6); |
| COUNT(expression) |
返回查询的记录总数,
expression
参数是一个字段或
者
*
号
|
返回
Products
表中
products
字段总共有多少条记录:
SELECT COUNT(ProductID) AS NumberOfProducts FROM
Products
;
|
| DEGREES(x) | 将弧度转换为角度 | SELECT DEGREES(3.1415926535898) -- 180 |
| n DIV m | 整除,n 为被除数,m 为除数 | 计算 10 除于 5: SELECT 10 DIV 5; -- 2 |
| EXP(x) | 返回 e 的 x 次方 | 计算 e 的三次方: SELECT EXP(3) -- 20.085536923188 |
| FLOOR(x) | 返回小于或等于 x 的最大整数 | 小于或等于 1.5 的整数: SELECT FLOOR(1.5) -- 返回1 |
|
GREATEST(expr1,
expr2, expr3, ...)
| 返回列表中的最大值 |
返回以下数字列表中的最大值:
SELECT GREATEST(3, 12, 34, 8,
25)
; --
34
返回以下字符串列表中的最大值:
SELECT
GREATEST("Google", "Runoob", "Apple")
; --
Runoob
|
|
LEAST(expr1,
expr2, expr3, ...)
| 返回列表中的最小值 |
返回以下数字列表中的最小值:
SELECT LEAST(3, 12, 34, 8, 25)
;
--
3
返回以下字符串列表中的最小值:
SELECT LEAST("Google",
"Runoob", "Apple")
; --
Apple
|
| LN |
返回数字的自然对数,以
e
为
底。
| 返回 2 的自然对数: SELECT LN(2); -- 0.6931471805599453 |
|
LOG(x)
或
LOG(base, x)
|
返回自然对数
(
以
e
为底的对
数
)
,如果带有
base
参数,则
base
为指定带底数。
| SELECT LOG(20.085536923188) -- 3 SELECT LOG(2, 4); -- 2 |
| LOG10(x) | 返回以 10 为底的对数 | SELECT LOG10(100) -- 2 |
| LOG2(x) | 返回以 2 为底的对数 |
返回以
2
为底
6
的对数:
SELECT LOG2(6)
; --
2.584962500721156
|
| MAX(expression) |
返回字段
expression
中的最
大值
|
返回数据表
Products
中字段
Price
的最大值:
SELECT
MAX(Price) AS LargestPrice FROM Products
;
|
| MIN(expression) |
返回字段
expression
中的最
小值
|
返回数据表
Products
中字段
Price
的最小值:
SELECT
MIN(Price) AS MinPrice FROM Products
;
|
| MOD(x,y) | 返回 x 除以 y 以后的余数 | 5 除于 2 的余数: SELECT MOD(5,2) -- 1 |
| PI() | 返回圆周率(3.141593) | SELECT PI() --3.141593 |
| POW(x,y) | 返回 x 的 y 次方 | 2 的 3 次方: SELECT POW(2,3) -- 8 |
| POWER(x,y) | 返回 x 的 y 次方 | 2 的 3 次方: SELECT POWER(2,3) -- 8 |
| RADIANS(x) | 将角度转换为弧度 |
180
度转换为弧度:
SELECT RADIANS(180)
--
3.1415926535898
|
| RAND() | 返回 0 到 1 的随机数 | SELECT RAND() --0.93099315644334 |
| ROUND(x) | 返回离 x 最近的整数 | SELECT ROUND(1.23456) --1 |
| SIGN(x) |
返回
x
的符号,
x
是负数、
0
、正数分别返回
-1
、
0
和
1
| SELECT SIGN(-10) -- (-1) |
| SIN(x) | 求正弦值(参数是弧度) | SELECT SIN(RADIANS(30)) -- 0.5 |
| SQRT(x) | 返回x的平方根 | 25 的平方根: SELECT SQRT(25) -- 5 |
| SUM(expression) | 返回指定字段的总和 |
计算
OrderDetails
表中字段
Quantity
的总和:
SELECT
SUM(Quantity) AS TotalItemsOrdered FROM OrderDetails
;
|
| TAN(x) | 求正切值(参数是弧度) | SELECT TAN(1.75); -- -5.52037992250933 |
|
TRUNCATE(x,y)
|
返回数值
x
保留到小数点后
y
位的值(与
ROUND
最大的区
别是不会进行四舍五入)
| SELECT TRUNCATE(1.23456,3) -- 1.234 |
SELECT ROUND(45.923,2),
ROUND(45.923,0),ROUND(45.923,-1);TRUNCATE(column|expression,n) 函数
SELECT TRUNCATE(45.923,2);使用MOD(m,n) 函数
MOD 函数找出m 除以n的余数。
SELECT last_name, salary, MOD(salary, 5000)FROM employees
WHERE job_id = 'SA_REP';日期函数
| 函数名 | 描述 | 实例 |
| CURDATE() | 返回当前日期 | SELECT CURDATE(); -> 2018-09-19 |
| CURTIME() | 返回当前时间 | SELECT CURTIME(); -> 19:59:02 |
| CURRENT_DATE() | 返回当前日期 | SELECT CURRENT_DATE(); -> 2018-09-19 |
| CURRENT_TIME() | 返回当前时间 | SELECT CURRENT_TIME(); -> 19:59:02 |
| DATE() | 从日期或日期时间表达式中提取日期值 | SELECT DATE("2017-06-15"); -> 2017-06-15 |
| DATEDIFF(d1,d2) | 计算日期 d1->d2 之间相隔的天数 |
SELECT DATEDIFF('2001
-
01
-
01','2001
-
02
-
02')
-
>
-
32
|
| DAY(d) | 返回日期值 d 的日期部分 | SELECT DAY("2017-06-15"); -> 15 |
| DAYNAME(d) |
返回日期
d
是星期几,如
Monday,Tuesday
|
SELECT DAYNAME('2011
-
11
-
11 11:11:11')
-
>Friday
|
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 |
SELECT DAYOFMONTH('2011
-
11
-
11 11:11:11')
-
>11
|
| DAYOFWEEK(d) |
日期
d
今天是星期几,
1
星期日,
2
星期
一,以此类推
| SELECT DAYOFWEEK('2011-11-11 11:11:11') ->6 |
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 |
SELECT DAYOFYEAR('2011
-
11
-
11 11:11:11')
-
>315
|
| HOUR(t) | 返回 t 中的小时值 | SELECT HOUR('1:2:3') -> 1 |
| LAST_DAY(d) | 返回给给定日期的那一月份的最后一天 | SELECT LAST_DAY("2017-06-20"); -> 2017-06-30 |
