在今天的时代,公司努力工作,使他们的客户满意。他们推出新的技术和服务,以便客户可以更多地使用他们的产品。他们试图与每一个客户保持联系,以便他们能够相应地提供货物。但实际上,与每个人保持联系非常困难和不现实。因此,这里来使用客户细分。
客户细分是指根据客户的相似特征、行为和需求对客户进行细分。这最终将在许多方面帮助公司。比如,他们可以推出产品或相应地增强功能。他们也可以根据自己的行为针对特定部门。所有这些都导致了公司整体市场价值的提升。
今天,我们将使用机器学习来实现客户细分的任务。
导入库
我们需要的库是:
- Pandas -此库有助于以2D数组格式加载数据框。
- Numpy - Numpy数组非常快,可以执行大型计算。
- Matplotlib / Seaborn -此库用于绘制可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings('ignore')
导入数据集
用于任务的数据集包括客户的详细信息,包括他们的婚姻状况、他们的收入、购买的物品的数量、购买的物品的类型等。
df = pd.read_csv('new.csv')
df.head()
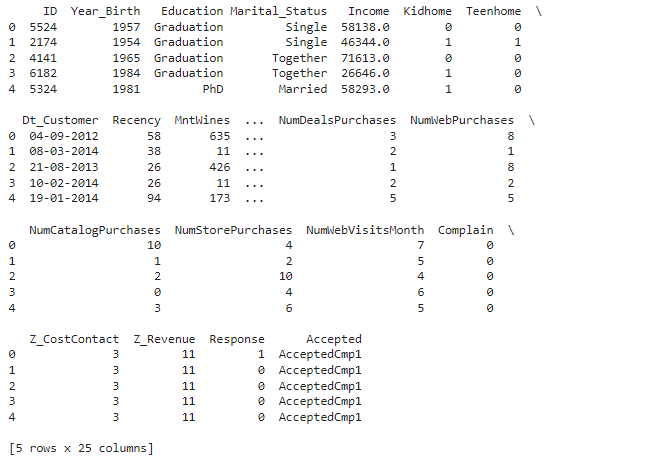
df.shape
输出:
(2240, 25)(2240, 25)
数据预处理
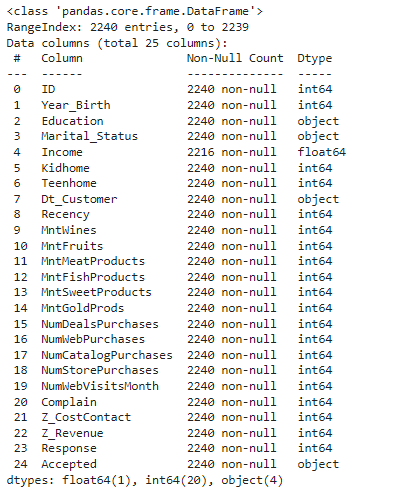
df.info()
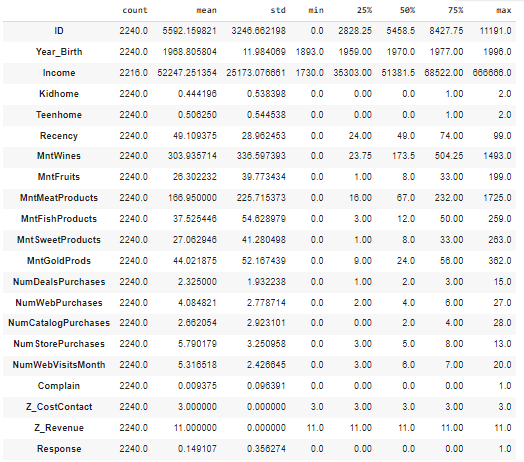
df.describe().T
df['Accepted'] = df['Accepted'].str.replace('Accepted', '')
检查数据集中的空值。
for col in df.columns:
temp = df[col].isnull().sum()
if temp > 0:
print(f'Column {col} contains {temp} null values.')
输出:
Column Income contains 24 null values.
