提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 学习目标
- (一)了解HDFS Java API
- 1、HDFS常见类与接口
- 2、FileSystem的常用方法
- (二)编写Java程序访问HDFS
- 1、创建Maven项目
- 2、添加相关依赖
- 3、创建日志属性文件
- 4、启动集群HDFS服务
- 5、在HDFS上创建文件
- 6、写入HDFS文件
- 7、读取HDFS文件
- 8、重命名目录或文件
- 9、显示文件列表
- 10、获取文件块信息
- 11、创建目录
- 12、判断目录或文件是否存在
- 13、判断Path指向目录还是文件
- 14、删除目录或文件
学习目标
- 了解HDFS Java API
- 掌握使用Java API操作HDFS
由于Hadoop是使用Java语言编写的,因此可以使用Java API操作Hadoop文件系统。HDFS Shell本质上就是对Java API的应用,通过编程的形式操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增、删、改、查)。
(一)了解HDFS Java API
- Hadoop文件系统API文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/index.html
1、HDFS常见类与接口
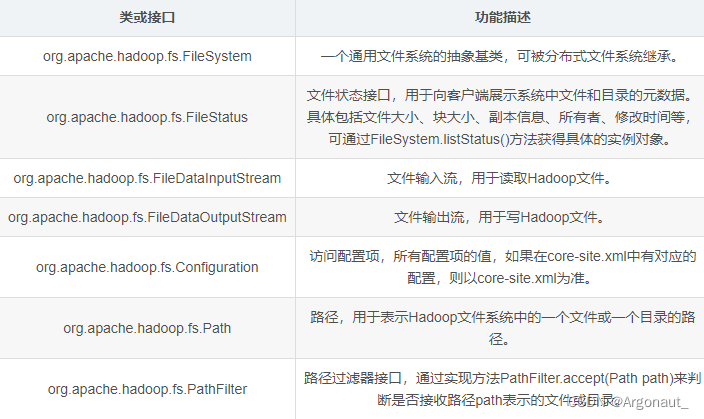
- Hadoop整合了众多文件系统,HDFS只是这个文件系统的一个实例。
2、FileSystem的常用方法
- FileSystem类API文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/filesystem.html
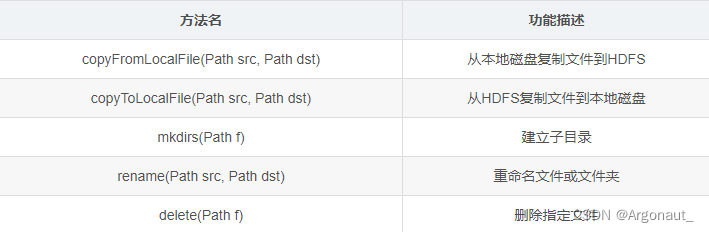
- FileSystem对象的一些方法可以对文件进行操作
(二)编写Java程序访问HDFS
1、创建Maven项目
- 创建Maven项目 - HDFSDemo
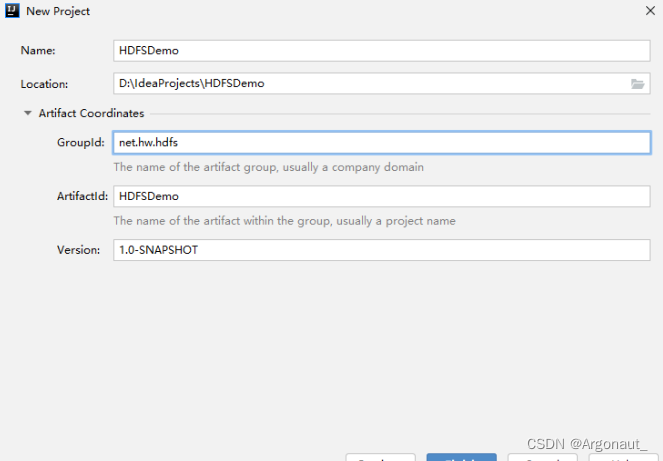
- 单击【Finish】按钮
2、添加相关依赖
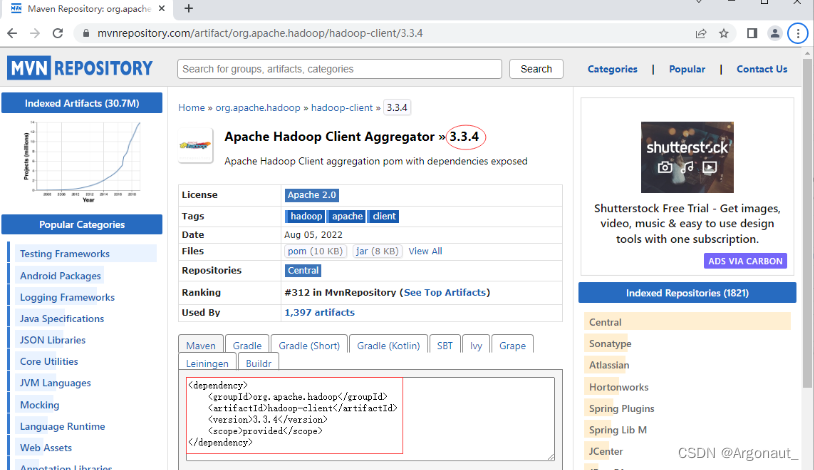
- 在pom.xml文件里添加hadoop和junit依赖
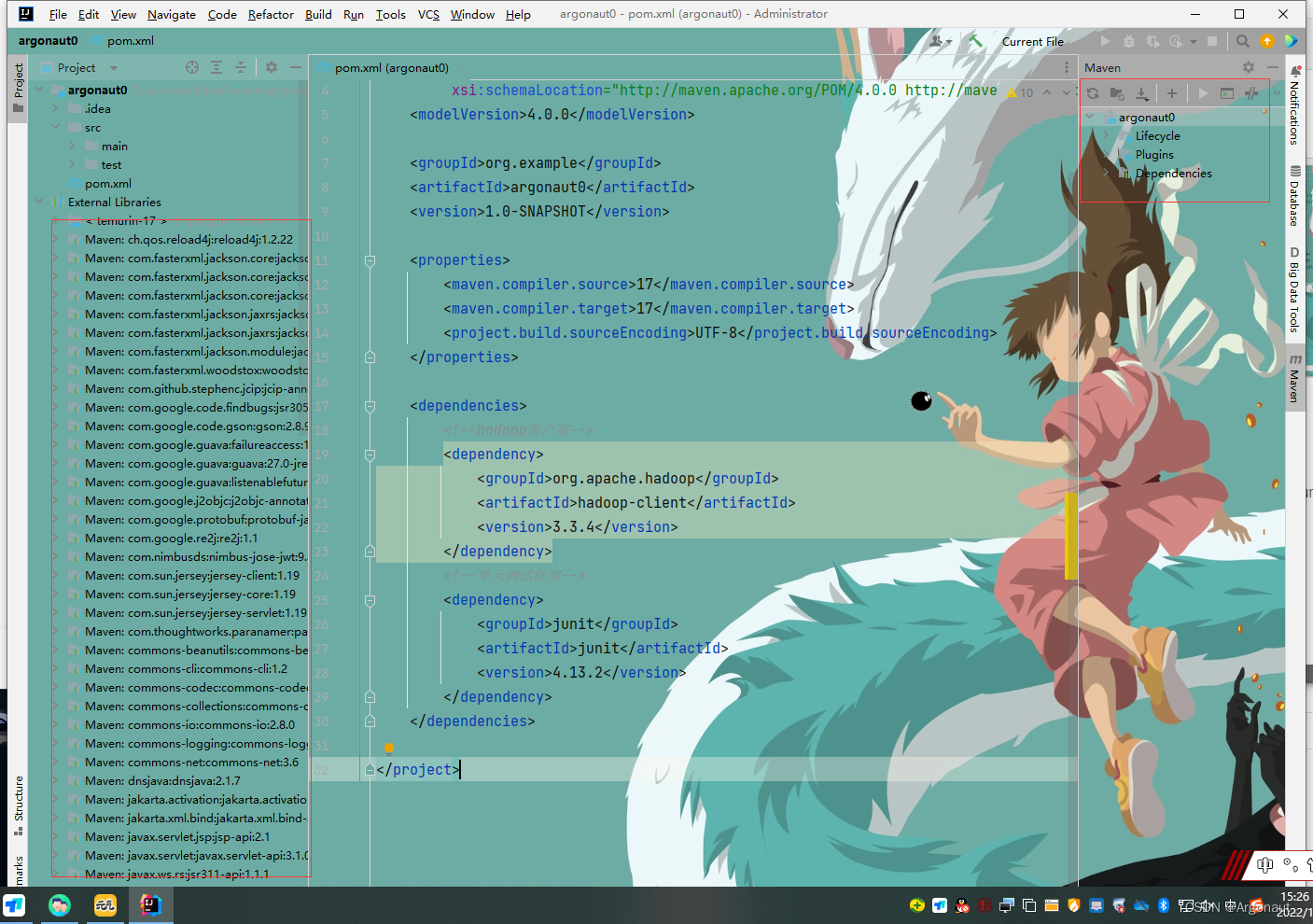
<dependencies>
<!--hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<!--单元测试框架-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies>
- Maven Repository(Maven仓库)
- https://mvnrepository.com/
- 搜索hadoop
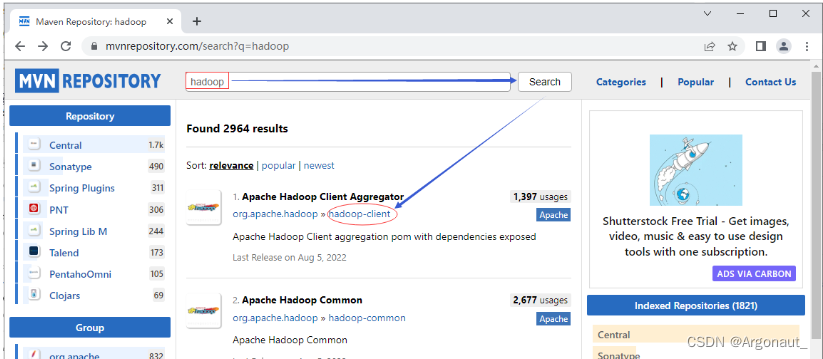
- 单击hadoop-client超链接
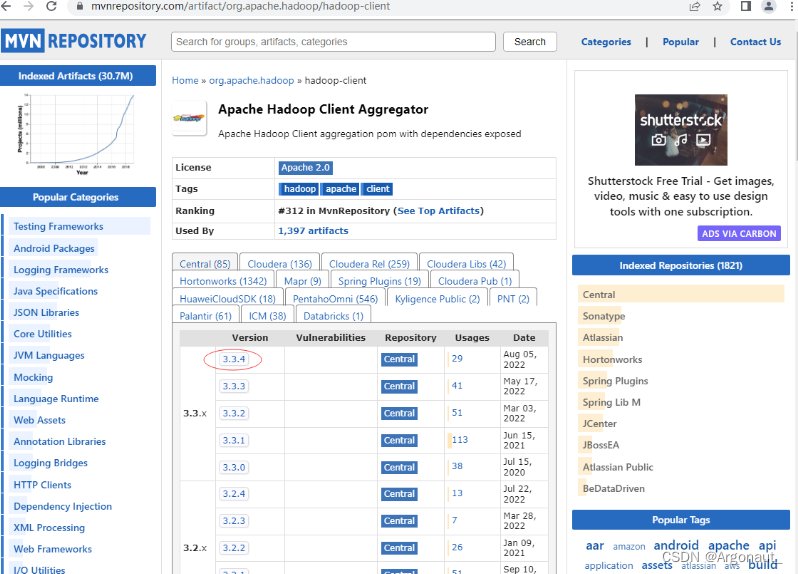
- 单击3.3.4超链接
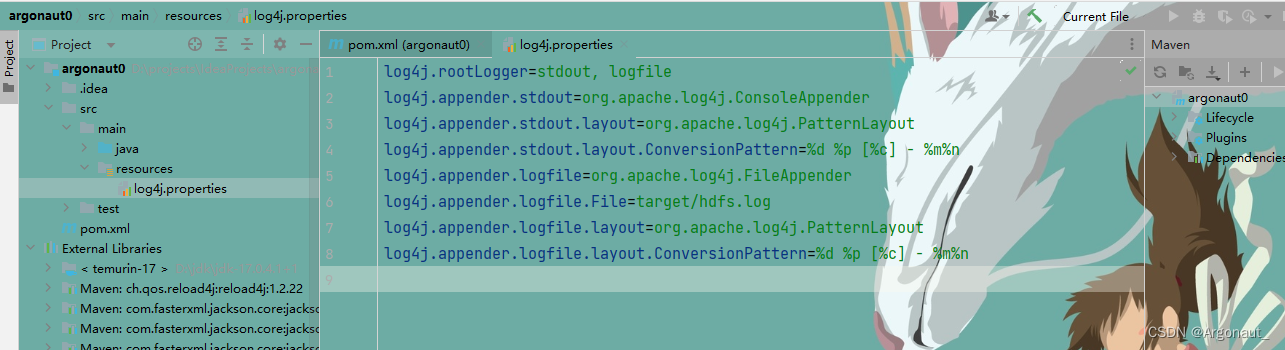
3、创建日志属性文件
- 在resources目录里创建log4j.properties文件
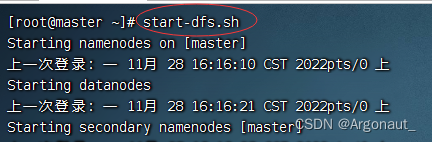
4、启动集群HDFS服务
- 在主节点上执行命令:start-dfs.sh
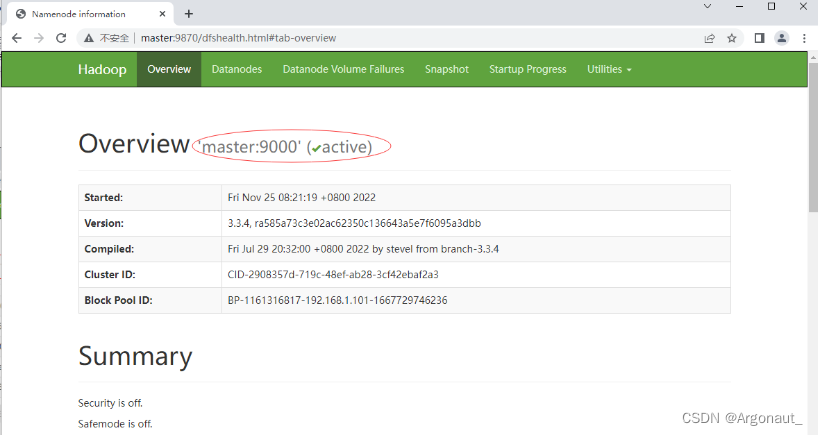
- 在Hadoop WebUI界面查看
5、在HDFS上创建文件
- 在HDFS Shell里利用hdfs dfs -touchz命令可以创建时间戳文件
- 任务:在/ied01目录创建hadoop.txt文件
- 创建net.hw.hdfs包,在包里创建CreateFileOnHDFS类
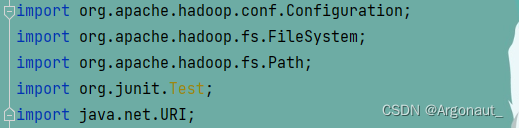
- 编写create1()方法
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.net.URI;
/**
* 功能:在HDFS上创建文件
* 作者:Argonaut
* 日期:2022年11月30日
*/
public class CreateFileOnHDFS {
@Test
public void create1() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/hadoop.txt");
// 基于路径对象创建文件
boolean result = fs.createNewFile(path);
// 根据返回值判断文件是否创建成功
if (result) {
System.out.println("文件[" + path + "]创建成功!");
} else {
System.out.println("文件[" + path + "]创建失败!");
}
}
}
- 注意:别导错包
- 运行程序,查看结果

