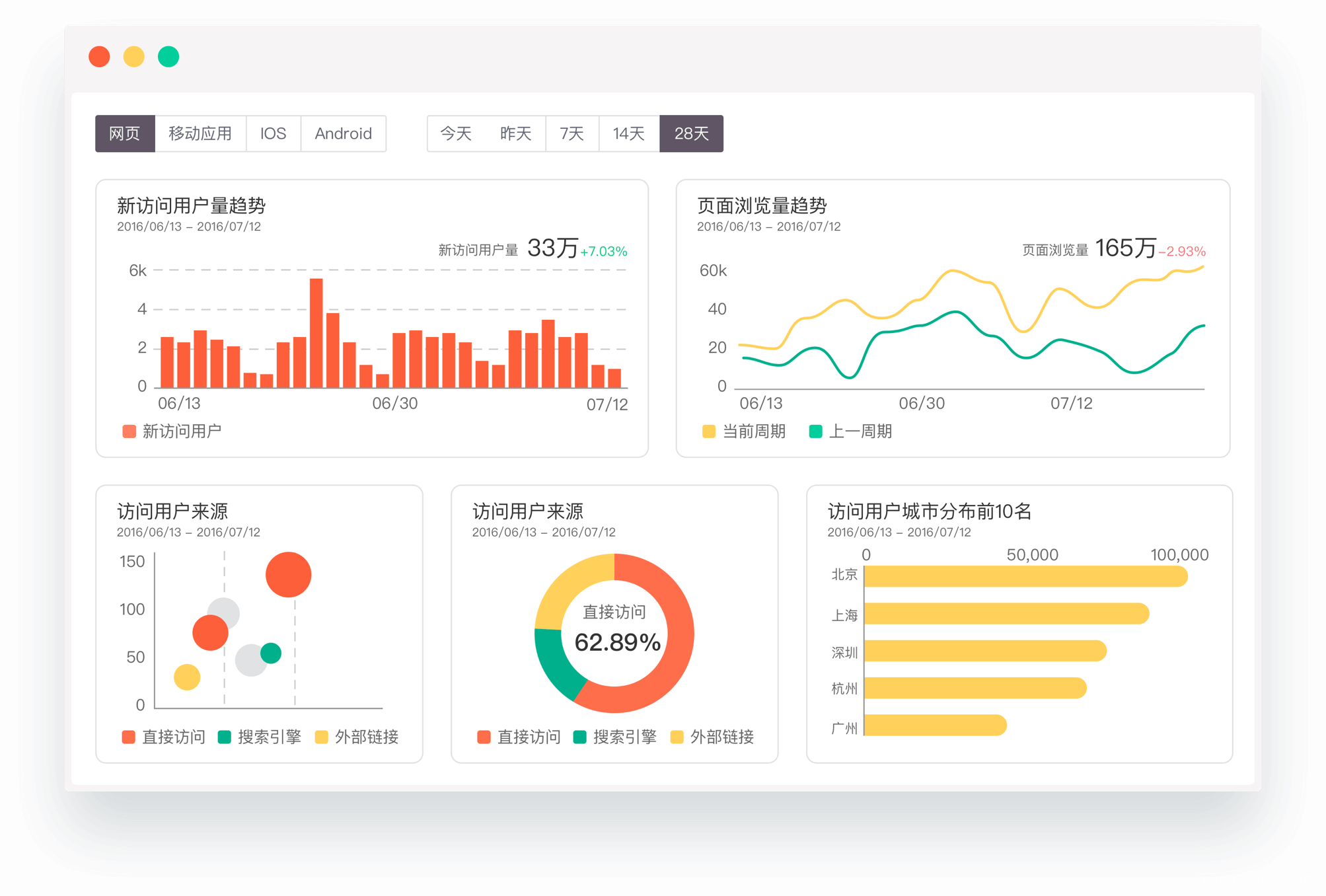
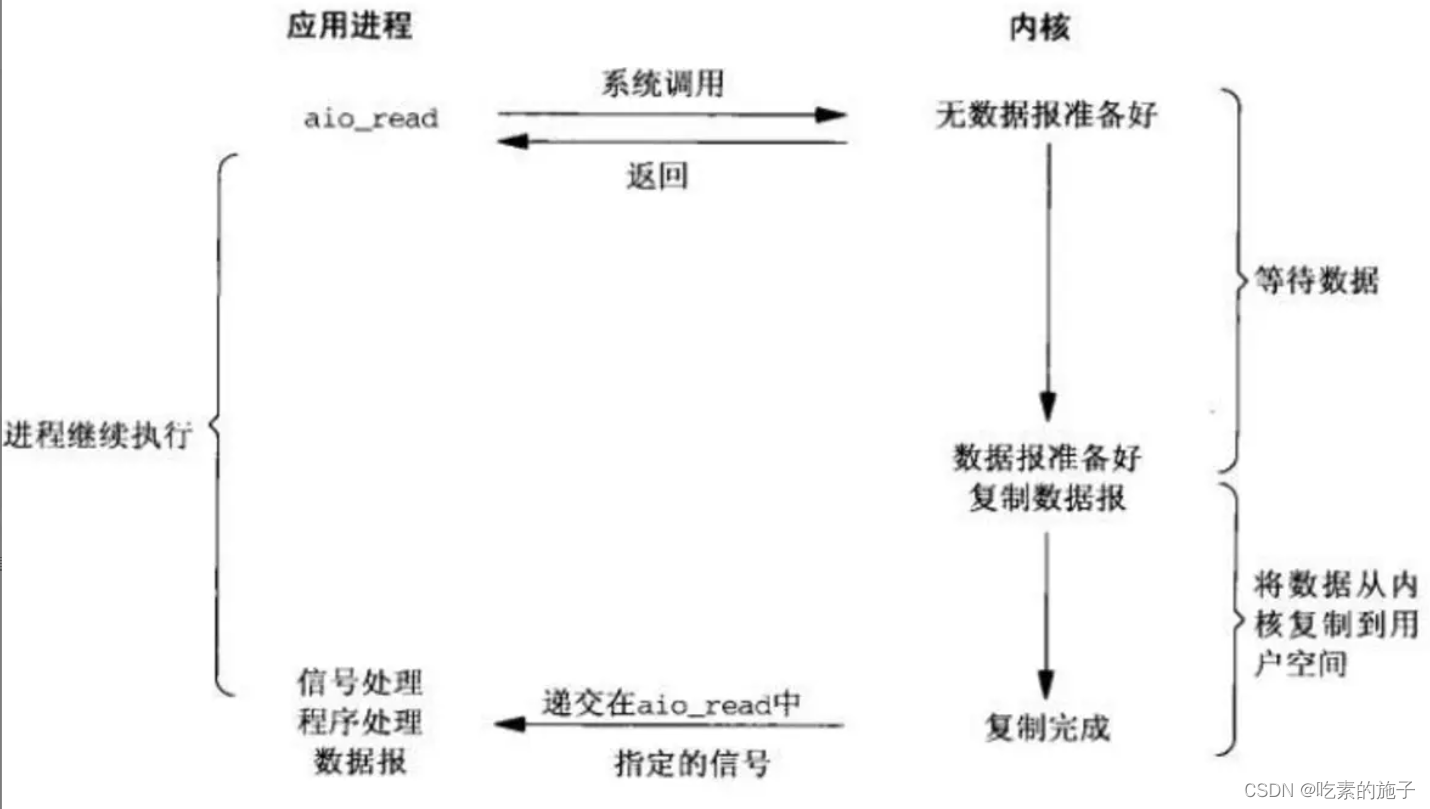
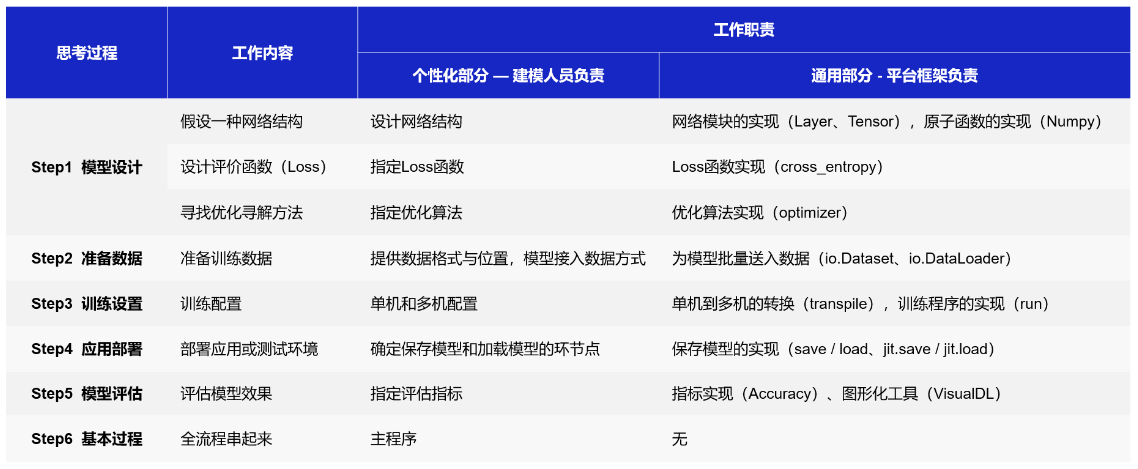
本文介绍的针对pagecache的异步内存回收方案与现有的思路有很大不同:内存回收的单位是一个个文件,再把文件的pagecache分成一个个小单元(或者叫区域)。提前判断出文件那些区域是频繁访问的(热区域),哪些区域很少访问(冷区域)。异步内存回收线程工作时,一个个遍历指定数目的文件,再把每个文件的冷区域找出来,最后回收掉冷区域的文件页page。当然,会首先遍历产生pagecache数量很多的文件,因为测试证明能从这种文件回收掉更多的冷文件页page。这种内存回收方案高效且精准。最后,还有很多其他特性,比如对容易发生refault的文件页page的处理等等,下文会一一介绍。
该方案已做成内核ko,不用编译内核,目前已经在红帽8和9系列的centos 8.3(内核版本4.18.0-240)和rocky 9.2(内核版本5.14.0-284.11.1)实现异步内存回收功能(其他内核发行版,如阿里龙蜥OS、腾讯opencloud OS、高内核版本的安卓手机等内核,理论上适配后也可以不修改编译内核的前提下使用该内核ko)。源码见GitHub - dongzhiyan-stack/async_memory_reclaime_for_cold_file_area: linux内核内存回收的另一个思路探索——基于冷热文件的冷热区域而更精准的回收冷page。
需要说明一下,近期火热的MGLRU内存回收新方案,已经合入了6.1内核。作为全新的内存回收方案,回收效果是挺好的,但是基本抛弃内核原有lru内存回收方案,对内核做了大幅改动,比较担忧它的稳定性,主流操作系统发行版短时间内估计很难会用到!
