Core Scheduling要解决什么问题?
core scheduling是v5.14中新增的功能,下图是内核数据结构为该功能所添加的字段。
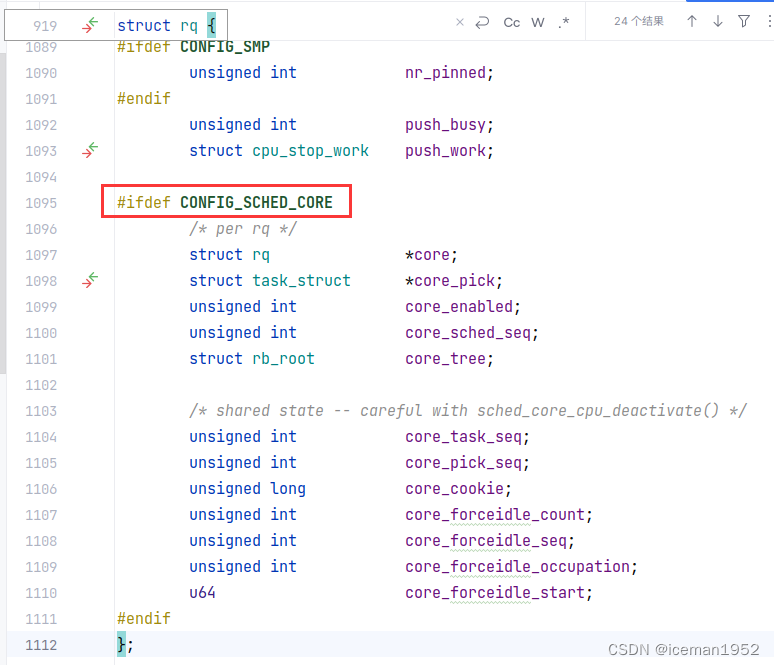
为什么有core scheduling呢?因为当开启超线程(HyperThreading)时,一个物理核就变成了两个逻辑核,但,这两个逻辑核还是要共享物理核的某些缓存,这种共享会带来安全问题(例如:MDS、L1TF等)。core scheduling就是要解决 开启超线程(HyperThreading)时所带来的安全问题。
假设,在两个逻辑核上同时在运行进程P1和P2,由于两个逻辑核来源于同一个物理核,两个逻辑核会共享某些资源,这样,P1就可能泄露数据给P2(反之亦然)。怎么解决呢?很简单,core scheduling添加了这种功能:cpu调度器确保, 在同一时刻,绝不让 “不互相信任的进程” 运行在同一个物理核上。对于上面的例子:
1. 如果用户指定了P1和P2互相信任,则,cpu调度器允许,在同一时刻,P1和P2可以运行在同一个物理核上。
2. 如果用户不指定P1和P2互相信任,则,cpu调度器绝不会让P1和P2,在同一个时刻,运行在同一个物理核上。
解释几个名称
本文翻译自 Core Scheduling — The Linux Kernel documentation,文档中出现了“core”, “siblings”等,这里的”core”是指物理核, “siblings”是指开启HT时,所产生的逻辑核。
当开启HT时,一个“core”就变成了两个“siblings”,即,一个物理核会变成两个逻辑核,所以才有我们说的“4核8线程”、“8核16线程”。
此外,当说到“thread”时,其实也是指逻辑核。
可以 cat /proc/cpuinfo 来查看cpu信息
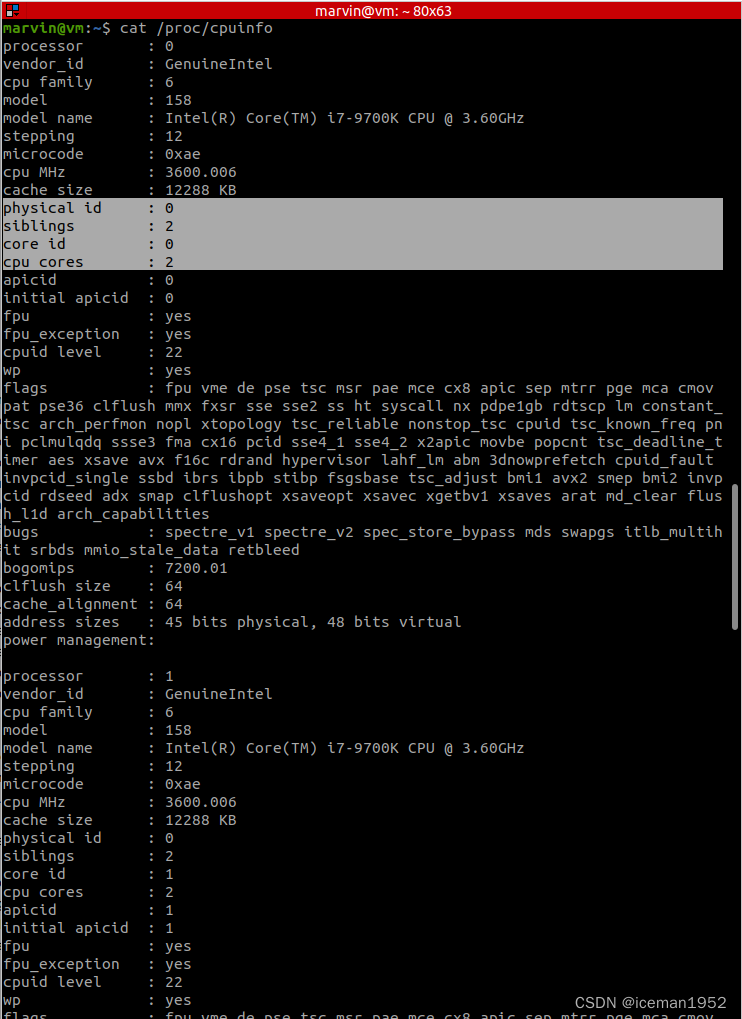
1. processor:每一个核(包括物理核以及由于HT而传送的逻辑核)。在kernel看来,无论物理核还是逻辑核,都是同等的核。
2. physical id:物理socket。同一个physical id上可以有多个物理核。
3. siblings:在该物理socket内,核的总个数(包括物理核以及由于HT而产生的逻辑核)。