- 利用Hadoop WebUI查看
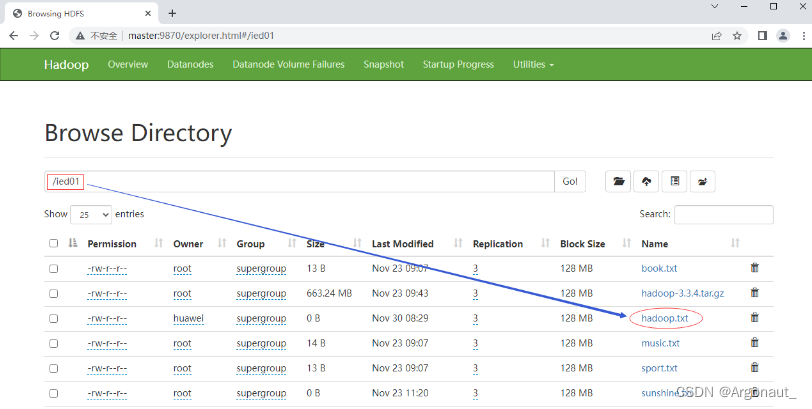
- 在/ied01目录里确实创建了一个0字节的hadoop.txt文件,有点类似于Hadoop Shell里执行hdfs dfs
-touchz /ied01/hadoop.txt命令的效果,但是有一点不同,hdfs dfs -touchz命令重复执行,不会失败,只是不断改变该文件的时间戳。 - 再次运行程序,由于hadoop.txt已经存在,此时会提示用户创建失败