并且,内存回收大部分场景针对的是文件的pagecache,针对pagecache的内存回收不一定得大幅改动内核吧?如果能把管理文件pagecache的页高速缓存address_space管理起来,根据每个文件页page访问频率,找出冷page,然后回收掉,不就可以实现pagecache的内存回收了?这就是本文的异步内存回收方案基本思路,重点是不用修改内核、做成了内核ko。目前已经实现的基本功能,性能损耗正常,下文详细介绍这个方案。
1:内存回收的现状
线上经常遇到pagecache 200G~300G且free内存很少的场景,此时进程频繁因分配内存失败而内存回收,容易造成阻塞、性能抖动!此时大概率kswapd进程也在疯狂回收内存!并且,网卡软中断里分配skb有关数据结构的page时因指定了GFP_ATOMIC标记而禁止内存回收时休眠,导致内存分配时进入slow分支而频繁触发dump_stack告警信息,严重的还会导致内核crash。这200G+的内存如果能提前异步回收,就没那么多事了!可是内核只能在内存不足时才会按需回收一小部分内存!对了,还遇到一个centos 7.6内核bug,触发后容器里内存回收就io hung。遇到这么多内存回收问题,在2021年就迫切想做一个异步内存回收的内核ko工具,灵活方便,关键是不用修改编译内核!
Linux内核原生的内存回收方案简单说下:内存page分为匿名页page和文件页page两类,分别存入inactive/active anon、inactive/active file lru链表。文件页page主要来自pagecache,内存回收大部分情况下也是从pagecache里回收的。注意,本文讨论是针对pagecache的文件页page内存回收,不讨论匿名页的内存回收。
内核原生内存回收方案比较被动:必须要等到进程分配时,当前内存zone的可直接分配的free内存数小于内存zone的min/low/high的内存水位值+内核预留内存时,才会进行直接内存回收或唤醒kswapd线程回收内存。这对于敏感业务,很容易因分配不出内存而性能抖动!