| MONTHNAME(d) | 返回日期当中的月份名称,如 November |
SELECT MONTHNAME('2011
-
11
-
11 11:11:11')
-
> November
|
| MONTH(d) | 返回日期d中的月份值,1 到 12 | SELECT MONTH('2011-11-11 11:11:11') ->11 |
| NOW() | 返回当前日期和时间 | SELECT NOW() -> 2018-09-19 20:57:43 |
| SECOND(t) | 返回 t 中的秒钟值 | SELECT SECOND('1:2:3') -> 3 |
| SYSDATE() | 返回当前日期和时间 | SELECT SYSDATE() -> 2018-09-19 20:57:43 |
|
TIMEDIFF(time1,
time2)
| 计算时间差值 |
SELECT TIMEDIFF("13:10:11", "13:10:10")
; -
>
00:00:01
|
| TO_DAYS(d) | 计算日期 d 距离 0000 年 1 月 1 日的天数 | SELECT TO_DAYS('0001-01-01 01:01:01') -> 366 |
| WEEK(d) |
计算日期
d
是本年的第几个星期,范围是
0
到
53
| SELECT WEEK('2011-11-11 11:11:11') -> 45 |
| WEEKDAY(d) |
日期
d
是星期几,
0
表示星期一,
1
表示星
期二
| SELECT WEEKDAY("2017-06-15"); -> 3 |
| WEEKOFYEAR(d) |
计算日期
d
是本年的第几个星期,范围是
0
到
53
|
SELECT WEEKOFYEAR('2011
-
11
-
11 11:11:11')
-
>
45
|
| YEAR(d) | 返回年份 | SELECT YEAR("2017-06-15"); -> 2017 |
示例一:
insert into
employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(300,'kevin','kevin@sxt.cn','2049-5-18:30:30','IT_PROG');
示例二:
SELECT last_name, (SYSDATE()-hire_date)/7 AS WEEKS FROM employees WHERE department_id = 90;转换函数
| 格式 | 描述 |
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时(00-23) |
| %h | 小时(01-12) |
| %I | 小时(01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天(001-366) |
| %k | 小时(0-23) |
| %l | 小时(1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间,24-小时(hh:mm:ss) |
| %U | 周(00-53)星期日是一周的第一天 |
| %u | 周(00-53)星期一是一周的第一天 |
| %V | 周(01-53)星期日是一周的第一天,与%X使用 |
| %v | 周(01-53)星期日是一周的第一天,与%x使用 |
| %W | 星期名 |
| %w | 周的天(0 = 星期日,6 = 星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与%V使用 |
| %x | 年,其中的星期日是周的第一天,4 位,与%v使用 |
| %Y | 年,4位 |
| %y | 年,2位 |
示例一:
insert into
employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(400,'oldlu','oldlu@sxt.cn',
STR_TO_DATE('2049 年 5 月 5 日','%Y 年%m 月%d日'),'IT_PROG');
select DATE_FORMAT(hire_date,'%Y 年%m 月%d日') from employees where last_name = 'King';
通用函数
| 函数名 | 描述 | 实例 |
| IF(expr,v1,v2) |
如果表达式
expr
成立,返回结果
v1
;否 则,返回结果 v2
。
|
SELECT IF(1 >0,'正
确','错误')
-
>正确
|
| IFNULL(v1,v2) |
如果
v1
的值不为
NULL
,则返回
v1
,否则返回 v2
。
|
SELECT IFNULL(null,'Hello
Word')
-
>Hello Word
|
| ISNULL(expression) | 判断表达式是否为 NULL |
SELECT
ISNULL(NULL)
; -
>1
|
| NULLIF(expr1, expr2) |
比较两个参数是否相同,如果参数
expr1
与 expr2 相等 返回
NULL
,否则返回
expr1
|
SELECT NULLIF(25,
25)
; -
>
|
|
COALESCE(expr1, expr2, ...., expr_n)
|
返回参数中的第一个非空表达式(从左向右)
|
SELECT
COALESCE(NULL,
NULL, NULL,
'bjsxt.com', NULL,
'google.com')
; -
> bjsxt.com
|
|
CASE expression WHEN
condition1 THEN result1
WHEN condition2 THEN
result2 ... WHEN conditionN
THEN resultN ELSE result
END
|
CASE
表示函数开始,
END
表示函数结束。
如果
condition1
成立,则返回
result1,
如果
condition2
成立,则返回
result2
,当全部不
成立则返回
result
,而当有一个成立之后,
后面的就不执行了。
|
SELECT CASE 'oldlu'
WHEN 'oldlu' THEN
'OLDLU' WHEN
'admin' THEN
'ADMIN' ELSE 'kevin'
END
;
|
示例一:
SELECT last_name, salary, commission_pct,
if(ISNULL(commission_pct),
'SAL','SAL+COMM') income
FROM employees
WHERE department_id IN (50, 80);示例二:
计算雇员的年报酬,你需要用 12 乘以月薪,再加上它的佣金 (等于年薪乘以佣金百分比)。
SELECT last_name, salary,
IFNULL(commission_pct, 0), (salary*12) + (salary*12*IFNULL(commission_pct, 0)) AN_SAL
FROM employees;示例三
SELECT first_name, LENGTH(first_name)
"expr1",
last_name, LENGTH(last_name) "expr2",
NULLIF(LENGTH(first_name),
LENGTH(last_name)) result
FROM employees;示例四:
SELECT last_name,
COALESCE(commission_pct, salary, 10) comm
FROM employees
ORDER BY commission_pct;示例五:
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN
1.10*salary
WHEN 'ST_CLERK' THEN
1.15*salary
WHEN 'SA_REP' THEN
1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;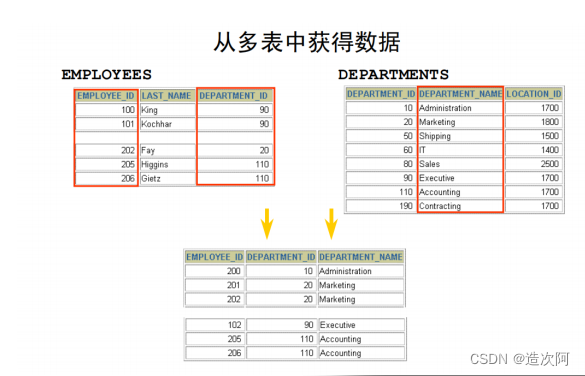