- 能否事先判断文件是否存在呢?我们去查看Hadoop FileSystem API文档
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/filesystem.html
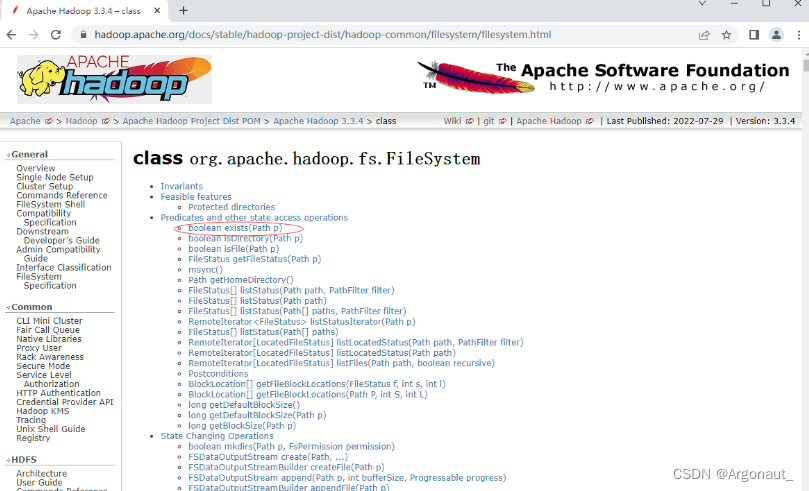
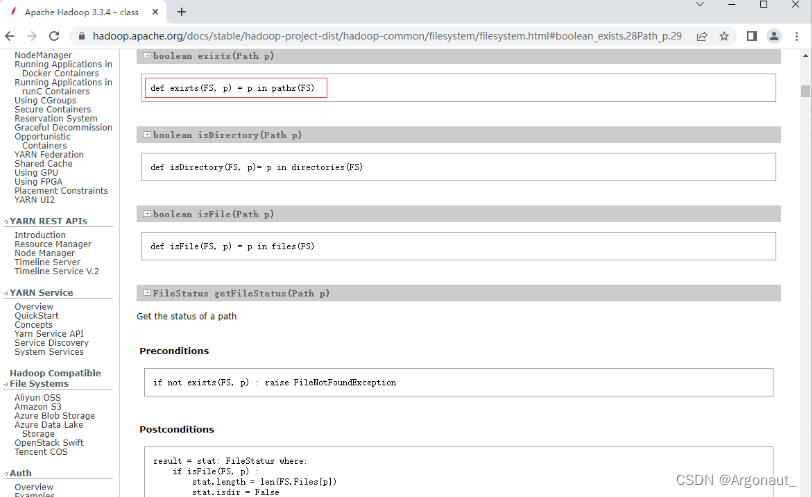
- 查看exists(Path path)方法
- 编写create2()方法,事先判断文件是否存在
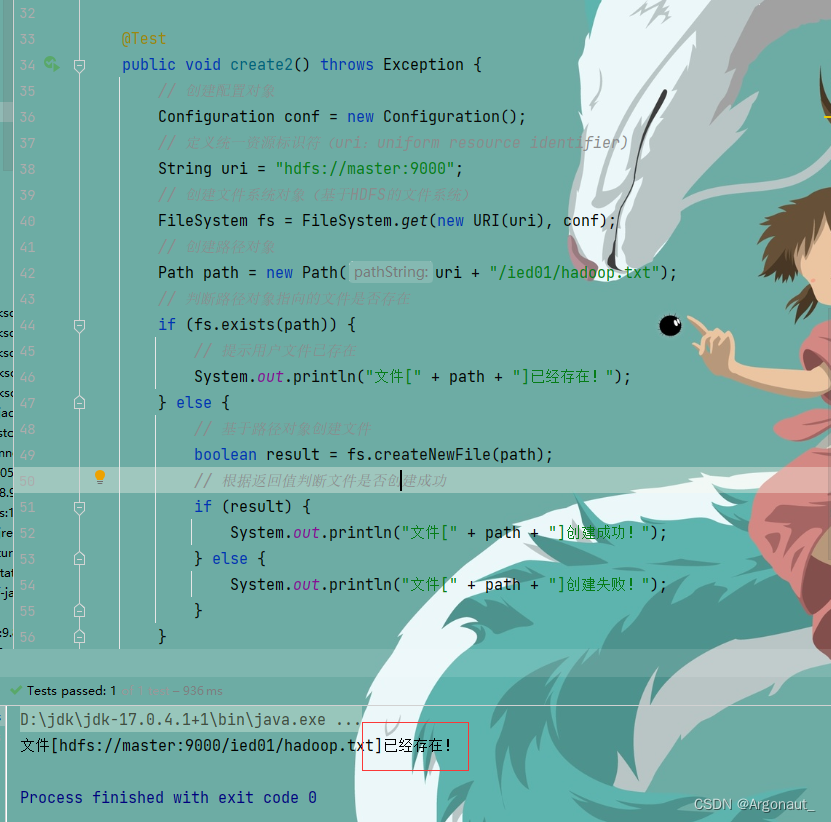
@Test
public void create2() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 定义统一资源标识符(uri:uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 创建路径对象
Path path = new Path(uri + "/ied01/hadoop.txt");
// 判断路径对象指向的文件是否存在
if (fs.exists(path)) {
// 提示用户文件已存在
System.out.println("文件[" + path + "]已经存在!");
} else {
// 基于路径对象创建文件
boolean result = fs.createNewFile(path);
// 根据返回值判断文件是否创建成功
if (result) {
System.out.println("文件[" + path + "]创建成功!");
} else {
System.out.println("文件[" + path + "]创建失败!");
}
}
}
- 如果hadoop服务没有启动,运行程序会抛出连接异常

- 故意让HDFS进入安全模式(只能读,不能写),看看会出现什么状况?
- 删除已经创建的/ied01/hadoop.txt
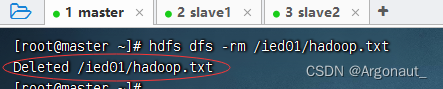
- 执行命令:hdfs dfsadmin -safemode enter
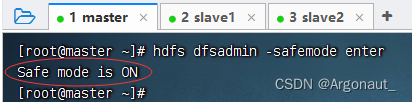
此时,再运行程序,查看结果,抛出SafeModeException异常

- 下面,修改程序,来处理这个可能会抛出的安全模式异常
@Test
public void create2() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/hadoop.txt");
// 判断路径对象指向的文件是否存在
if (fs.exists(path)) {
// 提示用户文件已存在
System.out.println("文件[" + path + "]已经存在!");
} else {
try {
// 基于路径对象创建文件
boolean result = fs.createNewFile(path);
// 根据返回值判断文件是否创建成功
if (result) {
System.out.println("文件[" + path + "]创建成功!");
} else {
System.out.println("文件[" + path + "]创建失败!");
}
} catch (Exception e) {
System.err.println("异常信息:" + e.getMessage());
}
}
}
- 运行程序,查看结果(虽然我们捕获了安全模式异常,但还是有一点系统抛出的异常信息)

- 关闭安全模式,执行命令:hdfs dfsadmin -safemode leave
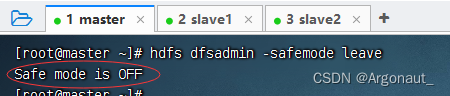
- 再运行程序,查看效果

6、写入HDFS文件
- 类似于HDFS Shell里的hdfs dfs -put命令
- 在net.hw.hdfs包里创建WriteFileOnHDFS类
(1)将数据直接写入HDFS文件 - 任务:在/ied01目录里创建hello.txt文件
- 创建write1()方法
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.net.URI;
/**
* 功能:写入HDFS文件
* 作者:Argonaut
* 日期:2022年11月30日
*/
public class WriteFileOnHDFS {
@Test
public void write1() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/hello.txt");
// 创建文件系统数据字节输出流(出水管:数据从程序到文件)
FSDataOutputStream out = fs.create(path);
// 通过字节输出流向文件写数据
out.write("Hello Hadoop World".getBytes());
// 关闭文件系统数据字节输出流
out.close();
// 关闭文件系统对象
fs.close();
// 提示用户写文件成功
System.out.println("文件[" + path + "]写入成功!");
}
}
- 运行write1()测试方法,查看结果,抛出RemoteException异常,三个数据节点都在运行,但是无法写入数据

- 修改代码,设置数据节点主机名属性,如下图所示
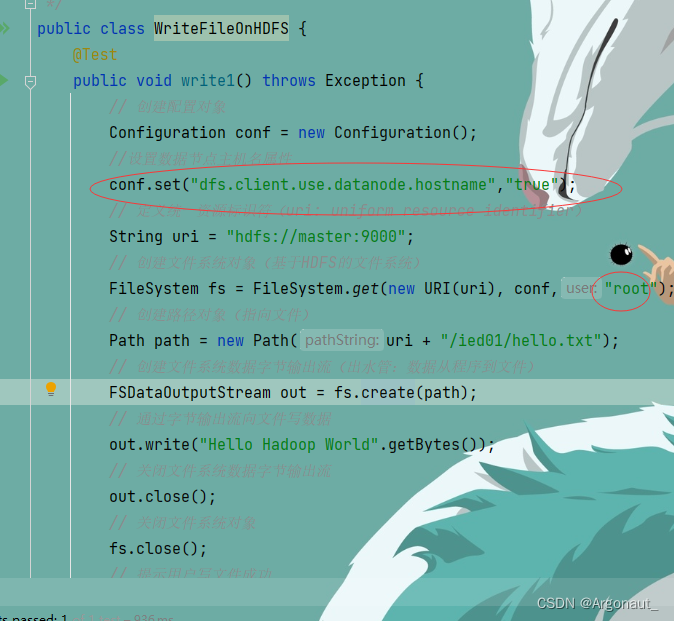
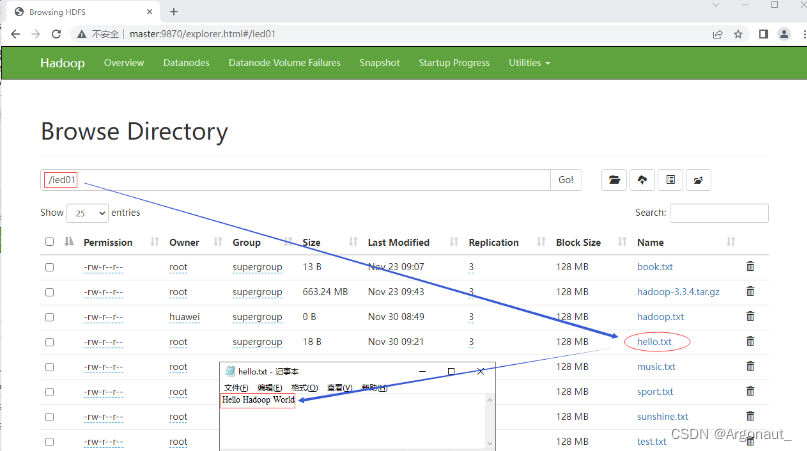
- 运行程序,查看结果

