来源:投稿 作者:TransforMe
编辑:学姐
贡献
在长尾识别任务上,解耦(二阶段)的方法取得了巨大的进步,详情参考https://blog.csdn.net/weixin_41246832/article/details/115718084。本文详细分析了解耦的方法, 针对存在的两个问题进行改进,提出了Mixup Shifted Label-Aware Smoothing model (MiSLAS),该方法包括标签平滑和迁移BN两种方案。
问题
Confidence calibration
实验观察到网络在长尾数据集会产生校准错误和过度自信问题。如图所示,在CIFAR100-LT数据集上统计的可靠性图。
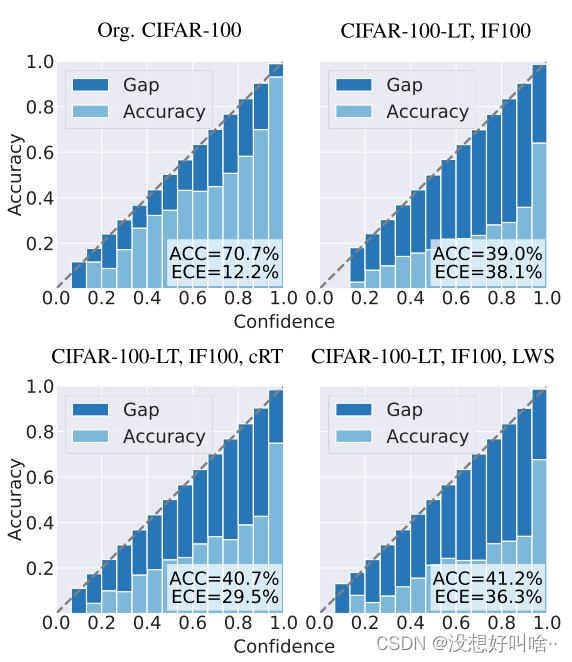
横坐标表示置信度,纵坐标表示准确率。其中ECE表示准确率和置信度的差异。具体公式为:

可靠性图可以较好的评估模型得到的概率是否合理,理论上最好的模型ECE为0。图中可见,网络在长尾数据集上都有较高的ECE,其中解耦的方法cRT和LWS也存在同样的问题。
Domain shift
另一个问题在于使用解耦方法训练网络时,由于两阶段的数据采样方式不同,导致两个阶段的数据集分布不同。本文通过改变BN层解决这个问题。
方法
前人研究表明mixup技术可以很好地增强网络的对齐能力(减少ECE)。因此,在解耦方法中验证mixup的作用。
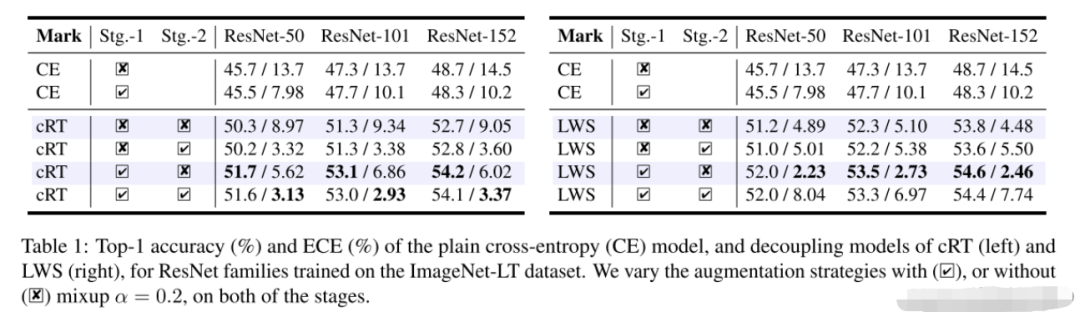
可以发现:
-
在第一阶段使用mixup对CE的精度无影响,ECE略有下降。
-
在第一阶段使用mixup对解耦的方法精度有所提升,ECE也减少了。
-
在第二阶段使用mixup对模型的精度无影响,对cRT来说ECE下降了,但LWS的ECE却上升了。
