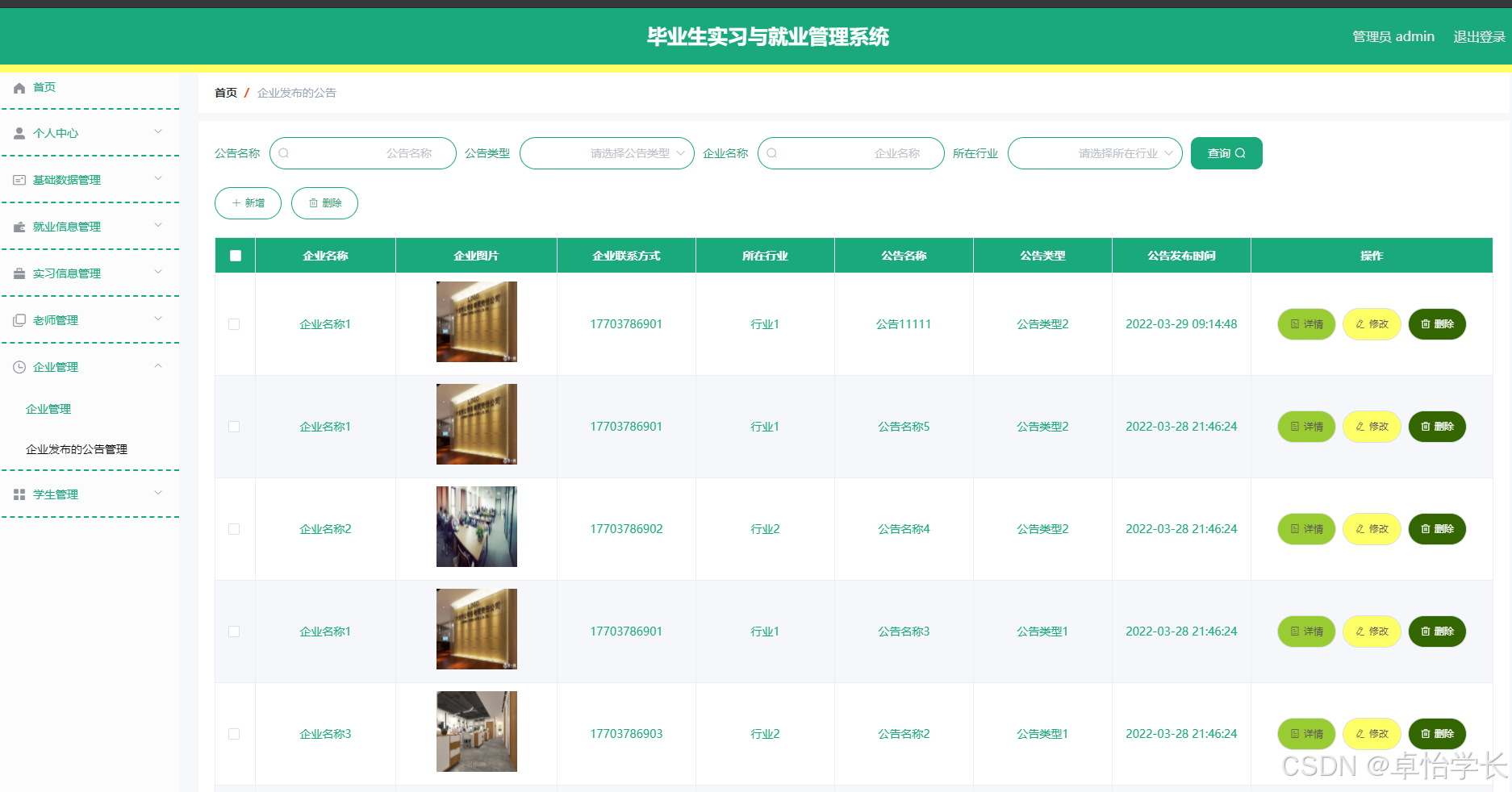
本文档详细解释了一段使用 TensorFlow 构建和训练混合密度网络(Mixture Density Network, MDN)的代码,涵盖数据生成、模型构建、自定义损失函数与预测可视化等各个环节。
1. 导入库与设置超参数
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import math
说明:
- 引入用于数值运算(NumPy)、构建深度学习模型(TensorFlow/Keras)和绘图(Matplotlib)的基础工具包。
超参数定义
N_HIDDEN = 15 # 隐藏层神经元数量
N_MIXES = 10 # GMM 中混合成分数量
OUTPUT_DIMS = 1 # 输出维度(目标变量维度)
2. 自定义 MDN 层
class MDN(layers.Layer):
def __init__(self, output_dims, num_mixtures, **kwargs):
super(MDN, self).__init__(**kwargs)
self.output_dims = output_dims
self.num_mixtures = num_mixtures
self.params = self.num_mixtures * (2 * self.output_dims + 1) # pi, mu, sigma
self.dense = layers.Dense(self.params)
def call(self, inputs):
output = self.dense(inputs)
return output
说明:
params表示 GMM 每个分量包含mu(均值)、sigma(标准差)和pi(权重),共2*D + 1个参数。- 输出维度为
(batch_size, num_mixtures * (2*output_dims + 1))。
3. 自定义 MDN 损失函数
def get_mixture_loss_func(output_dims, num_mixtures):
def mdn_loss(y_true, y_pred):
y_true = tf.reshape(y_true, [-1, 1])
out_mu = y_pred[:, :num_mixtures * output_dims]
out_sigma = y_pred[:, num_mixtures * output_dims:2 * num_mixtures * output_dims]
out_pi = y_pred[:, -num_mixtures:]
mu = tf.reshape(out_mu, [-1, num_mixtures, output_dims])
sigma = tf.exp(tf.reshape(out_sigma, [-1, num_mixtures, output_dims]))
pi = tf.nn.softmax(out_pi)
y_true = tf.tile(y_true[:, tf.newaxis, :], [1, num_mixtures, 1])
normal_dist = tf.exp(-0.5 * tf.square((y_true - mu) / sigma)) / (sigma * tf.sqrt(2.0 * np.pi))
prob = tf.reduce_prod(normal_dist, axis=2)
weighted_prob = prob * pi
loss = -tf.math.log(tf.reduce_sum(weighted_prob, axis=1) + 1e-8)
return tf.reduce_mean(loss)
return mdn_loss
说明:
- 通过概率密度函数计算目标值属于 GMM 各个分布的概率,并取加权平均。
- 对数似然函数取负作为损失。
4. 从输出分布中采样
def sample_from_output(y_pred, output_dims, num_mixtures, temp=1.0):
out_mu = y_pred[:num_mixtures * output_dims]
out_sigma = y_pred[num_mixtures * output_dims:2 * num_mixtures * output_dims]
out_pi = y_pred[-num_mixtures:]
out_sigma = np.exp(out_sigma)
out_pi = np.exp(out_pi / temp)
out_pi /= np.sum(out_pi)
mixture_idx = np.random.choice(np.arange(num_mixtures), p=out_pi)
mu = out_mu[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]
sigma = out_sigma[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]
sample = np.random.normal(mu, sigma)
return sample
说明:
- 使用 softmax 处理
pi,选择一个分布后按对应的mu和sigma采样。 temp控制采样温度(温度越高分布越平坦)。
5. 生成训练数据
NSAMPLE = 3000
y_data = np.float32(np.random.uniform(-10.5, 10.5, NSAMPLE))
