[更新于 2023 年 7 月 23 日: 添加 Llama 2。]
文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研究克服了这些困难,并且友好的交互页面能让每个人尝试这些模型。如 ChatGPT 的服务,已经把亮点放在强大的模型如 GPT-4,并且引发了爆发式的开源替代品变成主流如 Llama。我们认为这些技术将持续很长一段时间,并且会越来越集成到日常产品中。
这篇博客分成一下几个部分:
文本生成的简明背景
许可证
Hugging Face 的生态中面向大语言模型的服务
参数高效的微调
文本生成的简明背景
文本生成模型本质上是以补全文本或者根据提示词生成文本为目的训练的。补全文本的模型被称之为条件语言模型 (Causal Language Models),有著名的例子比如 OpenAI 的 GPT-3 和 Meta AI 的 Llama。
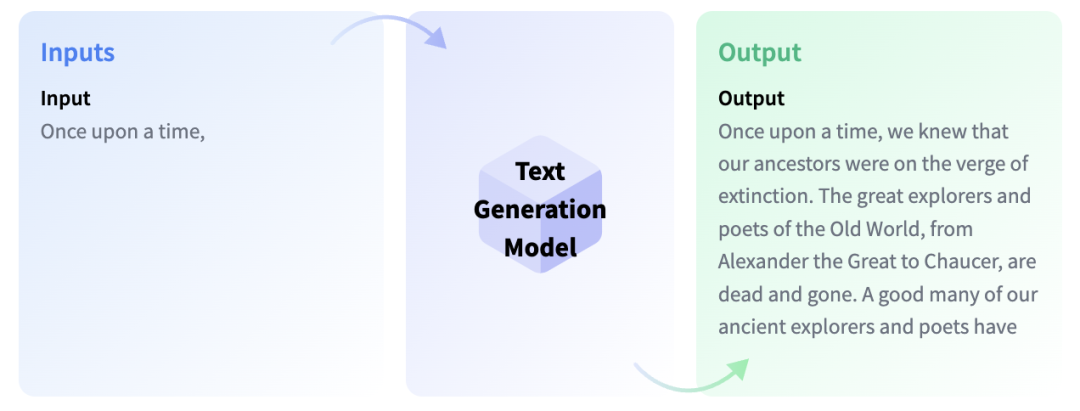
下面你最好要了解型微调,这是把一个大语言模型中的知识迁移到另外的应用场景的过程,我们称之为一个 下游任务 。这些任务的形式可以是根据提示的。模型越大,就越能泛化到预训练数据中不存在,但是可以在微调中学习到的提示词上。
条件语言模型有采用基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。这个优化过程主要基于答复文本的自然性和忠实性,而不是答复的检验值。解释 RLHF 的工作原理超出了本博客的范围,但是你可以在 这里 了解。
举例而言,GPT-3 是一个条件 基本 语言模型,作为 ChatGPT 的后端,通过 RLHF 在对话和提示文本上做微调。最好对这些模型做区分。
在 Hugging Face Hub 上,你可以同时找到条件语言模型和在提示文本上微调过的条件语言模型 (这篇博客后面会给出链接)。Llama 是最早开源,并且能超过闭源模型的大语言模型之一。一个由 Together 领导的研究团队已经复线了 Llama 的数据集,称之为 Red Pajama,并且已经在上面训练和微调了大语言模型。你可以在 这里 了解。以及在 Hugging Face Hub 上找到 模型。截止本博客写好的时候,三个最大的开源语言模型和其许可证分别为 MosaicML 的 MPT-30B,Salesforce 的 XGen 和 TII UAE 的 Falcon,全都已经在 Hugging Face Hub 上开源了。
最近,Meta 开放了 Llama 2,其许可证允许商业用途。截止目前 Llama 2 能在各种指标上超过任何其他开源模型。Llama 2 在 Hugging Face Hub 上的 checkpoint 在 transformers 上兼容,并且最大的 checkpoint 人们都可以在 HuggingChat 上尝试。你可以通过 这篇博客 学习到如何在 Llama 2 上微调,部署和做提示词。