现在,一旦我们有了空值的计数,并且我们知道这些值非常小,我们就可以删除它们(这不会对数据集产生太大影响)。
df = df.dropna()
print("Total missing values are:", len(df))
输出:
Total missing values are: 2216
要找到每列中唯一值的总数,我们可以使用data.unique()方法。
df.nunique()
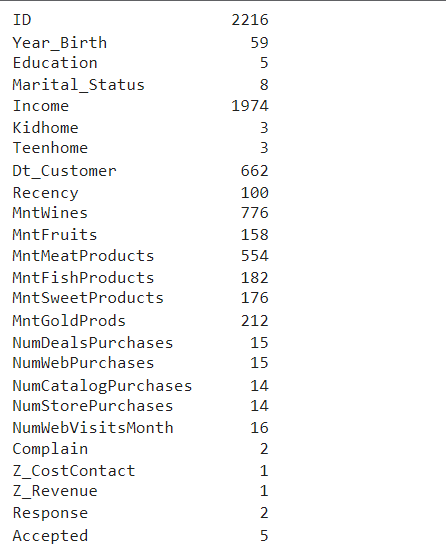
在这里,我们可以观察到在整个列中包含单个值的列,因此它们在模型开发中没有相关性。
此外,数据集有一个列Dt_Customer,其中包含日期列,我们可以转换为3列,即日、月、年。
parts = df["Dt_Customer"].str.split("-", n=3, expand=True)
df["day"] = parts[0].astype('int')
df["month"] = parts[1].astype('int')
df["year"] = parts[2].astype('int')
现在我们有了所有重要的特征,可以删除Z_CostContact,Z_Revenue,Dt_Customer等特征。
df.drop(['Z_CostContact', 'Z_Revenue', 'Dt_Customer'],
axis=1,
inplace=True)
数据可视化和分析
数据可视化是以图片或图形格式对信息和数据的图形表示。在这里,我们将使用条形图和计数图来更好地可视化。
floats, objects = [], []
for col in df.columns:
if df[col].dtype == object:
objects.append(col)
elif df[col].dtype == float:
floats.append(col)
print(objects)
print(floats)
输出:
['Education', 'Marital_Status', 'Accepted']
['Income']
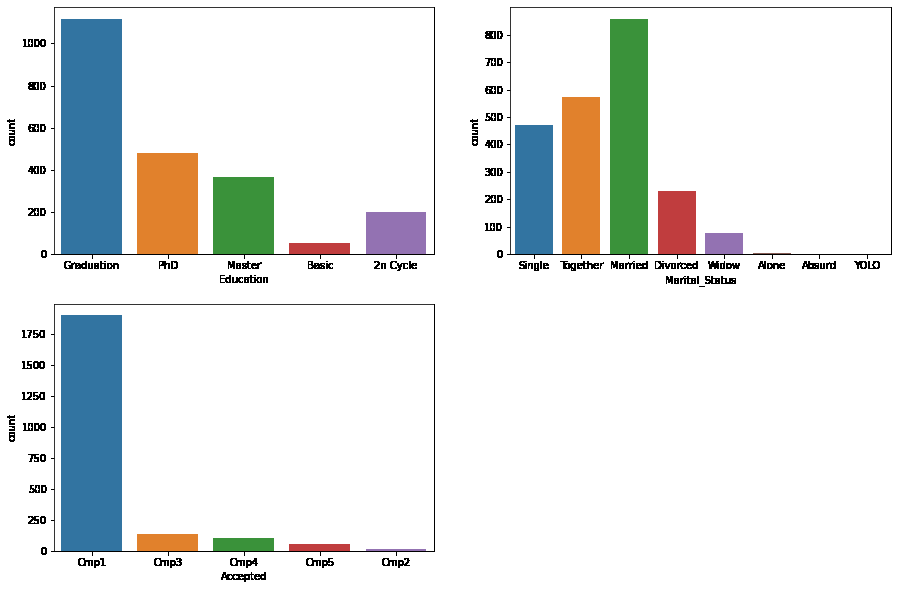
要获得datatype - object的列的计数图,请参考下面的代码。