- 利用Hadoop WebUI查看hello.txt文件
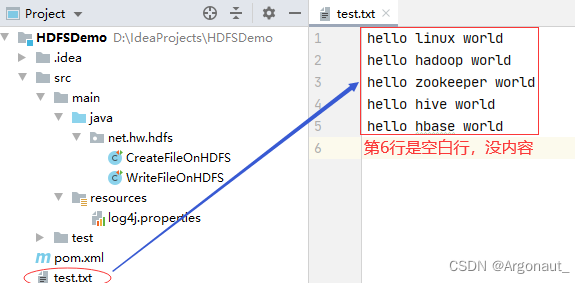
(2)将本地文件写入HDFS文件 - 在项目根目录创建一个文本文件test.txt
- 创建write2()方法
@Test
public void write2() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/exam.txt");
// 创建文件系统数据字节输出流(出水管:数据从程序到文件)
FSDataOutputStream out = fs.create(path);
// 创建文件字符输入流对象(进水管:数据从文件到程序)
FileReader fr = new FileReader("test.txt");
// 创建缓冲字符输入流对象
BufferedReader br = new BufferedReader(fr);
// 定义行字符串变量
String nextLine = "";
// 通过循环遍历缓冲字符输入流
while ((nextLine = br.readLine()) != null) {
// 在控制台输出读取的行
System.out.println(nextLine);
// 通过文件系统数据字节输出流对象写入指定文件
out.write((nextLine + "\n").getBytes());
}
// 关闭缓冲字符输入流
br.close();
// 关闭文件字符输入流
fr.close();
// 关闭文件系统数据字节输出流
out.close();
// 提示用户写入文件成功
System.out.println("本地文件[test.txt]成功写入[" + path + "]!");
}
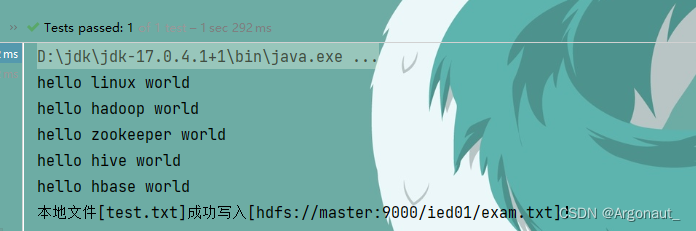
- 查看/ied01/exam.txt内容
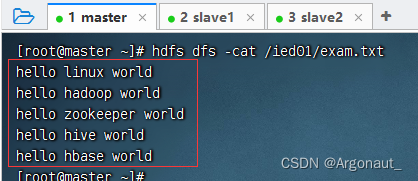
- 其实这个方法的功能就是将本地文件复制(上传)到HDFS,有没有更简单的处理方法呢?有的,通过使用一个工具类IOUtils来完成文件的相关操作。
- 编写write2_()方法

@Test
public void write2_() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/test.txt");
// 创建文件系统数据字节输出流(出水管:数据从程序到文件)
FSDataOutputStream out = fs.create(path);
// 创建文件字节输入流(进水管:数据从文件到程序)
FileInputStream in = new FileInputStream("test.txt");
// 利用IOUtils类提供的字节拷贝方法在控制台显示文件内容
IOUtils.copyBytes(in, System.out, 1024, false);
// 利用IOUtils类提供的字节拷贝方法来复制文件
IOUtils.copyBytes(in, out, conf);
// 关闭文件字节输入流
in.close();
// 关闭文件系统数据字节输出流
out.close();
// 提示用户写入文件成功
System.out.println("本地文件[test.txt]成功写入[" + path + "]!");
}
- 注意导包问题
- 运行write2_()测试方法,查看结果
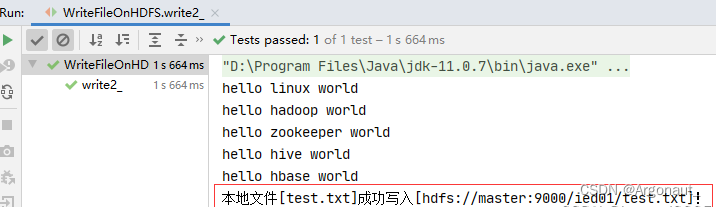
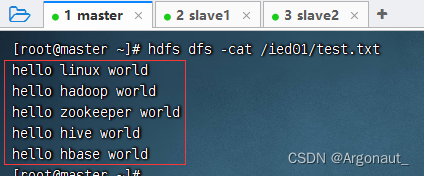
- 查看/ied01/test.txt内容,文件是存在的,但是没有内容,怎么回事呢?
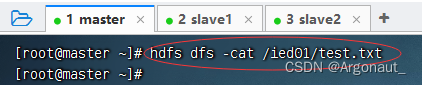
- 因为字节输入流的数据已经输出到到控制台,此时字节输入流里已经没有数据,此时执行IOUtils.copyBytes(in, out,
conf);,因此输出流肯定也没有数据可以写入文件,那该怎么办呢?再次读取文件,让字节输入流有数据。
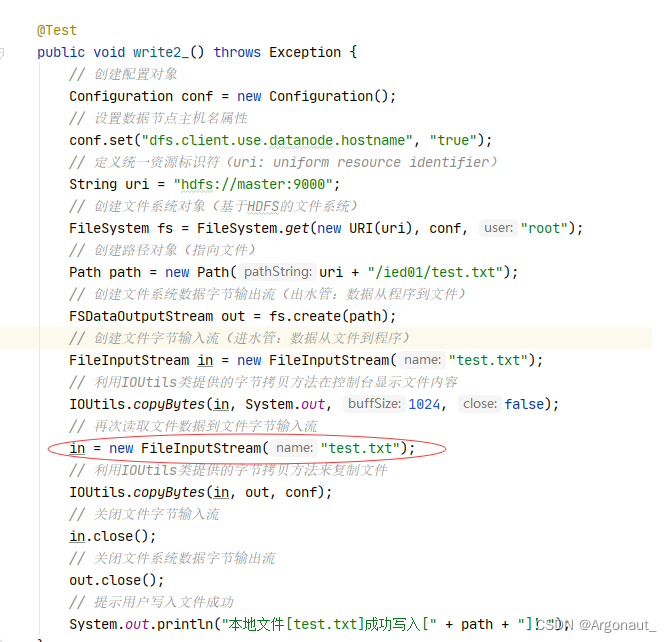
- 查看/ied01/test.txt文件
7、读取HDFS文件
- 相当于Shell里的两个命令:hdfs dfs -cat和hdfs dfs -get
- 在net.hw.hdfs包里创建ReadFileOnHDFS类
(1)读取HDFS文件直接在控制台显示 - 准备读取hdfs://master:9000/ied01/test.txt文件
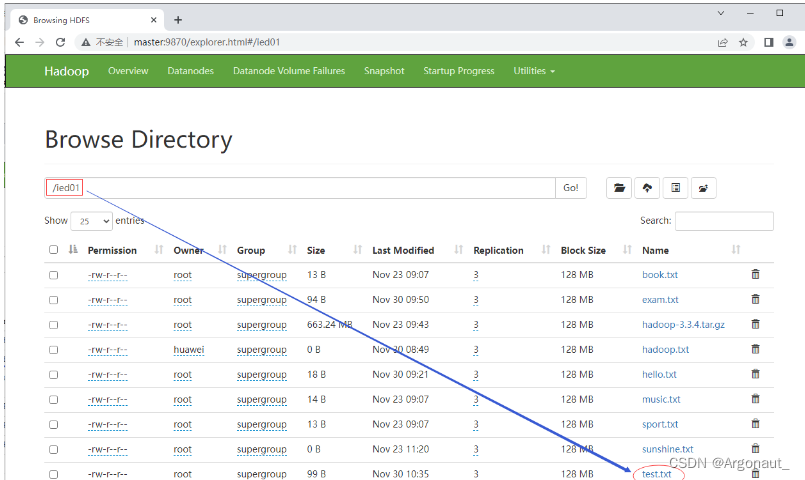
- 编写read1()方法
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
/**
* 功能:读取HDFS文件
* 作者:Argonaut
* 日期:2022年11月30日
*/
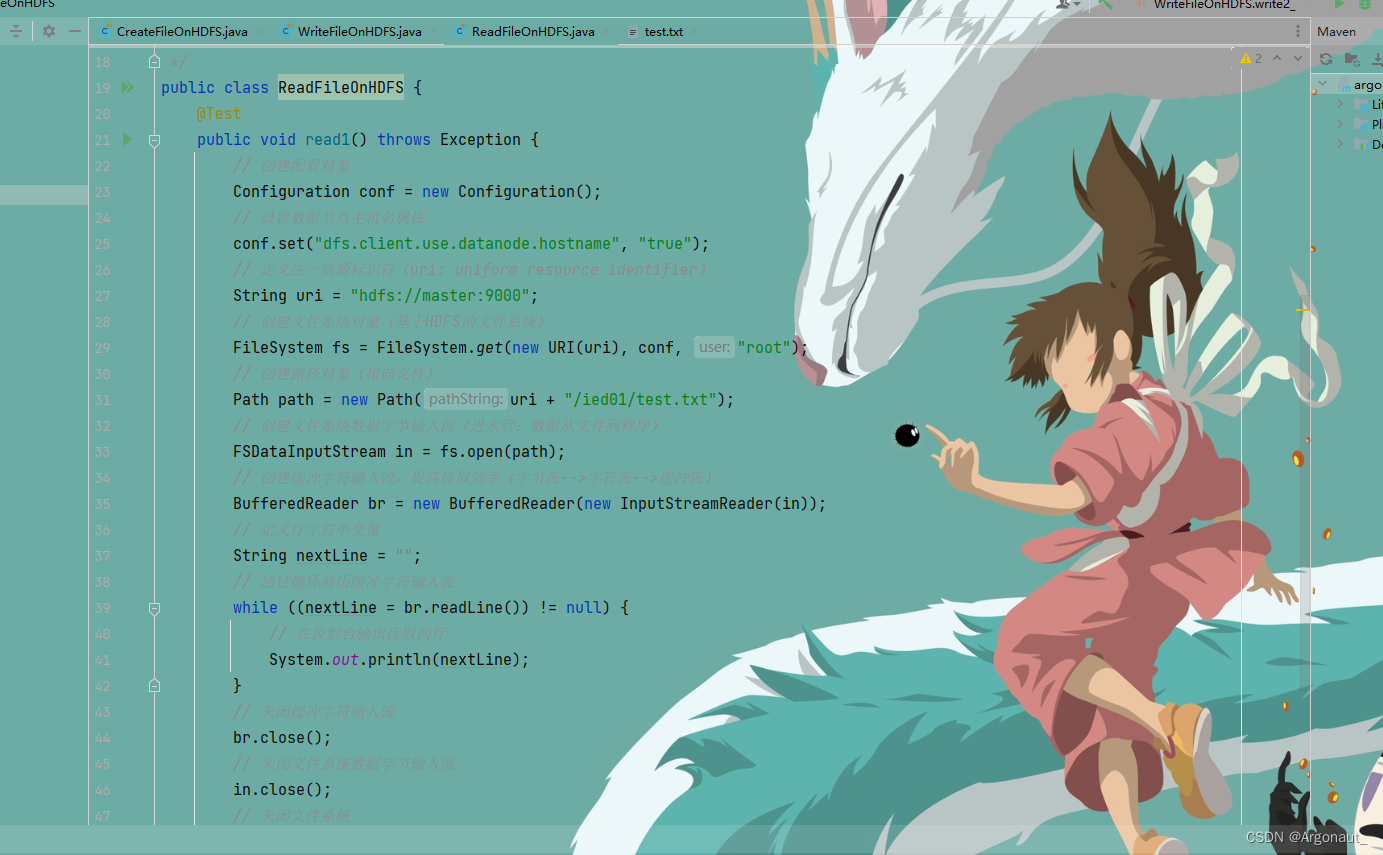
public class ReadFileOnHDFS {
@Test
public void read1() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/test.txt");
// 创建文件系统数据字节输入流(进水管:数据从文件到程序)
FSDataInputStream in = fs.open(path);
// 创建缓冲字符输入流,提高读取效率(字节流-->字符流-->缓冲流)
BufferedReader br = new BufferedReader(new InputStreamReader(in));
// 定义行字符串变量
String nextLine = "";
// 通过循环遍历缓冲字符输入流
while ((nextLine = br.readLine()) != null) {
// 在控制台输出读取的行
System.out.println(nextLine);
}
// 关闭缓冲字符输入流
br.close();
// 关闭文件系统数据字节输入流
in.close();
// 关闭文件系统
fs.close();
}
}
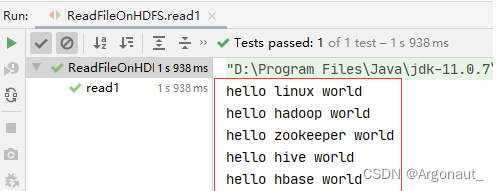
- 运行read1()测试方法,查看结果
(2)读取HDFS文件,保存为本地文件 - 任务:将/ied01/test.txt下载到项目的download目录里
- 创建download目录
- 创建read2()方法
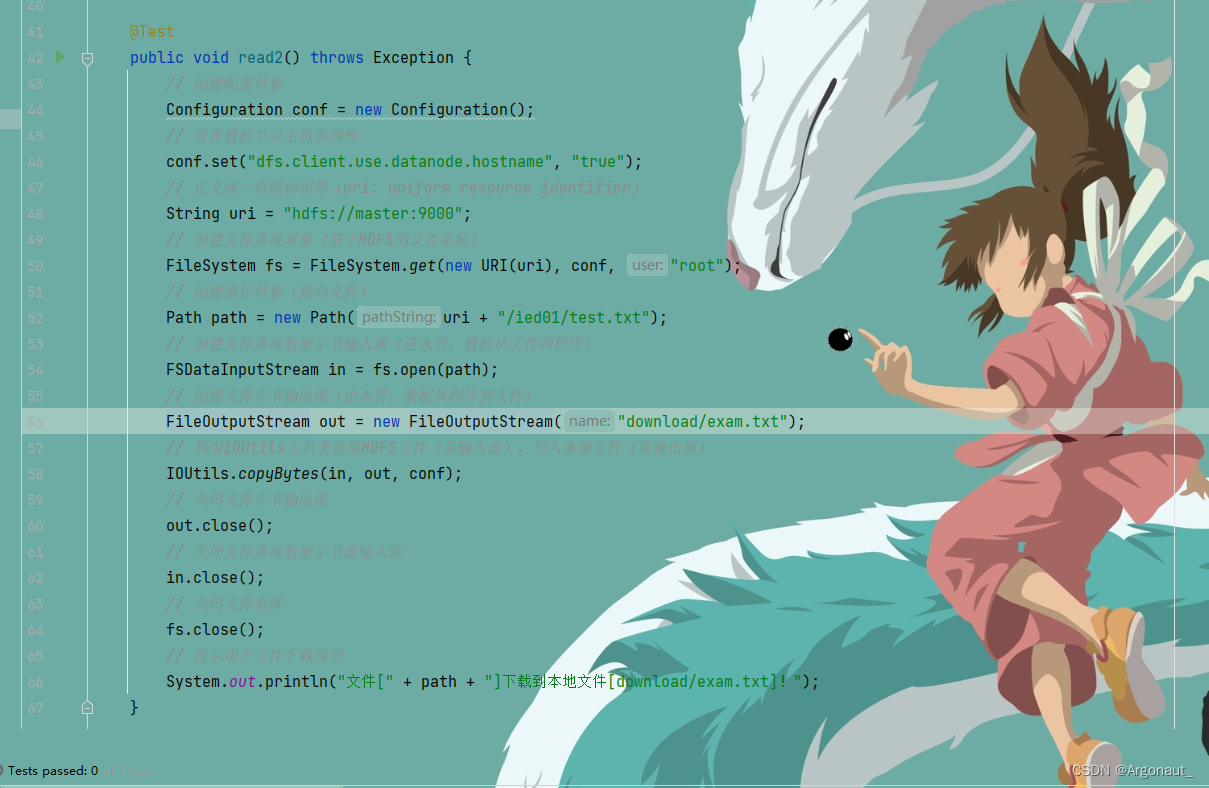
@Test
public void read2() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/ied01/test.txt");
// 创建文件系统数据字节输入流(进水管:数据从文件到程序)
FSDataInputStream in = fs.open(path);
// 创建文件字节输出流(出水管:数据从程序到文件)
FileOutputStream out = new FileOutputStream("download/exam.txt");
// 利用IOUtils工具类读取HDFS文件(靠输入流),写入本地文件(靠输出流)
IOUtils.copyBytes(in, out, conf);
// 关闭文件字节输出流
out.close();
// 关闭文件系统数据字节流输入流
in.close();
// 关闭文件系统
fs.close();
// 提示用户文件下载成功
System.out.println("文件[" + path + "]下载到本地文件[download/exam.txt]!");
}
- 运行read2()测试方法,查看结果