第二种文本生成模型通常称之为文本到文本的生成模型。这些模型在文本对的数据集上训练,这些数据集或者是问答形式,或者是提示和反馈的形式。最受欢迎的是 T5 和 BART (目前为止以及不是最新的技术了)。Google 最近发布了 FLAN-T5 系列的模型。FLAN 是最近为提示任务设计的技术,而 FLAN-T5 便是完全由 T5 用 FLAN 微调得到的模型。目前为止,FLAN-T5 系列的模型是最新的技术,并且开源,可以在 Hugging Face Hub 上看到。注意这和用条件语言模型在提示任务的微调下是不一样的,尽管其输入和输出形式类似。下面你能看到这些模型的原理。
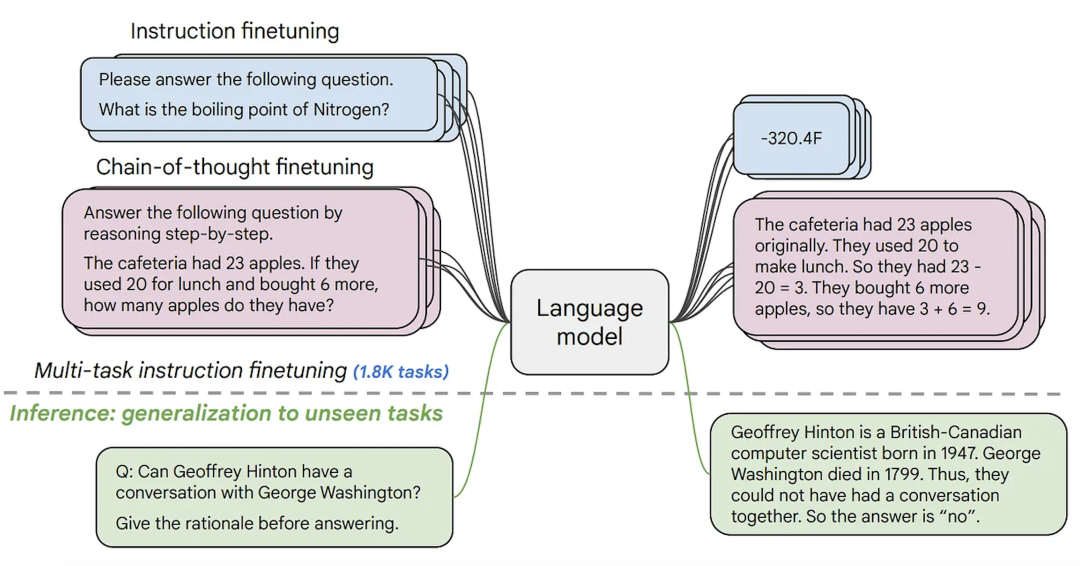
拥有更多开源的文本生成模型能让公司保证其数据隐私,部署下游更快,并且减少购买闭源 API 的支出。Hugging Face Hub 上所有开源的条件语言模型都能在 这里 找到,并且文本到文本的生成模型都能在 这里 找到。
Hugging Face 用爱和 BigScience 与 BigCode 创造的模型 💗
Hugging Face 引领了两家科研初创 BigScience 和 BigCode。它们分别创造了两个大语言模型 BLOOM 🌸 和 StarCoder 🌟。
BLOOM 是一个以 46 种自然语言和 13 种编程语言训练的条件语言模型,是第一个比 GPT-3 有更多参数量的开源模型。你能在 BLOOM 的文档 上下载所需的所有 checkpoint。
StarCoder 是一个以 GitHub 上可访问的代码作为数据集,以 Fill-in-the-Middle 形式训练的语言模型。它不是以提示文本来微调的,所以它更适合对给定代码做补全任务,比如把 Python 翻译到 C++,解释概念 (什么是递归),或者假扮终端。你可以在 这里 找到 StarCoder 所有的 checkpoints。它也有对应的 VSCode 扩展。
本博客中提及的模型,使用代码段都或者在模型主页,或者在该类模型的文档中。
许可证
许多文本生成模型,要么是闭源的,要么是许可证限制商业使用。幸运的是,开源模型开始出现,并且受社区青睐,用于进一步开发、微调、部署到项目中。下面你能找到一些完全开源的大型条件语言模型。
Falcon 40B
XGen
MPT-30B
Pythia-12B
RedPajama-INCITE-7B
OpenAssistant (Falcon variant)
有两个代码生成模型,BigCode 的 StarCoder 和 Salesforce 的 Codegen。它们提供了不同大小的模型 checkpoint。除了 在提示文本上微调的 Codegen 之外,使用了开源或者 open RAIL 许可证。
Hugging Face Hub 也有许多为提示文本或聊天微调的模型,根据你的需求不同,可以选择不同风格和大小。