多表查询分类
● sql92标准:内连接(等值连接 、非等值连接 、 自连接)。
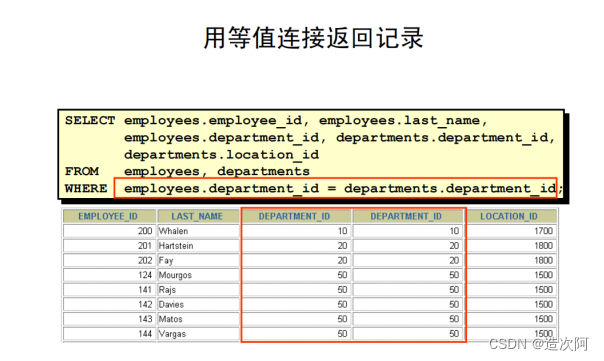
● SELECT 子句指定要返回的列名:
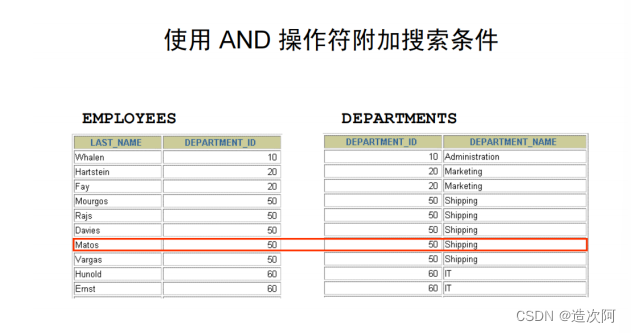
添加查询条件