r_data = np.random.normal(size=NSAMPLE)
x_data = np.sin(0.75 * y_data) * 7.0 + y_data * 0.5 + r_data * 1.0
x_data = x_data.reshape((NSAMPLE, 1))
y_data = y_data.reshape((NSAMPLE, 1))
说明:
- 构造非线性映射关系的合成数据:
x = sin(0.75y)*7 + 0.5y + 噪声。 x是输入,y是目标。
6. 构建模型
model = keras.Sequential([
layers.Dense(N_HIDDEN, input_shape=(1,), activation='relu'),
layers.Dense(N_HIDDEN, activation='relu'),
MDN(OUTPUT_DIMS, N_MIXES)
])
model.compile(loss=get_mixture_loss_func(OUTPUT_DIMS, N_MIXES), optimizer=keras.optimizers.Adam())
model.summary()
说明:
- 构建一个两层隐层的前馈神经网络,输出 MDN 层。
- 使用自定义的 MDN 损失函数训练模型。
7. 模型训练
model.fit(x_data, y_data, batch_size=128, epochs=200, validation_split=0.15, verbose=1)
- 批量大小 128,训练 200 个 epoch,保留 15% 数据用于验证。
8. 模型测试与预测可视化
x_test = np.linspace(-15, 15, 1000).astype(np.float32).reshape(-1, 1)
y_pred = model.predict(x_test)
y_samples = np.array([sample_from_output(p, OUTPUT_DIMS, N_MIXES) for p in y_pred])
- 对连续输入进行预测并从预测的 GMM 中采样。
可视化预测结果
plt.figure()
plt.scatter(x_test, y_samples, alpha=0.3, s=10)
plt.title("MDN Predictions")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
原始数据与预测对比
plt.figure(figsize=(8, 5))
plt.scatter(x_data, y_data, label="Original Data", alpha=0.2, s=10)
plt.scatter(x_test, y_samples, label="MDN Samples", alpha=0.5, s=10, color='r')
plt.title("MDN Prediction vs Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()
总代码如下
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import math
# 超参数
N_HIDDEN = 15
N_MIXES = 10
OUTPUT_DIMS = 1
# === 1. 自定义 MDN 层 ===
class MDN(layers.Layer):
def __init__(self, output_dims, num_mixtures, **kwargs):
super(MDN, self).__init__(**kwargs)
self.output_dims = output_dims
self.num_mixtures = num_mixtures
self.params = self.num_mixtures * (2 * self.output_dims + 1) # pi, mu, sigma
self.dense = layers.Dense(self.params)
def call(self, inputs):
output = self.dense(inputs)
return output
# === 2. 自定义损失函数 ===
def get_mixture_loss_func(output_dims, num_mixtures):
def mdn_loss(y_true, y_pred):
y_true = tf.reshape(y_true, [-1, 1])
out_mu = y_pred[:, :num_mixtures * output_dims]
out_sigma = y_pred[:, num_mixtures * output_dims:2 * num_mixtures * output_dims]
out_pi = y_pred[:, -num_mixtures:]
mu = tf.reshape(out_mu, [-1, num_mixtures, output_dims])
sigma = tf.exp(tf.reshape(out_sigma, [-1, num_mixtures, output_dims]))
pi = tf.nn.softmax(out_pi)
y_true = tf.tile(y_true[:, tf.newaxis, :], [1, num_mixtures, 1])