4. core id:在该物理socket内,某个物理核的编号。跨物理socket时,core id会重复。
5. cpu cores:在当前物理socket内,物理核的个数。
怎么判断是否开启了HT呢,很简单:如果siblings == 2*(cpu cores),则开启了HT。
还可以 lscpu 来查看
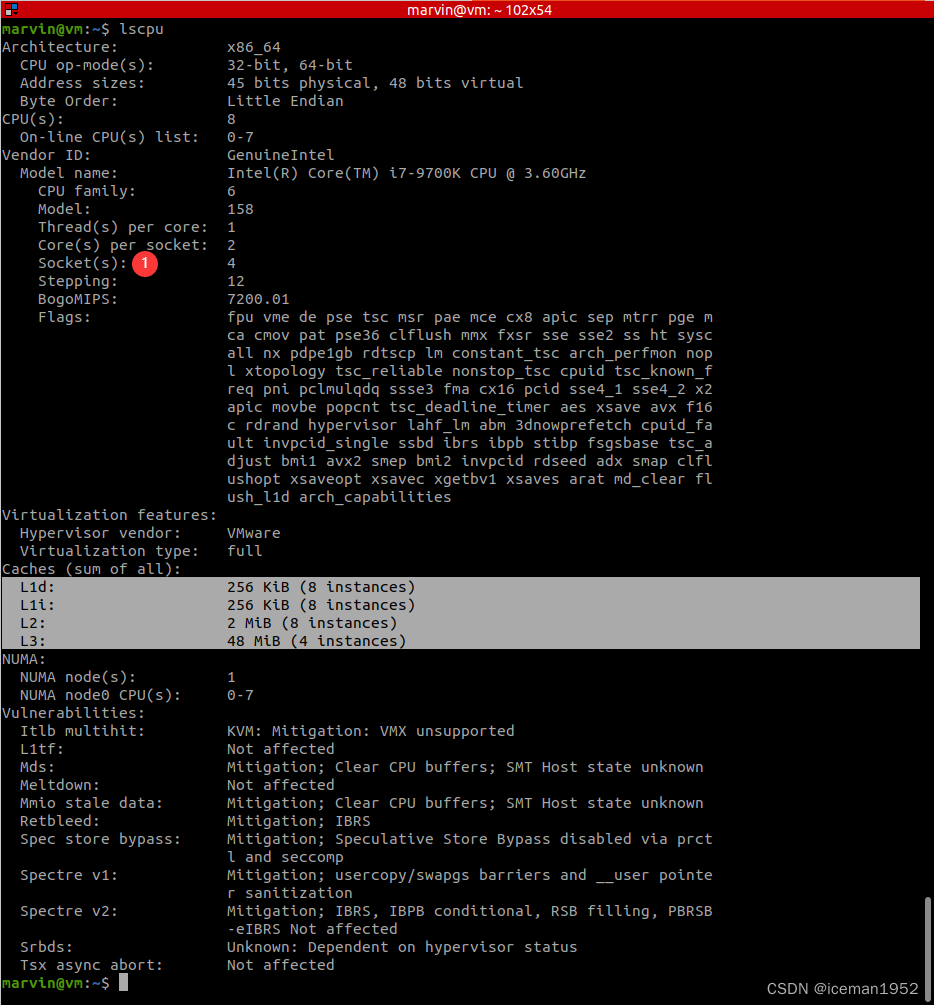
lscpu可以查看:
1. 物理socket 的个数。
2. 每个物理socket上 物理核的个数。
3. 每个物理核内逻辑核的个数。
Thread(s) per core: 1;每个物理核内,线程的个数。线程就是逻辑核。若开启HT,此处为2。我这里显示1,即并未开启HT。
Core(s) per socket: 2;每个物理socket内,物理核的个数。
Socket(s): 4;物理socket的个数。
再总结下
1. 同一个物理核会因为开启HT而变为两个核(即:两个逻辑核)。
2. 同一个物理核产生的两个逻辑核是可以并行执行某些指令的,但,两个逻辑核还会共享物理核的某些资源。
3. 在同一个时刻,当两个逻辑核执行的指令需要共享的资源时,那么,只能一个逻辑核运行,另一个等待。
以下翻译 Core Scheduling — The Linux Kernel documentation
正文开始
core scheduling允许userspace定义一组task,这一组task共享同一个core。用户或因为安全用例而分组(组内task 不信任 组外task),或因为性能用例而分组(有些workloads可能会从“运行在同一个core上”而受益,因为它们不需要被共享core上的同种硬件资源,或者,有些workloads更倾向于“运行在不同core上”,因为它们需要共享所需的硬件资源)。本文档仅描述安全用例。
Security usecase
cross-HT attack包含了attacker和victim,它们运行在同一个core的不同超线程上。MDS(Microarchitectural Data Sampling) 和 L1TF(L1 Terminal Fault)就是此类攻击。cross-HT attack唯一的彻底解决方案就是禁用超线程(Hyper Threading)。