表别名定义原则
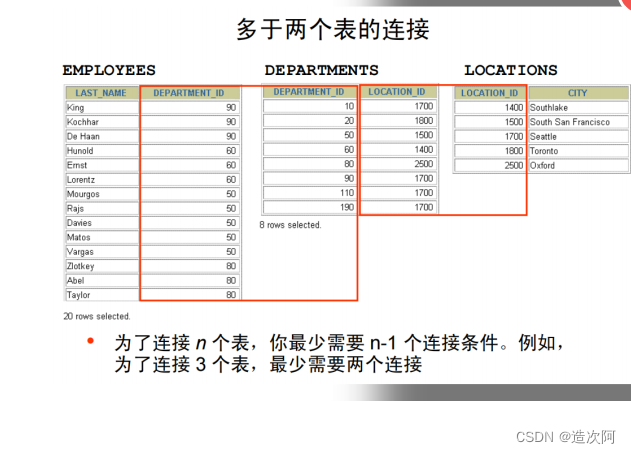
示例一:
select d.department_name from employees
e,departments d where e.dept_id =
d.department_id and e.last_name = 'King';非等值连接
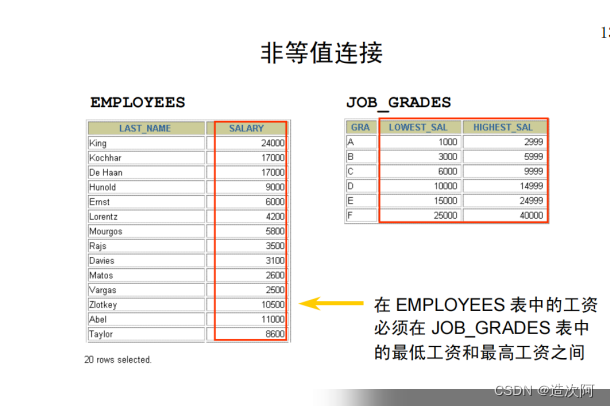
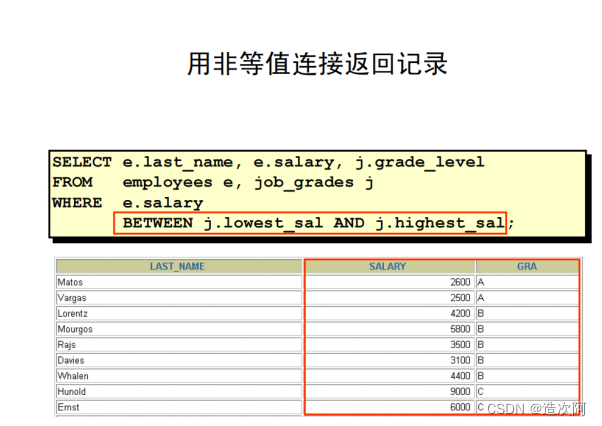
create table job_grades(lowest_sal int,highest_sal int ,grade_level
varchar(30));示例二:
插入数据
insert into job_grades values(1000,2999,'A');
insert into job_grades values(2000,4999,'B');
insert into job_grades values(5000,7999,'C');
insert into job_grades
values(8000,12000,'D');

