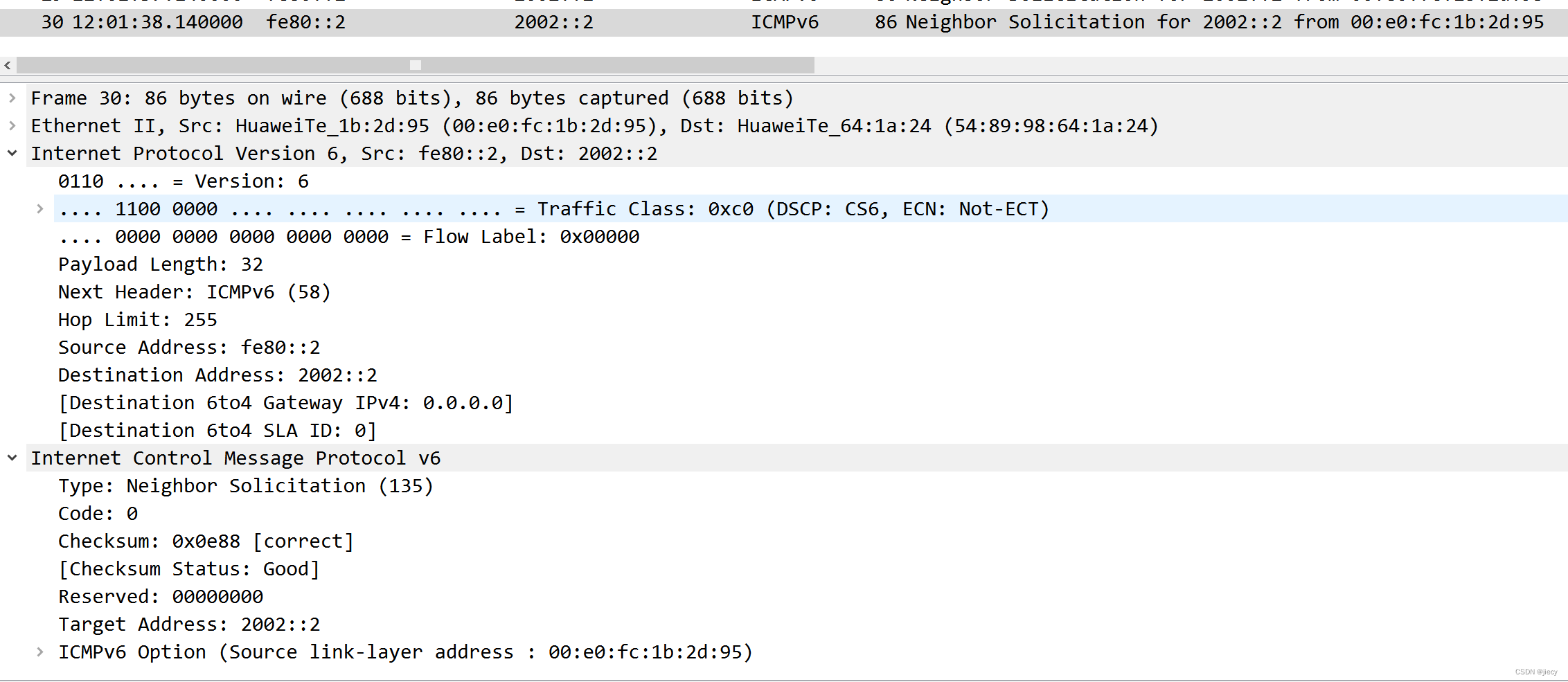
写在前面
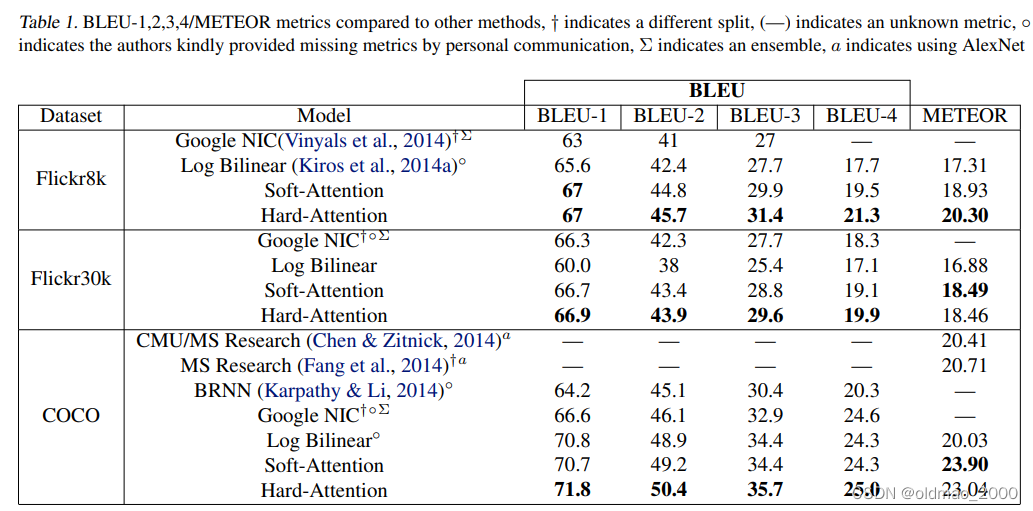
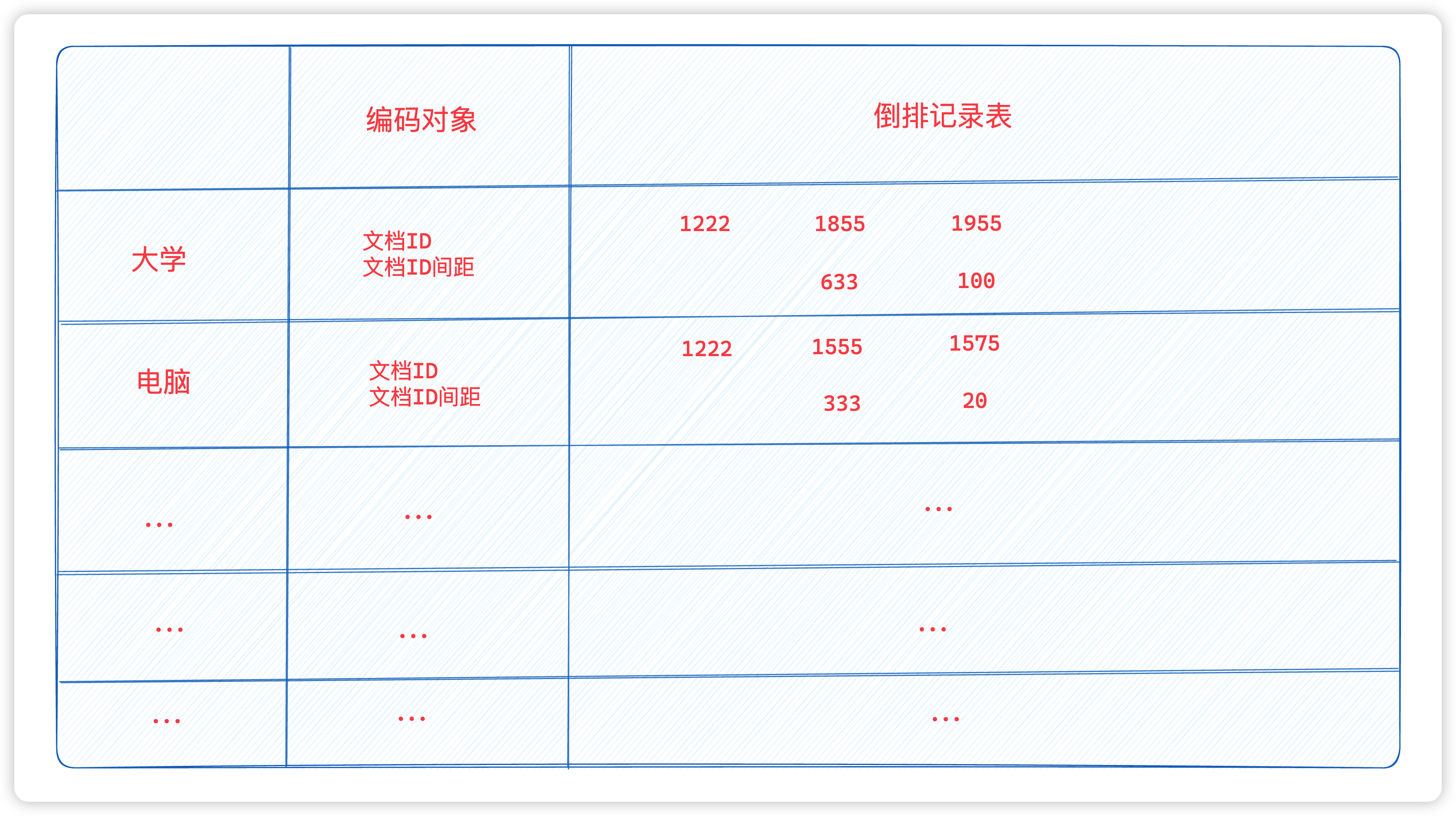
假设我们的数据集中有 800000 篇文章,每篇文章有 200 词条,每个词条有6个字符,倒排记录数目是 1 亿。那么如果我们倒排索引表中单单记录文档id,不记录文档内的频率和偏移信息。
那么 文档id 的长度就必须是
l
o
g
2
800000
=
20
b
i
t
log_2800000=20 bit
log2800000=20bit (文档可能每篇文章都存在,所以是以最长的长度要求),所以我们整个未压缩的倒排索引表的大小大概有,倒排记录数 * 文档id大小 = 100,000,000 * 20/8 = 250 MB
