一、目的
由于kettle的任务需要用到Hadoop(HDFS),所以就要连接Hadoop服务。
之前使用的是kettle9.3,由于在kettle新官网以及博客百度等渠道实在找不到shims的驱动包,无奈换成了kettle9.2,kettle9.2的安装包里自带了shims的驱动包,不需要额外下载,挺好!
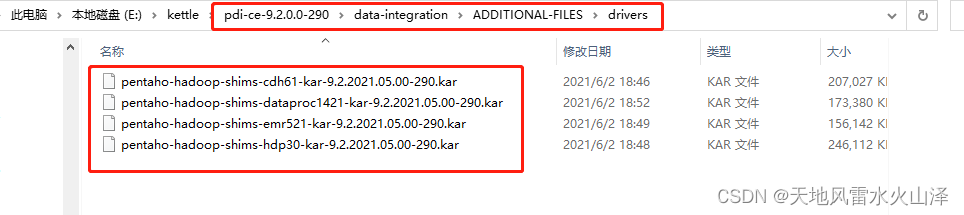
二、各工具版本
(一)kettle9.2.0
kettle9.2.0安装包网盘链接,请看鄙人拙作
http://t.csdn.cn/VccRx![]() http://t.csdn.cn/VccRx里面有目前我有的各种kettle安装包网盘链接
http://t.csdn.cn/VccRx里面有目前我有的各种kettle安装包网盘链接
(二)Hadoop3.1.3
三、前提
kettle9.2已经成功连接Hive3.1.2,即已复制Hadoop和Hive的配置文件
