并发编程面试题1
一、原子性高频问题:
1.1 Java中如何实现线程安全?
多线程操作共享数据出现的问题。
锁:
- 悲观锁:synchronized,lock
- 乐观锁:CAS
可以根据业务情况,选择ThreadLocal,让每个线程玩自己的数据。
1.2 CAS底层实现
最终回答:先从比较和交换的角度去聊清楚,在Java端聊到native方法,然后再聊到C++中的cmpxchg的指令,再聊到lock指令保证cmpxchg原子性
Java的角度,CAS在Java层面最多你就能看到native方法。
你会知道比较和交换:
- 先比较一下值是否与预期值一致,如果一致,交换,返回true
- 先比较一下值是否与预期值一致,如果不一致,不交换,返回false
可以去看Unsafe类中提供的CAS操作
四个参数:哪个对象,哪个属性的内存偏移量,oldValue,newValue

native是直接调用本地依赖库C++中的方法。
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/69087d08d473/src/share/vm/prims/unsafe.cpp

https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/69087d08d473/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
在CAS底层,如果是多核的操作系统,需要追加一个lock指令
单核不需要加,因为cmpxchg是一行指令,不能再被拆分了

看到cmpxchg ,是汇编的指令,CPU硬件底层就支持 比较和交换 (cmpxchg),cmpxchg并不保证原子性的。(cmpxchg的操作是不能再拆分的指令)
所以才会出现判断CPU是否是多核,如果是多核就追加lock指令。
lock指令你可以理解为是CPU层面的锁,一般锁的粒度就是 缓存行 级别的锁,当然也有 总线锁 ,但是成本太高,CPU会根据情况选择。
1.3 CAS的常见问题
ABA: ABA不一定是问题!因为一些只存在 ++,–的这种操作,即便出现ABA问题,也不影响结果!
线程A:期望将value从A1 - B2
线程B:期望将value从B2 - A3
线程C:期望将value从A1 - C4
按照原子性来说,无法保证线程安全。
解决方案很简单,Java端已经提供了。
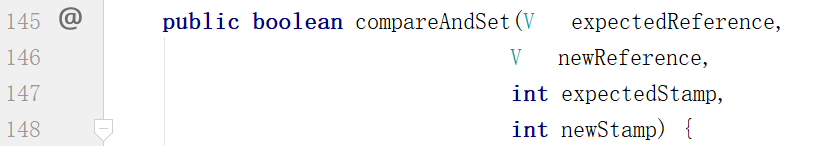
说人话就是,在修改value的同时,指定好版本号。
JUC下提供的AtomicStampedReference就可以实现。
自旋次数过多:
自旋次数过多,会额外的占用大量的CPU资源!浪费资源。
回答方式:可以从synchronized或者LongAdder层面去聊
- synchronized方向:从CAS几次失败后,就将线程挂起(WAITING),避免占用CPU过多的资源!
- LongAdder方向:这里是基于类似 分段锁 的形式去解决(要看业务,有限制的),传统的AtmoicLong是针对内存中唯一的一个值去++,LongAdder在内存中搞了好多个值,多个线程去加不同的值,当你需要结果时,我将所有值累加,返回给你。
只针对一个属性保证原子性: 处理方案,学了AQS就懂了。ReentrantLock基于AQS实现,AQS基于CAS实现核心功能。
1.4 四种引用类型 + ThreadLocal的问题?
ThreadLocal的问题:Java基础面试题2 – 第16题。
四种引用类型:
-
强引用:User xx = new User(); xx就是强引用,只要引用还在,GC就不会回收!