8、重命名目录或文件
- 相当于Shell里的hdfs dfs -mv命令
- 在net.hw.hdfs包里创建RenameDirOrFile类
(1)重命名目录 - 任务:将/ied01目录更名为/lzy01
- 编写renameDir()方法
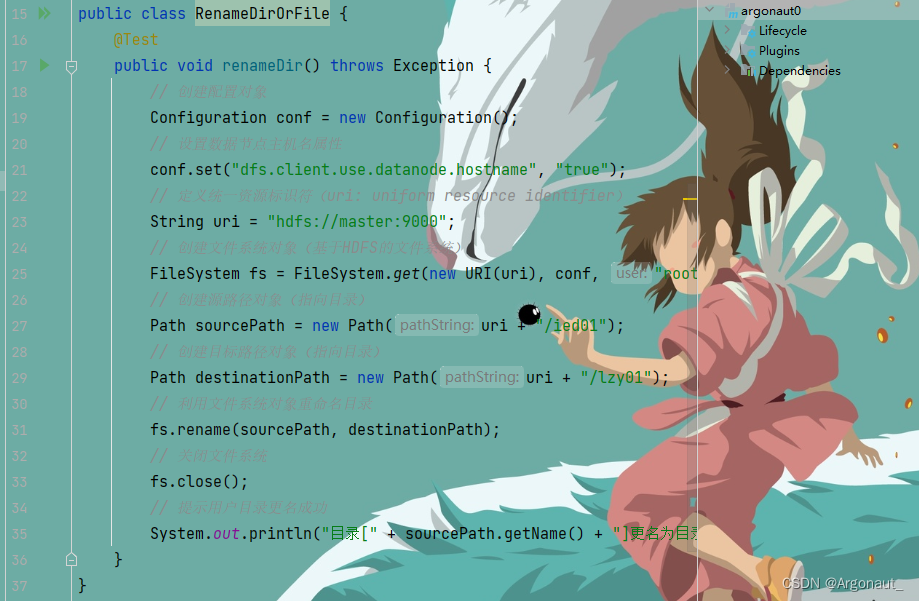
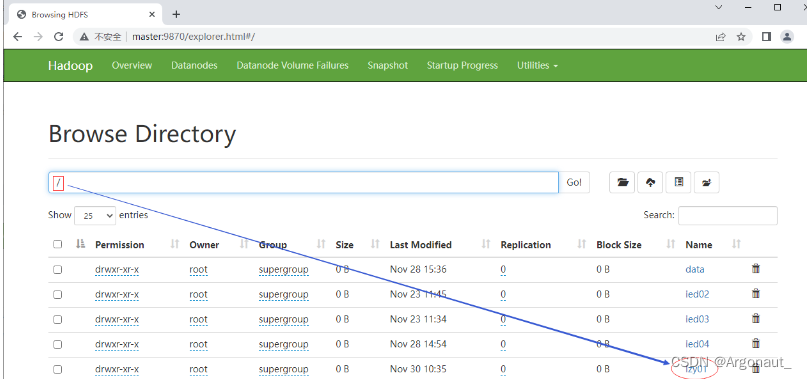
- 运行renameDir()方法,查看结果