SELECT
worker.LAST_NAME W,manager.LAST_NAME M
from employees worker,employees manager
where worker.MANAGER_ID = manager.EMPLOYEE_ID;SQL99标准中的查询

示例:
select * from employees cross join departments;
SQL99中的自然连接(NATURAL JOIN)

自然连接
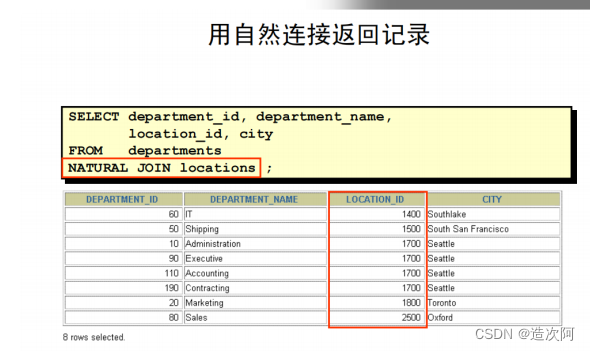
在图片例子中,LOCATIONS 表被用 LOCATION_ID 列连接到DEPARTMENT表,这是在两个表中唯一名字相同的列。如果存在其它的同名同类型的列,自然连接会使用等值连接的方式连接他们, 连接条件的关系为and。
自然连接也可以被写为等值连接:
select e.last_name,d.department_name from employees e natural join departments d;
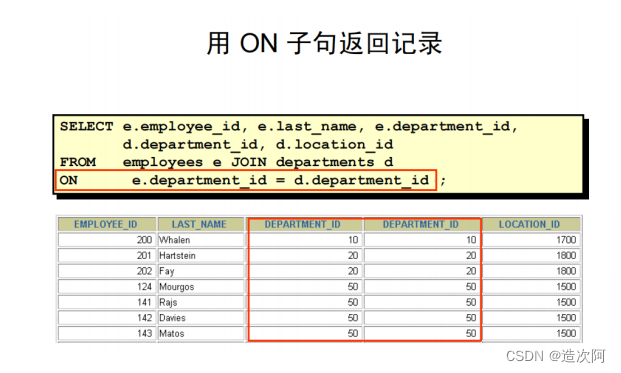
用ON子句指定更多的连接条件
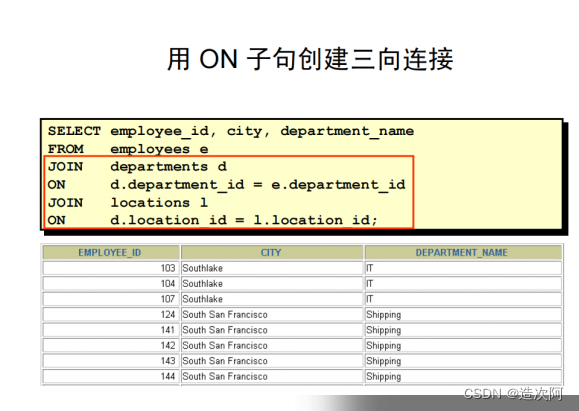
示例:
select
e.employee_id,e.salary,d.department_name from
employees e inner JOIN departments d on
e.department_id = d.department_id where
e.last_name = 'Fox';外连接查询(OUTER JOIN)