core scheduling是scheduler的一个特性,它可以减缓(并不是根除)cross-HT attack。通过确保“只有位于用户指定信任组内的task才能够共享同一个core”,core scheudling就可以安全的开启HT。这种 core共享 还可以提高性能,尽管很多现实世界的实际workloads都显示core scheduling确实提高了性能,但,并不能100%确保它总是可以提高性能的。理论上,core scheduling的性能表现至少应该和HT被禁用时一样好。在实践中,绝大部情况也确实如此,但,也并非100%,这是因为在同一个core中,跨2个或更多个cpu 同步(synchronizing)调度决策引入了额外的overhead,尤其是当系统负载较轻时(lightly loaded),overhead就更为明显。相比于SMT-disabled(即关闭HT),total_threads <= N_CPUS/2时core scheduling引入的额外overhead会使得core scheduling表现更差,这里N_CPUS是cpu的总个数。所以,决定开启core scheduling前,你应该先测试workloads的表现。
Usage
core scheduling通过内核选项CONFIG_SCHED_CORE来开启或禁用。利用该特性,userspace定义一组task,希望这些task总是在同一core上被调度(同一个物理核,多个逻辑核)。利用这些信息,scheduler在满足系统调度需求的同时,确保,在同一个时刻,组内task 和 组外task 永远不会在同一个core上同时运行。
可以通过PR_SCHED_CORE prctl接口来开启core scheduling。该接口用于创建core scheduling组,以及从组中增删task。
#include <sys/prctl.h>
int prctl(int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5);
option:
PR_SCHED_CORE
arg2:
Command for operation, must be one off:
PR_SCHED_CORE_GET – get core_sched cookie of pid.