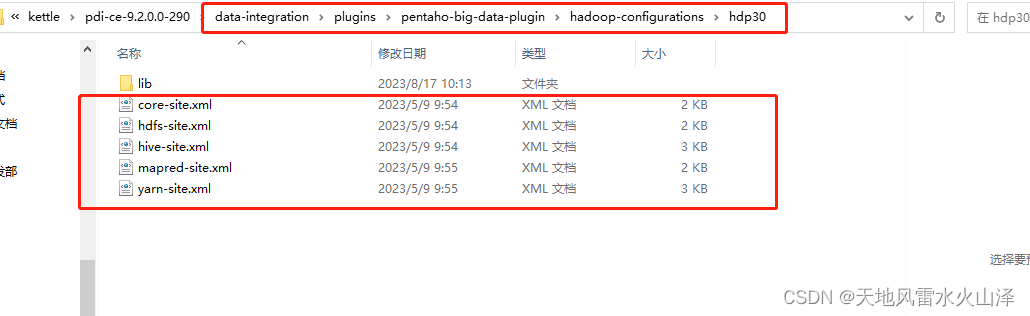
注意:如果kettle中还需要使用HBase,那配置文件还需要加上 hbase-site.xml
四、连接步骤
(一)开启kettle服务,右击Hadoop clusters,选择Add driver

(二)点击Browse,到data-integration\ADDITIONAL-FILES\drivers文件夹下,选择与自己Hadoop匹配驱动包
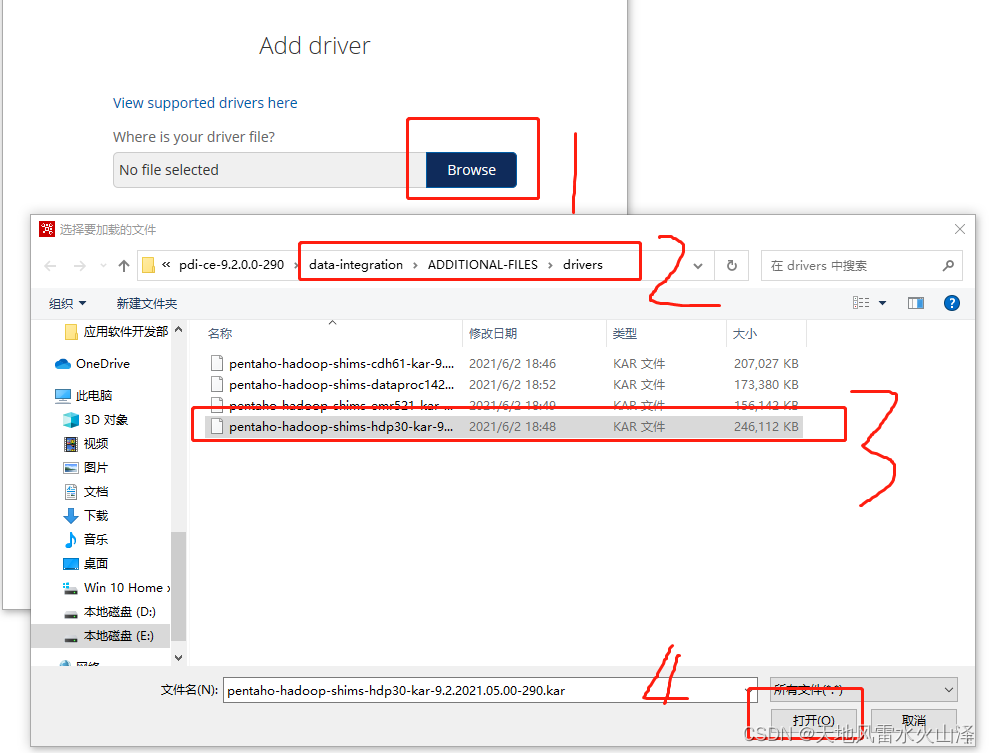
(三)选好驱动包后,点击Next
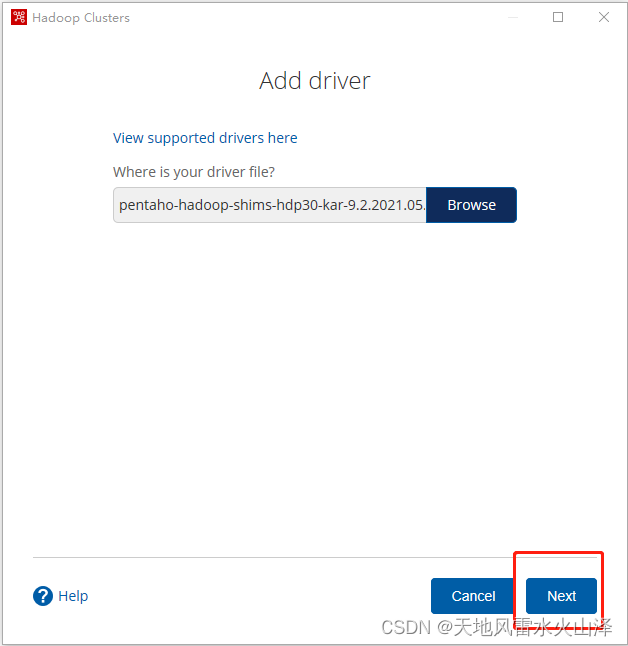
(四)之后kettle就成功导入驱动包,点击close关闭
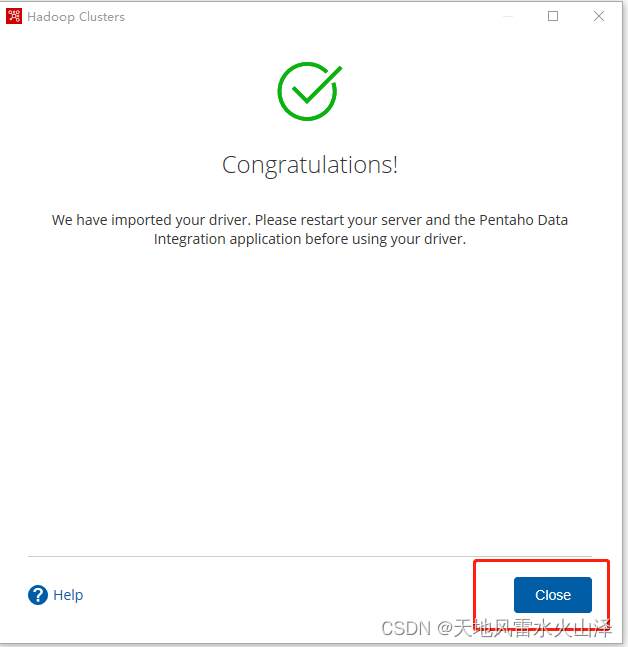