normal_dist = tf.exp(-0.5 * tf.square((y_true - mu) / sigma)) / (sigma * tf.sqrt(2.0 * np.pi))
prob = tf.reduce_prod(normal_dist, axis=2)
weighted_prob = prob * pi
loss = -tf.math.log(tf.reduce_sum(weighted_prob, axis=1) + 1e-8)
return tf.reduce_mean(loss)
return mdn_loss
# === 3. 从输出采样函数 ===
def sample_from_output(y_pred, output_dims, num_mixtures, temp=1.0):
out_mu = y_pred[:num_mixtures * output_dims]
out_sigma = y_pred[num_mixtures * output_dims:2 * num_mixtures * output_dims]
out_pi = y_pred[-num_mixtures:]
out_sigma = np.exp(out_sigma)
out_pi = np.exp(out_pi / temp)
out_pi /= np.sum(out_pi)
mixture_idx = np.random.choice(np.arange(num_mixtures), p=out_pi)
mu = out_mu[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]
sigma = out_sigma[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]
sample = np.random.normal(mu, sigma)
return sample
# === 4. 生成训练数据 ===
NSAMPLE = 3000
y_data = np.float32(np.random.uniform(-10.5, 10.5, NSAMPLE))
r_data = np.random.normal(size=NSAMPLE)
x_data = np.sin(0.75 * y_data) * 7.0 + y_data * 0.5 + r_data * 1.0
x_data = x_data.reshape((NSAMPLE, 1))
y_data = y_data.reshape((NSAMPLE, 1))
plt.figure()
plt.scatter(x_data, y_data, alpha=0.3)
plt.title("Training Data")
plt.show()
# === 5. 构建模型 ===
model = keras.Sequential([
layers.Dense(N_HIDDEN, input_shape=(1,), activation='relu'),
layers.Dense(N_HIDDEN, activation='relu'),
MDN(OUTPUT_DIMS, N_MIXES)
])
model.compile(loss=get_mixture_loss_func(OUTPUT_DIMS, N_MIXES), optimizer=keras.optimizers.Adam())
model.summary()
# === 6. 模型训练 ===
model.fit(x_data, y_data, batch_size=128, epochs=200, validation_split=0.15, verbose=1)
# === 7. 测试与可视化 ===
x_test = np.linspace(-15, 15, 1000).astype(np.float32).reshape(-1, 1)
y_pred = model.predict(x_test)
y_samples = np.array([sample_from_output(p, OUTPUT_DIMS, N_MIXES) for p in y_pred])
plt.figure()
plt.scatter(x_test, y_samples, alpha=0.3, s=10)
plt.title("MDN Predictions")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
# === 8. 测试数据与预测对比图 ===
plt.figure(figsize=(8, 5))
plt.scatter(x_data, y_data, label="Original Data", alpha=0.2, s=10)
plt.scatter(x_test, y_samples, label="MDN Samples", alpha=0.5, s=10, color='r')
plt.title("MDN Prediction vs Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()
总结
本项目展示了如何使用 TensorFlow 构建混合密度网络,用以建模复杂的条件分布。相比传统回归模型,MDN 能够生成多峰预测结果,适用于不确定性高、输出存在多解的场景。




![[文献阅读] EnCodec - High Fidelity Neural Audio Compression](https://i-blog.csdnimg.cn/direct/ef1619ec5dd242f5ba352767ccfc9bb7.png)