-
软引用:用一个SofeReference引用的对象,就是软引用,如果内存空间不足,才会回收只有软引用指向对象。 一般用于做缓存。
SoftwareReference xx = new SoftwareReference (new User); User user = xx.get(); -
弱引用:WeakReference引用的对象,一般就是弱引用,只要执行GC,就会回收只有弱引用指向的对象。可以解决内存泄漏的问题 ,看ThreadLocal即可
ThreadLocal的问题:Java基础面试题2 – 第16题。
-
虚引用:PhantomReference引用的对象,就是虚引用,拿不到虚引用指向的对象,一般监听GC回收阶段,或者是回收堆外内存时使用。
二、可见性高频问题:
2.1 Java的内存模型
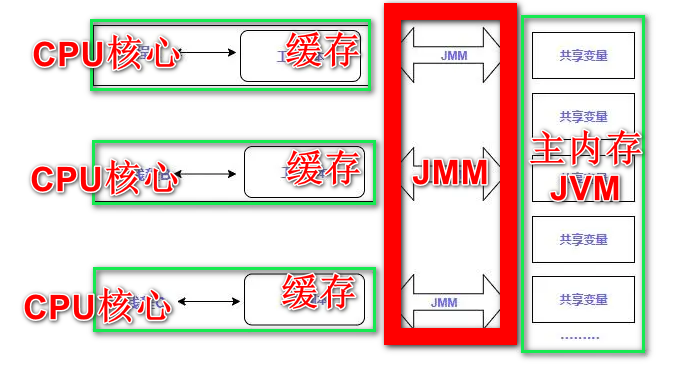
回答方式。先全局描述。 在处理指令时,CPU会拉取数据,优先级是从L1到L2到L3,如果都没有,需要去主内存中拉取,JMM就是在CPU和主内存之间,来协调,保证可见、有序性等操作。
一定要聊JMM,别上来就聊JVM的内存结构,不是一个东西!!!!(Java Memory Model)
 、
、
CPU核心,就是CPU核心(寄存器)
缓存是CPU的缓存,CPU的缓存分为L1(线程独享),L2(内核独享),L3(多核共享)
JMM就是Java内存模型的核心,可见性,有序性都基于这实现。
主内存JVM,就是你堆内存。
2.2 保证可见性的方式
啥是可见性: 可见性是指线程间的,对变量的变化是否可见
Java层面中,保证可见性的方式有很多:
- volatile,用volatile基本数据类型,可以保证每次CPU去操作数据时,都直接去主内存进行读写。
- synchronized,synchronized的内存语义可以保证在获取锁之后,可以保证前面操作的数据是可见的。
- lock(CAS-volatile),也可以保证CAS或者操作volatile的变量之后,可以保证前面操作的数据是可见的。
- final,是常量没法动~~
2.3 volatile修饰引用数据类型
先说结果, 首先volatile修饰引用数据类型,只能保证引用数据类型的地址是可见的,不保证内部属性可见。
But,这个结论只能在hotspot中实现,如果换一个版本的虚拟机,可能效果就不一样了。volatile修饰引用数据类型,JVM压根就没规范过这种操作,不同的虚拟机厂商,可以自己实现。
这个问题,只出现在面试中,干活你要这么干……………………干丫的~
2.4 有了MESI协议,为啥还有volatile?
MESI是CPU缓存一致性的协议,大多数的CPU厂商都根据MESI去实现了缓存一致性的效果。
CPU已经有MESI协议了,volatile是不是有点多余啊!?
首先,这哥俩不冲突,一个是从CPU硬件层面上的一致性,一个是Java中JMM层面的一致性。
MESI协议,他有一套固定的机制,无论你是否声明了volatile,他都会基于这个机制来保证缓存的一致性(可见性)。同时,也要清楚,如果没有MESI协议,volatile也会存在一些问题,不过也有其他的处理方案(总线锁,时间成本太高了,如果锁了总线,就一个CPU核心在干活)。
MESI是协议,是规划,是interface,他需要CPU厂商实现。
既然CPU有MESI了,为啥还要volatile,那自然是MESI协议有问题。MESI保证了多核CPU的独占cache之间的可见性,但是CPU不是说必须直接将寄存器中的数据写入到L1,因为在大多是×86架构的CPU中,寄存器和L1之间有一个store buffer,寄存器值可能落到了store buffer,没落到L1中,就会导致缓存不一致。而且除了×86架构的CPU,在arm和power的CPU中,还有load buffer,invalid queue都会或多或少影响缓存一致性!