(五)Add driver导入后需要重新启动kettle,不然可能看不到Driver信息
(六)重启kettle服务后,右击Hadoop clusters,选择New driver或者修改已有Edit clusters
第一步,填写Cluster name
第二步,选择Driver
第三步,添加hive和Hadoop5个配置文件(如需要hbase则要拉取hbase-site.xml)
第四步,配置HDFS信息(注意hostname与Hadoop配置文件core-site.xml里填的一模一样)
第五步,其他配不配都行、根据自己需要。然后点击Next
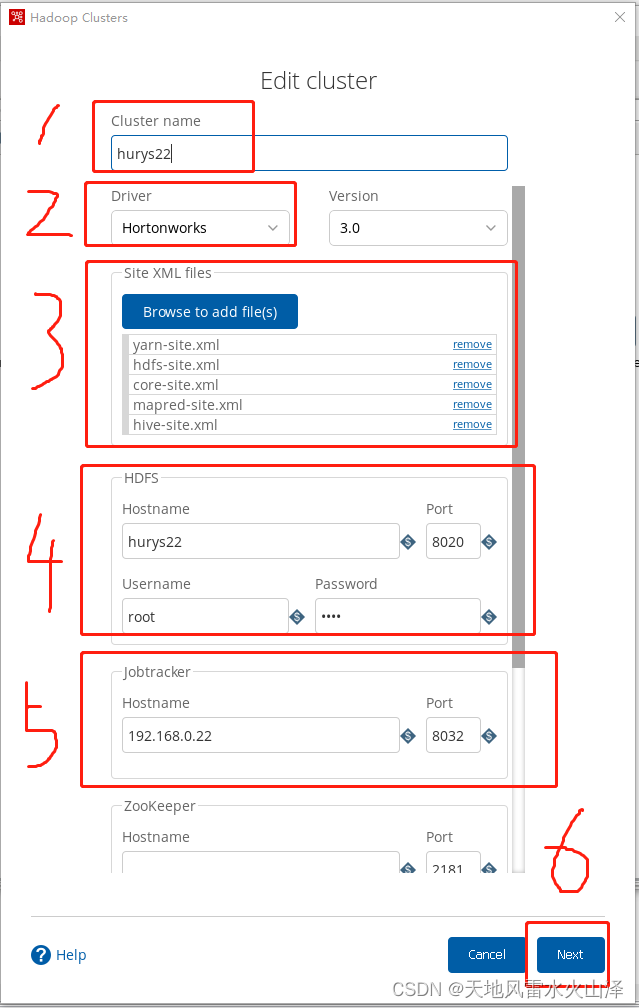
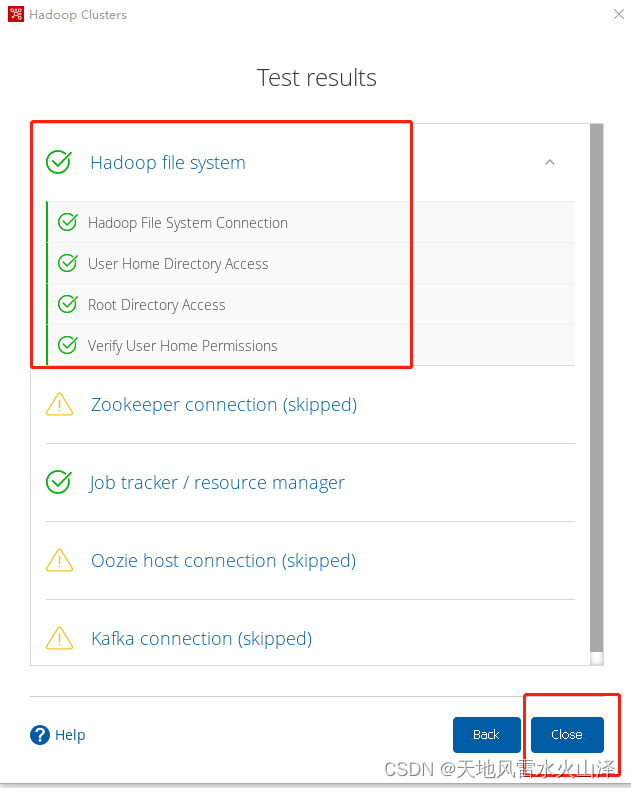
第六步,点击View test result查看具体详情
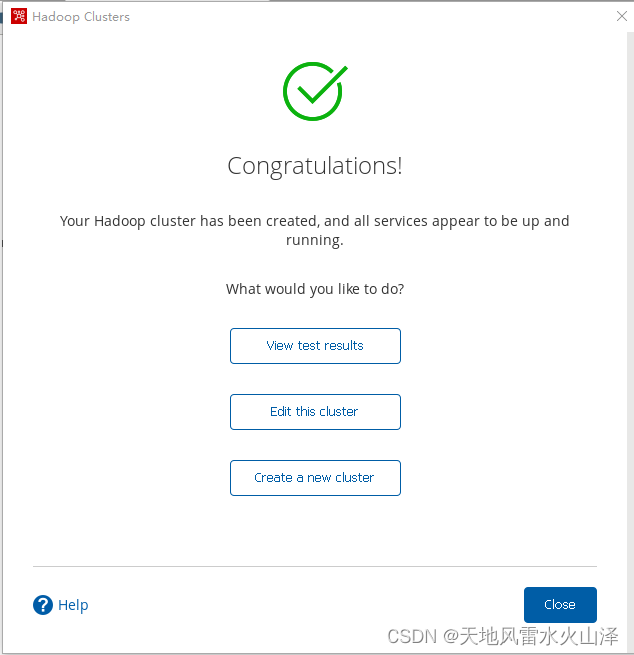