select e.last_name,d.department_name from
employees e LEFT OUTER JOIN departments d on
e.dept_id = d.department_id;
select e.last_name,d.department_name from
employees e RIGHT OUTER JOIN departments
d on e.DEPARTMENT_ID = d.department_id;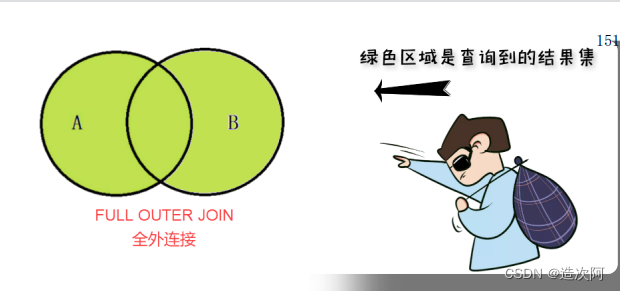
(SELECT 投影列 FROM 表名 LEFT OUTER JOIN 表名 ON 连接条件)
UNION
(SELECT 投影列 FROM 表名 RIGHT OUTER JOIN 表名 ON 连接条件)
(select e.last_name,d.department_name from employees e LEFT OUTER JOIN departments d one.department_id = d.department_id)
UNION
(select e1.last_name,d1.department_name from employees e1 RIGHT OUTER JOIN
departments d1 on d1.department_id = e1.department_id)
聚合函数类型

聚合函数说明:
| 函数名 | 描述 | 实例 |
| AVG(expression) |
返回一个表达式的平均值,expression
是一个字段
|
返回
Products
表中
Price
字段的平均值:
SELECT
AVG(Price) AS AveragePrice FROM Products
;
|
| COUNT(expression) |
返回查询的记录总数,
expression
参数是一个字段或者 *
号
|
返回
Products
表中
products
字段总共有多少条记录:
SELECT COUNT(ProductID) AS
NumberOfProducts FROM Products
;
|
| MAX(expression) |
返回字段
expression
中的最大值
|
返回数据表
Products
中字段
Price
的最大值:
SELECT MAX(Price) AS LargestPrice FROM Products
;
|
| MIN(expression) |
返回字段
expression
中
的最小值
|
返回数据表
Products
中字段
Price
的最小值:
SELECT MIN(Price) AS MinPrice FROM Products
;
|
| SUM(expression) | 返回指定字段的总和 |
计算
OrderDetails
表中字段
Quantity
的总和:
SELECT SUM(Quantity) AS TotalItemsOrdered FROM
OrderDetails
;
|

SELECT AVG(salary),SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';MIN 和 MAX 函数
SELECT MIN(hire_date), MAX(hire_date) FROM employees;COUNT 函数
返回分组中的总行数。
SELECT COUNT(commission_pct) FROM employees WHERE department_id = 80;
SELECT AVG(IFNULL(commission_pct, 0)) FROM
employees;数据分组(GROUP BY)
创建数据组
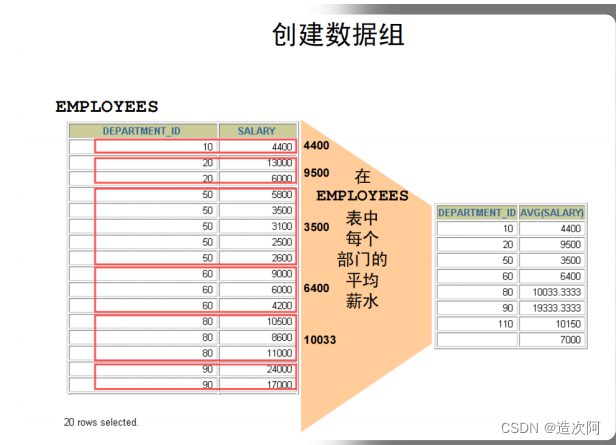
创建数据组
在没有进行数据分组之前,所有聚合函数是将结果集作为一个大的信息组进行处理。但是,有时,则需要将表的信息划分为较小的组,可以用 GROUP BY 子句实现。