- 利用Hadoop WebUI界面查看
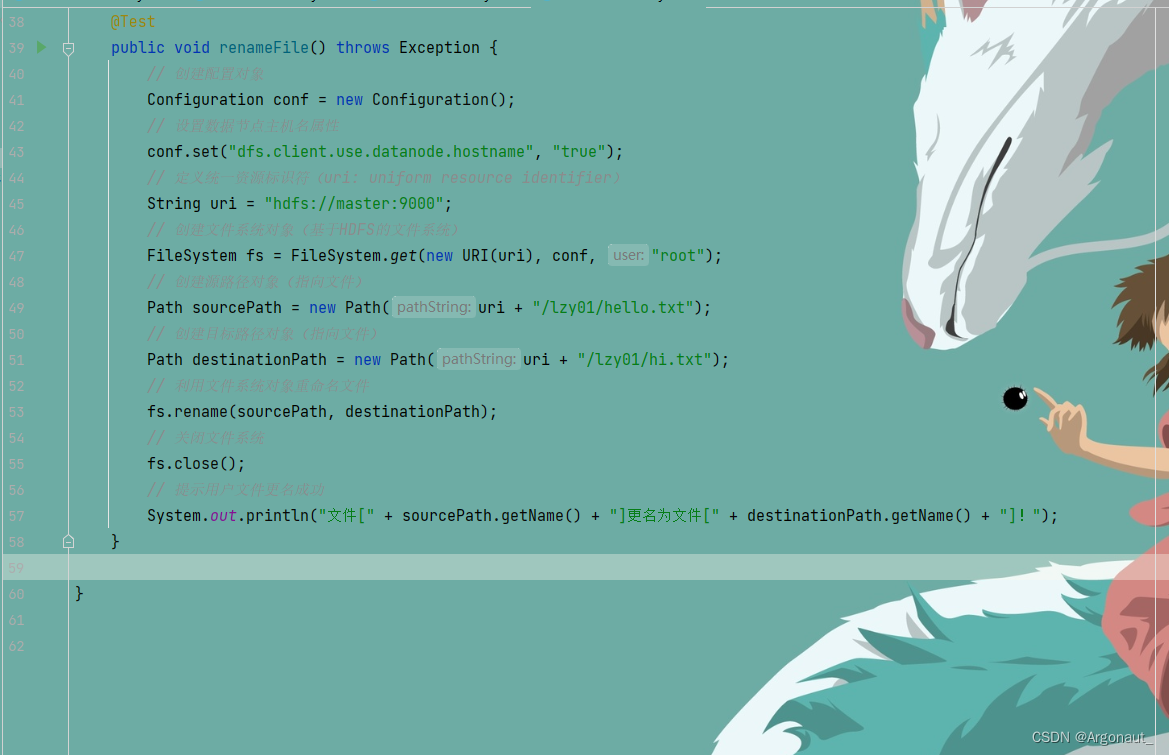
(2)重命名文件 - 任务:将lzy01目录下的hello.txt重命名为hi.txt
- 编写renameFile()方法
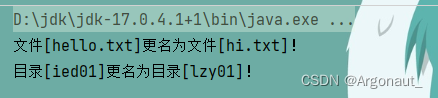
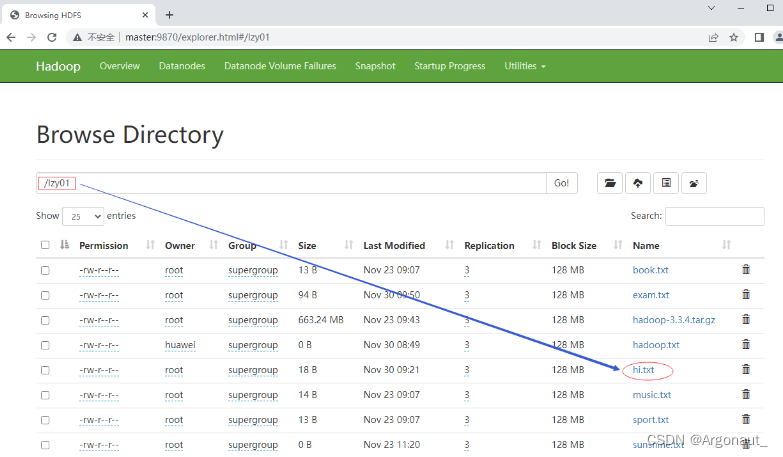
- 运行renameFile()测试方法,查看结果
9、显示文件列表
- 在net.hw.hdfs包里创建ListHDFSFiles类
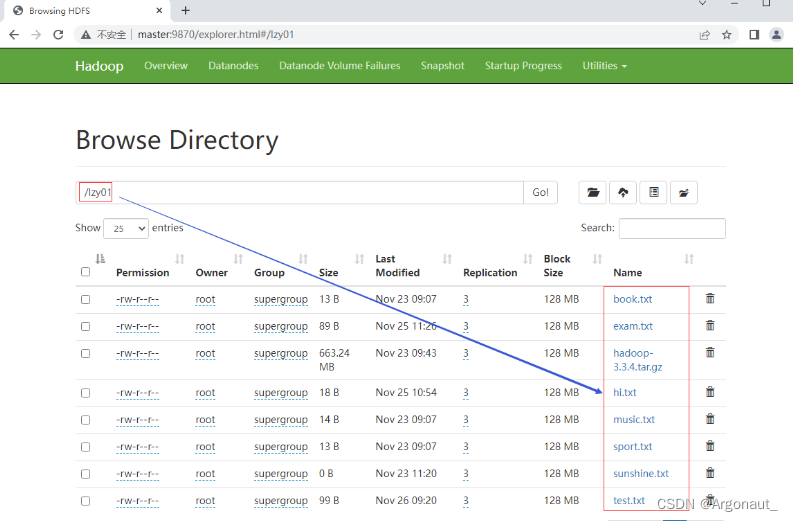
(1)显示指定目录下文件全部信息 - 任务:显示/lzy01目录下的文件列表
- 编写list1()方法
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Test;
import java.net.URI;
/**
* 功能:显示文件列表
* 作者:Argonaut
* 日期:2022年11月26日
*/
public class ListHDFSFiles {
@Test
public void list1() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建远程迭代器对象,泛型是位置文件状态类(相当于`hdfs dfs -ls -R /lzy01`)
RemoteIterator<LocatedFileStatus> ri = fs.listFiles(new Path("/lzy01"), true);
// 遍历远程迭代器
while (ri.hasNext()) {
System.out.println(ri.next());
}
}
}
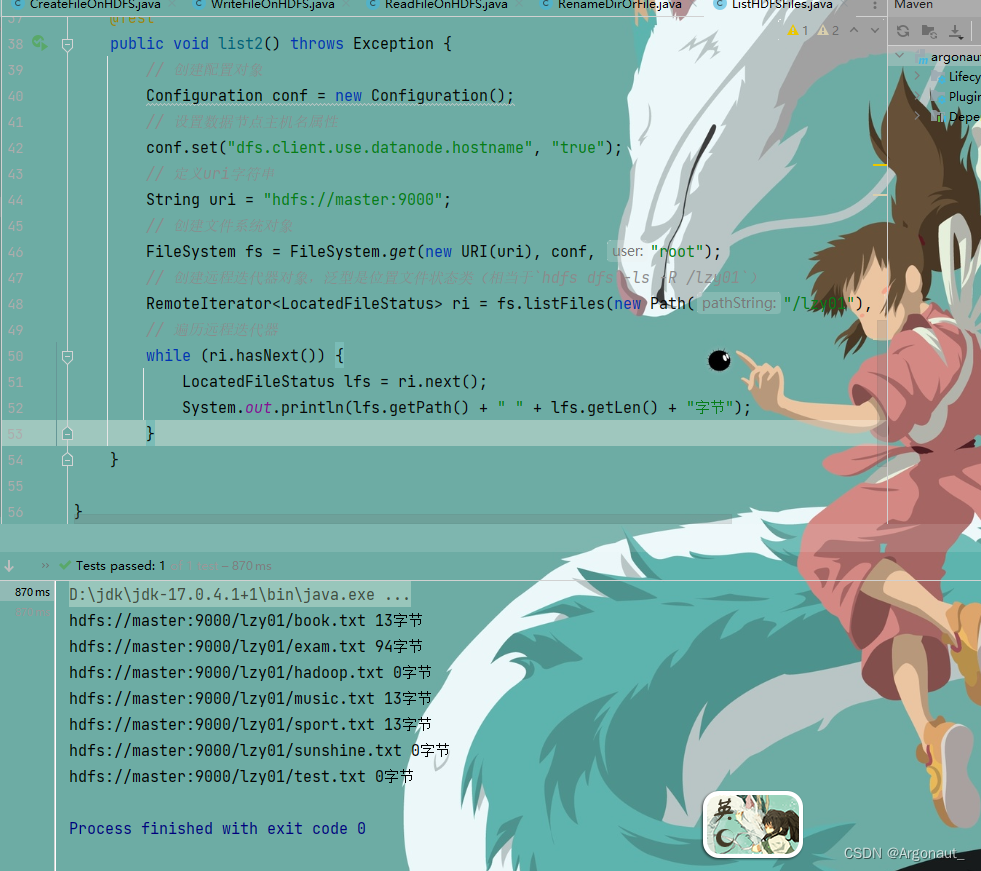
- 文件系统对象的listFiles()方法第二个参数设置true,这样可以将/lzy01目录的一切文件,包括子目录里的文件,都一网打尽
- 运行list1()测试方法,查看结果

