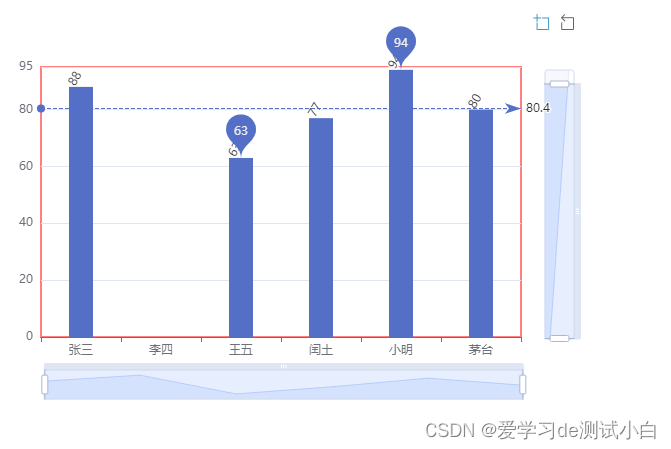
数据结构与算法
数据结构和算法,一个非常古老的课题,工作的时候,一般只求程序能跑,并不太关注性能
import java. util. Scanner ;
public class test {
public static void main ( String [ ] args) {
int i = 0 ;
int j = 0 ;
while ( true ) {
j = 0 ;
Scanner scanner = new Scanner ( System . in) ;
if ( scanner. hasNextInt ( ) ) {
i = scanner. nextInt ( ) ;
} else {
System . out. println ( "请输入整数(需要是int范围的整数,不能大于等于2147483648,否则也会到这里)" ) ;
}
if ( i < 2 ) {
System . out. println ( "请输入大于等于2的数" ) ;
} else {
for ( int a = 2 ; a< i; a++ ) {
if ( i% a== 0 ) {
System . out. println ( "不是质数" ) ;
j = 1 ;
break ;
}
}
if ( j == 0 ) {
System . out. println ( "是质数" ) ;
}
}
}
}
}
import java. util. Scanner ;
public class test {
public static void main ( String [ ] args) {
int i = 0 ;
int j = 0 ;
while ( true ) {
j = 0 ;
Scanner scanner = new Scanner ( System . in) ;
if ( scanner. hasNextInt ( ) ) {
i = scanner. nextInt ( ) ;
} else {
System . out. println ( "请输入整数(需要是int范围的整数,不能大于等于2147483648,否则也会到这里)" ) ;
}
if ( i < 2 ) {
System . out. println ( "请输入大于等于2的数" ) ;
} else {
for ( int a = 2 ; a<= ( int ) Math . sqrt ( i) ; a++ ) {
if ( i% a== 0 ) {
System . out. println ( "不是质数" ) ;
j = 1 ;
break ;
}
}
if ( j == 0 ) {
System . out. println ( "是质数" ) ;
}
}
}
}
}
import java. util. Scanner ;
public class test2 {
public static void main ( String [ ] args) {
Scanner scanner = new Scanner ( System . in) ;
while ( true ) {
try {
Thread . sleep ( 4000 ) ;
} catch ( Exception e) {
e. printStackTrace ( ) ;
}
if ( scanner. hasNextInt ( ) ) {
int i = scanner. nextInt ( ) ;
} else {
String next = scanner. next ( ) ;
System . out. println ( next) ;
System . out. println ( "请输入整数(需要是int范围的整数,不能大于等于2147483648,否则也会到这里)" ) ;
}
}
}
}
int sum ( int n) {
int s= 0 ;
int i= 1 ;
for ( ; i<= n; i++ ) {
s= s+ i;
}
return s;
}
T ( n) = O ( f ( n) )
int sum ( int n) {
int s= 0 ;
int i= 1 ;
int j= 1 ;
for ( ; i<= n; i++ ) {
j= 1 ;
for ( ; j<= n; j++ ) {
s= s+ i+ j;
}
}
return s;
}
int sum ( int n) {
int s= 0 ;
int i= 1 ;
int j= 1 ;
for ( ; i<= n; i++ ) {
s= s+ i;
}
for ( ; i<= n; i++ ) {
j= 1 ;
for ( ; j<= m; j++ ) {
s= s+ i+ j;
}
}
return s;
}
i = 1 ;
while ( i <= n) {
i = i * 2 ;
}
int sum ( int m, int n) {
int s1= 0 ;
int s2= 0 ;
int i= 1 ;
int j= 1 ;
for ( ; i<= m; i++ ) {
s1= s1+ i;
}
for ( ; j<= n; j++ ) {
s2= s2+ j;
}
return s1+ s2;
}
int sum ( int m, int n) {
int s= 0 ;
int i= 1 ;
int j= 1 ;
for ( ; i<= m; i++ ) {
j= 1 ;
for ( ; j<= n; j++ ) {
s= s+ i+ j;
}
}
return s;
}
对应的时间复杂度是以我写的程序来进行说明的 ,当然,如果可以优化的话,自然是可以更加的减低时间复杂度,这里以对应的程序为主,所以你可能在其他博客或者百度里面可以发现,具体理论上的时间复杂度比我说明的时间复杂度可能要低,这是很正常的,因为这里的程序也可能并不是最优解,所以如果后面的说明中,出现了时间复杂度在理论上不符合,那么说明程序还可以继续优化,你可以自己进行操作优化
a[ i] _address= a[ 0 ] _address+ i* 4
int n= nums[ 2 ]
nums[ 3 ] = 10 ;
a[ 6 ] = 10
int [ ] numsNew= new int [ nums. length* 2 ] ;
System . arraycopy ( nums, 0 , numsNew, 0 , nums. length) ;
nums= numsNew;
for ( int i= p; i< nums. length; i++ ) {
nums[ i- 1 ] = nums[ i] ;
}
public class Array {
int array = 8 ;
int [ ] nums = new int [ array] ;
public Array ( ) {
nums[ 0 ] = 3 ;
nums[ 1 ] = 1 ;
nums[ 2 ] = 2 ;
nums[ 3 ] = 5 ;
nums[ 4 ] = 4 ;
nums[ 5 ] = 9 ;
}
public int get ( int i) {
if ( i < 0 || i >= array) {
System . out. println ( "下标越界了" ) ;
return - 1 ;
}
return nums[ i] ;
}
public void update ( int i, int n) {
if ( i < 0 || i >= array) {
System . out. println ( "下标越界了" ) ;
return ;
}
nums[ i] = n;
}
public void insert6 ( int n) {
nums[ 6 ] = n;
}
public void insert ( int p, int n) {
if ( p < 0 || p >= array) {
System . out. println ( "下标越界了" ) ;
return ;
}
for ( int i = nums. length - 2 ; i >= p; i-- ) {
nums[ i + 1 ] = nums[ i] ;
}
nums[ p] = n;
if ( nums[ nums. length - 1 ] != 0 ) {
resize ( ) ;
}
}
public void resize ( ) {
int [ ] numsNew = new int [ nums. length * 2 ] ;
System . arraycopy ( nums, 0 , numsNew, 0 , nums. length) ;
nums = numsNew;
}
public void delete ( int p) {
if ( p < 0 || p >= array) {
System . out. println ( "下标越界了" ) ;
return ;
}
for ( int i = p; i < nums. length - 1 ; i++ ) {
nums[ i] = nums[ i + 1 ] ;
}
nums[ nums. length - 1 ] = 0 ;
}
public void select ( ) {
String a = "[" ;
for ( int j = 0 ; j < nums. length; j++ ) {
if ( j == nums. length - 1 ) {
a = a + nums[ j] + "]" ;
} else {
a = a + nums[ j] + "," ;
}
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "[" ;
for ( int j = nums. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
a = a + nums[ j] + "]" ;
} else {
a = a + nums[ j] + "," ;
}
}
System . out. println ( a) ;
}
public static void main ( String [ ] args) {
Array d = new Array ( ) ;
d. insert ( 6 , 3 ) ;
d. insert ( 7 , 3 ) ;
d. insert ( 8 , 6 ) ;
d. select ( ) ;
d. reverseSelect ( ) ;
System . out. println ( d. get ( 1 ) ) ;
d. delete ( 6 ) ;
d. update ( 1 , 32 ) ;
d. select ( ) ;
d. reverseSelect ( ) ;
d. resize ( ) ;
d. select ( ) ;
d. insert6 ( 36 ) ;
d. select ( ) ;
}
}
Node {
int data;
Node next;
}
Node {
int data;
Node next;
Node prev;
}
他们实际上通常是不一样的内存空间大小的 ,只是为了方便观察,所以认为都是同样的空间,所以使用图片表示,以后说明这样时,都按照这样的思想来说明
public class test {
Node head;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void insert ( Node node) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id < node. id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
temp2. next = node;
return ;
}
}
if ( temp1. id > node. id) {
node. next = temp1;
if ( temp1 != head) {
temp2. next = node;
return ;
}
head = node;
return ;
}
if ( temp1. id == node. id) {
if ( temp1 == head) {
node. next = temp1. next;
head = node;
return ;
}
if ( temp1. next != null ) {
temp2. next = node;
node. next = temp1. next;
return ;
}
temp2. next = node;
return ;
}
}
}
head = node;
}
public void delete ( int id) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有删除的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
if ( temp1 != head) {
temp2. next = temp1. next;
return ;
}
head = head. next;
return ;
}
}
}
System . out. println ( "没有节点删除了" ) ;
}
public void update ( int id, String name) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有修改的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
temp1. name = name;
return ;
}
}
}
System . out. println ( "没有节点更新了" ) ;
}
public void selectByNode ( int id) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有查询的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
System . out. println ( "[" + temp1. id + "," + temp1. name + "]" ) ;
return ;
}
}
}
System . out. println ( "没有节点查询了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public static void main ( String [ ] args) {
test t = new test ( ) ;
t. insert ( t. new Node ( 26 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "24" ) ) ;
t. insert ( t. new Node ( - 1 , "2" ) ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. delete ( 2 ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. update ( 26 , "5" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectByNode ( 2 ) ;
t. selectByNode ( 26 ) ;
}
}
public class test1 {
Node head;
public class Node {
Node prev;
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void insert ( Node node) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id < node. id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
temp2. next = node;
node. prev = temp2;
return ;
}
}
if ( temp1. id > node. id) {
node. next = temp1;
temp1. prev = node;
if ( temp1 != head) {
temp2. next = node;
node. prev = temp2;
return ;
}
head = node;
return ;
}
if ( temp1. id == node. id) {
if ( temp1 == head) {
node. next = temp1. next;
temp1. next. prev = node;