回答的方式:MESI协议和volatile不冲突,因为MESI是CPU层面的,而CPU厂商很多实现不一样,而且CPU的架构中的一些细节也会有影响,比如Store Buffer会影响寄存器写入L1缓存,导致缓存不一致。volatile的底层生成的是汇编的lock指令,这个指令会要求强行写入主内存,并且可以忽略Store Buffer这种缓存从而达到可见性的目的,而且会利用MESI协议,让其他缓存行失效。
2.5 volatile的可见性底层实现
volatile的底层生成的是汇编的lock指令,这个指令会要求强行写入主内存,并且可以忽略Store Buffer这种缓存从而达到可见性的目的,而且会利用MESI协议,让其他缓存行失效。
三、有序性高频问题:
3.1 什么是有序性问题
单例模式中的懒汉机制中,就存在一个这样的问题。
懒汉为了保证线程安全,一般会采用DCL的方式。
但是单单用DCL,依然会有几率出现问题。
线程可能会拿到初始化一半的对象去操作,极有可能出现NullPointException。
(初始化对象三部,开辟空间,初始化内部属性,指针指向引用)
在Java编译.java为.class时,会基于JIT做优化,将指令的顺序做调整,从而提升执行效率。
在CPU层面,也会对一些执行进行重新排序,从而提升执行效率。
这种指令的调整,在一些特殊的操作上,会导致出现问题。
3.2 volatile的有序性底层实现
被volatile修饰的属性,在编译时,会在前后追加 内存屏障 。
SS:屏障前的读写操作,必须全部完成,再执行后续操作
SL:屏障前的写操作,必须全部完成,再执行后续读操作
LL:屏障前的读操作,必须全部完成,再执行后续读操作
LS:屏障前的读操作,必须全部完成,再执行后续写操作
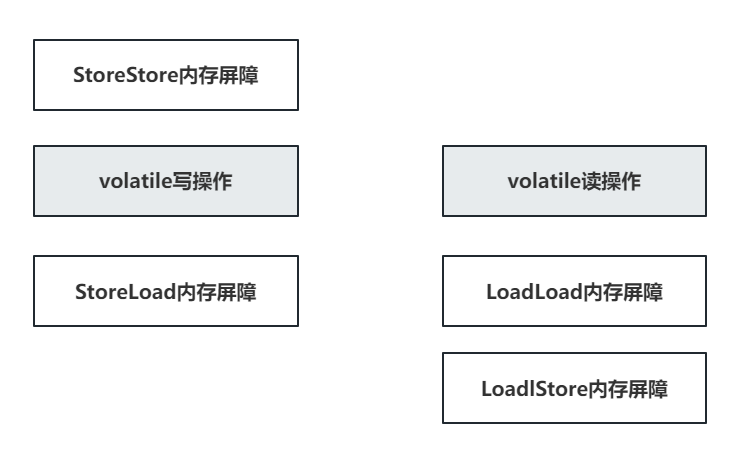
这个内存屏障是JDK规定的,目的是保证volatile修饰的属性不会出现指令重排的问题。
volatile在JMM层面,保证JIT不重排可以理解,但是,CPU怎么实现的。
查看这个文档:https://gee.cs.oswego.edu/dl/jmm/cookbook.html
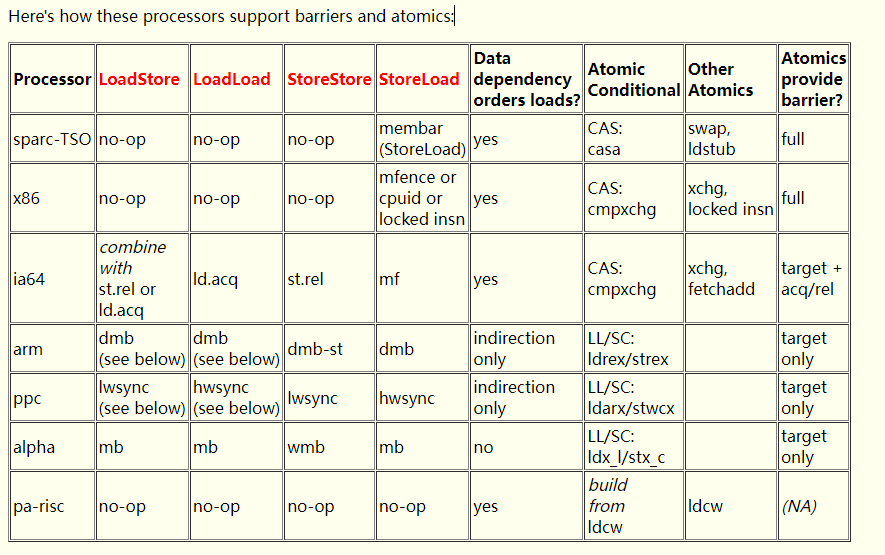
不同的CPU对内存屏障都有一定的支持,比如×86架构,内部自己已经实现了LS,LL,SS,只针对SL做了支持。
去openJDK再次查看,mfence是如何支持的。其实在底层还是mfence内部的lock指定,来解决指令重排问题。

四、synchronized高频问题:
4.1 synchronized锁升级的过程?