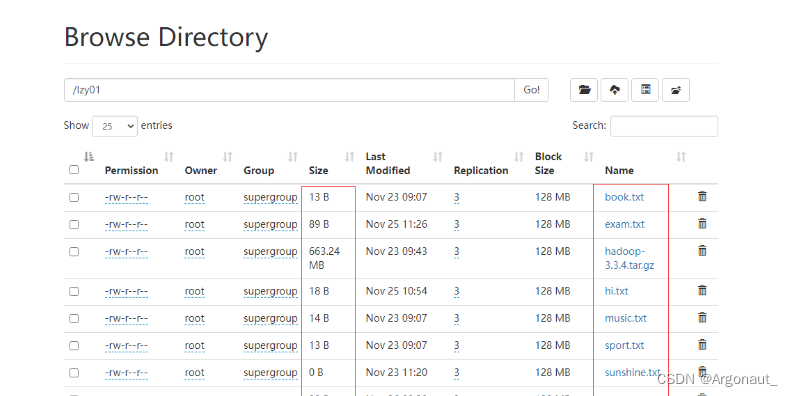
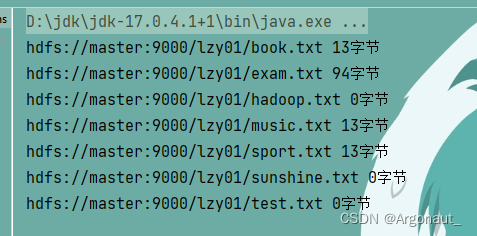
- 上述文件状态对象封装的有关信息,可以通过相应的方法来获取,比如getPath()方法就可以获取路径信息,getLen()方法就可以获取文件长度信息……
(2)显示指定目录下文件路径和长度信息
- 编写list2()方法
10、获取文件块信息
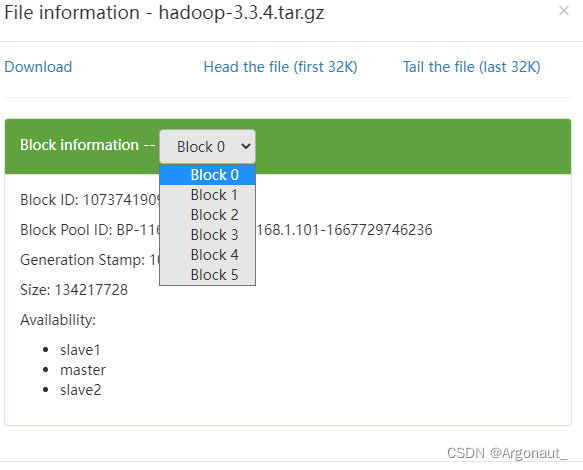
- 任务:获取/lzy01/hadoop-3.3.4.tar.gz文件块信息
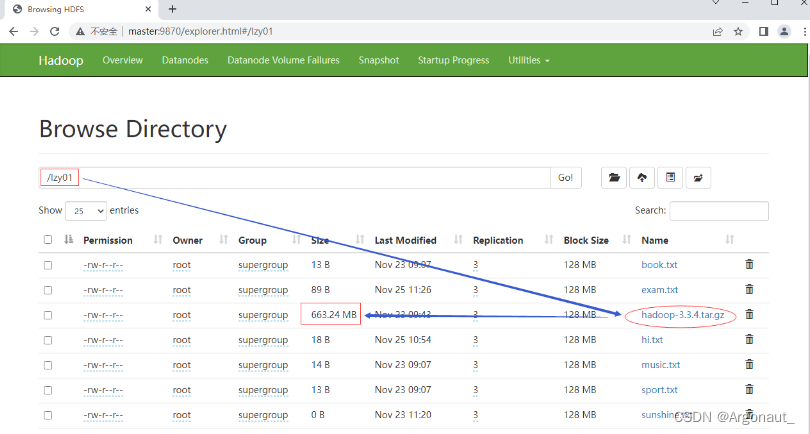
- hadoop压缩包会分割成6个文件块
- 在net.hw.hdfs包里创建GetBlockLocations类
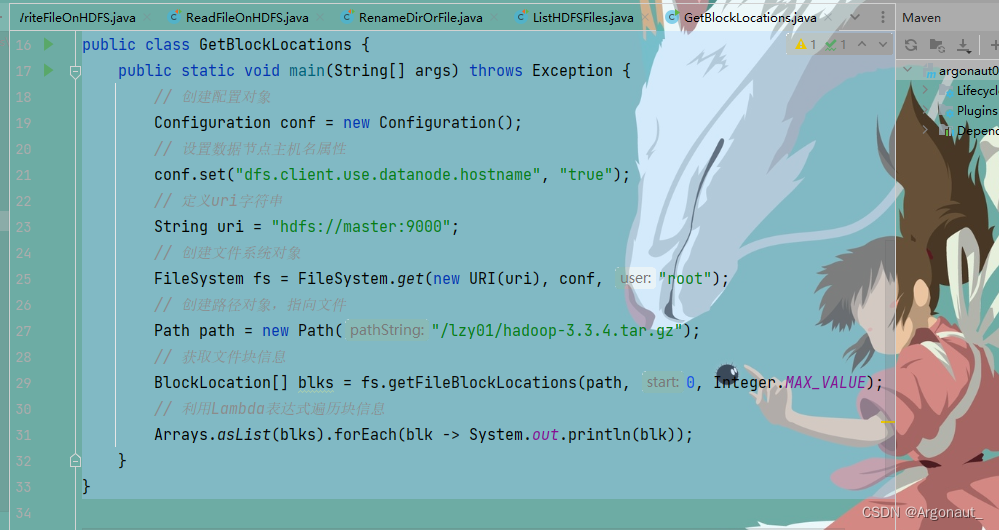
- 编写代码,获取文件块信息
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.Arrays;
/**
* 功能:获取文件块信息
* 作者:Argonaut
* 日期:2022年11月26日
*/
public class GetBlockLocations {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象,指向文件
Path path = new Path("/lzy01/hadoop-3.3.4.tar.gz");
// 获取文件块信息
BlockLocation[] blks = fs.getFileBlockLocations(path, 0, Integer.MAX_VALUE);
// 利用Lambda表达式遍历块信息
Arrays.asList(blks).forEach(blk -> System.out.println(blk));
}
}
- 大家可以尝试用传统for循环、增强for循环或迭代器来遍历块信息
// 利用增强for循环遍历块信息
for (BlockLocation blk : blks) {
System.out.println(blk);
}
// 利用传统for循环遍历块信息
for (int i = 0; i < blks.length; i++) {
System.out.println(blks[i]);
}
// 利用迭代器遍历块信息
Iterator<BlockLocation> iterator = Arrays.asList(blks).iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
- 运行程序,查看结果(切点位置,块大小,块存在位置)
11、创建目录
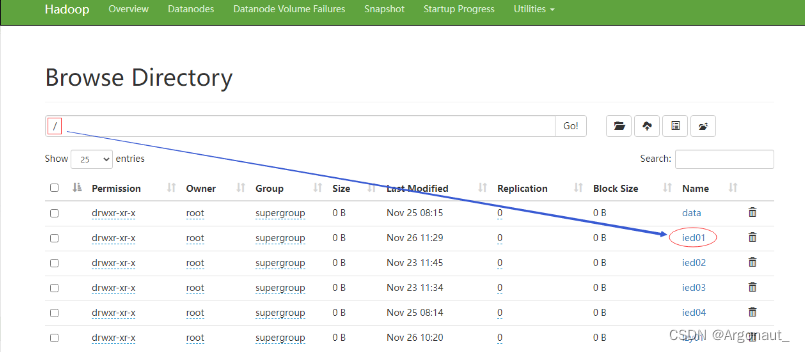
- 任务:在HDFS上创建/ied01目录
- 在net.hw.hdfs包里创建MakeDirOnHDFS类
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
/**
* 功能:在HDFS上创建目录
* 作者:Argonaut
* 日期:2022年11月26日
*/
public class MakeDirOnHDFS {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象,指向目录
Path path = new Path("/ied01");
// 利用文件系统创建指定目录
boolean result = fs.mkdirs(path);
// 判断目录是否创建成功
if (result) {
System.out.println("目录[" + path + "]创建成功!" );
} else {
System.out.println("目录[" + path + "]创建失败!" );
}
}
}
12、判断目录或文件是否存在
- 任务:判断HDFS上/ied01目录是否存在,判断/ied01/hadoop.txt文件是否存在
- 在net.hw.hdfs包里创建DirFileExistsOrNot类
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.net.URI;
/**
* 功能:判断目录或文件是否存在
* 作者:Argonaut
* 日期:2022年11月26日
*/
public class DirFileExistsOrNot {
@Test
public void dirExists() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象,指向目录
Path path = new Path("/ied01");
// 判断目录是否存在
if (fs.exists(path)) {
System.out.println("目录[" + path + "]存在!");
} else {
System.out.println("目录[" + path + "]不存在!");
}
}
}

- 编写fileExists()方法

13、判断Path指向目录还是文件
- 在net.hw.hdfs包里创建PathToFileOrDir类
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
/**
* 功能:判断路径指向目录还是文件
* 作者:Argonaut
* 日期:2022年11月26日
*/
public class PathToFileOrDir {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象,指向目录
Path path1 = new Path("/ied08");
if (fs.isDirectory(path1)) {
System.out.println("[" + path1 + "]指向的是目录!");
} else {
System.out.println("[" + path1 + "]指向的是文件!");
}
// 创建路径对象,指向文件
Path path2 = new Path("/lzy01/howard.txt");
if (fs.isFile(path2)) {
System.out.println("[" + path2 + "]指向的是文件!");
} else {
System.out.println("[" + path2 + "]指向的是目录!");
}
}
}
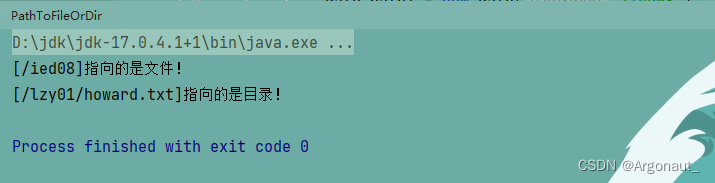
- 结果明显不对,说明程序逻辑上有问题,原因在于/ied08目录不存在,/lzy01/howard.txt文件不存在,修改代码,加上目录或文件存在与否的判断
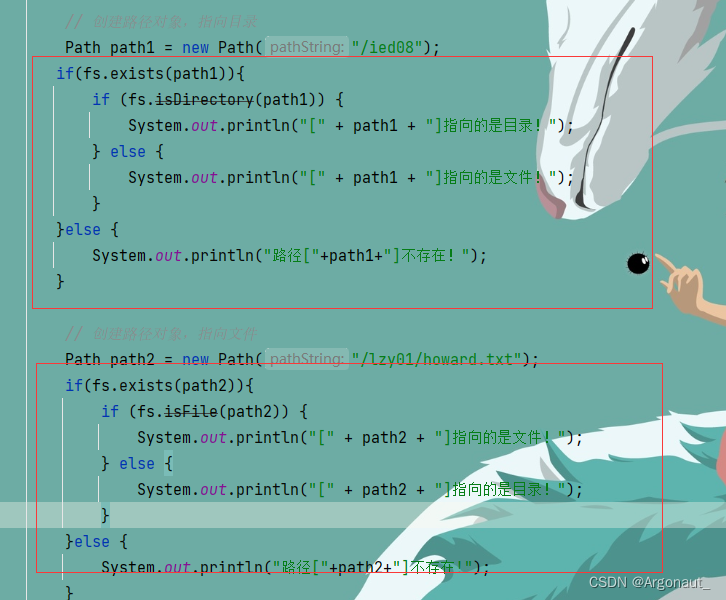