并且,保存在active lru链表的page一般是最近多次访问的(热page),保存在inactive lru链表的page一般是最近没访问过的(冷page)。内存回收时是从inactive lru链表尾扫描一些page,尝试内存回收,这个策略貌似看着是合理的,因为inactive lru链表上的page是最近没访问过的,内存回收就应该回收掉不经常访问的page,而经常访问的page不能回收。但是却经常有如下情况:
1:一些page在某个时间点被频繁访问后被移入active lru链表头,但是之后很长一段时间就不再被访问了。此时应该把这些page”降级”移动到inactive lru链表,但是内核没法做。总不能遍历active lru链表上的page,看看哪些page最近没被访问了,就移动到inactive lru链表吧?遍历过程需要全程加pgdat->lru_lock或lruvec->lru_lock锁,损耗性能会很大。
2:遍历inactive lru链表尾上的page,在内存回收这些page过程又被访问了,此时发生了refault现象。内核改善措施是增大active lru链表长度,增加page在active lru停留的时间。说实话,这个效果并不是太好。真正有效的措施是,对发生refault的page做个标记,后续内存回收尽量不回收这种page。
2:内存回收方案的改进
目前的异步内存回收方案都修改了内核,能否把异步内存回收做成一个ko,这样不用修改内核了,灵活很多。除了这点之外,有如下改进会更好:
- 1:能否不再理会内核的active/inacvie lru链表,而自定义一个内存page链表,page频繁被访问则移动到链表头,留在链表尾的都是冷page。内存回收时直接扫描链表尾的冷page,碰到热page直接返回,这样内存回收效率比较高。
- 2:文件回收的单位是一个个文件。同时,要能识别出消耗pagecache很多的文件(比如pagecache消耗了几个G的文件),内存回收时要先扫描这些pagecache很多文件的文件页page,因为更容易扫描出很多的冷page,内存回收效率比较高。
- 3:文件回收的单位是一个个文件,但是还要把文件的pagecache再分割成一个个小单元(区域)。为什么要这样?根据线上调试经验,文件索引是0的文件页page0被频繁访问后,索引是1的文件页page1有很大概率也会被访问。前后挨着的文件页page的冷热属性相近,因为组成一个内存page单元,一起参与内存回收比较合适。
如下图所示,这是一个4k*12大小的文件读写后产生的pagecache示意图,page0是文件地址0~4k文件数据对应的pagecache,就是索引是0的文件页page,其他类推。page0、page1、page3、page8、page10、page11访问的很频繁,是热page。剩下的page很少访问,是冷page。

图 2.1
这种情况其实挺常见的,如前文所说,把 page0~page3、page4~page7、page8~page11分别作为3个内存page单元,一起参与内存回收比较合适。分组效果如下:
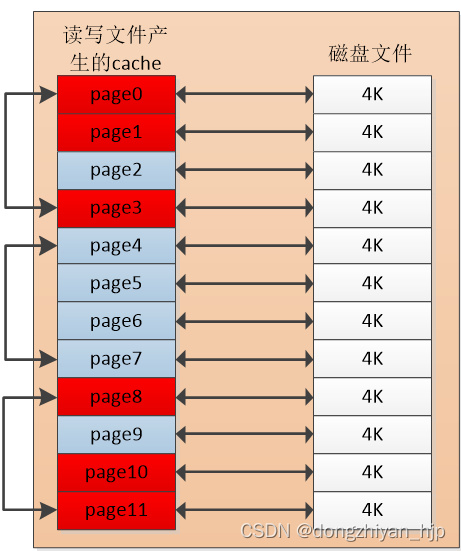
图 2.2
每个page被访问一次则内存page单元的访问计数加1。内存回收时先扫描这3个内存page单元,根据访问计数大小判断冷热程度,然后再回收冷的内存page单元的page。这样的内存回收效率应该比较高。好的,总结下本文介绍的异步内存回收方案,在“不修改内核,做成内核ko”的框架下。主要思路如下:
1:为每个文件分配一个file_stat数据结构,管理每个文件的所有pagecache。并且把每个文件的pagecache均分成若干个区域(每个区域包含4个索引连续的page),每个区域作为一个内存page单元。并为每个内存page单元分配一个file_area数据结构,主要统计这个内存page单元page的访问计数,如下图所示:
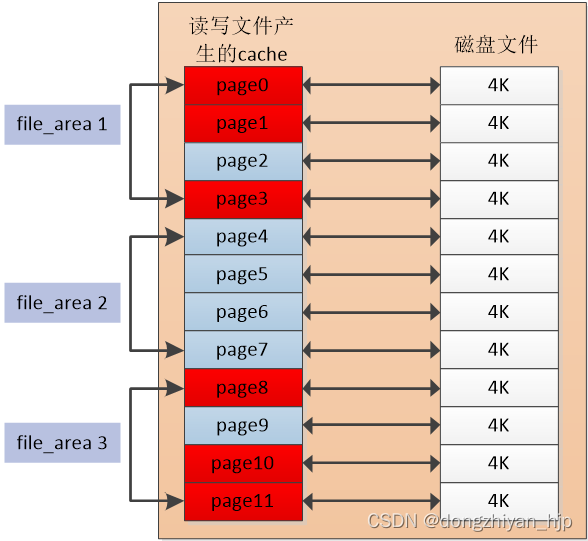
图 2.3
2:创建一个内核线程,负责异步内存回收工作,默认每1分钟运行一次,每次运行时先令全局age计数加1(这个age的思路参考了MGLRU的方案,作用一致)。同时,每个文件的每个内存page单元file_area,也有一个age计数。如果某个内存page单元file_area对应的文件页page被访问了,则该内存page单元file_area的age就要更新为全局age。如果一个内存page单元file_area对应的文件页page长时间不被访问,它的age计数就很小,称为冷file_area,内存回收时就要回收这些file_area对应的文件页page。举个例子,如下图所示:

图 2.4
现在全局age是10,异步内存回收线程已经运行了10次(每个周期1分钟)。file_area1和file_area3的age是10,说明二者对应的文件页page最近一个周期被访问过,被判定是热file_area。file_area2的age是2,说明已经至少有8个周期(8分钟)内其对应的文件页page没有被访问过,被判定是冷file_area,内存回收时优先回收file_area2的4个文件页page。
3:针对消耗pagecache多的文件,内存回收时优先扫描这些文件的内存page单元,大概率能回收很多冷page。这点下文会有讲解
每个文件的内存page单元file_area在代码里是怎么组织起来呢?用一个内核双向链表list_head即可: 
图 2.5
如图,展示的一个文件的pagecache简易组织情况。这个文件的pagecache共有page0~page23这些文件页page。每个内存page单元file_area对应该文件的4个文件页page,一共有6个file_area。最初全局age是0,每个file_area的age都是0。假设在第5个周期,全局age增加为5,此时file_area 1和file_area5对应的page被访问了,则把全局全局age赋值给这些file_area自己的age,如下:

图 2.6
这些file_area的组织比较混乱,有些file_area最近访问过,有些file_area最近没访问过。内存回收时只想把最近没有访问过的file_area(age很小)找出来,遍历整个链表代价太大了!于是当一个file_area的page被访问时,就把file_area移动到链表头,如下:

图 2.7
这样就好多了,我只用从链表尾遍历file_area,遇到age很小的file_area则一直向前遍历,如果如果age偏大的则结束遍历。这样就避免了很多无用功,因为最近被访问过的文件页page对应的file_area都移动到了链表头!