锁就是对象,随便哪一个都可以,Java中所有对象都是锁。
无锁(匿名偏向)、偏向锁、轻量级锁、重量级锁
无锁(匿名偏向): 一般情况下,new出来的一个对象,是无锁状态。因为偏向锁有延迟,在启动JVM的4s中,不存在偏向锁,但是如果关闭了偏向锁延迟的设置,new出来的对象,就是匿名偏向。
偏向锁: 当某一个线程来获取这个锁资源时,此时,就会变为偏向锁,偏向锁存储线程的ID
当偏向锁升级时,会触发偏向锁撤销,偏向锁撤销需要等到一个安全点,比如GC的时候,偏向锁撤销的成本太高,所以默认开始时,会做偏向锁延迟。
安全点:
- GC
- 方法返回之前
- 调用某个方法之后
- 甩异常的位置
- 循环的末尾
轻量级锁: 当在出现了多个线程的竞争,就要升级为轻量级锁(有可能直接从无锁变为轻量级锁,也有可能从偏向锁升级为轻量级锁),轻量级锁的效果就是基于CAS尝试获取锁资源,这里会用到自适应自旋锁,根据上次CAS成功与否,决定这次自旋多少次。
重量级锁: 如果到了重量级锁,那就没啥说的了,如果有线程持有锁,其他竞争的,就挂起。
4.2 synchronized锁粗化&锁消除?
锁粗化(锁膨胀):(JIT优化)
while(){
sync(){
// 多次的获取和释放,成本太高,优化为下面这种
}
}
//----
sync(){
while(){
// 优化成这样
}
}
锁消除:在一个sync中,没有任何共享资源,也不存在锁竞争的情况,JIT编译时,就直接将锁的指令优化掉。
4.3 synchronized实现互斥性的原理?
偏向锁:查看对象头中的MarkWord里的线程ID,是否是当前线程,如果不是,就CAS尝试改,如果是,就拿到了锁资源。
轻量级锁:查看对象头中的MarkWord里的Lock Record指针指向的是否是当前线程的虚拟机栈,如果是,拿锁执行业务,如果不是CAS,尝试修改,修改他几次,不成,再升级到重量级锁。
重量级锁:查看对象头中的MarkWord里的指向的ObjectMonitor,查看owner是否是当前线程,如果不是,扔到ObjectMonitor里的EntryList中,排队,并挂起线程,等待被唤醒。
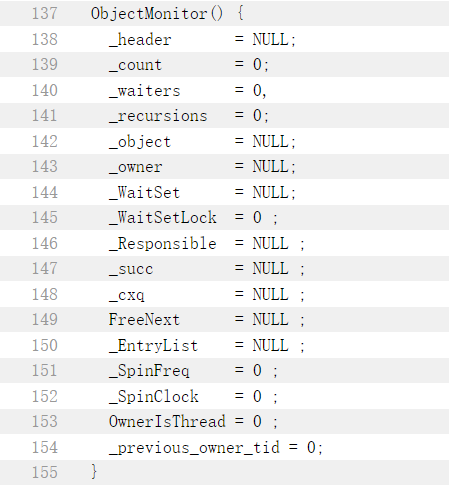
4.4 wait为什么是Object下的方法?
执行wait方法需要持有sync锁。
sync锁可以是任意对象。
同时执行wait方法是在持有sync锁的时候,释放锁资源。
其次wait方法需要去操作ObjectMonitor,而操作ObjectMonitor就必须要在持有锁资源的前提的才能操作,将当前线程扔到WaitSet等待池中。
同理,notify方法需要将WaitSet等待池中线程扔到EntryList,如果不拥有ObjectMonitor,怎么操作!
类锁就是基于类.class作为 类锁
对象锁,就是new 一个对象作为 对象锁
设计模式(单例,工厂,代理,消费者生产者,策略,责任链,观察者,模板,装饰者),多线程,JVM,MySQL,Spring,SpringBoot,Redis,MQ





![[JavaScript游戏开发] Q版地图上让英雄、地图都动起来](https://img-blog.csdnimg.cn/725ebb89254c46589848d4a6335abbd6.png)