原则
● 使用 WHERE 子句,可以在划分行成组以前过滤行。
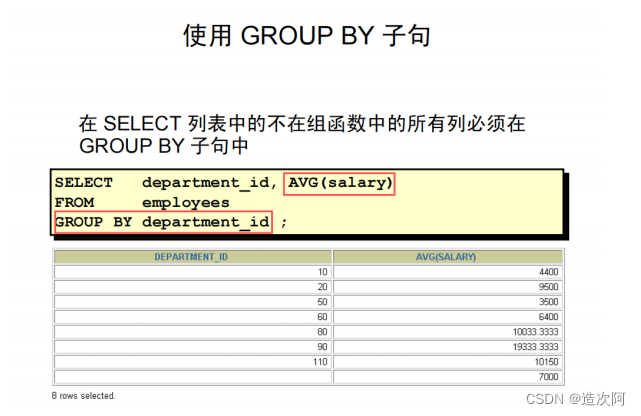
GROUP BY 子句
SELECT DEPARTMENT_ID, COUNT(*) FROM employees GROUP BY DEPARTMENT_ID;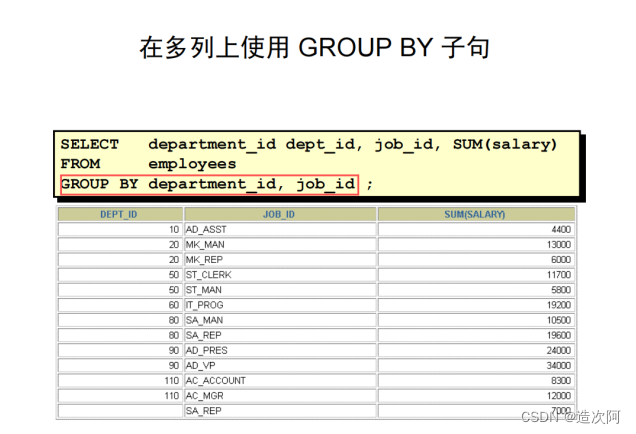
SELECT e.DEPARTMENT_ID, e.JOB_ID,COUNT(*)FROM
employees e
GROUP BY e.DEPARTMENT_ID,e.JOB_ID;约束分组结果(HAVING)
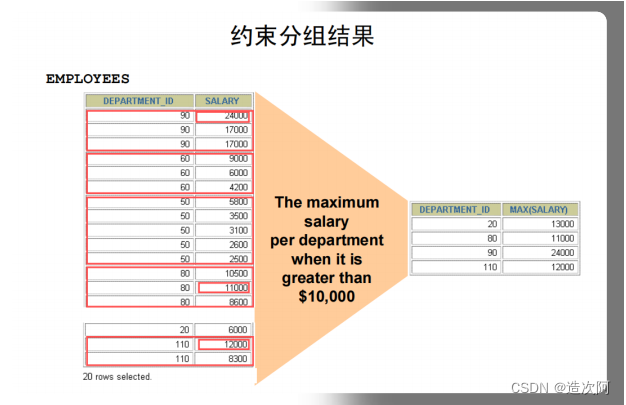
HAVING 子句
SELECT department_id, MAX(salary) FROM
employees GROUP BY department_id HAVING
MAX(salary)>10000 ;

示例:
SELECT job_id, SUM(salary) PAYROLL FROM
employees WHERE job_id NOT LIKE '%REP%'GROUP
BY job_id HAVING SUM(salary) > 13000 ORDER BY
SUM(salary);子查询


子查询
子查询是一个 SELECT 语句,它是嵌在另一个 SELECT 语句中的子句。使用子查询可以用简单的语句构建功能强大的语句。
可以将子查询放在许多的 SQL 子句中,包括:
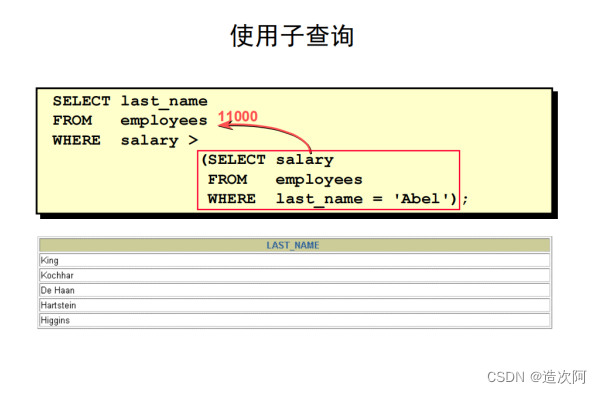
使用子查询的原则
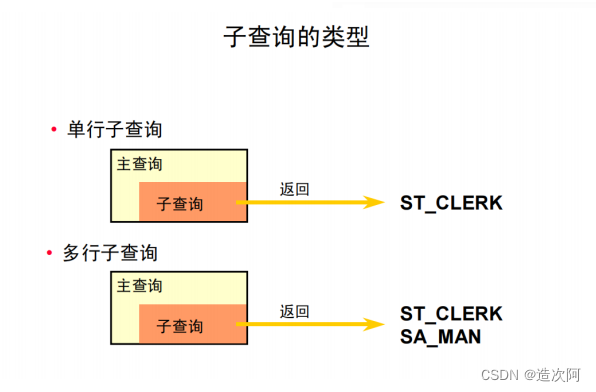
select e.LAST_NAME,e.DEPARTMENT_ID FROM
employees e
where e.DEPARTMENT_ID =
(select e1.DEPARTMENT_ID from employees e1
where e1.last_name = 'Fox');单行子查询