plt.subplots(figsize=(15, 10))
for i, col in enumerate(objects):
plt.subplot(2, 2, i + 1)
sb.countplot(df[col])
plt.show()
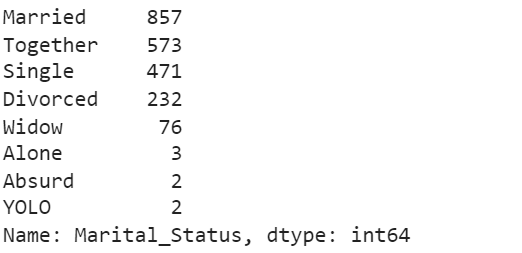
让我们检查数据的Marital_Status的value_counts。
df['Marital_Status'].value_counts()
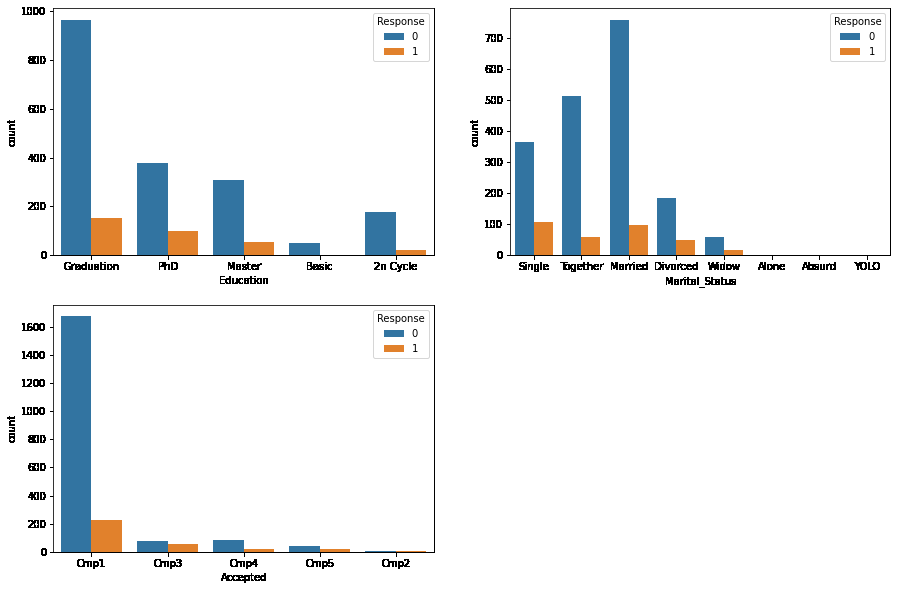
现在让我们看看特征相对于响应值的比较。
plt.subplots(figsize=(15, 10))
for i, col in enumerate(objects):
plt.subplot(2, 2, i + 1)
sb.countplot(df[col], hue=df['Response'])
plt.show()
标签编码
标签编码用于将分类值转换为数值,以便模型能够理解。
for col in df.columns:
if df[col].dtype == object:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
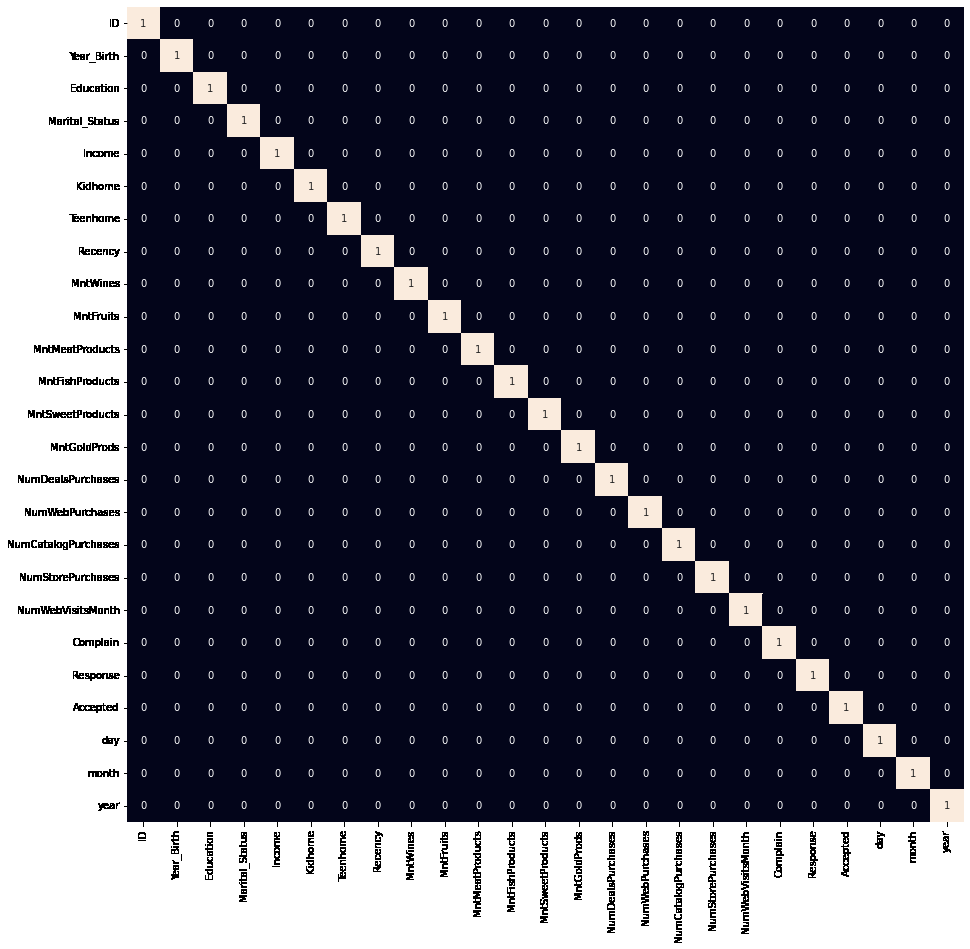
热图是可视化数据集不同特征之间相关性的最佳方法。让我们给予它0.8的值
plt.figure(figsize=(15, 15))
sb.heatmap(df.corr() > 0.8, annot=True, cbar=False)
plt.show()
标准化
标准化是特征缩放的方法,特征缩放是特征工程的一个组成部分。它缩小了数据,使机器学习模型更容易从中学习。它将平均值减少到’0’,将标准差减少到’1’。
scaler = StandardScaler()
data = scaler.fit_transform(df)
数据降维
我们将使用TSNE(T-distributed Stochastic Neighbor Embedding)降维。它有助于可视化高维数据。它将数据点之间的相似性转换为联合概率,并尝试将值最小化为低维嵌入。
from sklearn.manifold import TSNE