为了设计出一个更高效的倒排文件的表示方式,可以考虑每篇文档采用少雨20位的表示方法,观察中发现。高频词出现的文档id的序列相差不大。比如高频词 “大学”,我们去找一篇包含 大学 的文档,可能我们找了一个之后,不久又找到一个,这些文档id之间的gap(间距)不大,因此可以考虑用比20位端很多的位数来表示它。为了对这种间距分布的情况进行空间压缩,需要使用一种变长编码方法,这种方法可以对短间距采用更短的位数来表示
1. 可变字节码
VB(variable byte,可变字节) 编码利用整数个字节来对间距编码。字节的后7位是间距的有效编码区,而第一位是延续位。如果该位为1,则表明本字节是某个间距编码的最后一个字节,否则不是。要对一个可变字节编码进行解码,可以读入一段字节序列,其中前面的字节的延续位都为0,而最后一个字节的延续位为1。根据上述标识可以把每个字节的7位部分抽取出来并链接在一起形成编码。
go语言实现vb的编码,VBEncodeNumber 将整数编码为VB编码的字符串
func VBEncodeNumber(n uint32) string {
var bytes []uint32
for {
bytes = append(bytes, n%128+128)
if n < 128 {
break
}
n = n / 128
}
var by []string
for i := len(bytes) - 1; i >= 0; i-- {
if i < len(bytes)-1 {
by = append(by, strconv.FormatUint(uint64(bytes[i]), 2)[1:]+" ")
} else {
by = append(by, strconv.FormatUint(uint64(bytes[i]), 2))
}
}
return strings.Join(by, "")
}
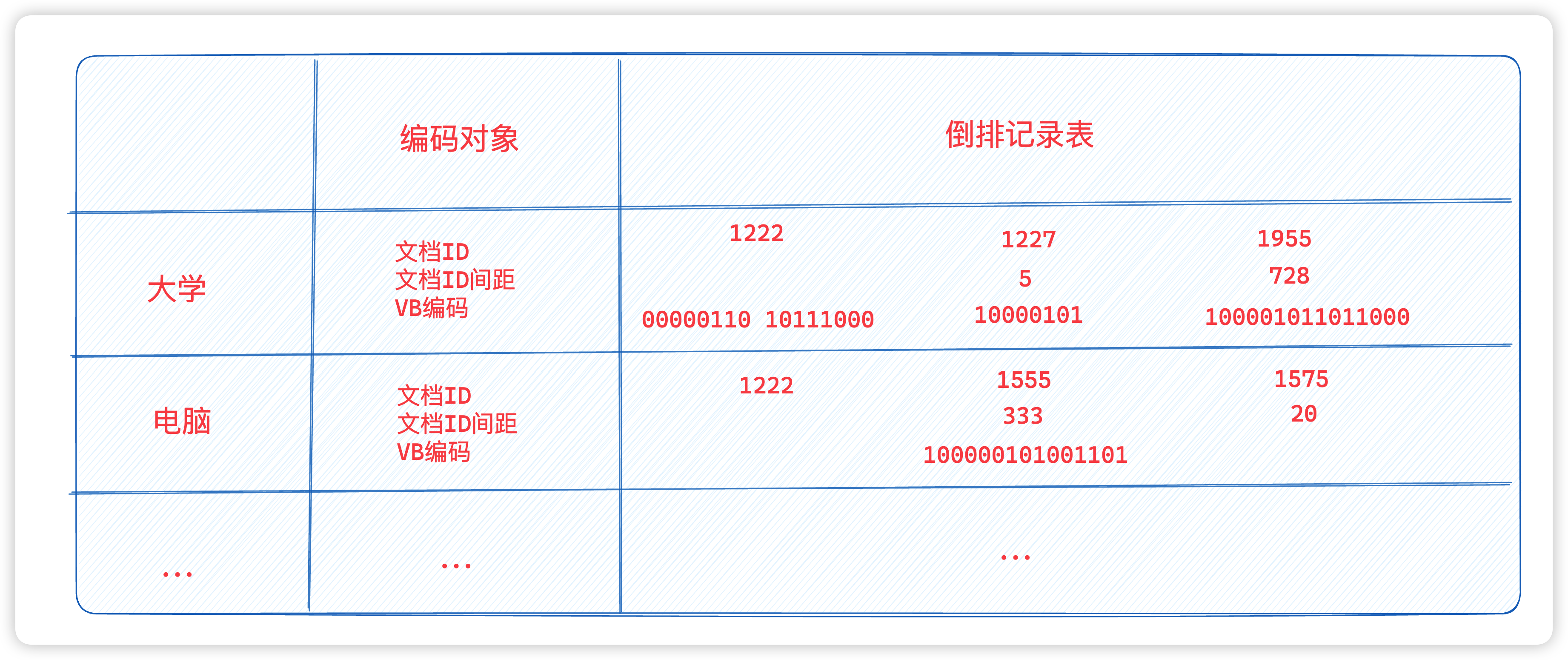
通过vb编解码,我们可以实现50%的压缩