head = node;
return ;
}
if ( temp1. next != null ) {
temp2. next = node;
node. next = temp1. next;
node. prev = temp2;
return ;
}
temp2. next = node;
node. prev = temp2;
return ;
}
}
}
head = node;
}
public void delete ( int id) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有删除的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
if ( temp1 != head) {
temp2. next = temp1. next;
temp1. next. prev = temp2;
return ;
}
head = head. next;
return ;
}
}
}
System . out. println ( "没有节点删除了" ) ;
}
public void update ( int id, String name) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有修改的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
temp1. name = name;
return ;
}
}
}
System . out. println ( "没有节点修改了" ) ;
}
public void selectByNode ( int id) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有查询的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
System . out. println ( "[" + temp1. id + "," + temp1. name + "]" ) ;
return ;
}
}
}
System . out. println ( "没有节点查询了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
Node temp1 = head;
Node temp2 = null ;
String a = "" ;
if ( temp1 != null ) {
while ( true ) {
temp1 = temp1. next;
if ( temp1 == null ) {
temp2 = head;
break ;
}
if ( temp1. next == null ) {
temp2 = temp1;
break ;
}
}
if ( temp2. prev == null ) {
a = a + "[" + temp2. id + "," + temp2. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp2. id + "," + temp2. name + "]," ;
while ( true ) {
temp2 = temp2. prev;
if ( temp2. prev == null ) {
a = a + "[" + temp2. id + "," + temp2. name + "]" ;
break ;
}
if ( temp2. prev != null ) {
a = a + "[" + temp2. id + "," + temp2. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public static void main ( String [ ] args) {
test1 t = new test1 ( ) ;
t. insert ( t. new Node ( 26 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "24" ) ) ;
t. insert ( t. new Node ( - 1 , "2" ) ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. delete ( 2 ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. update ( 26 , "5" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectByNode ( 2 ) ;
t. selectByNode ( 26 ) ;
}
}
public class test2 {
Node head;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public Node last ( ) {
Node temp1 = head;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == head) {
return temp1;
}
}
}
public void insert ( Node node) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id < node. id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == head) {
temp2. next = node;
node. next = head;
return ;
}
}
if ( temp1. id > node. id) {
node. next = temp1;
if ( temp1 != head) {
temp2. next = node;
return ;
}
Node next = last ( ) ;
head = node;
next. next = head;
return ;
}
if ( temp1. id == node. id) {
if ( temp1 == head) {
node. next = temp1. next;
Node next = last ( ) ;
head = node;
next. next = head;
return ;
}
if ( temp1. next != head) {
temp2. next = node;
node. next = temp1. next;
return ;
}
temp2. next = node;
node. next = head;
return ;
}
}
}
if ( temp1 == null ) {
head = node;
node. next = head;
}
}
public void delete ( int id) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == head) {
System . out. println ( "没有删除的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
if ( temp1 != head) {
if ( temp1. next == head) {
temp2. next = head;
return ;
}
temp2. next = temp1. next;
return ;
}
if ( temp1 == head) {
head = null ;
return ;
}
}
}
}
if ( temp1 == null ) {
System . out. println ( "没有删除的节点了" ) ;
}
}
public void update ( int id, String name) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == head) {
System . out. println ( "没有修改的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
temp1. name = name;
return ;
}
}
}
if ( temp1 != null ) {
System . out. println ( "没有修改的节点了" ) ;
}
}
public void selectByNode ( int id) {
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. id != id) {
temp1 = temp1. next;
if ( temp1 == head) {
System . out. println ( "没有查询的节点" ) ;
return ;
}
}
if ( temp1. id == id) {
System . out. println ( "[" + temp1. id + "," + temp1. name + "]" ) ;
return ;
}
}
}
if ( temp1 == null ) {
System . out. println ( "没有查询的节点了" ) ;
}
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == head) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == head) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != head) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == head) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == head) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != head) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public static void main ( String [ ] args) {
test2 t = new test2 ( ) ;
t. insert ( t. new Node ( 26 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "2" ) ) ;
t. insert ( t. new Node ( 2 , "24" ) ) ;
t. insert ( t. new Node ( - 1 , "2" ) ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. delete ( 2 ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. update ( 26 , "5" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectByNode ( 2 ) ;
t. selectByNode ( 26 ) ;
if ( t. head != null ) {
System . out. println ( "最后一个节点的next的id是:" + t. last ( ) . next. id) ;
System . out. println ( "最后一个节点的next的name是:" + t. last ( ) . next. name) ;
} else {
System . out. println ( "没有节点了" ) ;
}
}
}
public class test3 {
int [ ] array;
int count;
int max = 5 ;
public test3 ( int n) {
array = new int [ n] ;
count = 0 ;
}
public void push ( int i) {
if ( count + 1 <= max) {
array[ count] = i;
count++ ;
if ( count >= array. length) {
resize ( ) ;
}
return ;
}
System . out. println ( "已经到最大个数了,不能再入栈了" ) ;
}
public void resize ( ) {
int [ ] numsNew = new int [ array. length * 2 ] ;
System . arraycopy ( array, 0 , numsNew, 0 , array. length) ;
array = numsNew;
}
public void pop ( ) {
if ( count == 0 ) {
System . out. println ( "没有数据出栈了" ) ;
return ;
}
array[ -- count] = 0 ;
}
public void select ( ) {
String a = "[" ;
for ( int j = 0 ; j < array. length; j++ ) {
if ( j == array. length - 1 ) {
a = a + array[ j] + "]" ;
} else {
a = a + array[ j] + "," ;
}
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "[" ;
for ( int j = array. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
a = a + array[ j] + "]" ;
} else {
a = a + array[ j] + "," ;
}
}
System . out. println ( a) ;
}
public void selectLast ( ) {
if ( count != 0 ) {
System . out. println ( "最后一个入栈的数是:" + array[ count - 1 ] ) ;
return ;
}
System . out. println ( "没有数据了" ) ;
}
public static void main ( String [ ] args) {
test3 t = new test3 ( 2 ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. push ( 2 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
System . out. println ( "栈总数:" + t. count) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectLast ( ) ;
t. pop ( ) ;
t. pop ( ) ;
System . out. println ( 1 ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
}
}
public class test4 {
Node head;
int count;
int max = 5 ;
Node last;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void push ( Node node) {
if ( count + 1 <= max) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
temp2. next = node;
last = node;
count++ ;
return ;
}
}
}
head = node;
last = node;
count++ ;
return ;
}
System . out. println ( "已经到最大个数了,不能再入栈了" ) ;
}
public void pop ( ) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
if ( temp1. next == null ) {
head = null ;
last = null ;
count-- ;
return ;
}
if ( temp1. next != null ) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1. next == null ) {
