02——BigKey
一、MoreKey案例
-
大批量往redis里面插入2000w测试数据key
-
真实生产案例

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LfbSfvNL-1692427337323)(https://you-blog.oss-accelerate.aliyuncs.com/2023/202303052248850.png)]
生产上严禁使用
keys */ flushdb/flushall。通过修改配置文件redis.conf,严禁使用高危命令。
rename-command keys "" rename-command flushdb "" rename-command flushall "" -
不能用
keys *,因为会卡顿,那用什么使用scan命令,和MySQL的limit有类似,但不完全相同。
scan:增量遍历集合中的元素,除scan外,还有sscan、hscan、zscan
公式:
scan cursor [MATCH pattern] [COUNT count] scan 434176 match k10* count 100特性:
- 基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程。
- 以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历。
- 不保证每次执行都返回某个给定数量的元素,支持模糊查询。
- 一次返回的数量不可控,只能是大概率复合count参数。
遍历顺序:
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的重复遍历和遗漏。
二、BigKey案例
大的不是key,而是key对应的value
-
多大算big
阿里云redis开发规范
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gTEFqao7-1692427337324)(https://you-blog.oss-accelerate.aliyuncs.com/2023/202303052311463.png)]
string类型对应的是value值,最大是512MB,但超过10KB就是bigkey
list、hash、set和zset,个数超过5000就算是bigkey。
为什么对于二级结构的数据,个数超过5000,就算bigkey呢?理论上一个list、hash、set可以存超过40亿的数据。
-
有哪些危害
- 内存不均,集群迁移困难
- 超时删除,bigKey删除做梗
- 网络流量阻塞
-
如何产生
- 社交类:某个明星粉丝量徒增
- 汇总计算:报表,年月日累积
-
如何发现
-
使用
redis-cli –bigkeys好处:给出每种数据结构Top 1bigkey,同时给出每种数据类型的键值个数、平均大小
不足:不能查询大于10kb的所有可以key
使用注意:为防止扫描时资源效果过多,影响业务,在命令中加入休眠时间
# 每隔100条scan指令,就会休眠0.1s,ops就不会剧烈抬升,但是扫描时间会变长 redis-cli --bigkeys -i 0.1 -
使用
memory usage命令,统计key和value在RAM中所占用的字节数。使用:
momory usage k100
-
-
如何删除
- 非string类型的bigkey,不能使用del删除;对于list、hash、set需要使用scan对应的命令,渐进式删除。
- 对应string类型,一般使用del,过于庞大,使用unlink
- 对于hash,先使用hscan获取少量field-value,再使用hdel删除field
- list:使用ltrim渐进式删除,直到全部删除
- set:使用sscan获取部分元素,再使用srem删除每个元素
- zset:使用zcan获取部分元素,再使用zremrangebyrank命令删除每个元素
三、BigKey生产调优
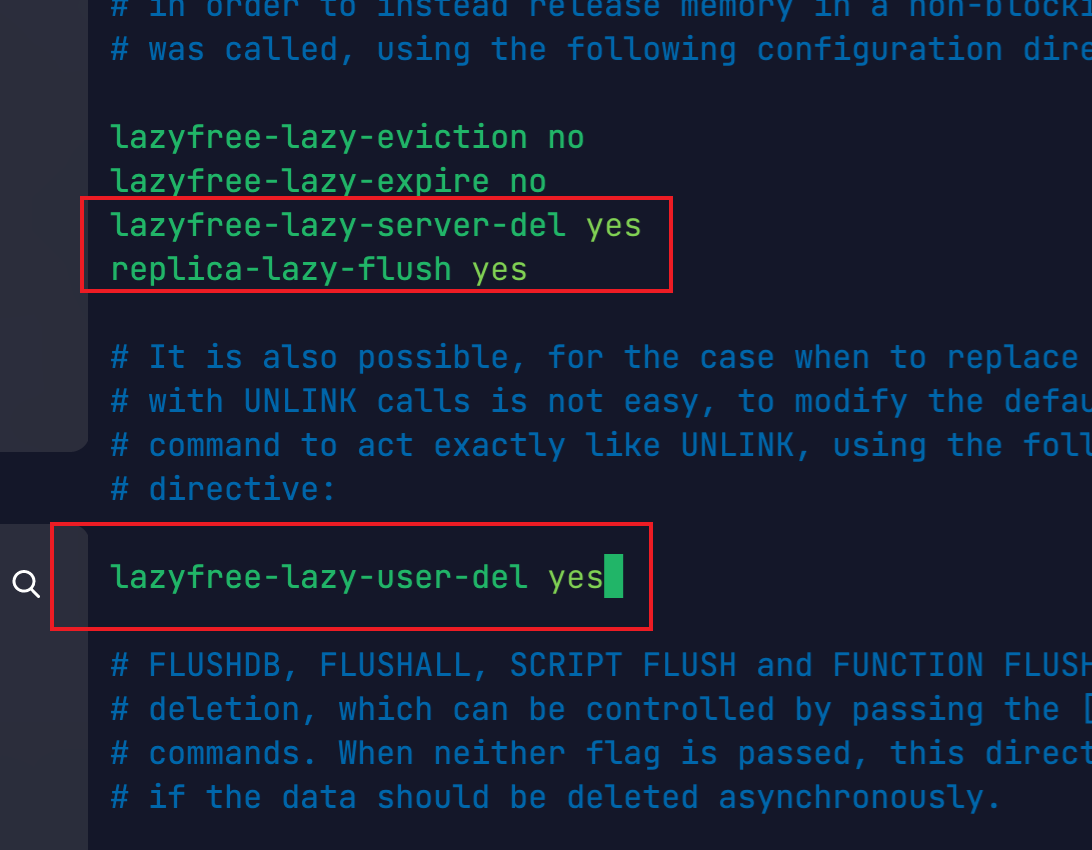
lazy freeing
redis删除:
- 阻塞:del
- 非阻塞:unlink、flushall、flushdb
配置lazy freeing:
lazyfree-lazy-server-del yes
replica-lazy-flush yes
lazyfree-lazy-user-del yes