select empl.last_name from employees
empl where empl.department_id =
(select e.department_id from employees e
where e.last_name = 'Fox') and empl.last_name
<> 'Fox';多行子查询
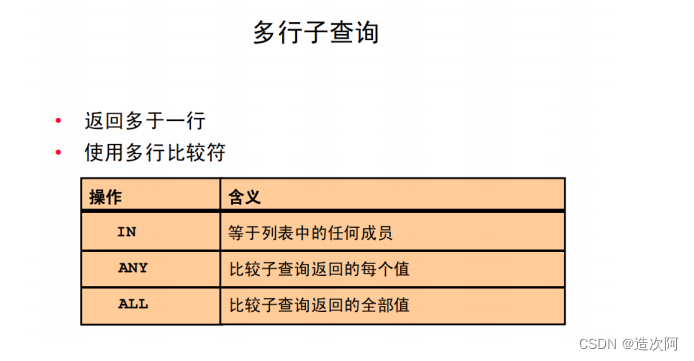 多行子查询
多行子查询

ANY 运算符
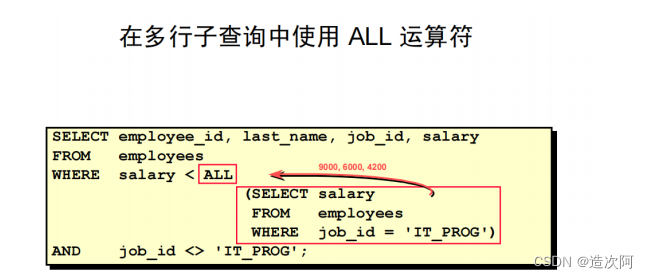
ALL 运算符比较一个值与子查询返回的每个值。

内查询返回的值含有空值,并因此整个查询无返回行,原因是用大于、小于或不等于比较Null值,都返回null。所以,只要空值可能是子查询结果集的一部分,就不能用 NOT IN 运算符。NOT IN 运算符相当于 <> ALL。
SELECT emp.last_name FROM employees emp WHERE
emp.employee_id IN (SELECT mgr.manager_id
FROM employees mgr);示例:
select
em.last_name,em.salary,em.department_id from
employees em where em.salary in(select
min(e.salary) from employees e group by
e.department_id);
索引介绍
SHOW INDEX FROM table_name;直接创建索引
CREATE INDEX index_name ON table(column(length));
示例:
为 emp3 表中的 name 创建一个索引,索引名为emp3_name_index;
create index emp3_name_index ON emp3(name);修改表添加索引
ALTER TABLE table_name ADD INDEX index_name (column(length));创建表时指定索引列
CREATE TABLE `table` (
COLUMN TYPE ,
PRIMARY KEY (`id`),
INDEX index_name (column(length))
);CREATE UNIQUE INDEX indexName ON
table(column(length));修改表添加唯一索引
ALTER TABLE table_name ADD UNIQUE indexName
(column(length));创建表时指定唯一索引
CREATE TABLE `table` (
COLUMN TYPE ,
PRIMARY KEY (`id`),
UNIQUE index_name (column(length))
);ALTER TABLE 表名 ADD PRIMARY KEY(列名);CREATE TABLE `table` (
COLUMN TYPE ,
PRIMARY KEY(column)
);组合索引
组合索引是指使用多个字段创建的索引,只有在查询条件中使用了 创建索引时的第一个字段,索引才会被使用(最左前缀原则)。
ALTER TABLE table_name ADD INDEX index_name
(column(length),column(length));CREATE TABLE `table` (
COLUMN TYPE ,
INDEX index_name
(column(length),column(length))
);
| TCL语句 | 描述 |
| start transaction | 事务开启 |
| commit | 事物提交 |
| rollback | 事物回滚 |
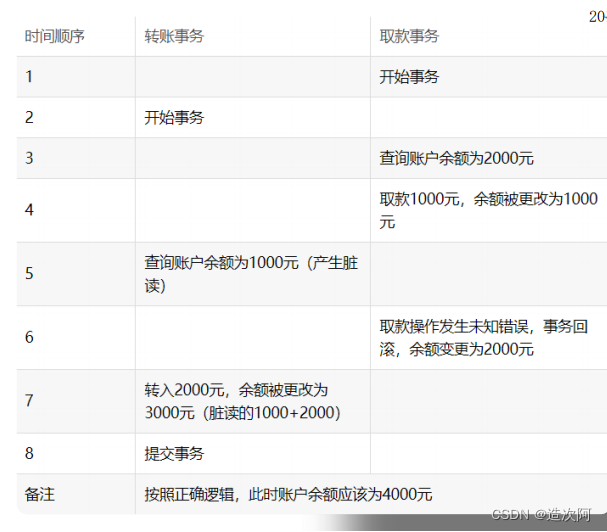
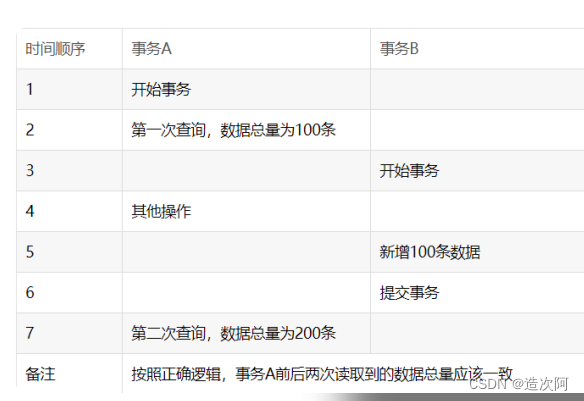
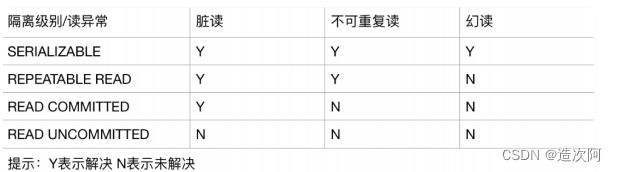
不可重复读(前后多次读取,数据内容不一致)
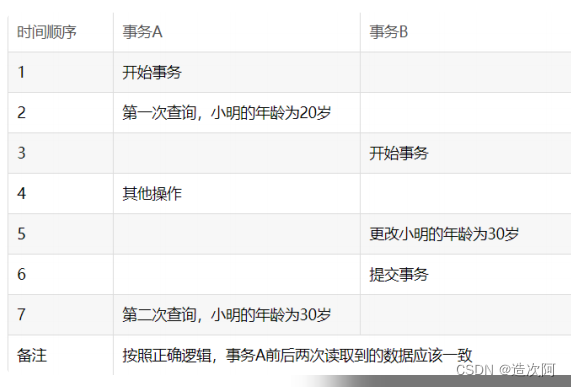
幻读(前后多次读取,数据总量不一致)
SELECT @@transaction_isolation;set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
set session transaction isolation level repeatable read;
set session transaction isolation level serializable;CREATE USER username IDENTIFIED BY
'password';查看用户
SELECT USER,HOST FROM mysql.user;| 字段 | 含义 |
| % | 匹配所有主机 |
| localhost | localhost 不会被解析成 IP 地址,直接通过 UNIXsocket 连接 |
| 127.0.0.1 | 会通过 TCP/IP 协议连接,并且只能在本机访问 |
| :: 1 | ::1 就是兼容支持 ipv6 的,表示同 ipv4 的 127.0.0. 1 |
| 权 限 | 作用范围 | 作 用 |
| all [privileges] | 服务器 | 所有权限 |
| select | 表、列 | 选择行 |
| insert | 表、列 | 插入行 |
|
update
|
表、列
|
更新行
|
|
delete
|
表
|
删除行
|
| create | 数据库、表、索引 | 创建 |
| drop | 数据库、表、视图 | 删除 |
| reload | 服务器 | 允许使用flush语句 |
| shutdown | 服务器 | 关闭服务 |
| process | 服务器 | 查看线程信息 |
| file | 服务器 | 文件操作 |
| grant option | 数据库、表、存储过程 | 授权 |
| references | 数据库、表 | 外键约束的父表 |
| index | 表 | 创建/删除索引 |
| alter | 表 | 修改表结构 |
| show databases | 服务器 | 查看数据库名称 |
| super | 服务器 | 超级权限 |
| create temporary tables | 表 |
创建临时表
|
| lock tables | 数据库 | 锁表 |
| execute | 存储过程 | 执行 |
| replication client | 服务器 | 允许查看主/从/二进制日志状态 |
| replication slave | 服务器 |
主从复制
|
| create view | 视图 | 创建视图 |
| show view | 视图 | 查看视图 |
| create routine | 存储过程 | 创建存储过程 |
| alter routine | 存储过程 | 修改/删除存储过程 |
| create user | 服务器 | 创建用户 |
| event | 数据库 | 创建/更改/删除/查看事件 |
| trigger | 表 | 触发器 |
| create tablespace | 服务器 | 创建/更改/删除表空间/日志文件 |
| proxy | 服务器 | 代理成为其它用户 |
| usage | 服务器 | 没有权限 |
FLUSH PRIVILEGES;删除用户
DROP USER username@localhost;



![[附源码]Python计算机毕业设计SSM基于JAVA线上订餐系统(程序+LW)](https://img-blog.csdnimg.cn/6223f5ae9b4b4c8d8f2caf7ae599a5fd.png)