temp2. next = null ;
last = temp2;
count-- ;
return ;
}
}
}
}
System . out. println ( "没有节点出栈了" ) ;
}
public void selectLast ( ) {
Node temp2 = head;
Node temp1 = head;
if ( temp1 != null ) {
while ( true ) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "最后一个入栈的节点信息是:[" + temp2. id + "," + temp2. name + "]" ) ;
return ;
}
}
}
System . out. println ( "没有入栈的节点信息了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public void last ( ) {
if ( last != null ) {
System . out. println ( "最后一个入栈的节点信息是:[" + last. id + "," + last. name + "]" ) ;
return ;
}
System . out. println ( "没有节点信息了" ) ;
}
public static void main ( String [ ] args) {
test4 t = new test4 ( ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 2 , "2" ) ) ;
t. push ( t. new Node ( 4 , "2" ) ) ;
t. push ( t. new Node ( 4 , "2" ) ) ;
t. push ( t. new Node ( 4 , "2" ) ) ;
t. push ( t. new Node ( 4 , "2" ) ) ;
System . out. println ( "栈总数:" + t. count) ;
t. select ( ) ;
t. selectLast ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. pop ( ) ;
System . out. println ( "栈总数:" + t. count) ;
t. select ( ) ;
t. selectLast ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. selectLast ( ) ;
t. reverseSelect ( ) ;
System . out. println ( 66 ) ;
t. last ( ) ;
}
}
public class test44 {
Node head;
int count;
int max = 5 ;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void push ( Node node) {
if ( count + 1 <= max) {
node. next = head;
head = node;
count++ ;
return ;
}
System . out. println ( "已经到最大个数了,不能再入栈了" ) ;
}
public void pop ( ) {
if ( head != null ) {
if ( head. next == null ) {
head = null ;
count-- ;
return ;
}
head = head. next;
count-- ;
return ;
}
System . out. println ( "没有节点出栈了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public static void main ( String [ ] args) {
test44 t = new test44 ( ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 2 , "2" ) ) ;
t. push ( t. new Node ( 2 , "2" ) ) ;
t. push ( t. new Node ( 2 , "2" ) ) ;
t. push ( t. new Node ( 25 , "2" ) ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
if ( t. head != null ) {
System . out. println ( "最后一个入栈的节点信息是:[" + t. head. id + "," + t. head. name + "]" ) ;
} else {
System . out. println ( "没有节点信息了" ) ;
}
}
}
public class test5 {
int [ ] nums;
int head;
int last;
int max = 5 ;
public test5 ( int n) {
nums = new int [ n] ;
head = 0 ;
last = 0 ;
}
public void push ( int a) {
if ( last - head + 1 <= max) {
nums[ last] = a;
last++ ;
if ( last >= nums. length) {
resize ( ) ;
}
return ;
}
System . out. println ( "已经到最大个数了,不能再入列了" ) ;
}
public void pop ( ) {
if ( head != last) {
nums[ head] = 0 ;
head++ ;
return ;
}
System . out. println ( "没有数据出列了" ) ;
}
public void resize ( ) {
int [ ] numsNew = new int [ nums. length * 2 ] ;
System . arraycopy ( nums, 0 , numsNew, 0 , nums. length) ;
nums = numsNew;
}
public void reset ( ) {
int [ ] array = new int [ nums. length] ;
int j = 0 ;
for ( int i = head; i < last; i++ , j++ ) {
array[ j] = nums[ i] ;
}
nums = array;
head = 0 ;
last = j;
}
public void select ( ) {
String a = "[" ;
for ( int j = 0 ; j < nums. length; j++ ) {
if ( j == nums. length - 1 ) {
a = a + nums[ j] + "]" ;
} else {
a = a + nums[ j] + "," ;
}
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "[" ;
for ( int j = nums. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
a = a + nums[ j] + "]" ;
} else {
a = a + nums[ j] + "," ;
}
}
System . out. println ( a) ;
}
public void selectHeadLast ( ) {
if ( head != last) {
System . out. println ( "准备出列的数是:" + nums[ head] ) ;
System . out. println ( "最后一个入列的数是:" + + nums[ last - 1 ] ) ;
return ;
}
System . out. println ( "没有出列的数据了" ) ;
}
public static void main ( String [ ] args) {
test5 t = new test5 ( 2 ) ;
t. push ( 2 ) ;
t. push ( 2 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. push ( 3 ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. reset ( ) ;
t. select ( ) ;
System . out. println ( t. head) ;
System . out. println ( t. last) ;
t. reverseSelect ( ) ;
t. selectHeadLast ( ) ;
}
}
public class test6 {
Node head;
int countHead;
int countLast;
int max = 5 ;
Node last;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void push ( Node node) {
if ( countLast - countHead + 1 <= max) {
Node temp1 = head;
Node temp2 = head;
if ( temp1 != null ) {
while ( true ) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
temp2. next = node;
countLast++ ;
last = node;
return ;
}
}
}
head = node;
last = node;
countLast++ ;
return ;
}
System . out. println ( "已经到最大个数了,不能再入列了" ) ;
}
public void pop ( ) {
if ( head != null ) {
head = head. next;
countHead++ ;
return ;
}
System . out. println ( "没有数据出列了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public void selectHeadLast ( ) {
if ( head != null ) {
System . out. println ( "准备出列的节点信息是:[" + head. id + "," + head. name + "]" ) ;
System . out. println ( "最后一个入列的节点信息是:[" + last. id + "," + last. name + "]" ) ;
return ;
}
System . out. println ( "没有节点信息了" ) ;
}
public static void main ( String [ ] args) {
test6 t = new test6 ( ) ;
t. push ( t. new Node ( 14 , "2" ) ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 12 , "2" ) ) ;
t. push ( t. new Node ( 121 , "2" ) ) ;
t. push ( t. new Node ( 121 , "2" ) ) ;
t. push ( t. new Node ( 121 , "2" ) ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectHeadLast ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. selectHeadLast ( ) ;
}
}
public class test66 {
Node head;
Node last;
int count;
int max = 5 ;
public class Node {
int id;
String name;
Node next;
public Node ( int id, String name) {
this . id = id;
this . name = name;
}
}
public void push ( Node node) {
if ( count + 1 <= max) {
if ( head == null ) {
head = node;
last = node;
count++ ;
return ;
}
last. next = node;
last = node;
count++ ;
return ;
}
System . out. println ( "已经到最大个数了,不能再入列了" ) ;
}
public void pop ( ) {
if ( count != 0 ) {
head = head. next;
count-- ;
return ;
}
System . out. println ( "没有节点出列了" ) ;
}
public void select ( ) {
String a = "" ;
Node temp1 = head;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]" ;
break ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. id + "," + temp1. name + "]," ;
}
}
}
if ( temp1 == null ) {
a = "[]" ;
}
System . out. println ( a) ;
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Node temp1 = head;
String cc = "" ;
if ( temp1 != null ) {
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. id;
b = b + temp1. name;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. id + "," ;
b = b + temp1. name + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
}
if ( temp1 == null ) {
cc = "[]" ;
}
System . out. println ( cc) ;
}
public static void main ( String [ ] args) {
test66 t = new test66 ( ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 2 , "2" ) ) ;
t. push ( t. new Node ( 1 , "2" ) ) ;
t. push ( t. new Node ( 12 , "2" ) ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
if ( t. head != null ) {
System . out. println ( "准备出列的节点信息是:[" + t. head. id + "," + t. head. name + "]" ) ;
System . out. println ( "最后一个入列的节点信息是:[" + t. last. id + "," + t. last. name + "]" ) ;
} else {
System . out. println ( "没有节点信息了" ) ;
}
t. select ( ) ;
t. reverseSelect ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. pop ( ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
}
}
以后默认是重写哈希函数的哈希值 ),即到那个时候,可能不同的引用确出现了相同的下标(当然如果针对数组,那么下标越小越容易相同,因为他操作计算了,且是容易相同的取模%,但是仅仅只是针对自带的重写的哈希方法产生的哈希值来说,通常需要数据量大的情况下,才会出现相同结果,因为既然是重写的,自然会考虑很多情况,一般自带的很难出现相同结果,而我们手动写的可能容易出现,除非你考虑的更多,那么也是很难出现的,而对于没有重写的,不同引用地址的结果,基本不会出现相同的)