14、删除目录或文件
- 类似于HDFS Shell里的hdfs dfs -rmdir和hdfs dfs -rm -r命令
- 在net.hw.hdfs包里创建DeleteFileOrDir类
(1)删除文件
任务:删除/lzy01/hi.txt文件
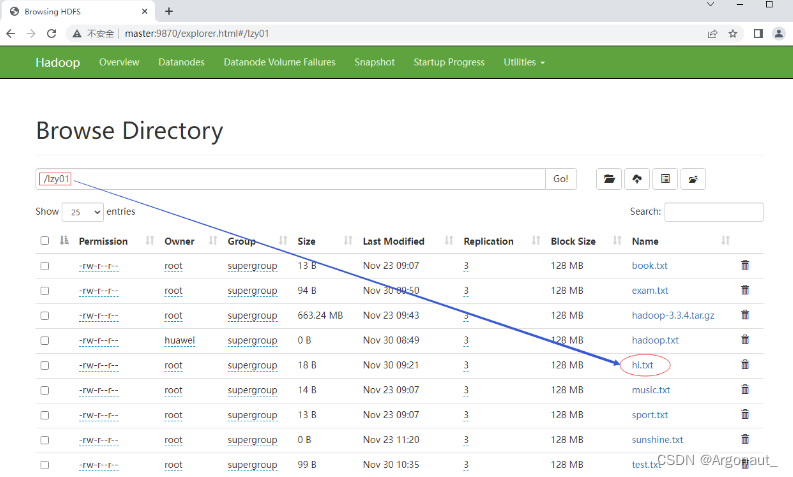
- 编写deleteFile()方法
package net.at.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.net.URI;
/**
* 功能:删除目录或文件
* 作者:Argonaut
* 日期:2022年12月02日
*/
public class DeleteFileOrDir {
@Test
public void deleteFile() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/lzy01/hi.txt");
// 删除路径对象指向的文件(第二个参数表明是否递归,删除文件,不用递归)
boolean result = fs.delete(path, false);
// 根据返回结果提示用户
if (result) {
System.out.println("文件[" + path + "]删除成功!");
} else {
System.out.println("文件[" + path + "]删除失败!");
}
}
}
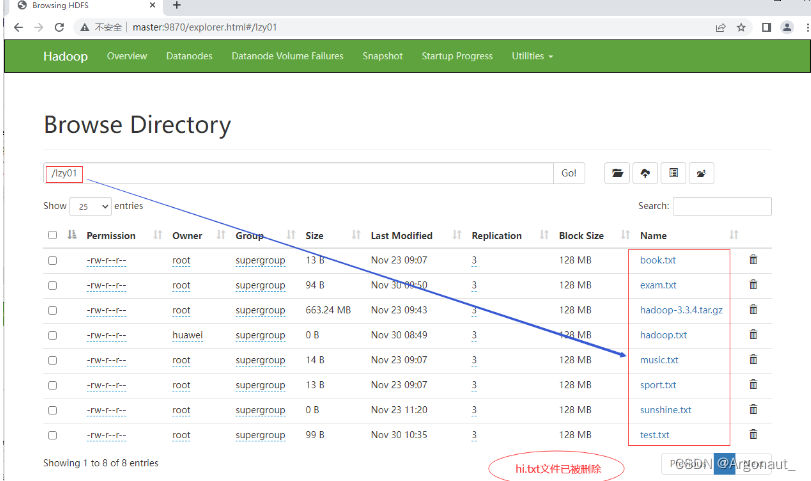
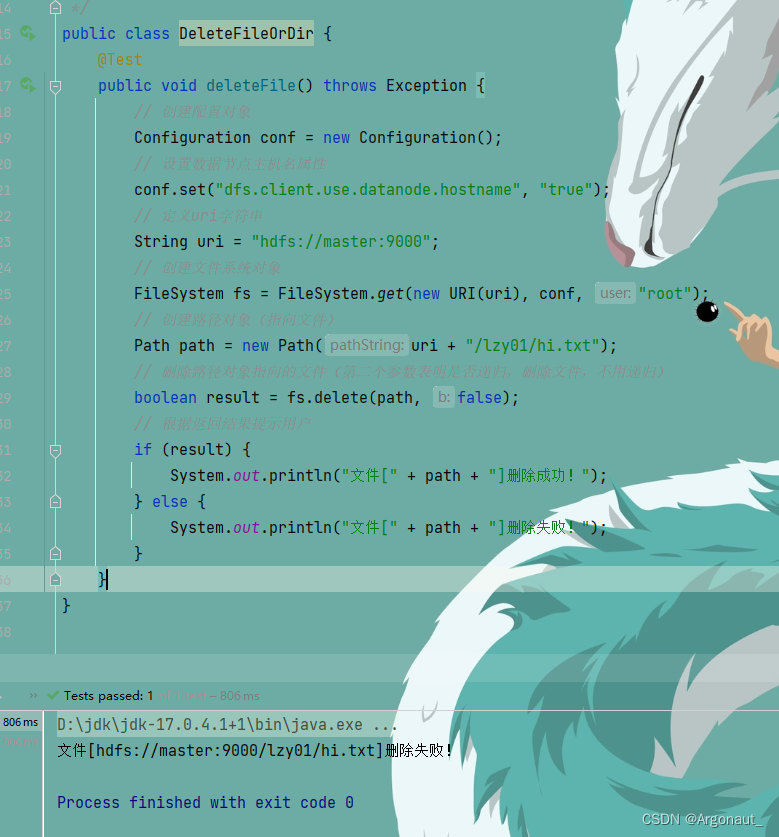
- 再运行deleteFile()测试方法,查看结果

- 可以在删除文件之前,判断文件是否存在,需要修改代码

(2)删除目录 - 任务:删除/lzy01目录
- 编写deleteDir()方法
@Test
public void deleteDir() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向目录)
Path path = new Path(uri + "/lzy01");
// 判断路径对象指向的目录否存在
if (fs.exists(path)) {
// 删除路径对象指向的目录(第二个参数表明是否递归,删除文件,要递归)
boolean result = fs.delete(path, true);
// 根据返回结果提示用户
if (result) {
System.out.println("目录[" + path + "]删除成功!");
} else {
System.out.println("目录[" + path + "]删除失败!");
}
} else {
System.out.println("目录[" + path + "]不存在!");
}
}


(3)删除目录或文件
- 进行三个层面的判断:判断是否存在、判断类型(目录或文件)、判断删除是否成功
- 任务:删除/ied02/exam.txt文件和/lzy01目录
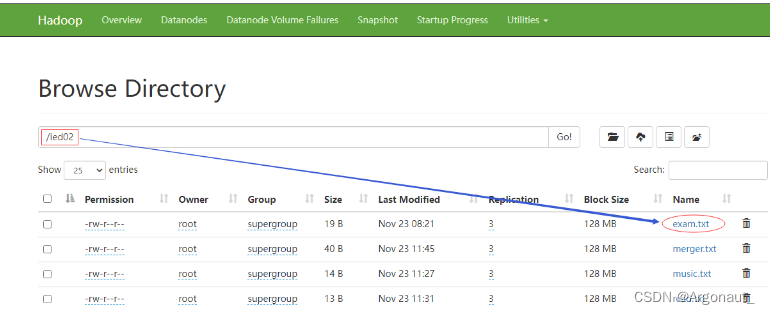
- 编写delete()方法
@Test
public void delete() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建文件系统对象
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 定义随机对象
Random random = new Random();
// 产生随机整数 - [0, 1]
int choice = random.nextInt(100) % 2;
// 定义路径字符串
String[] strPath = {"/ied02/exam.txt", "/lzy01"};
// 创建路径对象(指向目录或文件)
Path path = new Path(uri + strPath[choice]);
// 判断存在性
if (fs.exists(path)) {
// 判断类型:目录或文件
String type = "";
if (fs.isDirectory(path)) {
type = "目录";
} else {
type = "文件";
}
// 删除路径对象指向的目录或文件
boolean result = fs.delete(path, true);
// 判断删除是否成功
if (result) {
System.out.println(type + "[" + path + "]删除成功!");
} else {
System.out.println(type + "[" + path + "]删除失败!");
}
} else {
System.out.println("路径[" + path + "]不存在!");
}
}

![[附源码]Python计算机毕业设计Django基于vuejs的文创产品销售平台app](https://img-blog.csdnimg.cn/ddbd8c46ee864865b2b36ed38068a20e.png)