__CUDA_ARCH__属于NVCC的宏
5.7.4. Virtual Architecture Macros 给出说明
The architecture identification macro __CUDA_ARCH__ is assigned a three-digit value string xy0 (ending in a literal 0) during each nvcc compilation stage 1 that compiles for compute_xy.
This macro can be used in the implementation of GPU functions for determining the virtual architecture for which it is currently being compiled. The host code (the non-GPU code) must not depend on it.
The architecture list macro __CUDA_ARCH_LIST__ is a list of comma-separated __CUDA_ARCH__ values for each of the virtual architectures specified in the compiler invocation. The list is sorted in numerically ascending order.
The macro __CUDA_ARCH_LIST__ is defined when compiling C, C++ and CUDA source files.
在编译时才定义,因此在代码编辑器中是看不到它的值的,也不要尝试自己写这个宏
For example, the following nvcc compilation command line will define __CUDA_ARCH_LIST__ as 500,530,800 :
nvcc x.cu \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_50,code=sm_52 \
--generate-code arch=compute_50,code=sm_50 \
--generate-code arch=compute_53,code=sm_53
通过nvcc编译命令 -arch设置架构
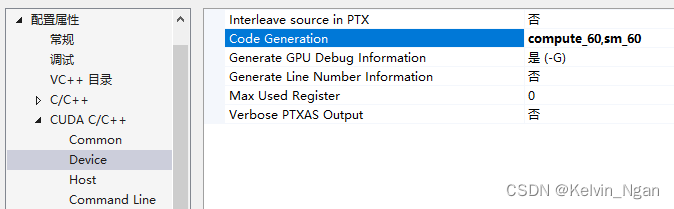
在vs中,如果设置了多个Code Generation(即命令-gencode=arch=compute_xx,code=sm_xx),会以最高的架构版本为准
更多技术细节见NVIDIA CUDA Compiler Driver NVCC
如果想打印看看__CUDA_ARCH__宏,可以这样做
#include <stdio.h>
__global__ void Mykernel()
{
printf("%d\n", __CUDA_ARCH__);
}
int main()
{
Mykernel<<<1, 5>>>();
cudaDeviceSynchronize();
return 0;
}





![SpringSecurity[5]-基于表达式的访问控制/基于注解的访问控制/Remember Me功能实现](https://img-blog.csdnimg.cn/a886154fde4e41619062cccc238fd14d.png)


![[附源码]Node.js计算机毕业设计防疫科普微课堂Express](https://img-blog.csdnimg.cn/6781557975f14564967f6f74db291a74.png)