index = HashCode ( Key ) % Array . length
int index= Math . abs ( "Hello" . hashCode ( ) ) % 10 ;
Entry {
int key;
Object value;
Entry next;
}
package com ;
import java. util. List ;
public class testCom1 {
ListEntry [ ] entry = new ListEntry [ 8 ] ;
int size;
double top = 0.75 ;
public class Entry {
String key;
String value;
Entry next;
public Entry ( String key, String value) {
this . key = key;
this . value = value;
}
}
public class ListEntry {
Entry head;
public void addEntry ( Entry entry) {
Entry temp1 = head;
while ( true ) {
if ( temp1. key. equals ( entry. key) ) {
temp1. value = entry. value;
return ;
}
if ( temp1. next == null ) {
temp1. next = entry;
return ;
}
temp1 = temp1. next;
}
}
public void deleteEntry ( String key) {
Entry temp1 = head;
Entry temp2 = head;
while ( true ) {
temp2 = temp1;
temp1 = temp1. next;
if ( temp1 == null ) {
System . out. println ( "没有该节点" ) ;
return ;
}
if ( temp1. key. equals ( key) ) {
temp2. next = temp1. next;
return ;
}
}
}
public void updateEntry ( String key, String value) {
Entry temp1 = head;
while ( true ) {
if ( temp1 == null ) {
System . out. println ( "没有该节点" ) ;
return ;
}
if ( temp1. key. equals ( key) ) {
temp1. value = value;
return ;
}
temp1 = temp1. next;
}
}
public String getEntry ( String key) {
Entry temp1 = head;
while ( true ) {
if ( temp1 == null ) {
System . out. println ( "没有该节点" ) ;
return null ;
}
if ( temp1. key. equals ( key) ) {
if ( temp1. value == null ) {
System . out. println ( "他的值是null哦" ) ;
}
return temp1. value;
}
temp1 = temp1. next;
}
}
public void select ( ) {
String a = "" ;
Entry temp1 = head;
if ( temp1. next == null ) {
a = a + "[" + temp1. key + "," + temp1. value + "]" ;
System . out. println ( a) ;
return ;
}
a = a + "[" + temp1. key + "," + temp1. value + "]," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + "[" + temp1. key + "," + temp1. value + "]" ;
System . out. println ( a) ;
return ;
}
if ( temp1. next != null ) {
a = a + "[" + temp1. key + "," + temp1. value + "]," ;
}
}
}
public void reverseSelect ( ) {
String a = "" ;
String b = "" ;
Entry temp1 = head;
String cc = "" ;
if ( temp1. next == null ) {
a = a + temp1. key;
b = b + temp1. value;
System . out. println ( "[" + a + "," + b + "]" ) ;
return ;
}
a = a + temp1. key + "," ;
b = b + temp1. value + "," ;
while ( true ) {
temp1 = temp1. next;
if ( temp1. next == null ) {
a = a + temp1. key;
b = b + temp1. value;
break ;
}
if ( temp1. next != null ) {
a = a + temp1. key + "," ;
b = b + temp1. value + "," ;
}
}
String [ ] aa = a. split ( "," ) ;
String [ ] bb = b. split ( "," ) ;
for ( int j = aa. length - 1 ; j >= 0 ; j-- ) {
if ( j == 0 ) {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]" ;
} else {
cc = cc + "[" + aa[ j] + "," + bb[ j] + "]," ;
}
}
System . out. println ( cc) ;
}
}
public void resize ( ) {
ListEntry [ ] numsNew = new ListEntry [ entry. length * 2 ] ;
size = 0 ;
for ( int i = 0 ; i < entry. length; i++ ) {
if ( entry[ i] != null ) {
Entry temp1 = entry[ i] . head;
while ( true ) {
if ( temp1 != null ) {
int index = temp1. key. hashCode ( ) & ( numsNew. length - 1 ) ;
if ( numsNew[ index] == null ) {
ListEntry list = new ListEntry ( ) ;
list. head = new Entry ( temp1. key, temp1. value) ;
numsNew[ index] = list;
size++ ;
} else {
numsNew[ index] . addEntry ( new Entry ( temp1. key, temp1. value) ) ;
}
temp1 = temp1. next;
} else {
break ;
}
}
}
}
entry = numsNew;
}
public void put ( String key, String value) {
int index = Math . abs ( key. hashCode ( ) % entry. length) ;
if ( entry[ index] == null ) {
ListEntry entry1 = new ListEntry ( ) ;
entry[ index] = entry1;
entry[ index] . head = new Entry ( key, value) ;
size++ ;
if ( size >= entry. length * top) {
resize ( ) ;
}
return ;
}
entry[ index] . addEntry ( new Entry ( key, value) ) ;
}
public String get ( String key) {
int index = Math . abs ( key. hashCode ( ) % entry. length) ;
if ( entry[ index] == null ) {
System . out. println ( "没有该key指定的value数据" ) ;
return null ;
}
String value = this . entry[ index] . getEntry ( key) ;
return value;
}
public void update ( String key, String value) {
int index = Math . abs ( key. hashCode ( ) % entry. length) ;
if ( entry[ index] == null ) {
System . out. println ( "没有该key指定的value数据" ) ;
return ;
}
this . entry[ index] . updateEntry ( key, value) ;
}
public void delete ( String key) {
int index = Math . abs ( key. hashCode ( ) % entry. length) ;
if ( entry[ index] == null ) {
System . out. println ( "没有该key指定的value数据" ) ;
return ;
}
if ( entry[ index] . head. key. equals ( key) ) {
if ( entry[ index] . head. next == null ) {
entry[ index] = null ;
} else {
entry[ index] . head = entry[ index] . head. next;
}
return ;
}
this . entry[ index] . deleteEntry ( key) ;
}
public void select ( ) {
System . out. println ( "正向查询所有:" ) ;
System . out. println ( "链表数组长度是:" + entry. length) ;
for ( int i = 0 ; i < entry. length; i++ ) {
System . out. print ( "第" + i + "个链表:" ) ;
if ( entry[ i] == null ) {
System . out. println ( "[]" ) ;
} else {
entry[ i] . select ( ) ;
}
}
}
public void reverseSelect ( ) {
System . out. println ( "反向查询所有:" ) ;
System . out. println ( "链表数组长度是:" + entry. length) ;
for ( int i = 0 ; i < entry. length; i++ ) {
System . out. print ( "第" + i + "个链表:" ) ;
if ( entry[ i] == null ) {
System . out. println ( "[]" ) ;
} else {
entry[ i] . reverseSelect ( ) ;
}
}
}
public static void main ( String [ ] args) {
testCom1 t = new testCom1 ( ) ;
t. put ( "1" , "2" ) ;
t. put ( "2" , "3" ) ;
t. put ( "2" , "34" ) ;
t. put ( "2" , "343" ) ;
t. put ( "22" , "3" ) ;
t. put ( "223" , "3" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. put ( "3" , "3" ) ;
t. put ( "4" , "3" ) ;
t. put ( "5" , "3" ) ;
t. put ( "6" , "3" ) ;
t. put ( "7" , "3" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. delete ( "2" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
t. update ( "22" , "334" ) ;
t. select ( ) ;
t. reverseSelect ( ) ;
String s = t. get ( "1" ) ;
System . out. println ( s) ;
}
}
package com ;
public class recursion {
public void round ( ) {
for ( int t = 0 ; t < 5 ; t++ ) {
System . out. println ( "Hello World" ) ;
}
}
public void recursion ( int n) {
if ( n <= 0 ) {
return ;
}
System . out. println ( "Hello World" ) ;
recursion ( -- n) ;
}
public static void main ( String [ ] args) {
recursion r = new recursion ( ) ;
r. round ( ) ;
System . out. println ( "-----" ) ;
r. recursion ( 5 ) ;
}
}
package com ;
public class test {
public int fa ( int n) {
if ( n <= 1 ) return n;
return fa ( n - 1 ) + fa ( n - 2 ) ;
}
public static void main ( String [ ] args) {
test t = new test ( ) ;
int fa = t. fa ( 6 ) ;
System . out. println ( fa) ;
}
}
package com ;
public class test1 {
public Double fa ( int n) {
return ( 1 / Math . sqrt ( 5 ) ) * ( Math . pow ( ( ( 1 + Math . sqrt ( 5 ) ) / 2 ) , n) - Math . pow ( ( ( 1 - Math . sqrt ( 5 ) ) / 2 ) , n) ) ;
}
public static void main ( String [ ] args) {
test1 t = new test1 ( ) ;
System . out. println ( t. fa ( 6 ) ) ;
System . out. println ( Math . round ( t. fa ( 6 ) ) ) ;
}
}
11 / 2 = 5
5 / 2 = 2
2 / 2 = 1
1 / 2 = 0
1 * 2 ^ 0 + 1 * 2 ^ 1 + 0 * 2 ^ 2 + 1 * 2 ^ 3 = 1 + 2 + 8 = 11
2 ^ 0 + 2 ^ 1 + 2 ^ 3 = 1 + 2 + 8 = 11
A = 2 ^ 0 + 2 ^ 1 + 2 ^ 2 + 2 ^ 3 + 2 ^ 4
5 = 101
5 = 2 ^ 1 + 2 ^ 2
5 / 10 = 2 ^ 1 / 10 + 2 ^ 2 / 10 = 0.1 + 0.4 = 0.5 = 2 ^ - 1
0.5 / 2 = 0.2
0.2 / 2 = 0.1
0.1 / 2 = 0.05
. . . . . .