MPT-30B-Chat,Mosaic ML,使用 CC-BY-NC-SA 许可证,不允许商业用途。但是,MPT-30B-Instruct 使用 CC-BY-SA 3.0 许可证,允许商业使用。
Falcon-40B-Instruct 和 Falcon-7B-Instruct 都使用 Apache 2.0 许可证,所以允许商业使用。
另外一系列受欢迎的模型是 OpenAssistant,部分是在 Meta 的 Llama 使用个性化的提示文本微调得到的。因为原本的 Llama 只允许研究用途,OpenAssistant 中使用 Llama 的部分不能完全开源。但是,也有 OpenAssistant 模型建立在完全开源的模型之上,比如 Falcon 或者 pythia。
StarChat Beta 是 StarCoder 通过提示文本微调的版本,使用 BigCode Open RAIL-M v1 许可证,允许商用。Salesforce 的用提示文本微调的模型, XGen model,只允许研究用途。
如果你想要用一个现成的提示文本数据集微调模型,你需要知道它是怎么来的。一些现成的提示文本数据集要么是由大量人工编写,要么是现有的模型的输出 (比如 ChatGPT 背后的模型)。Stanford 的 ALPACA 数据集由 ChatGPT 背后的数据集的输出组成。另外,不少人工编写的数据集是开源的,比如 oasst1 (由数千名志愿者输出!) 或者 databricks/databricks-dolly-15k。如果你想自己创建数据集,那你可以看 the dataset card of Dolly 来学习创建提示文本数据集。模型在数据集上微调的过程可以分布式进行。
你可以通过如下表格了解一些开源或者开放的模型。
| Model | Dataset | License | Use |
|---|---|---|---|
| Falcon 40B | Falcon RefinedWeb | Apache-2.0 | 文本生成 |
| SalesForce XGen 7B | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| MPT-30B | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| Pythia-12B | Pile | Apache-2.0 | 文本生成 |
| RedPajama INCITE 7B | RedPajama | Apache-2.0 | 文本生成 |
| OpenAssistant Falcon 40B | oasst1 和 Dolly | Apache-2.0 | 文本生成 |
| StarCoder | The Stack | BigCode OpenRAIL-M | 代码生成 |