PR_SCHED_CORE_CREATE – create a new unique cookie for pid.
PR_SCHED_CORE_SHARE_TO – push core_sched cookie to pid.
PR_SCHED_CORE_SHARE_FROM – pull core_sched cookie from pid.
arg3:
pid of the task for which the operation applies.
arg4:
pid_type for which the operation applies.
It is one of PR_SCHED_CORE_SCOPE_-prefixed macro constants.
For example, if arg4 is PR_SCHED_CORE_SCOPE_THREAD_GROUP,
then the operation of this command will be performed
for all tasks in the task group of pid.
arg5:
userspace pointer to an unsigned long for
storing the cookie returned by PR_SCHED_CORE_GET command.
Should be 0 for all other commands.
进程必须得开启”PTRACE_MODE_READ_REALCREDS”的ptrace访问模式,这样,进程 才能够pull a cookie from a process或 push a cookie to a process。
Building hierarchies of tasks
The simplest way to build hierarchies of threads/processes which share a cookie and thus a core is to rely on the fact that the core-sched cookie is inherited across forks/clones and execs, thus setting a cookie for the ‘initial’ script/executable/daemon will place every spawned child in the same core-sched group.【写的什么鬼,看不懂】。
对于初始的’script/executable/daemon’设置cookie值,则由它们fork/clone/exec的子进程也就位于同一个core-sched组里面啦。
Cookie Transferral
可以在当前task和其他task之间传递cookie。使用PR_SCHED_CORE_SHARE_FROM 或 PR_SCHED_CORE_SHARE_TO 从一个特定的task继承cookie,或者向某个task共享cookie。结合起来,这允许一个简单的程序从位于core-sched的一个task中拖取cookie,然后将该cookie共享给已在运行的task。
Design/Implementation
每个被标记的task都在内核内部分配了一个 cookie。 如Usage中所述,具有相同 cookie 值的task相互信任,并共享同一个core。
基本思想是,每个调度事件都尝试为 core的所有siblings 选择task,以便,在任何时间点,所有选定的运行在同一个core上的task都是可信任的(即:具有相同的 cookie)。 kernel thread被认为总是可信任的。idle task也被认为是特殊的,因为它信任一切,一切也都信任它。
在任何一个core的siblings的调度事件期间,该siblings上的最高优先级的task被挑选出来并分配给调用 schedule()的siblings,如果该siblings有task入队。【写是什么鬼,看不懂。During a schedule() event on any sibling of a core, the highest priority task on the sibling’s core is picked and assigned to the sibling calling schedule(), if the sibling has the task enqueued. 】。对于core的其余siblings,如果siblings在它们自己的rq中有一个可运行的task,则选择具有相同 cookie 的最高优先级的task。如果具有相同 cookie 的task不可用,则选择idle task。 idle task是全局都被信任的。
一旦为core的所有siblings选择了一个task,就会给 选择了新task 的siblings 发送 IPI 。 收到 IPI 的siblings将立即切换到新task。 如果为siblings选择了idle task,则认为该siblings处于force idle状态。force idle的意思是,它的rq上可能有task要运行,但它仍然必须得执行idle task。下一节将详细介绍这一点。
Forced-idling of hyperthreads
scheduler尽其所能的找到彼此信任的task,从而,被选中调度所有task都是core内优先级最高的task。但,某些rq所持有tasks 与 core上最高优先级tasks并不兼容。相比于fairness,优选security,如果siblings的最高优先级的task 和 core范围内(一个core会有多个siblings)最高优先级task无法彼此信任,则,1或多个siblings可能会被强制选择一个低优先级的task。如果某个siblings不存在任何一个可信任的task,则,该siblings就被强制idle。