0.75 * 2 = 1.5
0.5 * 2 = 1.0
package com ;
public class tt {
public static int fa ( int i) {
if ( i <= 1 ) return i;
int a = 0 ;
int b = 1 ;
for ( int j = 2 ; j <= i; j++ ) {
b = b + a;
a = b - a;
}
return b;
}
public static void main ( String [ ] args) {
System . out. println ( fa ( 6 ) ) ;
}
}
package com ;
public class test3 {
public static int fa ( int [ ] i, int j) {
int head = 0 ;
int last = i. length - 1 ;
int h = ( head + last) / 2 ;
while ( true ) {
if ( i[ h] == j) {
return h;
}
if ( head >= last) {
return - 1 ;
}
if ( i[ h] > j) {
last = h - 1 ;
h = ( head + last) / 2 ;
} else if ( i[ h] < j) {
head = h + 1 ;
h = ( head + last) / 2 ;
}
}
}
public static void main ( String [ ] args) {
int [ ] nums = { 3 , 12 , 24 , 31 , 46 , 48 , 52 , 66 , 69 , 79 , 82 } ;
System . out. println ( fa ( nums, 66 ) ) ;
}
}
package com ;
public class test4 {
public static int fb ( int [ ] array, int i, int n, int var ) {
int h = ( i + n) / 2 ;
if ( array[ h] == var ) {
return h;
}
if ( i >= n) {
return - 1 ;
}
if ( array[ h] > var ) {
return fb ( array, i, h - 1 , var ) ;
} else {
return fb ( array, h + 1 , n, var ) ;
}
}
public static void main ( String [ ] args) {
int [ ] nums = { 3 , 12 , 24 , 31 , 46 , 48 , 52 , 66 , 69 , 79 , 82 } ;
System . out. println ( fb ( nums, 0 , nums. length - 1 , 66 ) ) ;
}
}
package com ;
public class test5 {
public static int fc ( int [ ] array) {
int head = 0 ;
int last = array. length - 1 ;
int h = ( head + last) / 2 ;
while ( true ) {
if ( h % 2 == 0 ) {
if ( h == 0 || h == array. length - 1 ) {
return h;
}
if ( array[ h] == array[ h + 1 ] ) {
head = h + 2 ;
h = ( head + last) / 2 ;
} else if ( array[ h] == array[ h - 1 ] ) {
last = h - 2 ;
h = ( head + last) / 2 ;
} else {
return h;
}
} else {
if ( array[ h] == array[ h - 1 ] ) {
head = h + 1 ;
h = ( head + last) / 2 ;
} else if ( array[ h] == array[ h + 1 ] ) {
last = h - 1 ;
h = ( head + last) / 2 ;
} else {
return h;
}
}
if ( head > last) {
return - 1 ;
}
}
}
public static void main ( String [ ] args) {
int [ ] array = { 1 , 2 , 2 , 3 , 3 , 4 , 4 , 7 , 7 , 6 , 6 } ;
System . out. println ( fc ( array) ) ;
}
}
这里以二叉查找树为主 ) :
即每个节点都要满足 (这句话是关键),所以才会出现上面说的"如果该节点是父"package com ;
import f. Tree1 ;
public class Tree {
TreeNode root;
int max;
String array = "" ;
public class TreeNode {
int data;
TreeNode left;
TreeNode right;
public TreeNode ( int data) {
this . data = data;
}
}
public TreeNode insert ( TreeNode treeNode, int data) {
if ( treeNode == null ) {
treeNode = new TreeNode ( data) ;
max++ ;
return treeNode;
}
if ( data < treeNode. data) {
treeNode. left = insert ( treeNode. left, data) ;
}
else if ( data > treeNode. data) {
treeNode. right = insert ( treeNode. right, data) ;
} else {
treeNode. data = data;
}
return treeNode;
}
public void preSelect ( TreeNode treeNode) {
if ( treeNode == null ) {
return ;
}
array = array + treeNode. data + "," ;
preSelect ( treeNode. left) ;
preSelect ( treeNode. right) ;
}
public void inSelect ( TreeNode treeNode) {
if ( treeNode == null ) {
return ;
}
inSelect ( treeNode. left) ;
array = array + treeNode. data + "," ;
inSelect ( treeNode. right) ;
}
public void latSelect ( TreeNode treeNode) {
if ( treeNode == null ) {
return ;
}
latSelect ( treeNode. left) ;
latSelect ( treeNode. right) ;
array = array + treeNode. data + "," ;
}
public void Select ( ) {
if ( array != "" ) {
String a = "" ;
String [ ] split = array. split ( "," ) ;
System . out. print ( "[" ) ;
for ( int i = 0 ; i < split. length; i++ ) {
if ( i == split. length - 1 ) {
a = a + split[ i] + "]" ;
} else {
a = a + split[ i] + "," ;
}
}
System . out. println ( a) ;
} else {
System . out. println ( "[]" ) ;
}
array = "" ;
}
public TreeNode getNode ( int data) {
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
if ( treeNode. data > data) {
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
return treeNode;
}
}
}
public void delete ( int data) {
TreeNode treeNode = root;
TreeNode temp1 = null ;
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp1 = treeNode;
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
temp1 = treeNode;
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
if ( temp1. left == treeNode) {
temp1. left = null ;
return ;
}
if ( temp1. right == treeNode) {
temp1. right = null ;
return ;
}
}
}
}
public void update ( int data, int da) {
TreeNode treeNode = root;
TreeNode temp1 = root;
TreeNode temp2 = root;
TreeNode aa = null ;
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. left;
if ( temp2. right == temp1 && temp1. left == treeNode) {
aa = temp2;
}
} else if ( treeNode. data < data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. right;
if ( temp2. left == temp1 && temp1. right == treeNode) {
aa = temp2;
}
} else if ( treeNode. data == data) {
TreeNode temp3 = treeNode. left;
TreeNode temp4 = treeNode. right;
int max;
int min;
if ( temp3 != null ) {
while ( true ) {
if ( temp3. right == null ) {
min = temp3. data;
break ;
}
temp3 = temp3. right;
}
} else {
min = treeNode. data;
}
if ( temp4 != null ) {
while ( true ) {
if ( temp4. left == null ) {
max = temp4. data;
break ;
}
temp4 = temp4. left;
}
} else {
max = treeNode. data;
}
if ( min == treeNode. data && max == treeNode. data) {
if ( treeNode == root) {
treeNode. data = da;
return ;
}
} else if ( min == treeNode. data) {
if ( da >= max) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
} else if ( max == treeNode. data) {
if ( da <= min) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
}
if ( temp1. left == treeNode) {
if ( aa == null ) {
if ( da >= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da >= temp1. data || da <= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
if ( temp1. right == treeNode) {
if ( aa == null ) {
if ( da <= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da <= temp1. data || da >= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
}
}
}
public static void main ( String [ ] args) {
Tree tree = new Tree ( ) ;
tree. root = tree. insert ( tree. root, 10 ) ;
tree. root = tree. insert ( tree. root, 8 ) ;
tree. root = tree. insert ( tree. root, 11 ) ;
tree. root = tree. insert ( tree. root, 7 ) ;
tree. root = tree. insert ( tree. root, 9 ) ;
tree. root = tree. insert ( tree. root, 12 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "总个数是:" + tree. max) ;
TreeNode node = tree. getNode ( 7 ) ;
if ( node != null ) {
System . out. println ( "数值为:" + node. data) ;
} else {
System . out. println ( "没有节点,也就没有数值" ) ;
}
tree. delete ( 7 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( tree. root) ;
tree. Select( ) ;
tree. update ( 8 , 9 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( tree. root) ;
tree. Select( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( tree. root) ;
tree. Select( ) ;
}
}
package f ;
import com. Tree ;
import java. util. ArrayList ;
import java. util. List ;
import java. util. Stack ;
public class Tree1 {
TreeNode root;
int max;
public class TreeNode {
int data;
TreeNode left;
TreeNode right;
public TreeNode ( int data) {
this . data = data;
}
}
public void insert ( int data) {
if ( root == null ) {
root = new TreeNode ( data) ;
max++ ;
return ;
}
TreeNode temp1 = root;
while ( true ) {
if ( data < temp1. data) {
if ( temp1. left == null ) {
temp1. left = new TreeNode ( data) ;
max++ ;
return ;
} else {
temp1 = temp1. left;
}
}
if ( data > temp1. data) {
if ( temp1. right == null ) {
temp1. right = new TreeNode ( data) ;
max++ ;
return ;
} else {
temp1 = temp1. right;
}
}
}
}
public void preSelect ( ) {
int [ ] in = new int [ max] ;
int i = 0 ;
TreeNode [ ] a = new TreeNode [ max] ;
int aa = 0 ;
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "[]" ) ;
return ;
}
while ( true ) {
if ( treeNode == null && aa == 0 ) {
break ;
}
while ( true ) {
if ( treeNode == null ) {
break ;
}
in[ i] = treeNode. data;
i++ ;
a[ aa] = treeNode;
aa++ ;
treeNode = treeNode. left;
}
treeNode = a[ -- aa] . right;
a[ aa] = null ;
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < in. length; ii++ ) {
if ( ii == in. length - 1 ) {
b = b + in[ ii] + "]" ;
} else {
b = b + in[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public void inSelect ( ) {
int [ ] in = new int [ max] ;
int i = 0 ;
TreeNode [ ] a = new TreeNode [ max] ;
int aa = 0 ;
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "[]" ) ;
return ;
}
while ( true ) {
if ( treeNode == null && aa == 0 ) {
break ;
}
while ( true ) {
if ( treeNode == null ) {
break ;
}
a[ aa] = treeNode;
aa++ ;
treeNode = treeNode. left;
}
treeNode = a[ -- aa] ;
in[ i] = treeNode. data;
i++ ;
treeNode = a[ aa] . right;
a[ aa] = null ;
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < in. length; ii++ ) {
if ( ii == in. length - 1 ) {
b = b + in[ ii] + "]" ;
} else {