最后,创建一个异步内存回收线程,从这个链表尾依次扫出 file_area6、file_area2、file_area4、file_area3这些age很小的file_area。因为这些file_area对应的的文件页page较长时间都没有访问了,那就把这些page找出来并回收掉。
这就是本文异步内存回收的基本方案,就是想办法把长时间未被访问的文件pagecache的文件页page找出来并回收掉!难点之一是不修改内核源码的前提下(做成一个内核ko),把产生pagecache的文件组织起来,判定这些文件pagecache中,哪些文件页page是频繁访问的(热page),哪些文件页page是长时间不被访问的(冷page),最后把冷page回收掉!另外一个难点是怎么高效的组织这些文件pagecache的文件页冷热page,快速找到每个文件的冷文件页page,性能损耗还要低!当然还有很多其他细节,下文结合示意图再详细讲讲。
3:示意图详解异步内存回收机制
3.1 整体框架介绍
前文已经介绍了针对单个文件的pagecache回收思路,一个linux系统有成千上万个文件,每个文件对应一个file_stat结构,该怎么组织起来这些文件? 一个文件也会有相当多文件页page,这就导致会有相当多数目的内存page单元file_area(默认一个file_area对应4个索引连续的文件页page)。这些file_area对应的文件页page有些是频繁访问的(热page);有些是很少访问(冷page)而要参与内存回收的;有些file_area的文件页page被内存回收后短时间内又被访问了,发生refault现象,则这种file_area对应的文件页page需要一段时间内禁止再内存回收,防止再发生refault……..情况很复杂,该怎么组织起来这些file_area?一点一点讲解。
一个文件对应一个file_stat结构,一个文件的pagecache中,4个文件页page对应一个内存page单元file_area,file_stat怎么与file_area关联起来?file_stat又怎么与文件的inode、页高速缓存结构address_space产生联系的呢?当访问一个文件的pagecache时,便会执行mark_page_accessed()函数(现在也在考虑换成pagecache_get_page函数,效果一样,但是可以解决高版本内核buffer io write不执行mark_page_accessed函数的问题,阅读本方案的源码时需注意),原始定义如下:
void mark_page_accessed(struct page *page)
该函数默认功能是将inactive lru链表上的page随着访问次数的增加而移动到active lru链表。本方案 kprobe 该函数,获取到读写的文件页page指针,通过page->mapping得到文件页高速缓存结构struct address_space。而address_space结构体最后在红帽8和9系列内核有预留字段unsigned long rh_reserved1(大部分高版本的内核发行版address_space结构体最后都有预留字段,如红帽8和9、阿里龙蜥OS、腾讯opencloud OS、安卓手机内核)。
本方案正是把为文件分配的file_stat结构指针赋值给该文件唯一的address_space结构体的预留字段的成员unsigned long rh_reserved1。这样一来,就把文件的文件页page、文件页高速缓存address_space、radix/xarray tree(保存文件页page指针)、file_stat、file_area 串联起来了!如下示意图所示:

图 3.1
page、address_space、file_stat结构体通过其成员相互指向,而file_area默认添加在file_stat结构体成员file_area_temp这个链表上。那系统成百上千个文件的file_stat以及每个文件产生的属性繁多的file_area(频繁访问的、很少访问的、发生refault过的)又是怎么组织起来的呢?下文重点介绍。
3.2 文件file_stat、内存page单元file_area的组织关系
3.2.1 file_stat 是怎么组织起来的?
本方案把文件分成3类,普通文件、大文件、热文件。
- 普通文件:一个文件最开始读写产生pagecache默认被判定为普通文件
- 大文件:当一个文件的文件页page数量大于某个阀值(比如1G)则判定为大文件,异步内存回收时优先扫描大文件的文件页page,因为有较大概率能回收到很多冷page
- 热文件:当一个普通文件或大文件的文件页page大部分都访问频繁则判定为热文件,异步内存回收时一定时间内不会遍历这些文件。
每个文件对应一个file_stat结构,本方案定义了一个struct hot_cold_file_global全局结构体,把普通文件、大文件、热文件组织起来,如下:
