MySQL索引总结
1.索引的概念、作用与使用场景
本质上就是减少读写磁盘的次数。
索引是一种特殊的文件,包含这对数据表中所有记录的引用指针,可以对表中的一列或多列创建索引,并指定索引的类型,每种类型都有对应数据结构实现。
- 加快查找速度(常用数据库操作是增删改查,但是查是最常见的)
- 增加了增删改的开销(调整时还需要调整目录)
- 增加了空间的开销(还需要额外的空间保存索引)
一般对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量比较大并且经常对他们进行条件查询
- 这些表的插入操作和这个列的修改频率较低
- 索引占用的额外空间
注意:加上索引不一定快
当数据量很少,一行一行查可能会更快;
另外,如果对大量重复数据加索引,也是无法提高查询速度。例如都是性别字段,大学里的年级字段
索引创建好之后,不需要手动创建,直接查询的时候就会自动走索引。
SQL是通过数据库的执行引擎来执行的,执行引擎会自动评估,哪种方案是成本最低的,速度最快的。
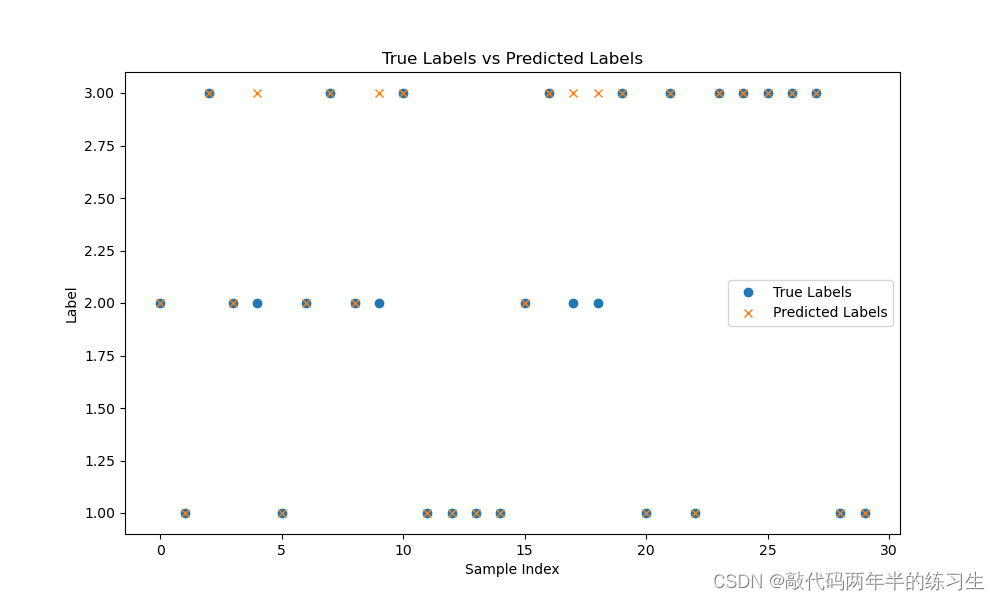
具体某次查询是走的索引还是不走,可以通过explain关键字显示查询过程中具体情况。不过,使用比较简单,复杂的是分析(暂存疑问:怎么分析explain执行的结果)
//eg: explain select * from student;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aFmCFOT1-1692010130477)(F:\typora插图\image-20230813140952527.png)]](https://img-blog.csdnimg.cn/130976da39be411dbdfb5273d66c4134.png)
2.索引的使用方法
查看索引
show index from 表名;
容易发现,我们并未手动添加索引,但是也能查询的到:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cvnEKklZ-1692010130478)(F:\typora插图\image-20230813134427973.png)]](https://img-blog.csdnimg.cn/af1c6ecbe3b84d99b58ba4fe17aa5145.png)
这是因为创建主键约束,唯一约束和外键约束时,数据库会自动创建对应列的索引。
创建索引
针对非主键非唯一约束非外键字段,可以创建普通索引:
create index 索引名 on 表名;
注意:创建索引最好是在创建表的时候就把索引弄好。否则,如果针对一个可能有很多记录的表创建索引是一个危险操作。中途创建可能吃掉大量磁盘io,花掉很长时间,这段时间数据库是不能正常使用的。
例如:针对学生姓名创建索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rUJA3YxN-1692010130478)(F:\typora插图\image-20230813135007596.png)]](https://img-blog.csdnimg.cn/4be994d9b52445028a42d11c3cae0d4e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fI8WTB3P-1692010130479)(F:\typora插图\image-20230813135034453.png)]](https://img-blog.csdnimg.cn/e96c5ef8772b4473b2b3f397f06116de.png)
删除索引
drop index 索引名 on 表名;
注意:删除索引也可能吃掉大量磁盘IO,也是比较危险的操作
例如:删除刚刚创建的索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Mu9FeA3-1692010130479)(F:\typora插图\image-20230813135943128.png)]](https://img-blog.csdnimg.cn/520fe35f0f984d289619dbc6d0b7c508.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bsTLRts3-1692010130479)(F:\typora插图\image-20230813140022915-16919064235821.png)]](https://img-blog.csdnimg.cn/fd4d5bfe64b543cdad0d8641a64dc5ab.png)