当选中的最高优先级的task运行时,reschedule-IPI事件会被发送到siblings,强制siblings进入idle。根据VM或普通usermode进程是否运行在HT,这会产生4种情况。
HT1 (attack) HT2 (victim)
A idle -> user space user space -> idle
B idle -> user space guest -> idle
C idle -> guest user space -> idle
D idle -> guest guest -> idle注意,为了更好的性能,我们并不会等待destination cpu(victim)进入idle模式。这是因为发送IPI会使得destination cpu立即从userspace进入kernel模式,或者,如果是guests虚拟机则立即进入VMEXIT。最多,这只会泄露一些无关紧要的调度元信息。还有可能,在某些架构上,IPI收到的可能会非常晚,不过,在x86上,这种情况尚未被观测到。
Trust model
通过给组内的task分配一个标记,即值相同的cookie值,core scheduling在组内的task间维护了信任关系。当启用core scheduling的系统启动时,所有task都被认为是信任彼此的。这是因为core scheduling并没有关于信任关系的任何信息,直到userspace使用上述的接口,kernel才用于组的信任关系。换句话说,所有task都有默认cookie值0,因此所有任务都是彼此信任的。需要避免forced-idling的siblings运行cookie值为0的task。
一旦userspace使用上述接口将task放入某个组,位于同一个组的task就信任彼此,这些task不再信任组外task,组外task也不会再信任它们。
Limitations of core-scheduling
core scheduling尝试确保只有被信任的task才可以同时运行在同一个core上。但,会有一个小的时间窗口,在此期间,不被信任的task也会同时运行在同一个core上,或,kernel和另外一个不被kernel所信任的task同时运行在同一个core上。
IPI processing delays
core scheduling只选择信任的task,让它们在同一个core上同时运行。IPI用于通知siblings要切换到新task上。但,在某些架构上,收取IPI可能存在硬件延迟,在x86上,这尚未被观察到。假设,cpu 1发送IPI,cpu 2是cpu 1的siblings,cpu 1发送了IPI,然后cpu 1上的attacker task开始运行了,但,cpu 2收到IPI太晚了,这就造成了,cpu 1和cpu 2上同时运行的并不是彼此信任的task。尽管,在进入user mode时,cache会被flush,在attacker开始运行之后,siblings上的victim task可能会在cache 和 micro architectural buffers中放置数据(于是attacker就可以访问到),这可能导致数据泄露。
Open cross-HT issues that core scheduling does not solve
1. For MDS
针对 “siblings同时运行user mode代码 和 kernel mode代码” 的攻击,core scheduling无法防护。即使所有的siblings运行的都是彼此信任的task,当kernel代表某个task执行代码时,kernel无法信任运行在siblings上的代码。对于任何siblings cpu组合模式(host模式 或guest模式),这种攻击是可能的。
2. For L1TF
针对 “L1TF guest attackter利用guest或host victim” 的攻击,core scheduling无法防护。这是因为guest attacker 可以构建无效的PTE,由于guest kernel的脆弱性 这种无效的PTE不能被反转。唯一的解决方式就是禁用EPT(Extended Page Tables)。
对于MDS和L1TF,如果guest vCPU被配置为不信任彼此(通过分开打tag的方式),那么,guest到guest的攻击就不存在啦。或者,设置系统管理策略 将guest to guest攻击当做是guest自己的问题。
另外一种解决方式是,让系统中的每一个 不被信任的task 不信任 任何其他 不被信任的task。当然,这会降低 不被信任task 的并行度,不过,这确实 在允许被信任task的进程共享同一个core的同时,解决上述问题。
3. Protecting the kernel (IRQ, syscall, VMEXIT)
不幸的是,core scheduling并不能保护 运行在siblings超线程上的kernel context免受 运行在其他siblings上的kernel context的打扰。解决方式的原型代码已被发布到LKML,以期解决该问题,但,这种窗口能否被实际利用,其所引入的性能overhead是否值的(更不用说,这增加了代码复杂度),依然值得商榷。
Other Use cases
core scheduling的主要用例是在SMT开启的前提下,减轻cross-HT的脆弱性。但,core scheduling还可以用在下面地方
1. 隔离 需要整个core的 task。这方面的例子包括realtime task,使用SIMD指令的task等。
2. 团伙scheduling(gang scheduling),一组task需要一起调度,这种需求也可以使用core scheduling。VM的vCPU就是该方面的一个例子。




![[ Linux ] 一篇带你理解Linux下线程概念](https://img-blog.csdnimg.cn/img_convert/83909507702c18c57defc37117c5b017.png)