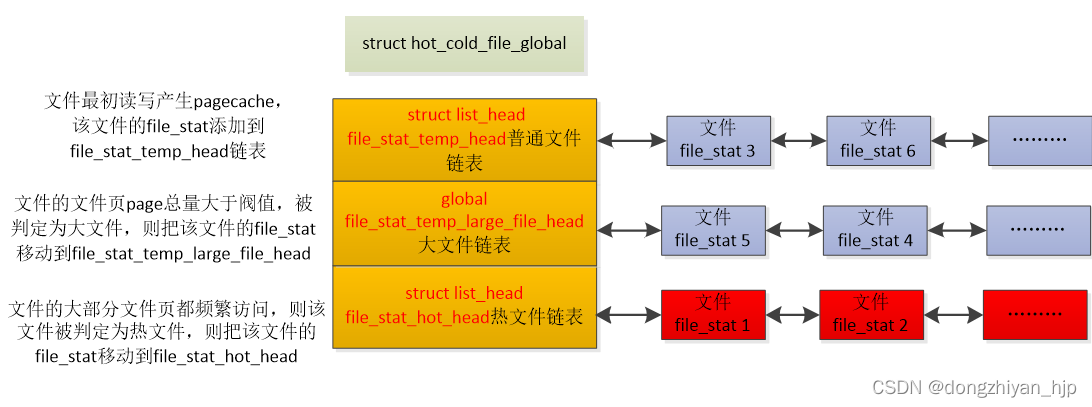
图 3.2.1
为了叙述方便,下文把struct hot_cold_file_global结构体的 struct list_head file_stat_temp_head、struct file_stat_temp_large_file_head、struct list_head file_stat_hot_head链表简称为global file_stat_temp_head、global file_stat_temp_large_file_head、global file_stat_hot_head链表。下一节开始介绍文件file_stat和内存page单元file_area的关系。
3.2.1 file_stat和file_area的关系
如图,file_stat结构体有各种各样的链表file_area_temp、file_area_hot、file_area_refault、file_area_free_temp、file_area_free,分别保存不同属性的file_area。
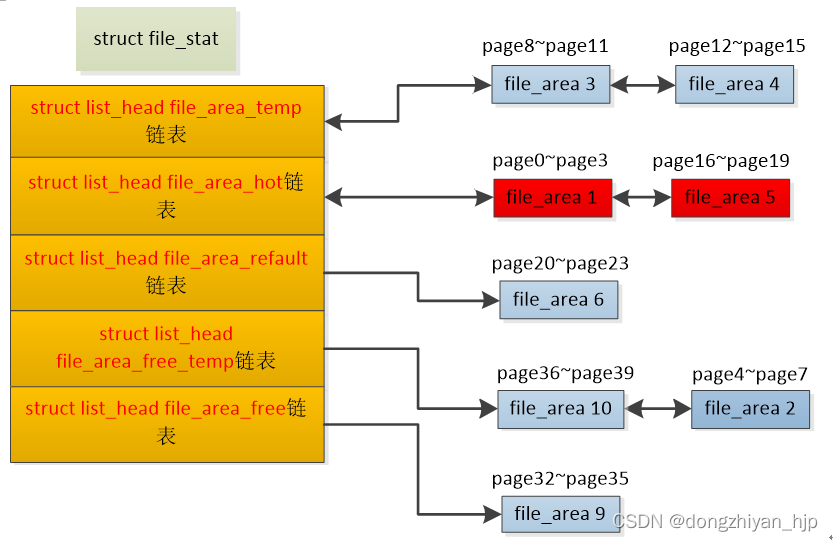
图 3.2.1.1
- 文件file_stat的struct list_head file_area_temp链表:file_area默认添加file_area_temp链表。异步内存回收线程只会遍历file_area_temp链表上file_area!如图该文件的文件页page8~page11、page12~page15对应的内存page单元file_area3、file_area4就是在file_area_temp链表。
- 文件file_stat的struct list_head file_area_hot链表:如果file_area对应的文件页page被频繁访问,被判定是热file_area,于是把该热file_area移动到file_area_hot链表。异步内存回收线程在较长一段时间都不会遍历file_area_hot链表上的file_area,因为这些file_area最近大概率还会被访问。如图该文件的文件页page0~page3、page16~page19因为频繁访问,则把对应的内存page单元file_area1、file_area5移动到file_area_hot链表。
- 文件file_stat的struct list_head file_area_refault链表:如果file_area对应的文件页page被内存回收后,短时间又被访问,则被判定是refault file_area。于是把该file_area移动到 file_area_refault链表,这些file_area在较长一段时间不会再参与内存回收,即便age与全局相差较大!如图该文件的文件页page20~page23在内存回收后,短时间内这几个索引的page又被访问了,发生refault现象,于是把page20~page23对应的内存page单元file_area6移动到file_area_refault链表。
- 文件file_stat的struct list_head file_area_free_temp链表:内存回收时,把file_area_temp链表尾的冷file_area移动到file_area_free_temp链表。内存回收时正是遍历每个文件file_stat的file_area_free_temp链表上的file_area对应的文件页page。如图,page36~page39、page4~page7 正在被内存回收,对应的内存page单元file_area10、file_area2正是在file_area_free_temp链表。
- 文件file_stat的struct list_head file_area_free链表:内存回收后的file_area移动要到file_area_free链表,如果该file_area对应的文件页page长时间不再被访问则释放掉file_area结构。如果又被访问了则要把file_area移动回file_area_temp链表。如图page32~page35在内存回收后,对应的file_area9则被移动到file_area_free链表。
下文为了叙述方便,把文件file_stat的struct list_head file_area_temp链表下文简称file_stat->file_area_temp,struct list_head file_area_hot下文简称file_stat->file_area_hot,struct list_head file_area_refault下文简称file_stat->file_area_refault,struct list_head file_area_free_temp下文简称file_stat->file_area_free_temp,struct list_head file_area_free下文简称file_stat->file_area_free。