3.索引在MySQL中数据结构
索引本质是就是通过已知信息查找相关完整信息,那么我们知道的数据结构中关于查找的有哈希表、二叉搜索树、N叉搜索树和B+树。
但MySQL中InnoDB引擎中使用的是B+树。
为什么这个数据引擎不使用前三种?下边是可能的考量因素:
Why not
哈希表
哈希表是一种查询开销为O(1)的数据结构,但是哈希表不适合做数据库的索引。
因为哈希表只能比较相等,而不能进行><这样的范围查询,而进行数据库查询时经常会有这样的场景,例如查找id大于0小于10的用户信息。
二叉搜索树
二叉搜索树的前序遍历是有序的,可以进行范围查询,但是因为当二叉搜索树元素个数很多或者节点分布不均匀时,树的高度就会比较高,对应的时间复杂度就可能达到O(N),元素比较的次数就会比较多,而数据库进行比较都是要读硬盘的,这样效率就会比较低。
N叉搜索树
顾名思义,N叉搜索树就是每个节点最多有N个孩子节点的搜索树,分叉变多,树的高度是降下来了。其中最典型的实现就是B树
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iXn30Aai-1692010130479)(F:\typora插图\image-20230814151349302.png)]](https://img-blog.csdnimg.cn/15e6dec893464d5ba680636acb9ab79d.png)
因为节点是存储在硬盘上的,如果采用B树的方式存索引的话,树的高度降低,比较的次数虽然没有显著减少,一个节点可能需要比较多次,但是读写硬盘的次数能减少。
但是MySQL中没有使用B树,因为实际开发中对性能的要求比较高,所以使用的就是B+树。
Why B+树
B+树也是一个N叉搜索树,是B树的plus版本。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-72Pf5NdD-1692010130480)(F:\typora插图\image-20230814152634595.png)]](https://img-blog.csdnimg.cn/8bfee95620a24e1599cc16d1d2ef20f9.png)
它具有以下特点:
- 每个节点可能存在N个key,N个key值划分出N个区间,最后一个key就是当前区间的右边界,也就是最大值
- 父元素的key值会在子元素中重复出现,并且是以最大值的姿态出现的。这样的重复出现就会使得叶子结点中包含所有数据的全集,非叶子结点的所有值都会在叶子结点中体现出来。
- 叶子结点会以类似于链表连接起来。
这些特点使得B+树具有相较于前边几种数据结构不具有的优势
- 更适合范围查询
- 树的高度降下来之后,比较的次数减少,磁盘IO的次数也就减少了
- 每个数据查询的时间开销比较均匀。因为所有的查询都是要落在叶子结点上的,所以不管查询那个数据,比较的次数都差不多。
- 空间开销会减少。由于所有的key都会在叶子结点中体现,所以非叶子节点中并不需要存储真实的数据行,只需要存储索引的值,而数据行存储在叶子结点上。这样当数据量非常大的时候,成本可以降低。
因此,既可以满足MySQL索引的功能需求也能满足它的性能要求,所以用B+树做MySQL的索引的数据结构
无索引和多索引的情况
无索引的时候,应该是以表的形式组织表这样的结构的
单索引的时候很大概率是以上述的B+树进行组织的,以学生表为例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8cEjoBDr-1692010130480)(F:\typora插图\image-20230814155321980.png)]](https://img-blog.csdnimg.cn/44ee8d3e808c4b41aec0c8097b463a51.png)
而多索引时会创建多个B+树,以学生表中有主键索引和姓名索引(自定义索引)为例。
这时会构造两个B+树,一个是类似上边的通过主键创建B+树,叶子结点是真实的数据行,另一个是通过自定义索引创建B+树,叶子结点是主键id。因此通过非主键列查询数据行的时候,会先查一遍索引列的B+树,再查一遍主键列的B+树。这个操作叫做回表。
提醒
关于索引,建议在最开始的时候就规划好,如果是已经有大量数据,再进行操作,就需要慎重考虑!!!
是真实的数据行,另一个是通过自定义索引创建B+树,叶子结点是主键id。因此通过非主键列查询数据行的时候,会先查一遍索引列的B+树,再查一遍主键列的B+树。这个操作叫做回表。