model = TSNE(n_components=2, random_state=0)
tsne_data = model.fit_transform(df)
plt.figure(figsize=(7, 7))
plt.scatter(tsne_data[:, 0], tsne_data[:, 1])
plt.show()
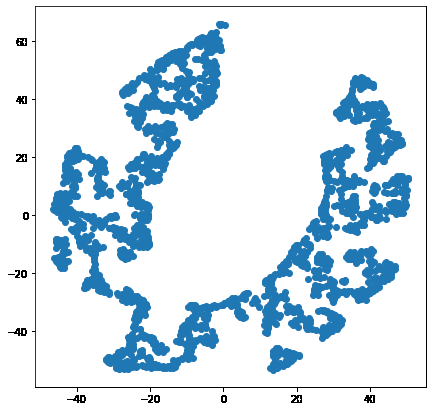
当然,从给定数据的2-D表示中可以清楚地看到一些聚类。让我们使用KMeans算法在高维平面本身中找到这些聚类。
KMeans聚类也可用于对平面中的不同点进行聚类。
error = []
for n_clusters in range(1, 21):
model = KMeans(init='k-means++',
n_clusters=n_clusters,
max_iter=500,
random_state=22)
model.fit(df)
error.append(model.inertia_)
plt.figure(figsize=(10, 5))
sb.lineplot(x=range(1, 21), y=error)
sb.scatterplot(x=range(1, 21), y=error)
plt.show()
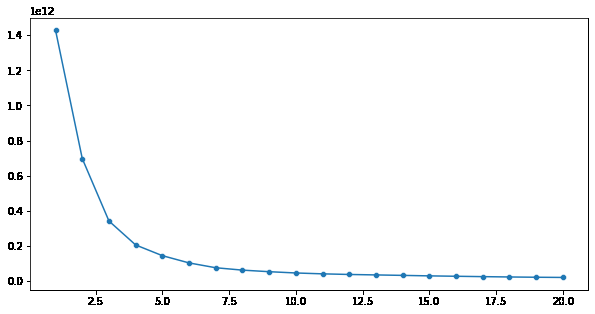
这里,通过肘部法则,我们可以说k = 6是应该进行的聚类的最佳数量,因为在k = 6之后,惯性的值不会急剧下降。
# create clustering model with optimal k=5
model = KMeans(init='k-means++',
n_clusters=5,
max_iter=500,
random_state=22)
segments = model.fit_predict(df)
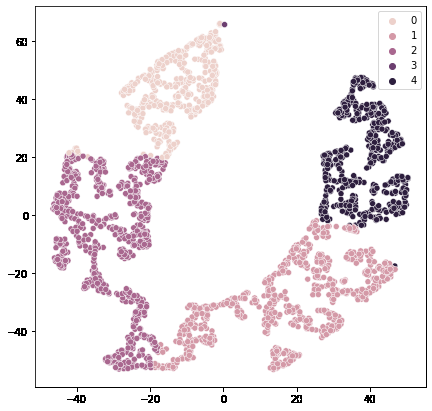
散点图将用于查看由K均值聚类形成的所有5个聚类。
plt.figure(figsize=(7, 7))
sb.scatterplot(tsne_data[:, 0], tsne_data[:, 1], hue=segments)
plt.show()