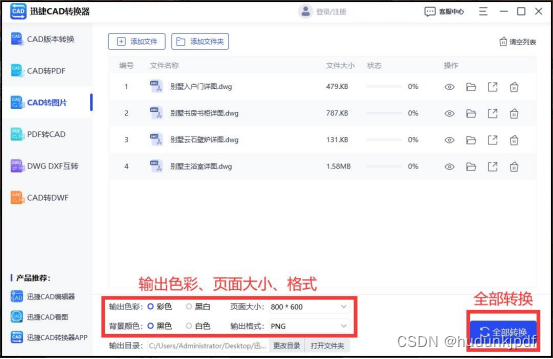
昨天发的《量子论公众号是如何半年做到10000粉的?》,好像没人感兴趣,那以后不发此类话题了。
今天的内容也是翻看Hacker News上的帖子里发现的。
近期,OpenAI官网介绍了一款新产品GPTBot。可是,这款产品对我们没什么用,它是给OpenAI自己使用的。
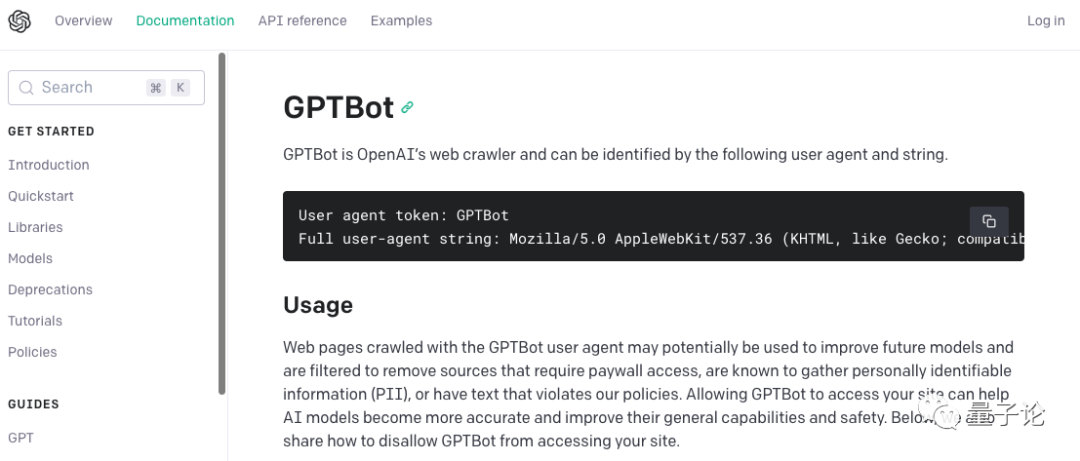
官网上挂个说明,可能是为了宣布有这么个事,如果你感到权益受损,可以按文档中的操作进行阻止。
GPTBot其实是一个网络爬虫。
网络爬虫,有时称为网络蜘蛛,是一种为互联网上的网站内容编制索引的机器人。
像谷歌百度这样的搜索引擎会使用它们,以便网站显示在搜索结果中。
OpenAI表示,网络爬虫将从互联网上收集公开可用的数据,但会过滤掉需要付费内容的来源,或者已知收集个人身份信息的来源,或者包含违反其政策的文本。
GPTBot可用来抓取海量数据训练和优化未来的AI模型。不少国外科技媒体八卦认为,这个未来的AI模型剑指GPT-5。
上个月,OpenAI提交了GPT-5商标申请,此时又放出这个网络爬虫,确实可以联想出,GPT-5离我们越来越近了。
OpenAI已公开GPTBot的IP地址,网站所有者除了可以通过向服务器上的标准文件添加“disallow”命令来拒绝GPTBot访问外,还能以IP地址为单位阻止GPTBot的访问。

此前,OpenAI抓取公开数据来训练专利AI模型的行为备受争议。
Reddit和Twitter等网站已经采取措施拒绝AI公司免费使用其网站内容的行为,还有一些作者和其他创作者也因为AI公司涉嫌未经授权使用其作品而提起了诉讼。
ChatGPT今日宣布推出6大新功能,体验效果更佳
AI在抢饭碗!澳洲最大报业集团启用AI每周自动生成新闻3000篇
香港岭南大学已为全校购买ChatGPT许可证,并对师生提供培训
GPTBot文档链接:
https://platform.openai.com/docs/gptbot