3.2.3 file_area的冷热判断
前文多次提到热file_area,也就是频繁访问的,反应到代码层面是怎么界定的?先看下file_area结构体的主要成员,主要有两个:

图3.2.3
file_area_age就是file_area的age。异步内存回收周期默认1分钟,每过一个周期令全局age加1,当file_area对应的文件页page被访问,则把全局age赋值给file_area的成员file_area_age。因此,file_area的age就是最近一次被访问时的全局age。file_area的age与全局age差值越小,说明file_area对应的文件页page最近被访问过;file_area的age与全局age差值很大,说明这个file_area对应的文件页page很长时间没有被访问了(冷file_area)。内存回收时正是优先遍历冷file_area对应的文件页page(这些page是冷page)。
access_count是file_area在一个周期的访问计数,file_area对应的文件页page每访问一次则access_count加1。如果一个周期内file_area对应的文件页page被访问的总次数大于阀值,被判定为热file_area,则把该file_area移动到该文件的file_stat->file_area_hot链表。异步内存回收线程在较长一段时间都不会遍历file_stat->file_area_hot链表上的file_area,因为这些file_area最近大概率还会被访问。
file_area的age和access_count都表示热file_area,用途不一样。在一个内存回收周期内,如果file_area的access_count大于阀值,则立即判定该file_area是热的,然后移动到file_stat->file_area_hot链表,禁止一段时间内被异步内存回收线程遍历到。file_area的age表示file_area广义的冷热程度,如果异步内存回收线程遍历到某个file_area的access_count较小,但是file_area的age与全局age差异较小,也被判定是热file_area,这种file_area不参与内存回收,只是热的程度比不上access_count很大的file_area。
好的,文件file_stat及内存page单元file_area的组织关系已经介绍过了。下文举个例子,介绍下一个文件的文件页page(pagecache)的回收过程。
3.3 异步内存回收举例
假设有个进程访问test文件,下文演示下怎么识别出哪些文件页page是频繁访问的,哪些是不经常访问,简单说就是识别出冷热文件页page,然后只回收冷文件页page。
在第1个内存回收周期,全部读取98304大小test文件。于是先为该文件创建一个file_stat结构并添加到global file_stat_temp_head链表。接着为该文件的98304大小的pagecache分配6个内存page单元file_area1~file_area6。file_area1表示索引是0~3的文件页page0~page3,其他类推。file_area1~file_area6最初添加到该文件file_stat->file_area_temp链表。如下图:
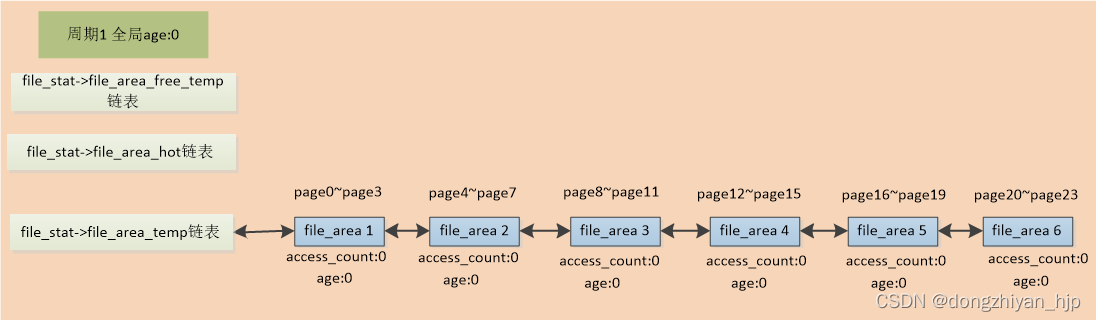
图 3.3.1
接着来到第2个内存回收周期,全局age加1为1。test文件的索引是16、20的文件页page16、page20被读取了两次,则对应的内存page单元file_area5、file_area6的age被赋值为全局age,且access_count增加到2。接着还要把file_area5、file_area6移动到file_stat->file_area_temp链表头,因为被访问过的file_area都要移动到链表头!效果如下图:

图 3.3.2
注意,这里设定只有file_area的age与全局age的差值大于阀值N(假设N=5)时,才被判定是冷file_area,然后才会回收该file_area对应的文件页page。显然此时还没有达到内存回收条件的file_area。
接着来到第3个内存回收周期,全局age加1为2。这个周期内,该文件的文件页page16、page20连续被访问了6次,超过了阀值,对应的file_area5和file_area6被判定为热file_area。则把file_area5和file_area6被移动到file_stat->file_area_hot链表,age也被赋值为2。同时该文件的文件页page5、page8也被访问了一次,则对应的file_area2、file_area3被移动到file_stat->file_area_temp链表链表头,且age被赋值2,access_count赋值1,最终效果如图所示:
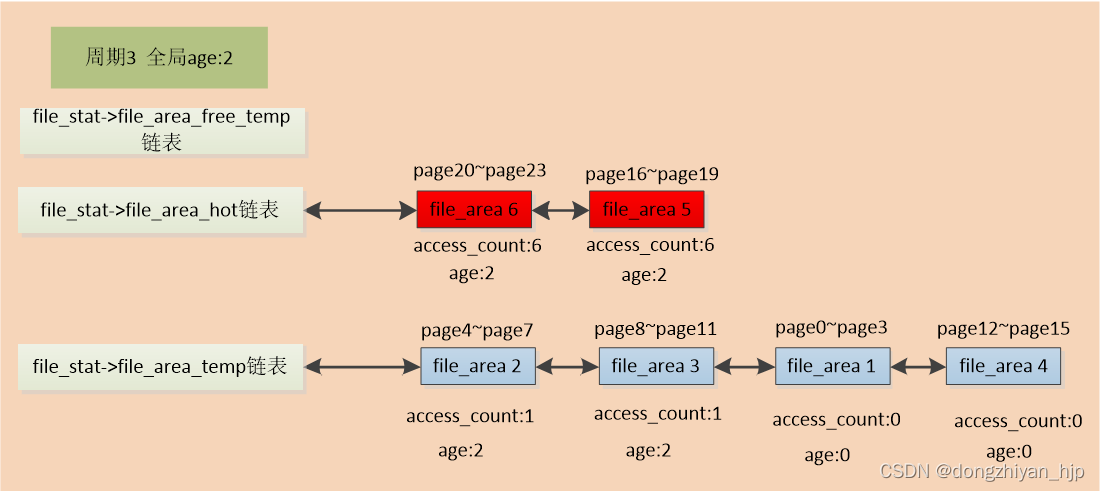
图 3.3.3
随后一直到周期7,该文件都没再被访问了,此时出现了内存回收契机。因为此时全局age增加到6,而该文件在file_stat->file_area_temp链表尾的内存page单元file_area1、file_area4对应的文件页page0~page3、page12~page15 一直没有被访问,age是0,与全局age的差值大于阀值N(假设N=5),则二者被判定是冷file_area。然后在该周期,异步内存回收线程把file_area1、file_area4移动到file_stat->file_area_free_temp链表。如图:
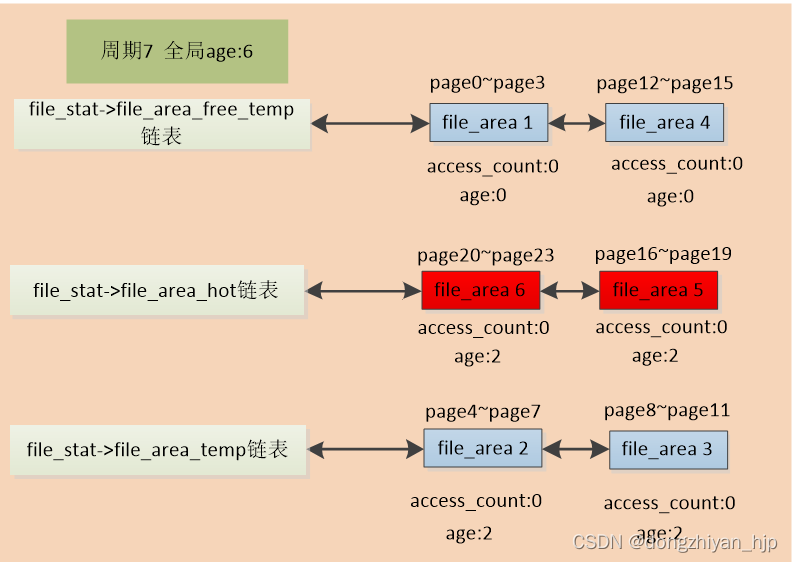
图 3.3.4
接着,异步内存回收遍历file_stat->file_area_free_temp链表上的file_area1和file_area4,根据该文件address_space的radix/xarray tree(保存文件页page指针),找到对应的page0~page3、page12~page15文件页指针。然后就尝试回收掉这8个page,具体回收流程大体模仿内核原生内存回收代码,但有很大改动。这些文件页page回收完后,把file_area1和file_area4移动到file_stat->file_area_free链表。如图:
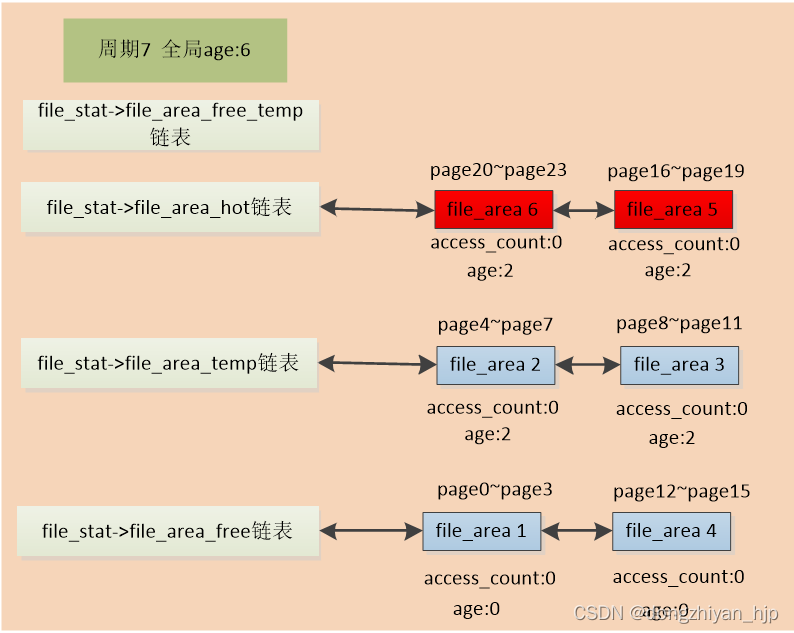
图 3.3.5
假设file_area1对应的索引是0的文件页page0在内存回收后,索引是0的page立即又被进程访问了。则发生了refault现象,于是把file_area1移动到file_stat-> file_area_refault链表,这样file_area1后期有相当长一段时间不会再被参与内存回收,即便它的age与全局age相差很大。如图:
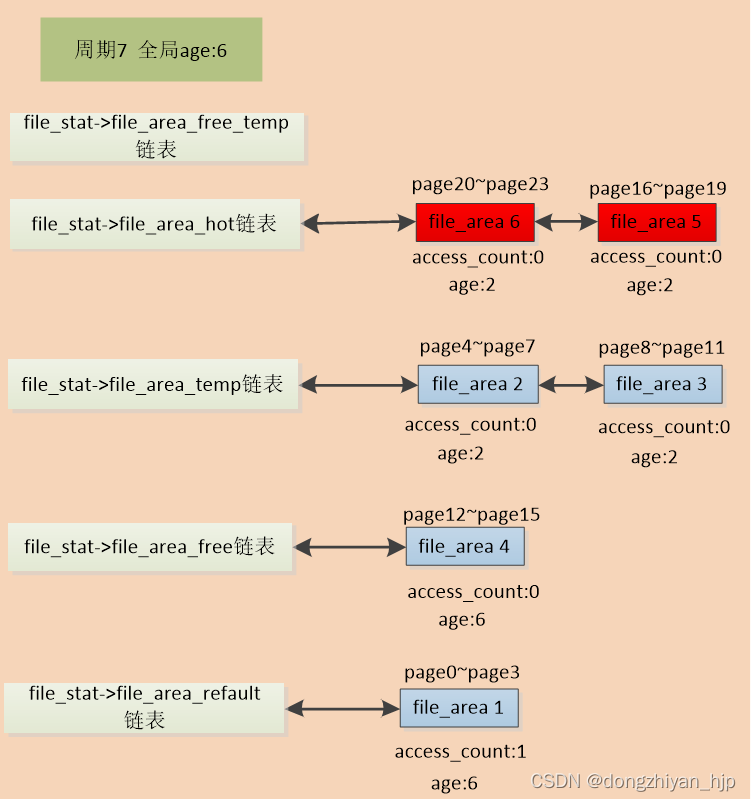
图 3.3.6
好的,以上把针对单个文件的文件页page的内存回收流程大体演示了一遍。系统有成百上千个文件时,每个文件的文件页page回收过程类似。但再结合普通文件、大文件、热文件的文件页page的回收,就很复杂了。下文从代码角度介绍下整体的异步内存回收流程,或许可以加深理解。
4:基于源码流程图聊聊异步内存回收
该方案的源码主要有两个流程:
1:文件页读写后,会执行到内核原生mark_page_accessed()函数。本方案kprobe mark_page_accessed()函数(现在也在考虑换成pagecache_get_page函数,效果一样,但是可以解决高版本内核buffer io write不执行mark_page_accessed函数的问题,阅读本方案的源码时需注意),然后执行自定义hot_file_update_file_status()函数。在函数hot_file_update_file_status()函数里:为读写的文件分配file_stat;为访问的文件页page分配对应的file_area;把file_stat、file_area添加到各种链表;增加file_area的age和访问计数access_count;判断热file_area;普通文件在达到一定条件升级到大文件或者热文件等等。
2:异步内存回收线程的入口函数是walk_throuth_all_file_area(),默认一分钟运行一次。在walk_throuth_all_file_area()函数里:令全局age加1;遍历global file_stat_temp_large_file_head大文件链表和global file_stat_temp_head普通文件链表的file_stat,从这些文件file_stat-> file_area_temp链表尾找出age与全局age差值大于阀值N的file_area(这些file_area就是冷file_area,对应的文件页page长时间不被访问,本次就回收这些page);如果遍历到的文件file_stat的file_stat->file_area_hot和file_stat-> file_area_refault链表上的file_area长时间不被访问,则要降级移动到file_stat->file_area_temp链表;如果global file_stat_temp_large_file_head 链表上的大文件,对应文件页page减少到阀值以下,则降级为普通文件,并把file_stat移动到普通文件global file_stat_temp_head链表;如果global file_stat_hot_head链表上的热文件,大部分file_area不再是热file_area,则也要降级为普通文件,并把file_stat移动到普通文件global file_stat_temp_head或global file_stat_temp_large_file_head链表等等。