b = b + in[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public void latSelect ( ) {
int [ ] in = new int [ max] ;
int i = 0 ;
TreeNode [ ] a = new TreeNode [ max] ;
int aa = 0 ;
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "[]" ) ;
return ;
}
TreeNode pre = null ;
int p = 0 ;
while ( true ) {
if ( treeNode == null && aa == 0 ) {
break ;
}
if ( aa == 0 && p == 1 ) {
break ;
}
while ( true ) {
if ( treeNode == null ) {
break ;
}
if ( p == 1 ) {
break ;
}
a[ aa] = treeNode;
aa++ ;
treeNode = treeNode. left;
}
treeNode = a[ aa - 1 ] . right;
if ( treeNode == null || pre == treeNode) {
pre = a[ aa - 1 ] ;
p = 1 ;
in[ i] = a[ aa - 1 ] . data;
i++ ;
aa-- ;
a[ aa] = null ;
} else {
p = 0 ;
}
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < in. length; ii++ ) {
if ( ii == in. length - 1 ) {
b = b + in[ ii] + "]" ;
} else {
b = b + in[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public TreeNode getNode ( int data) {
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
if ( treeNode. data > data) {
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
return treeNode;
}
}
}
public void delete ( int data) {
TreeNode treeNode = root;
TreeNode temp1 = null ;
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp1 = treeNode;
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
temp1 = treeNode;
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
if ( temp1. left == treeNode) {
temp1. left = null ;
return ;
}
if ( temp1. right == treeNode) {
temp1. right = null ;
return ;
}
}
}
}
public void update ( int data, int da) {
TreeNode treeNode = root;
TreeNode temp1 = root;
TreeNode temp2 = root;
TreeNode aa = null ;
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. left;
if ( temp2. right == temp1 && temp1. left == treeNode) {
aa = temp2;
}
} else if ( treeNode. data < data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. right;
if ( temp2. left == temp1 && temp1. right == treeNode) {
aa = temp2;
}
} else if ( treeNode. data == data) {
TreeNode temp3 = treeNode. left;
TreeNode temp4 = treeNode. right;
int max;
int min;
if ( temp3 != null ) {
while ( true ) {
if ( temp3. right == null ) {
min = temp3. data;
break ;
}
temp3 = temp3. right;
}
} else {
min = treeNode. data;
}
if ( temp4 != null ) {
while ( true ) {
if ( temp4. left == null ) {
max = temp4. data;
break ;
}
temp4 = temp4. left;
}
} else {
max = treeNode. data;
}
if ( min == treeNode. data && max == treeNode. data) {
if ( treeNode == root) {
treeNode. data = da;
return ;
}
} else if ( min == treeNode. data) {
if ( da >= max) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
} else if ( max == treeNode. data) {
if ( da <= min) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
}
if ( temp1. left == treeNode) {
if ( aa == null ) {
if ( da >= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da >= temp1. data || da <= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
if ( temp1. right == treeNode) {
if ( aa == null ) {
if ( da <= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da <= temp1. data || da >= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
}
}
}
public static void main ( String [ ] args) {
Tree1 tree = new Tree1 ( ) ;
tree. insert ( 10 ) ;
tree. insert ( 8 ) ;
tree. insert ( 11 ) ;
tree. insert ( 7 ) ;
tree. insert ( 9 ) ;
tree. insert ( 12 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
System . out. println ( "总个数是:" + tree. max) ;
TreeNode node = tree. getNode ( 7 ) ;
if ( node != null ) {
System . out. println ( "数值为:" + node. data) ;
} else {
System . out. println ( "没有节点,也就没有数值" ) ;
}
tree. delete ( 7 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
tree. update ( 8 , 9 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
}
}
package f ;
import com. Tree ;
import java. util. ArrayList ;
import java. util. List ;
import java. util. Stack ;
public class Tree2 {
TreeNode root;
int max;
public class TreeNode {
int data;
TreeNode left;
TreeNode right;
public TreeNode ( int data) {
this . data = data;
}
}
public void insert ( int data) {
if ( root == null ) {
root = new TreeNode ( data) ;
max++ ;
return ;
}
TreeNode temp1 = root;
while ( true ) {
if ( data < temp1. data) {
if ( temp1. left == null ) {
temp1. left = new TreeNode ( data) ;
max++ ;
return ;
} else {
temp1 = temp1. left;
}
}
if ( data > temp1. data) {
if ( temp1. right == null ) {
temp1. right = new TreeNode ( data) ;
max++ ;
return ;
} else {
temp1 = temp1. right;
}
}
}
}
public void preSelect ( ) {
int [ ] result = new int [ max] ;
int a = 0 ;
Stack < TreeNode > = new Stack < > ( ) ;
TreeNode cur = root;
if ( cur == null ) {
System . out. println ( "[]" ) ;
return ;
}
while ( null != cur || ! stack. isEmpty ( ) ) {
while ( null != cur) {
result[ a] = cur. data;
a++ ;
stack. push ( cur) ;
cur = cur. left;
}
cur = stack. pop ( ) . right;
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < result. length; ii++ ) {
if ( ii == result. length - 1 ) {
b = b + result[ ii] + "]" ;
} else {
b = b + result[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public void inSelect ( ) {
int [ ] result = new int [ max] ;
int a = 0 ;
Stack < TreeNode > = new Stack < > ( ) ;
TreeNode cur = root;
if ( cur == null ) {
System . out. println ( "[]" ) ;
return ;
}
while ( null != cur || ! stack. isEmpty ( ) ) {
while ( null != cur) {
stack. push ( cur) ;
cur = cur. left;
}
cur = stack. pop ( ) ;
result[ a] = cur. data;
a++ ;
cur = cur. right;
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < result. length; ii++ ) {
if ( ii == result. length - 1 ) {
b = b + result[ ii] + "]" ;
} else {
b = b + result[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public void latSelect ( ) {
int [ ] result = new int [ max] ;
int a = 0 ;
Stack < TreeNode > = new Stack < > ( ) ;
TreeNode cur = root, pre = null ;
if ( cur == null ) {
System . out. println ( "[]" ) ;
return ;
}
while ( null != cur || ! stack. isEmpty ( ) ) {
while ( null != cur) {
stack. push ( cur) ;
cur = cur. left;
}
cur = stack. peek ( ) ;
if ( null == cur. right || pre == cur. right) {
result[ a] = cur. data;
a++ ;
pre = cur;
cur = null ;
stack. pop ( ) ;
} else
cur = cur. right;
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < result. length; ii++ ) {
if ( ii == result. length - 1 ) {
b = b + result[ ii] + "]" ;
} else {
b = b + result[ ii] + "," ;
}
}
System . out. println ( b) ;
}
public TreeNode getNode ( int data) {
TreeNode treeNode = root;
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要查找的节点" ) ;
return null ;
}
if ( treeNode. data > data) {
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
return treeNode;
}
}
}
public void delete ( int data) {
TreeNode treeNode = root;
TreeNode temp1 = null ;
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要删除的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp1 = treeNode;
treeNode = treeNode. left;
} else if ( treeNode. data < data) {
temp1 = treeNode;
treeNode = treeNode. right;
} else if ( treeNode. data == data) {
if ( temp1. left == treeNode) {
temp1. left = null ;
return ;
}
if ( temp1. right == treeNode) {
temp1. right = null ;
return ;
}
}
}
}
public void update ( int data, int da) {
TreeNode treeNode = root;
TreeNode temp1 = root;
TreeNode temp2 = root;
TreeNode aa = null ;
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
}
while ( true ) {
if ( treeNode == null ) {
System . out. println ( "没有要修改的节点" ) ;
return ;
} else if ( treeNode. data > data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. left;
if ( temp2. right == temp1 && temp1. left == treeNode) {
aa = temp2;
}
} else if ( treeNode. data < data) {
temp2 = temp1;
temp1 = treeNode;
treeNode = treeNode. right;
if ( temp2. left == temp1 && temp1. right == treeNode) {
aa = temp2;
}
} else if ( treeNode. data == data) {
TreeNode temp3 = treeNode. left;
TreeNode temp4 = treeNode. right;
int max;
int min;
if ( temp3 != null ) {
while ( true ) {
if ( temp3. right == null ) {
min = temp3. data;
break ;
}
temp3 = temp3. right;
}
} else {
min = treeNode. data;
}
if ( temp4 != null ) {
while ( true ) {
if ( temp4. left == null ) {
max = temp4. data;
break ;
}
temp4 = temp4. left;
}
} else {
max = treeNode. data;
}
if ( min == treeNode. data && max == treeNode. data) {
if ( treeNode == root) {
treeNode. data = da;
return ;
}
} else if ( min == treeNode. data) {
if ( da >= max) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
} else if ( max == treeNode. data) {
if ( da <= min) {
System . out. println ( "修改数值不合理" ) ;
return ;
}
}
if ( temp1. left == treeNode) {
if ( aa == null ) {
if ( da >= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da >= temp1. data || da <= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
if ( temp1. right == treeNode) {
if ( aa == null ) {
if ( da <= temp1. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
