一、深度学习框架
1.简介
深度学习在很多机器学习任务中都有着非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等领域都有着广泛应用。面对繁多的应用场景,深度学习框架有助于建模者聚焦业务场景和模型设计本身,省去大量而繁琐的代码编写工作,其优势主要表现在如下两个方面:
- 节省编写大量底层代码的精力:深度学习框架屏蔽了底层实现,用户只需关注模型的逻辑结构,同时简化了计算逻辑,降低了深度学习入门门槛;
- 省去了部署和适配环境的烦恼:深度学习框架具备灵活的移植性,可将代码部署到CPU、GPU或移动端上,选择具有分布式性能的深度学习框架会使模型训练更高效。
2.设计思想
深度学习框架的本质是自动实现建模过程中相对通用的模块,建模者只实现模型中个性化的部分。
在构建神经网络模型的过程中,每一步所需要完成的任务均可以拆分成个性化和通用化两个部分。
- 个性化部分:往往是指定模型由哪些逻辑元素组合,由建模者完成;
- 通用部分:聚焦这些元素的算法实现,由深度学习框架完成。
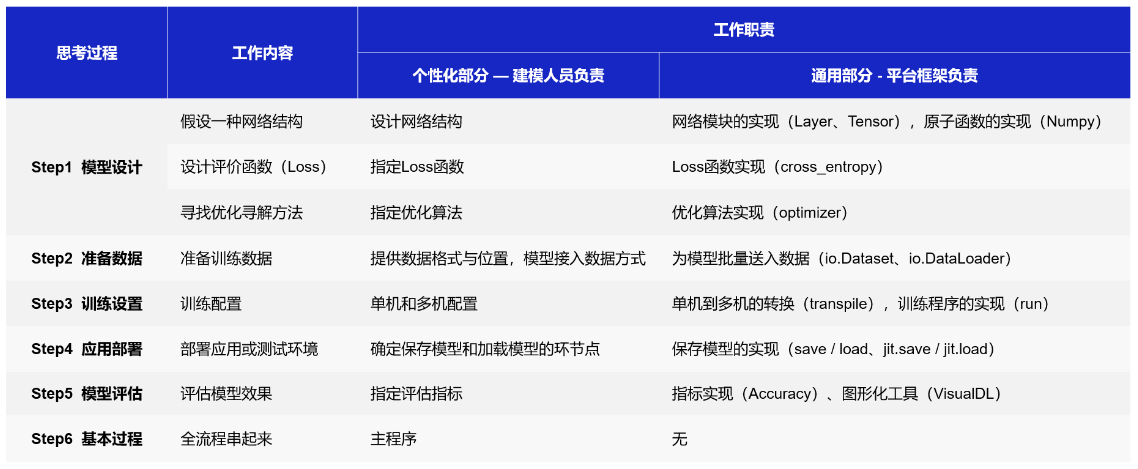
无论是计算机视觉任务还是自然语言处理任务,使用的深度学习模型结构都是类似的,只是在每个环节指定的实现算法不同。因此,多数情况下,算法实现只是相对有限的一些选择,如常见的Loss函数不超过十种、常用的网络配置也就十几种、常用优化算法不超过五种等等,这些特性使得基于框架建模更像一个编写“模型配置”的过程。
![[计算机入门] 设置屏幕分辨率](https://img-blog.csdnimg.cn/67e0e85044aa45d38b81bc96ef02663d.png)
![[自学记录06|*百人计划]Gamma矫正与线性工作流](https://img-blog.csdnimg.cn/img_convert/fb9053fca186cfaba119a681ab098e7a.jpeg)