细节还是比较复杂的,下边先看下文件被读写最后执行到的hot_file_update_file_status()函数的整体流程图:

可以发现,这个流程主要就是为操作的文件file_stat和本次访问的文件页page对应的内存page单元file_area:更新 file_area的age、增加file_are计数、热文件和大文件的判定、热file_area、refault file_area的判定和处理。下边看下异步内存回收线程入口函数walk_throuth_all_file_area()的整理流程:
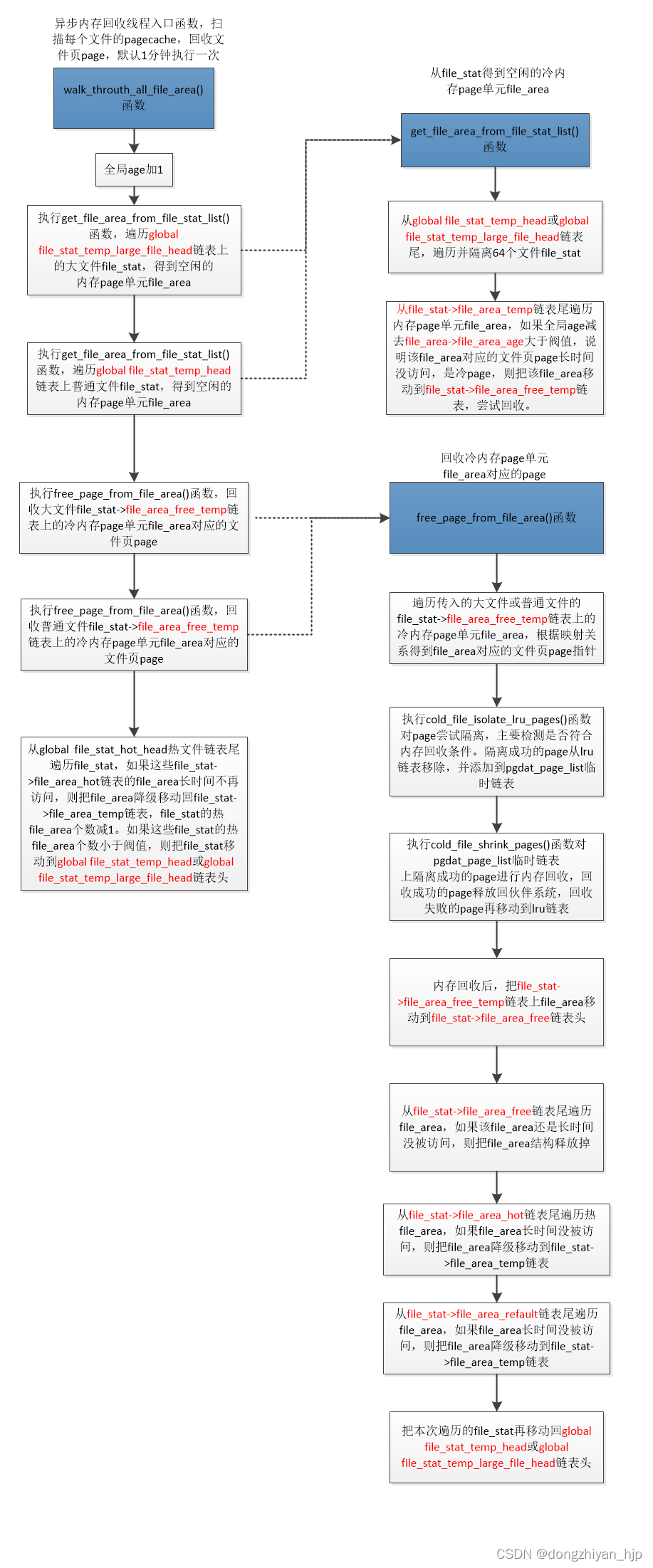
可以发现,这个流程主要讲解怎么一个个扫描文件file_stat,从 file_stat->file_area_temp链表尾扫出冷file_area,然后把冷file_area对应的文件页page回收掉。还有就是file_stat->file_area_hot和file_stat->file_area_refault链表上file_area怎么降级到file_stat->file_area_temp链表,热文件、大文件怎么的降级等等。源码就不再列了,后续的文章再讲解。
5:总结
本文只是最简单了一下异步内存回收的大体方案,实际还有很多细节没讲解,比如:
- 1:前文提过,文件的内存page单元file_area都是组织在file_stat->file_area_temp等双向链表。这就有个问题,如果某个file_area对应的文件页page被访问,就要遍历这个双向链表找到对应的file_area,如果链表上的file_area很多,太耗时了!就是设计了类似的radix tree方案,给每个file_area设置一个类似page索引的编号start_index,start_index=该file_area对应的第一个文件页page的索引除以4,因为默认一个file_area对应4个索引连续文件页page。然后把file_area指针按照start_index保存到自定义的radix tree。后续知道一个文件页page的索引后,可以快速通过该radix tree找到对应的内存page单元file_area。
- 2:单个文件file_stat->file_area_hot和file_stat->file_area_refault链表上的file_area,因为随后可能有较大概率被访问,即便age与全局age相差很大,也不参与内存。但是也不能无限期不参与内存回收!当满足一定条件下也需要把这些file_area移动到file_stat-> file_area_temp链表,参与内存回收,细节需要深究。
- 3:如果文件inode被删除了,而该文件的file_stat、file_area正在被访问,怎么做好并发访问?这是实际代码开发时最难的一点。
- 4:怎么模仿内核原生内存回收流程,实现本方案的page的隔离、回收,有很多重点。并且有很多内核非export函数不能在本方案的内核ko 里用,这个难题也很棘手。
- 5:本方案把文件分配3种,普通文件、大文件、热文件,对应文件file_stat分别放置在global file_stat_temp_head、file_stat_temp_large_file_head、file_stat_hot_head链表。当普通文件的file_area数量大于阀值则被判定为大文件,当大文件的file_area数量减少小于阀值,则要降级到普通文件;当普通文件或大文件的大部分文件页都频繁访问,则该文件就被判定为热文件。而如果热文件的大部分file_area经过较长时间后都没访问了,变成冷file_area,就要降级为普通文件或大文件。内存回收时优先扫描大文件的file_area,其次是普通文件的file_area,热文件的file_area不参与内存回收。普通文件、大文件、热文件 3者之间的转化,具体在内存回收时是怎么运作的,也是一个复杂点。
- 6:代码也不能无脑spin_lock加锁防止并发,而要用其他手段控制并发!也是代码编时一个很大的考虑点。
当然,还有很多其他细节,代码开发测试过程也遇到很多棘手的bug!就不在本文介绍了,后续再单独写文章。
本文介绍的异步内存回收方案是个不错的学习机会,源码已经开源。在模仿内核原生内存回收源码,修改成适用于本方案的内存回收代码的过程中,对内存回收的理解也加深了很多。目前已经解决了很多bug,但不排除还有隐藏bug,欢迎大佬的指导和批评指正。