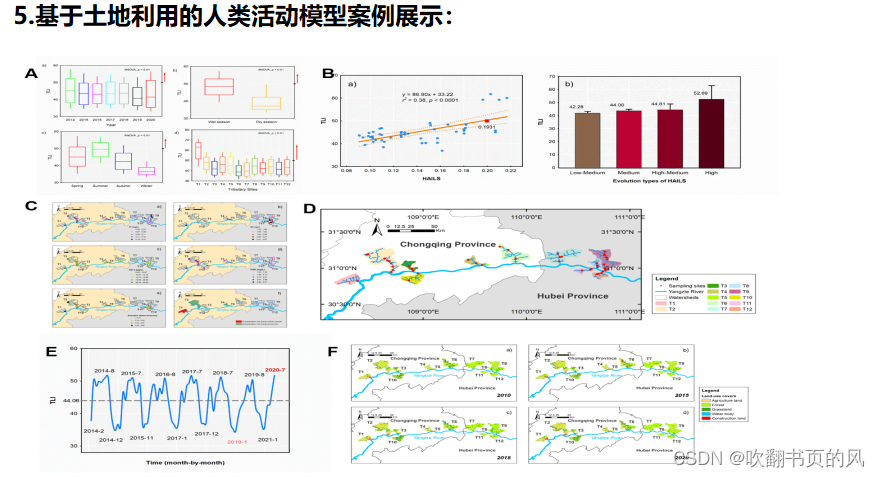
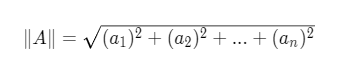今天继续给大家介绍Python相关知识,本文主要内容莽荒纪人物出场数据统计。
一、中文文本词频统计思路
在上文Python英文词频统计(哈姆雷特)程序示例中,我们进行了英文单词的统计。今天,我们进行中文人物出场频率统计。
与前文相比,本文主要难点有三个,一是相比于由单词构成的英文,中文没有直接的用空格分隔的规律,需要先进行分词;二是中文分词的结果并不是人物,我们还需要想办法转换成人物;三是有些人物具有多个名称,我们需要将这多个名称对应同一个人物。
为了解决中文分词的问题,我们需要使用jieba词库来进行中文分词;为了解决分词结果不是人物的问题,我们可以根据词性来排除大部分选项,只保留筛选人物名词,然后根据结果进行不断修正;为了解决单个人物有多个名称的问题,我们需要在进行中文分词后,进行特殊处理,将这多个名称归一到一个人物身上。
二、中文文本词频统计程序编写
根据上述思路,我们就可以进行中文人物频率统计程序编写了。首先编写程序如下所示:
import jieba.posseg as pseg
f=open("C:\\Users\\Administrator\\Desktop\\莽荒纪.txt","rt",encoding="utf-8")
MangStr=f.read()
f.close()
MangList=pseg.cut(MangStr)
MangDic=dict()
for word,flag in MangList:
if flag=="nr":
MangDic[word]=MangDic.get(word,0)+1
MangSeq=list(MangDic.items())
MangSeq.sort(key=lambda x:x[1],reverse=True)
for i in range(30):
word,count=MangSeq[i]
print("人物{}在莽荒纪中出现次数为第{},出现了{}次".format(word,i+1,count))
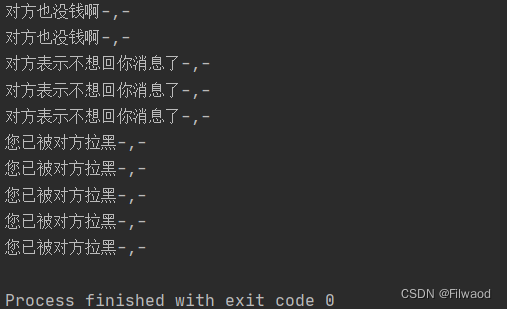
上述程序运行结果如下所示:

三、结果修正与效果展示
从上图中可以看出,我们完成了莽荒纪中文分词,并进行了人物出现频次统计,但是由于jieba并不能准确的识别判定,因此我们还需要对上述结果进行手动修正。一是删除上图中不存在的人物,二是将同一个人物的不同名称,归一为一个人物进行处理。
删除不存在的人物增加代码如下所示:
for word,flag in MangList:
if flag=="nr":
if word=="向纪宁" or word=="和纪宁" or word=="北冥":
word="纪宁"
MangDic[word]=MangDic.get(word,0)+1
exclude={"帝君","连","明白","老祖","师兄","真仙","师傅",
"纪氏","修仙","王","尉迟","少炎氏","黄毛","鸿","雪城",
"古老","须知","师尊","王朝","祖","真灵","文明","玄妙",
"金光","北虹剑","宫","白发","宝贝","奥妙","府","天苍宫",
"纪","师姐","北冥剑","冷笑","应龙卫","莫道","紫光","祖神祖",
"宫殿","金丹","小家伙","北冥剑"}
for word in exclude:
del MangDic[word]
对同一人物进行归一化处理代码如下所示:
if flag=="nr":
if word=="向纪宁" or word=="和纪宁" or word=="北冥":
word="纪宁"
MangDic[word]=MangDic.get(word,0)+1
这样,最后的代码如下所示:
import jieba.posseg as pseg
f=open("C:\\Users\\Administrator\\Desktop\\莽荒纪.txt","rt",encoding="utf-8")
MangStr=f.read()
f.close()
MangList=pseg.cut(MangStr)
MangDic=dict()
for word,flag in MangList:
if flag=="nr":
if word=="向纪宁" or word=="和纪宁" or word=="北冥":
word="纪宁"
MangDic[word]=MangDic.get(word,0)+1
exclude={"帝君","连","明白","老祖","师兄","真仙","师傅",
"纪氏","修仙","王","尉迟","少炎氏","黄毛","鸿","雪城",
"古老","须知","师尊","王朝","祖","真灵","文明","玄妙",
"金光","北虹剑","宫","白发","宝贝","奥妙","府","天苍宫",
"纪","师姐","北冥剑","冷笑","应龙卫","莫道","紫光","祖神祖",
"宫殿","金丹","小家伙","北冥剑"}
for word in exclude:
try:
del MangDic[word]
except:
pass
MangSeq=list(MangDic.items())
MangSeq.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=MangSeq[i]
print("人物{}在莽荒纪中出现次数为第{},出现了{}次".format(word,i+1,count))
上述代码执行结果如下所示:

从上图可以看出,莽荒纪人物出场数据统计成功!
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200


![[Java] 什么是锁?什么是并发控制?线程安全又是什么?锁的本质是什么?如何实现一个锁?](https://img-blog.csdnimg.cn/0ba3e5c3c358440ea9ef7abae632bc8e.png)