} else {
if ( da <= temp1. data || da >= aa. data) {
System . out. println ( "修改数值不合理" ) ;
} else {
treeNode. data = da;
}
}
return ;
}
}
}
}
public static void main ( String [ ] args) {
Tree2 tree = new Tree2 ( ) ;
tree. insert ( 10 ) ;
tree. insert ( 8 ) ;
tree. insert ( 11 ) ;
tree. insert ( 7 ) ;
tree. insert ( 9 ) ;
tree. insert ( 12 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
System . out. println ( "总个数是:" + tree. max) ;
TreeNode node = tree. getNode ( 7 ) ;
if ( node != null ) {
System . out. println ( "数值为:" + node. data) ;
} else {
System . out. println ( "没有节点,也就没有数值" ) ;
}
tree. delete ( 7 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
tree. update ( 8 , 9 ) ;
System . out. println ( "=============前序遍历是:=============" ) ;
tree. preSelect ( ) ;
System . out. println ( "=============中序遍历是:=============" ) ;
tree. inSelect ( ) ;
System . out. println ( "=============后序遍历是:=============" ) ;
tree. latSelect ( ) ;
}
}
package com ;
import javax. management. Query ;
import java. util. LinkedList ;
import java. util. Queue ;
public class Scope {
TreeNode root;
int max;
public class TreeNode {
int data;
TreeNode left;
TreeNode right;
public TreeNode ( int data) {
this . data = data;
}
}
public TreeNode insert ( TreeNode treeNode, int data) {
if ( treeNode == null ) {
treeNode = new TreeNode ( data) ;
max++ ;
return treeNode;
}
if ( data < treeNode. data) {
treeNode. left = insert ( treeNode. left, data) ;
} else if ( data > treeNode. data) {
treeNode. right = insert ( treeNode. right, data) ;
} else {
treeNode. data = data;
}
return treeNode;
}
public void Scope ( ) {
Queue < TreeNode > = new LinkedList ( ) ;
queue. offer ( root) ;
while ( ! queue. isEmpty ( ) ) {
TreeNode poll = queue. poll ( ) ;
System . out. println ( poll. data) ;
if ( poll. left != null ) {
queue. offer ( poll. left) ;
}
if ( poll. right != null ) {
queue. offer ( poll. right) ;
}
}
}
public static void main ( String [ ] args) {
Scope tree = new Scope ( ) ;
tree. root = tree. insert ( tree. root, 10 ) ;
tree. root = tree. insert ( tree. root, 8 ) ;
tree. root = tree. insert ( tree. root, 11 ) ;
tree. root = tree. insert ( tree. root, 7 ) ;
tree. root = tree. insert ( tree. root, 9 ) ;
tree. root = tree. insert ( tree. root, 12 ) ;
tree. Scope( ) ;
System . out. println ( "总共多少节点:" + tree. max) ;
}
}
这个1在log里面 ,即这个5就是logn+1+x次,即范围就是[logn+1+x ~ 0.99],但我们可以发现,他可以多出几个节点(比如下面的6位置的节点),那么一般能加上几次,所以是logn+1+x,但整体而言,是logn+1(一般底数也是2,省略了,所以我们默认log在时间复杂度的底数是2,以后默认省略,无论n是否无限大都省略)
不同情况的图片是不相关的,不要 以为有联系
即没有C,所以下面的C你要省略 ,因为加上了是不符合规则的,这里要注意,这是图片的问题 ),且新结点是父结点的右孩子,父结 点(B)是祖父结点的左孩子
不同情况的图片是不相关的 以c省略 来操作的),且新结点是父结点的左孩子,父结 点(B)是祖父结点的左孩子
一般是这样的 ,这也是为了防止以后再次出现的原因,因为程序是一直操作的,无论是颜色反转,还是左右旋转,都是服务于程序的,所以需要综合考虑),所以通常这样考虑,那么既然说到这里,就说明一下,颜色反转为什么只操作子,父,爷三个节点的
public class Tree {
Node root;
public class Node {
Node left;
Node right;
Node parent;
boolean color;
int key;
public Node ( int key) {
this . key = key;
this . color = false ;
}
public String toString ( ) {
return "Tree{" +
"key=" + key +
", color=" + ( color == true ? "BLACK" : "RED" ) +
'}' ;
}
}
public void insert ( int key) {
Node temp1 = root;
if ( temp1 == null ) {
root = new Node ( key) ;
root. color = true ;
return ;
}
Node parent = root;
while ( temp1 != null ) {
if ( key < temp1. key) {
parent = temp1;
temp1 = temp1. left;
} else if ( key > temp1. key) {
parent = temp1;
temp1 = temp1. right;
} else {
temp1. key = key;
return ;
}
}
Node node = new Node ( key) ;
if ( key < parent. key) {
parent. left = node;
}
if ( key > parent. key) {
parent. right = node;
}
node. parent = parent;
banlanceInsert ( node) ;
}
public void banlanceInsert ( Node node) {
if ( node. parent. color == true ) {
return ;
}
while ( node. parent != null && node. parent. color != true ) {
Node grandparent = node. parent. parent;
if ( grandparent. left == node. parent) {
if ( grandparent. right != null && grandparent. right. color == false ) {
node. parent. color = true ;
grandparent. right. color = true ;
grandparent. color = false ;
node = grandparent;
continue ;
}
if ( node == node. parent. right) {
Node temp = node. parent;
leftRotate ( node) ;
rightRotate ( temp) ;
} else {
rightRotate ( node) ;
}
} else {
if ( grandparent. left != null && grandparent. left. color == false ) {
node. parent. color = true ;
grandparent. left. color = true ;
grandparent. color = false ;
node = grandparent;
continue ;
}
if ( node == node. parent. right) {
leftRotate ( node) ;
} else {
Node temp = node. parent;
rightRotate ( node) ;
leftRotate ( temp) ;
}
}
}
root. color = true ;
}
public void leftRotate ( Node node) {
Node parent = node. parent;
Node grandparent = parent. parent;
if ( grandparent. parent == null ) {
if ( node. parent. right == node && grandparent. left == node. parent) {
Node node1 = node. left;
node. left = node. parent;
node. parent. parent = node;
node. parent. right = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. left = node;
node. parent = grandparent;
return ;
}
if ( node. parent. right == node && grandparent. right == node. parent) {
root = node. parent;
grandparent. right = node. parent. left;
if ( node. parent. left!= null ) {
node. parent. left. parent = grandparent;
}
node. parent. parent = null ;
node. parent. left = grandparent;
grandparent. parent = node. parent;
grandparent. color = false ;
root. color = true ;
return ;
}
} else {
if ( node. parent. right == node && grandparent. left == node. parent) {
Node node1 = node. left;
node. left = node. parent;
node. parent. parent = node;
node. parent. right = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. left = node;
node. parent = grandparent;
return ;
}
if ( node. parent. right == node && grandparent. right == node. parent) {
if ( grandparent. parent. left == grandparent) {
grandparent. parent. left = node. parent;
grandparent. right = node. parent. left;
if ( node. parent. left!= null ) {
node. parent. left. parent = grandparent;
}
node. parent. parent = grandparent. parent;
node. parent. left = grandparent;
grandparent. parent = node. parent;
grandparent. color = false ;
grandparent. parent. color = true ;
return ;
}
if ( grandparent. parent. right == grandparent) {
grandparent. parent. right = node. parent;
grandparent. right = node. parent. left;
if ( node. parent. left!= null ) {
node. parent. left. parent = grandparent;
}
node. parent. parent = grandparent. parent;
node. parent. left = grandparent;
grandparent. parent = node. parent;
grandparent. color = false ;
grandparent. parent. color = true ;
return ;
}
}
}
}
public void rightRotate ( Node node) {
Node parent = node. parent;
Node grandparent = parent. parent;
if ( grandparent. parent == null ) {
if ( node. parent. left == node && grandparent. right == node. parent) {
Node node1 = node. right;
node. right = node. parent;
node. parent. parent = node;
node. parent. left = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. right = node;
node. parent = grandparent;
return ;
}
if ( node. parent. left == node && grandparent. left == node. parent) {
Node node1 = node. parent. right;
root = node. parent;
grandparent. left = node1;
if ( node1!= null ) {
node1. parent = grandparent;
}
node. parent. parent = null ;
node. parent. right = grandparent;
grandparent. parent = node. parent;
grandparent. color = false ;
root. color = true ;
return ;
}
} else {
if ( node. parent. left == node && grandparent. right == node. parent) {
Node node1 = node. right;
node. right = node. parent;
node. parent. parent = node;
node. parent. left = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. right = node;
node. parent = grandparent;
return ;
}
if ( node. parent. left == node && grandparent. left == node. parent) {
if ( grandparent. parent. left == grandparent) {
Node node1 = node. parent. right;
grandparent. parent. left = node. parent;
node. parent. parent = grandparent. parent;
grandparent. left = node1;
if ( node1!= null ) {
node1. parent = grandparent;
}
grandparent. parent = node. parent;
node. parent. right = grandparent;
grandparent. color = false ;
grandparent. parent. color = true ;
return ;
}
if ( grandparent. parent. right == grandparent) {
Node node1 = node. parent. right;
grandparent. parent. right = node. parent;
node. parent. parent = grandparent. parent;
grandparent. left = node1;
if ( node1!= null ) {
node1. parent = grandparent;
}
grandparent. parent = node. parent;
node. parent. right = grandparent;
grandparent. color = false ;
grandparent. parent. color = true ;
return ;
}
}
}
}
public void list ( Node node) {
if ( node == null ) {
return ;
}
if ( node. left == null && node. right == null ) {
System . out. println ( node) ;
return ;
}
System . out. println ( node) ;
list ( node. left) ;
list ( node. right) ;