第七步,可以看到Hadoop(HDFS)可以正常连接,点击close关闭
(七)在kettle的Hadoop file output控件里打开或者创建Hadoop cluster
1、配置Hadoop cluster信息
注意:选择Vendor shim为hdp30
注意:hostname与Hadoop配置文件core-site.xml里填的一模一样

2、点击测试一下

五、运行从MySQL到HDFS 的kettle任务
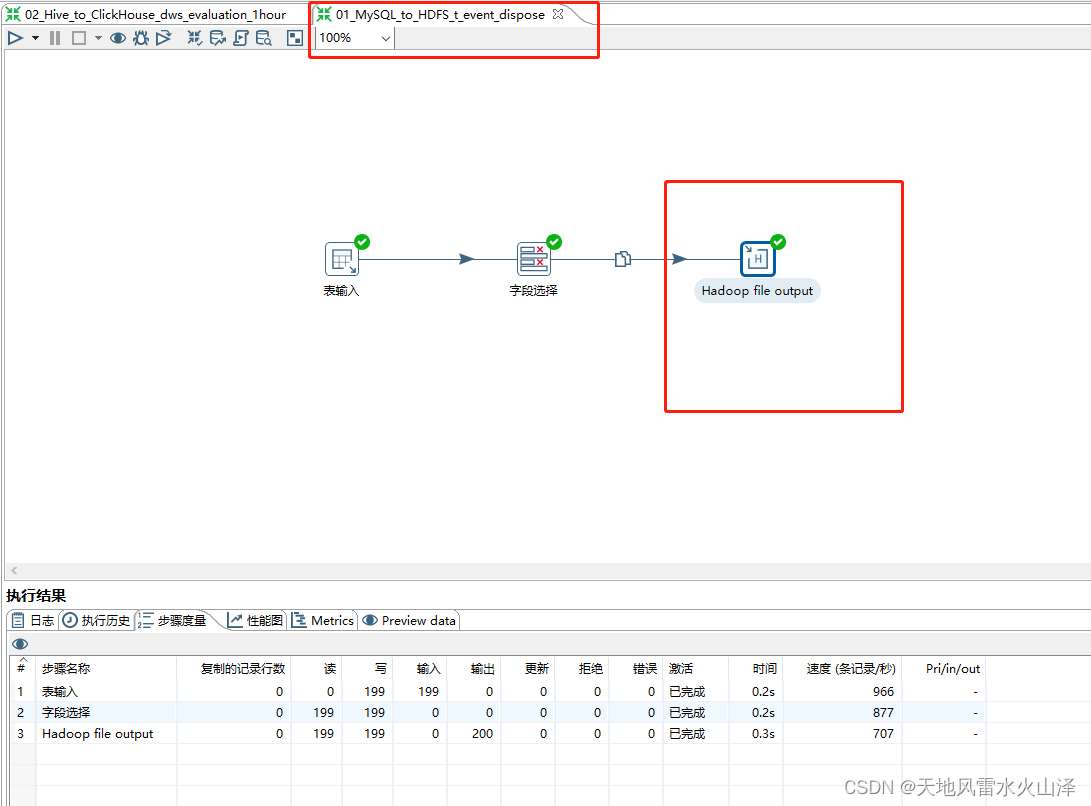
到这里,kettle9.2就成功连接Hadoop3.1.3(HDFS)了,如果需要相关安装包请到我的博客里获取网盘链接。
乐于奉献共享,帮助你我他!!!




![LeetCode[56]合并区间](https://img-blog.csdnimg.cn/f20f2dd65df94838be0864955f552b72.png)