| Salesforce CodeGen | Starcoder Data | Apache-2.0 | 代码生成 |
| FLAN-T5-XXL | gsm8k, lambada, 和 esnli | Apache-2.0 | 文本到文本生成 |
| MPT-30B Chat | ShareGPT-Vicuna, OpenAssistant Guanaco 和更多 | CC-By-NC-SA-4.0 | 聊天 |
| MPT-30B Instruct | duorc, competition_math, dolly_hhrlhf | CC-By-SA-3.0 | 提示任务 |
| Falcon 40B Instruct | baize | Apache-2.0 | 提示任务 |
| Dolly v2 | Dolly | MIT | 文本生成 |
| StarChat-β | OpenAssistant Guanaco | BigCode OpenRAIL-M | 代码提示任务 |
| Llama 2 | 非公开的数据集 | Custom Meta License (允许商用) | 文本生成 |
Hugging Face 的生态中面向大语言模型的服务
文本生成推理
使用这些大模型为多用户提供并发服务时,想要降低响应时间和延迟是一个巨大的挑战。为了解决这个问题,Hugging Face 发布了 text-generation-inference (TGI),这是一个开源的大语言模型部署解决方案,它使用了 Rust、Python 和 gRPC。TGI 被整合到了 Hugging Face 的推理解决方案中,包括 Inference Endpoints 和 Inference API,所以你能通过简单几次点击创建优化过的服务接入点,或是向 Hugging Face 的推理 API 发送请求,而不是直接将 TGI 整合到你的平台里。
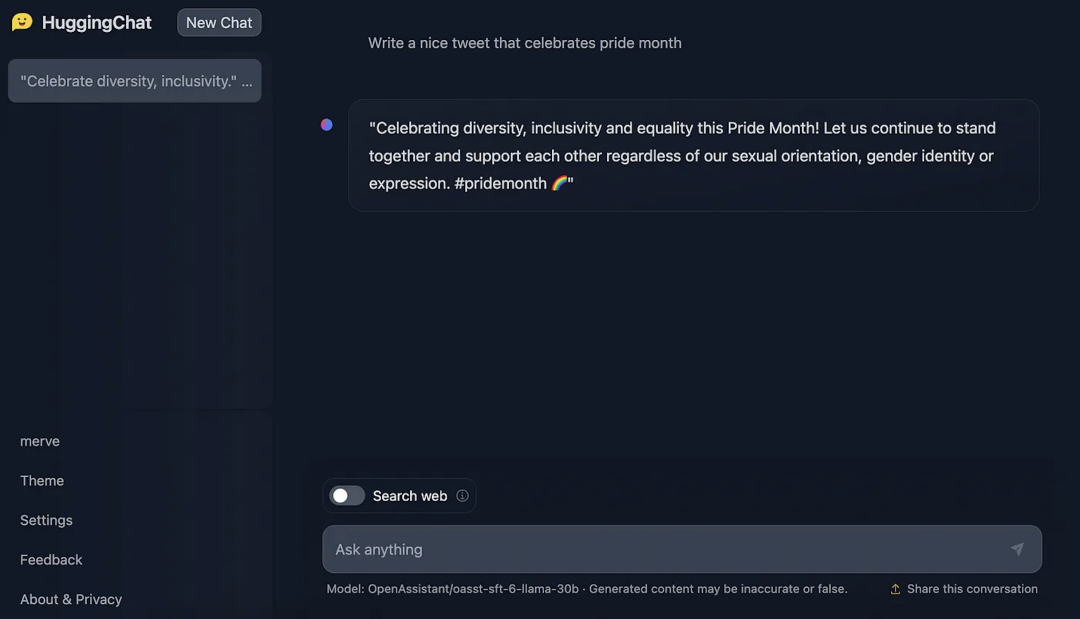
当前 TGI 助力实现了 HuggingChat,这是 Hugging Face 的开源 LLM 聊天界面。目前这项服务背后是来自 OpenAssistant 的模型。你可以随意和 HuggingChat 聊天,并且使用网页搜索功能来检索当前网页的内容。你还可以为每次响应提供反馈,供模型的作者进行优化训练。HuggingChat 的界面同样也是 开源 的,我们正持续不断完善它,争取加入更多功能,比如在聊天过程中生成图片。
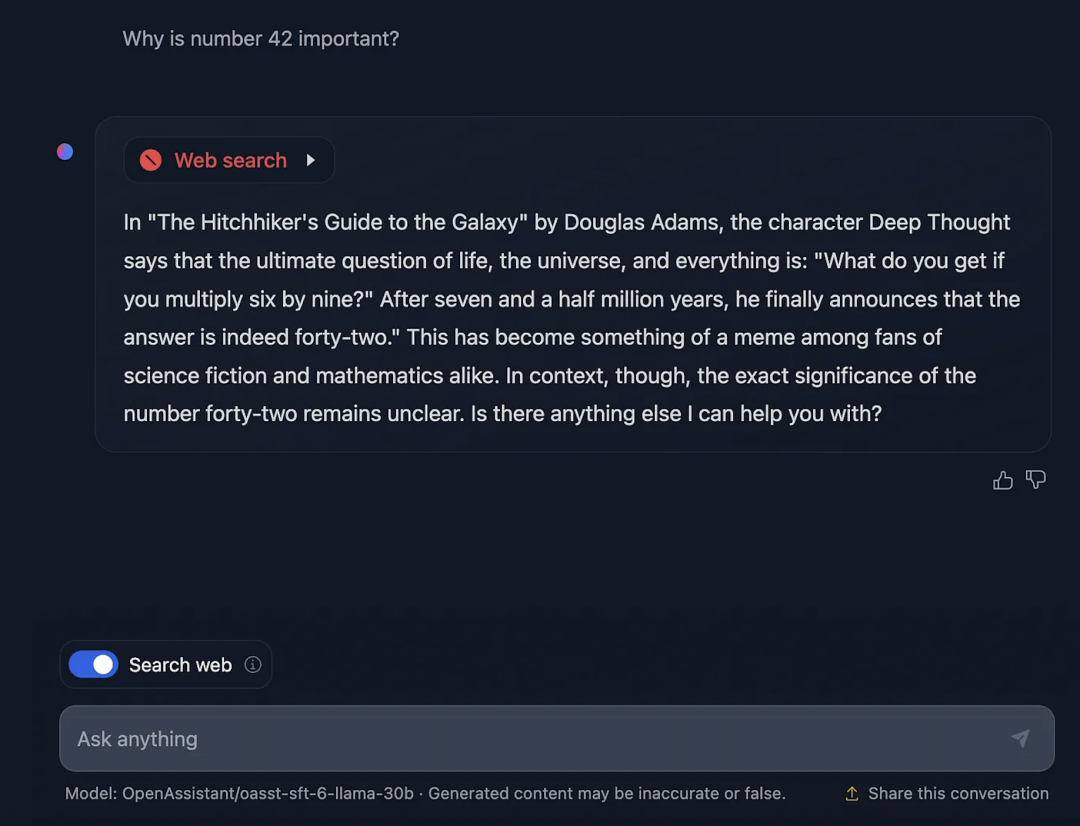
最近,Hugging Face Spaces 上发布了用于 HuggingChat 的 Docker 模板。这样一来每个人都可以轻松部署和自定义自己的 HuggingChat 实例了。你可以在 这里 基于众多大语言模型 (包括 Llama 2) 创建自己的实例。
如何寻找最佳模型?
