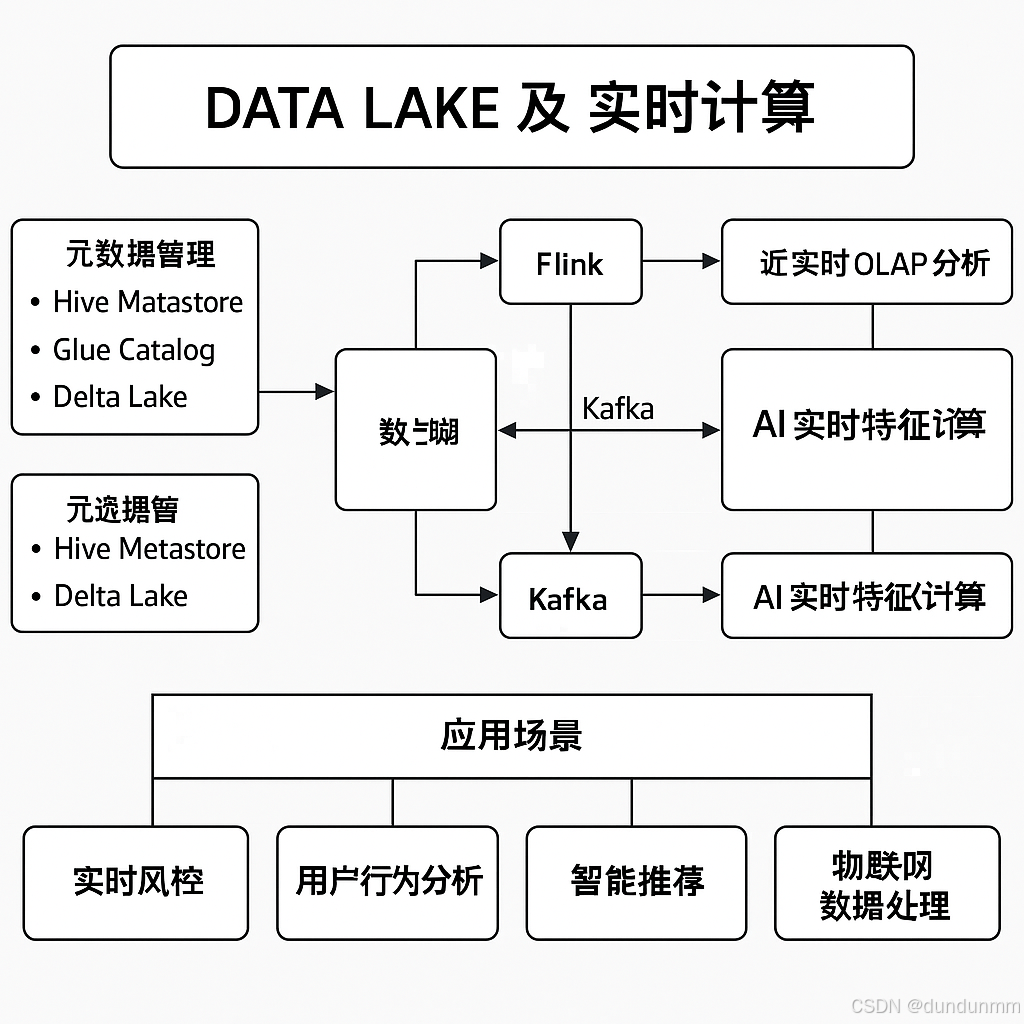
一、普通全量微调模型
核心机制:模型克隆
-
深拷贝创建
- 通过
create_reference_model(model)对当前模型进行完全复制(包括所有层和参数)。 - 示例代码:
import copy def create_reference_model(model): ref_model = copy.deepcopy(model) ref_model.requires_grad_(False) # 冻结参数 ref_model.eval() # 评估模式 return ref_model - 技术细节:深拷贝会递归复制所有子模块,确保参考模型与原始模型完全独立。
- 通过
-
参数冻结与评估模式
requires_grad_(False):关闭梯度计算,防止反向传播影响参考模型。eval():关闭Dropout和BatchNorm等训练专用层,保证输出稳定性。
-
内存占用分析
- 原始模型参数量为N时,总内存占用≈2N。
- 典型场景:7B参数的模型需要约14GB显存(假设FP32精度)。
-
同步机制(可选)
- 启用
sync_ref_model后,通过回调函数周期性将参考模型参数替换为当前模型:class SyncRefModelCallback: def on_step_end(self, args, state, control, **kwargs): with torch.no_grad(): for ref_param, model_param in zip(ref_model.parameters(), model.parameters()): ref_param.copy_(model_param.detach()) - 应用场景:允许参考模型跟随训练进度,实现动态策略约束。
- 启用
二、PEFT微调模型
核心机制:动态适配器切换
-
PEFT架构特性
- 典型实现(如LoRA):在原始模型基础上添加低秩适配器矩阵。
- 参数分布:基础模型参数冻结(占比≈95%),仅训练适配器(占比≈5%)。
-
禁用适配器原理
- 上下文管理器
disable_adapter()的工作流程:class LoraModel: def disable_adapter(self): original_forward = self.layer.forward self.layer.forward = self.original_forward # 恢复原始前向传播 - 技术效果:前向计算时绕过所有适配器层,等同于原始模型。
- 上下文管理器
-
内存优化原理
- 不需要存储额外模型实例,节省≈N显存。
- 示例对比:7B模型PEFT微调时,显存占用从14GB降至≈7.5GB。
-
梯度计算隔离
- 即使禁用适配器,反向传播时仍只会更新适配器参数。
- 实现方式:通过PyTorch的
torch.no_grad()上下文管理器:with model.disable_adapter(): with torch.no_grad(): # 确保不计算参考模型梯度 outputs = model(inputs)
三、DeepSpeed ZeRO-3模式
核心机制:权重重加载
-
ZeRO-3分片原理
- 参数分布:模型参数被划分到多个GPU,单个设备只保留部分参数。