综上,可以得出结论:mixup确实促进了模型的表示学习,但是对分类器的学习无用。
进一步,我们观察mixup对分类器范数的影响。
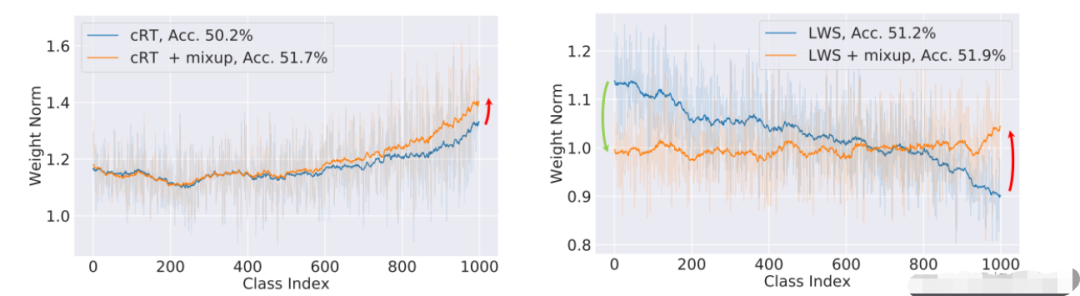
图中类别按照样本数降序排列,可见使用mixup时尾部类的范数更大,mixup对尾部类别分类更友好。
Label-aware Smoothing
由于头部类别有大量的样本,在使用CE训练时分类器更倾向于头部类,导致头部的分类器权值范数更大。如图3上方浅蓝色所示,头部类的概率都接近1,而尾部类概率最小,因此我们提出标签平滑来解决交叉熵过度自信和预测概率分布变化的问题。如图3下方深蓝色所示,使用标签平滑后头部的预测概率明显下降,而且尾部预测概率有所提升。
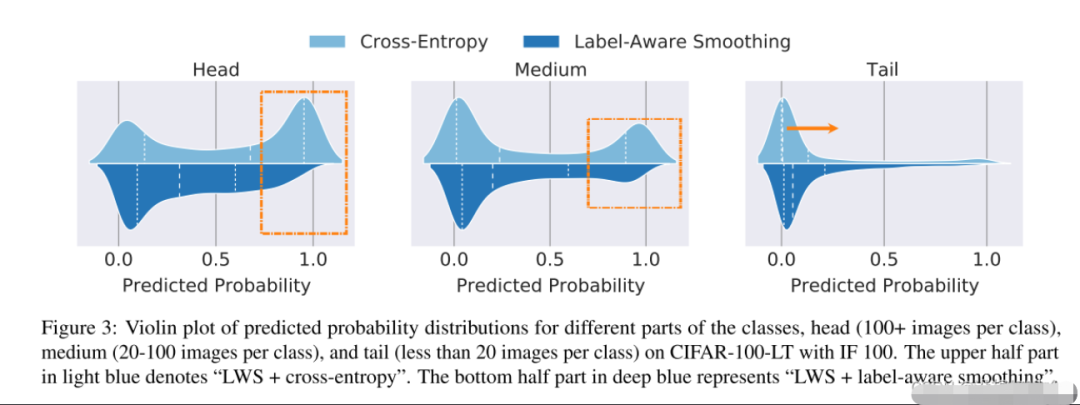
具体来说,我们在计算CE时,对真实标签加上一个很小的平滑系数,这样可以降低过度头部类的自信,并提升尾部类的概率。
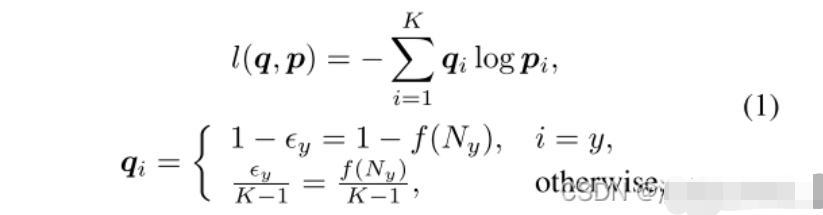
如公式1所示,ε表示为一个很小的数,当分类正确时的值接近但不等于1。当分类错误时,的值接近但大于0。同时本文设计了三种可变的ε(),可以使得ε的值与样本数正相关,即样本数越大惩罚越大。
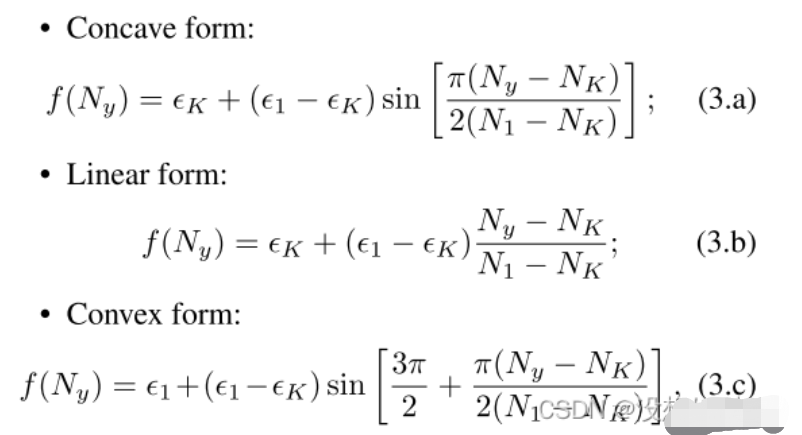
从分类器角度出发,我们提出了一个更通用的分类器学习框架。
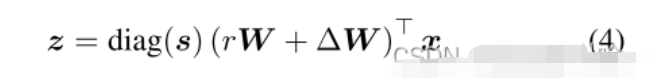
当且时,公式等同于cRT方法。当且时,公式等同于LWS方法。本实验将和设置为可学习参数,固定,相当于结合了cRT和LWS两种方法,既可以改变原表征学习参数,又可以同时成比例放大或缩小参数。