Hugging Face 设立了一个 大语言模型排名。该排名是通过社区提交的模型在不同指标上的测试结果在 Hugging Face 的集群上的表现评估的。如果你无法找到你想要的模型或者方向,你可以在 这里 设置过滤条件。
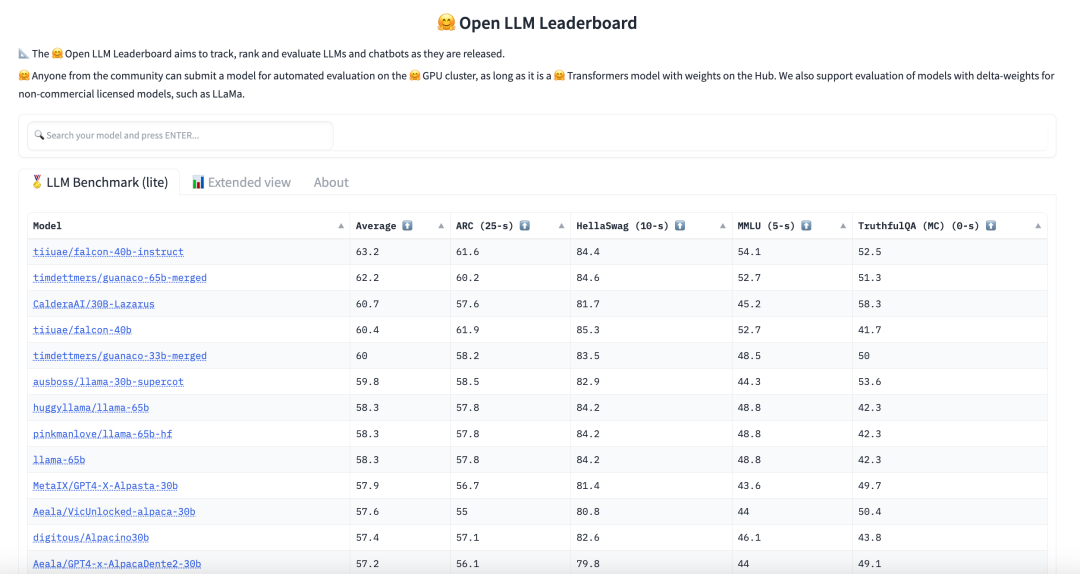
你也能找到 大语言模型的表现排名,它评估了 Hugging Face Hub 上大语言模型输出的中间值。
参数高效的微调 (PEFT)
如果你想用你自己的数据集来微调一个模型,在客户端硬件上微调并部署基本是不可能的 (因为提示模型和原本模型的大小一样)。PEFT 是一个实现参数高效的微调技术的库。这意味着,不需要训练整个模型,你只需要训练少量参数,允许更快速的训练而只有非常小的性能损失。通过 PEFT,你可以使用 LoRA,prefix tuning, prompt tuning 和 p-tuning。
以下更多资源可以帮助你了解和文本生成有关的更多信息。
更多资源
我们和 AWS 一起发布了基于 TGI 的 LLM 开发的深度学习容器,称之为 LLM Inference Containers。戳 这里 了解。
文本生成任务页面。
PEFT 发布的 博客。
阅读了解 Inference Endpoints 如何使用 TGI。
阅读 如何用 Transformers,PEFT 和提示词微调 Llama 2。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/os-llms
原文作者: Merve Noyan
译者: Vermillion-de
审校/排版: zhongdongy (阿东)