- 示例:8 GPU训练时,每个GPU存储约1/8的参数和优化器状态。
-
无法深拷贝的根本原因
- 分片后的参数无法通过常规方式访问完整副本。
- 尝试复制会引发错误:
RuntimeError: Cannot access full parameter outside of forward/backward
-
重加载实现细节
- 从磁盘或缓存重新初始化模型:
model_id = "qwen/Qwen1.5-7B" ref_model = AutoModelForCausalLM.from_pretrained( model_id, device_map="auto", torch_dtype=torch.bfloat16 ) - 优化技巧:使用
accelerate库的disk_offload功能减少内存压力。
- 从磁盘或缓存重新初始化模型:
-
分布式一致性保证
- 通过DeepSpeed的
broadcast_parameters()确保所有GPU加载相同初始权重。 - 关键代码:
deepspeed.utils.broadcast_parameters(ref_model.state_dict())
- 通过DeepSpeed的
四、KL散度计算流程
无论采用何种参考模型机制,最终目标都是计算:
D
K
L
(
π
θ
∣
∣
π
r
e
f
)
=
E
x
∼
π
θ
[
log
π
θ
(
x
)
−
log
π
r
e
f
(
x
)
]
D_{KL}(\pi_{\theta} || \pi_{ref}) = \mathbb{E}_{x \sim \pi_{\theta}}[\log \pi_{\theta}(x) - \log \pi_{ref}(x)]
DKL(πθ∣∣πref)=Ex∼πθ[logπθ(x)−logπref(x)]
-
计算步骤
def compute_kl_divergence(model, ref_model, inputs): with torch.no_grad(): ref_logits = ref_model(**inputs).logits current_logits = model(**inputs).logits kl = F.kl_div( F.log_softmax(current_logits, dim=-1), F.softmax(ref_logits.detach(), dim=-1), reduction='batchmean' ) return kl -
各机制下的实现差异
- 普通微调:直接调用
ref_model计算 - PEFT:在
disable_adapter()上下文中用同一模型计算 - ZeRO-3:使用独立加载的
ref_model计算
- 普通微调:直接调用
五、选型建议
| 微调类型 | 适用场景 | 显存开销 | 计算效率 |
|---|---|---|---|
| 普通全量微调 | 单卡/多卡非ZeRO环境 | 高 | 高 |
| PEFT微调 | 低显存设备(如消费级GPU) | 低 | 中 |
| DeepSpeed ZeRO-3 | 超大模型训练(如>20B参数) | 最低 | 较低 |
典型决策流程:
是否需要训练超大模型(>20B)?
├─ 是 → 采用DeepSpeed ZeRO-3
└─ 否 → 显存是否充足(如A100 80G)?
├─ 是 → 普通全量微调
└─ 否 → 使用PEFT微调