}
public static void main ( String [ ] args) {
Tree rb = new Tree ( ) ;
rb. insert ( 10 ) ;
rb. insert ( 5 ) ;
rb. insert ( 9 ) ;
rb. insert ( 3 ) ;
rb. insert ( 6 ) ;
rb. insert ( 7 ) ;
rb. insert ( 19 ) ;
rb. insert ( 32 ) ;
rb. insert ( 24 ) ;
rb. insert ( 17 ) ;
rb. list ( rb. root) ;
}
}
public void leftRotate ( Node node) {
Node parent = node. parent;
Node grandparent = parent. parent;
if ( node. parent. right == node && grandparent. left == node. parent) {
Node node1 = node. left;
node. left = node. parent;
node. parent. parent = node;
node. parent. right = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. left = node;
node. parent = grandparent;
return ;
}
if ( node. parent. right == node && grandparent. right == node. parent) {
if ( grandparent. parent == null ) {
root = node. parent;
node. parent. parent = null ;
} else {
if ( grandparent. parent. left == grandparent) {
grandparent. parent. left = node. parent;
}
if ( grandparent. parent. right == grandparent) {
grandparent. parent. right = node. parent;
}
node. parent. parent = grandparent. parent;
}
}
grandparent. right = node. parent. left;
if ( node. parent. left!= null ) {
node. parent. left. parent = grandparent;
}
node. parent. left = grandparent;
grandparent. parent = node. parent;
grandparent. color = false ;
if ( grandparent. parent != null ) {
grandparent. parent. color = true ;
} else {
root. color = true ;
}
}
public void rightRotate ( Node node) {
Node parent = node. parent;
Node grandparent = parent. parent;
if ( node. parent. left == node && grandparent. right == node. parent) {
Node node1 = node. right;
node. right = node. parent;
node. parent. parent = node;
node. parent. left = node1;
if ( node1!= null ) {
node1. parent = node. parent;
}
grandparent. right = node;
node. parent = grandparent;
return ;
}
if ( node. parent. left == node && grandparent. left == node. parent) {
Node node1 = node. parent. right;
if ( grandparent. parent == null ) {
root = node. parent;
node. parent. parent = null ;
} else {
if ( grandparent. parent. left == grandparent) {
grandparent. parent. left = node. parent;
}
if ( grandparent. parent. right == grandparent) {
grandparent. parent. right = node. parent;
}
node. parent. parent = grandparent. parent;
}
grandparent. left = node1;
if ( node1!= null ) {
node1. parent = grandparent;
}
grandparent. parent = node. parent;
node. parent. right = grandparent;
grandparent. color = false ;
if ( grandparent. parent == null ) {
root. color = true ;
} else {
grandparent. parent. color = true ;
}
}
}
package tt ;
public class Tree {
public class RBTreeNode {
private int key;
private boolean isBlack;
private RBTreeNode left;
private RBTreeNode right;
private RBTreeNode parent;
public RBTreeNode ( int key) {
this . key = key;
this . isBlack = false ;
}
public int getKey ( ) {
return key;
}
public boolean isBlack ( ) {
return isBlack;
}
public RBTreeNode getLeft ( ) {
return left;
}
public RBTreeNode getRight ( ) {
return right;
}
public RBTreeNode getParent ( ) {
return parent;
}
public void setKey ( int key) {
this . key = key;
}
public void setBlack ( boolean black) {
isBlack = black;
}
public void setLeft ( RBTreeNode left) {
this . left = left;
}
public void setRight ( RBTreeNode right) {
this . right = right;
}
public void setParent ( RBTreeNode parent) {
this . parent = parent;
}
@Override
public String toString ( ) {
return "RBTreeNode{" +
"key=" + key +
", color=" + ( isBlack == true ? "BLACK" : "RED" ) +
'}' ;
}
}
RBTreeNode root;
public void list ( RBTreeNode node) {
if ( node == null ) return ;
if ( node. getLeft ( ) == null && node. getRight ( ) == null ) {
System . out. println ( node) ;
return ;
}
System . out. println ( node) ;
list ( node. getLeft ( ) ) ;
list ( node. getRight ( ) ) ;
}
public void insert ( int key) {
RBTreeNode node = new RBTreeNode ( key) ;
if ( root == null ) {
node. setBlack ( true ) ;
root = node;
return ;
}
RBTreeNode parent = root;
RBTreeNode son = null ;
if ( key <= parent. getKey ( ) ) {
son = parent. getLeft ( ) ;
} else {
son = parent. getRight ( ) ;
}
while ( son != null ) {
parent = son;
if ( key <= parent. getKey ( ) ) {
son = parent. getLeft ( ) ;
} else {
son = parent. getRight ( ) ;
}
}
if ( key <= parent. getKey ( ) ) {
parent. setLeft ( node) ;
} else {
parent. setRight ( node) ;
}
node. setParent ( parent) ;
banlanceInsert ( node) ;
}
private void banlanceInsert ( RBTreeNode node) {
RBTreeNode father, grandFather;
while ( ( father = node. getParent ( ) ) != null && father. isBlack ( ) == false ) {
grandFather = father. getParent ( ) ;
if ( grandFather. getLeft ( ) == father) {
RBTreeNode uncle = grandFather. getRight ( ) ;
if ( uncle != null && uncle. isBlack ( ) == false ) {
setBlack ( father) ;
setBlack ( uncle) ;
setRed ( grandFather) ;
node = grandFather;
continue ;
}
if ( node == father. getRight ( ) ) {
leftRotate ( father) ;
RBTreeNode tmp = node;
node = father;
father = tmp;
}
setBlack ( father) ;
setRed ( grandFather) ;
rightRotate ( grandFather) ;
}
else {
RBTreeNode uncle = grandFather. getLeft ( ) ;
if ( uncle != null && uncle. isBlack ( ) == false ) {
setBlack ( father) ;
setBlack ( uncle) ;
setRed ( grandFather) ;
node = grandFather;
continue ;
}
if ( node == father. getLeft ( ) ) {
rightRotate ( father) ;
RBTreeNode tmp = node;
node = father;
father = tmp;
}
setBlack ( father) ;
setRed ( grandFather) ;
leftRotate ( grandFather) ;
}
}
setBlack ( root) ;
}
private void leftRotate ( RBTreeNode node) {
RBTreeNode right = node. getRight ( ) ;
RBTreeNode parent = node. getParent ( ) ;
if ( parent == null ) {
root = right;
right. setParent ( null ) ;
} else {
if ( parent. getLeft ( ) != null && parent. getLeft ( ) == node) {
parent. setLeft ( right) ;
} else {
parent. setRight ( right) ;
}
right. setParent ( parent) ;
}
node. setParent ( right) ;
node. setRight ( right. getLeft ( ) ) ;
if ( right. getLeft ( ) != null ) {
right. getLeft ( ) . setParent ( node) ;
}
right. setLeft ( node) ;
}
private void rightRotate ( RBTreeNode node) {
RBTreeNode left = node. getLeft ( ) ;
RBTreeNode parent = node. getParent ( ) ;
if ( parent == null ) {
root = left;
left. setParent ( null ) ;
} else {
if ( parent. getLeft ( ) != null && parent. getLeft ( ) == node) {
parent. setLeft ( left) ;
} else {
parent. setRight ( left) ;
}
left. setParent ( parent) ;
}
node. setParent ( left) ;
node. setLeft ( left. getRight ( ) ) ;
if ( left. getRight ( ) != null ) {
left. getRight ( ) . setParent ( node) ;
}
left. setRight ( node) ;
}
private void setBlack ( RBTreeNode node) {
node. setBlack ( true ) ;
}
private void setRed ( RBTreeNode node) {
node. setBlack ( false ) ;
}
public static void main ( String [ ] args) {
Tree rb = new Tree ( ) ;
rb. insert ( 10 ) ;
rb. insert ( 5 ) ;
rb. insert ( 9 ) ;
rb. insert ( 3 ) ;
rb. insert ( 6 ) ;
rb. insert ( 7 ) ;
rb. insert ( 19 ) ;
rb. insert ( 32 ) ;
rb. insert ( 24 ) ;
rb. insert ( 17 ) ;
rb. list ( rb. root) ;
}
}
transient Node < K , V > [ ] table;
static final int TREEIFY_THRESHOLD = 8 ;
值相同 ,而不是具体位置,比如原来5在5前面,那么排序后,5还是在5前面,他们的相对位置没有变,具体一点,就是,如果下标1的值是5,下标3的值是5,将下标1的5变到下标5中,下标3变到下标6中,且下标6的5还是下标5的5的后一个,所以可以说,判断一种排序是否稳定就是在排序过程中看相同的元素的相对位置 (始终在后面)是否改变
package com. lagou ;
public class test1 {
public static void main ( String [ ] args) {
int [ ] array = { 50 , 2 , 5 , 7 , 8 , 3 , 1 } ;
for ( int i = 0 ; i < array. length - 1 ; i++ ) {
for ( int j = 0 ; j < array. length - 1 ; j++ ) {
if ( array[ j] > array[ j + 1 ] ) {
int a = array[ j + 1 ] ;
array[ j + 1 ] = array[ j] ;
array[ j] = a;
}
}
}
for ( int o = 0 ; o < array. length; o++ ) {
System . out. println ( array[ o] ) ;
}
}
}
package com. lagou ;
public class test2 {
public static void main ( String [ ] args) {
int [ ] nums = new int [ ] { 5 , 8 , 6 , 3 , 9 , 2 , 1 , 7 } ;
for ( int i = 0 ; i < nums. length - 1 ; i++ ) {
for ( int j = 0 ; j < nums. length - 1 ; j++ ) {
int tmp = 0 ;
if ( nums[ j] > nums[ j + 1 ] ) {
tmp = nums[ j] ;
nums[ j] = nums[ j + 1 ] ;
nums[ j + 1 ] = tmp;
}
}
}
for ( int n : nums) {
System . out. println ( n) ;
}
}
}
package com. lagou ;
public class test2 {
public static void main ( String [ ] args) {
int [ ] nums = new int [ ] { 5 , 8 , 6 , 3 , 9 , 2 , 1 , 7 } ;
for ( int i = 0 ; i < nums. length - 1 ; i++ ) {
boolean is = true ;
for ( int j = 0 ; j < nums. length - 1 - i; j++ ) {
int tmp = 0 ;
if ( nums[ j] > nums[ j + 1 ] ) {
is = false ;
tmp = nums[ j] ;
nums[ j] = nums[ j + 1 ] ;
nums[ j + 1 ] = tmp;
}
}
if ( is) {
break ;
}
}
for ( int n : nums) {
System . out. println ( n) ;
}
}
}











































































































![[附源码]Python计算机毕业设计Django基于vuejs的文创产品销售平台app](https://img-blog.csdnimg.cn/ddbd8c46ee864865b2b36ed38068a20e.png)