Shift Learning on Batch Normalization
由于两阶段的数据分布不同,我们更新一个batch的均值µ和方差σ,并固定了可学习的线性转换参数α和β,以便在阶段2中更好地规范化。
实验
SOTA
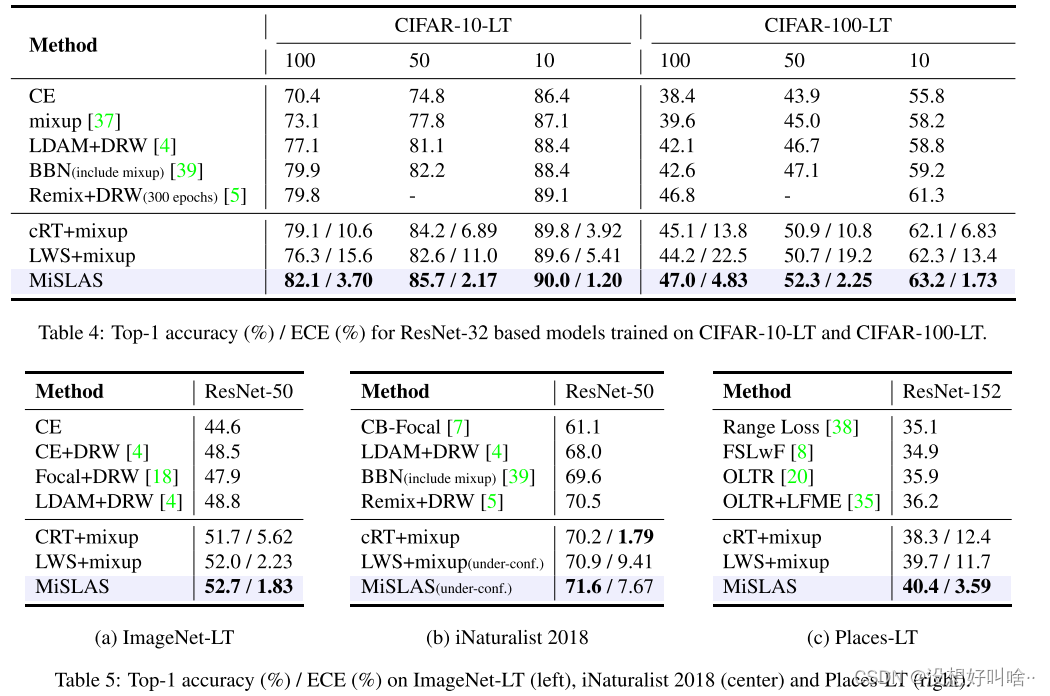
如图所示,MiSLAS方法在五个数据集上都取得了sota的效果,并且大多有较小的ECE。
消融实验

-
MU 代表Mixup;
-
SL 代表BN的迁移(shift learning on BN);
-
LAS 代表标签平滑,上下两块分别代表ACC和ECE。
消融实验证明了每个模块都能提升性能并减少ECE。
总结
在第一阶段使用mixup并平滑标签以得到更好的特征表示,在第二阶段在表征模型中仅改变BN的均值和方差,以此提升模型的性能。
方法简单有效,从ECE的角度切入,实验充分,并做了大量的实验验证各个模块的有效性,包含各种类型的图表且行文通顺易读。
220+篇论文解读免费领👇👇👇点击卡片关注

![P3884 [JLOI2009]二叉树问题——树化图Floyd+dfs](https://img-blog.csdnimg.cn/img_convert/88dd83b356031d1d877bafebad61c922.png)
![[附源码]Python计算机毕业设计Django高校体育场馆管理系统](https://img-blog.csdnimg.cn/a1e2e49d3625467e99151179bc8873b0.png)








![[Java] 什么是锁?什么是并发控制?线程安全又是什么?锁的本质是什么?如何实现一个锁?](https://img-blog.csdnimg.cn/0ba3e5c3c358440ea9ef7abae632bc8e.png)