1. 自动微分
自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。
1.1 基础概念
1. 张量 :Torch中一切皆为张量,属性requires_grad决定是否对其进行梯度计算。默认是 False,如需计算梯度则设置为True。
2. 计算图:torch.autograd通过创建一个动态计算图来跟踪张量的操作,每个张量是计算图中的一个节点,节点之间的操作构成图的边。
在 PyTorch 中,当张量的 requires_grad=True 时,PyTorch 会自动跟踪与该张量相关的所有操作,并构建计算图。每个操作都会生成一个新的张量,并记录其依赖关系。当设置为 True 时,表示该张量在计算图中需要参与梯度计算,即在反向传播(Backpropagation)过程中会自动计算其梯度;当设置为 False 时,不会计算梯度。
例如:
在上述代码中,x 和 y 是输入张量,即叶子节点,z 是中间结果,loss 是最终输出。每一步操作都会记录依赖关系:z = x * y:z 依赖于 x 和 y;loss = z.sum():loss 依赖于 z。
这些依赖关系形成了一个动态计算图,如下所示:
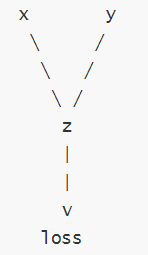
叶子节点:在 PyTorch 的自动微分机制中,叶子节点(leaf node) 是计算图中:
1. 由用户直接创建的张量,并且它的 requires_grad=True;
2. 这些张量是计算图的起始点,通常作为模型参数或输入变量。
特征:
1. 没有由其他张量通过操作生成;
2. 如果参与了计算,其梯度会存储在 leaf_tensor.grad 中;
3. 默认情况下,叶子节点的梯度不会自动清零,需要显式调用 optimizer.zero_grad() 或 x.grad.zero_() 清除。
如何判断一个张量是否是叶子节点?
通过 tensor.is_leaf 属性,可以判断一个张量是否是叶子节点。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) # 叶子节点
y = x ** 2 # 非叶子节点(通过计算生成)
z = y.sum()
print(x.is_leaf) # True
print(y.is_leaf) # False
print(z.is_leaf) # False叶子节点与非叶子节点的区别:
| 特性 | 叶子节点 | 非叶子节点 |
|---|---|---|
| 创建方式 | 用户直接创建的张量 | 通过其他张量的运算生成 |
| is_leaf 属性 | True | False |
| 梯度存储 | 梯度存储在 .grad 属性中 | 梯度不会存储在 .grad,只能通过反向传播传递 |
| 是否参与计算图 | 是计算图的起点 | 是计算图的中间或终点 |
| 删除条件 | 默认不会被删除 | 在反向传播后,默认被释放(除非 retain_graph=True) |
detach():张量 x 从计算图中分离出来,返回一个新的张量,与 x 共享数据,但不包含计算图(即不会追踪梯度)。
特点:
1. 返回的张量是一个新的张量,与原始张量共享数据;
2. 对 x.detach() 的操作不会影响原始张量的梯度计算;
3. 推荐使用 detach(),因为它更安全,且在未来版本的 PyTorch 中可能会取代 data。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x.detach() # y 是一个新张量,不追踪梯度
y += 1 # 修改 y 不会影响 x 的梯度计算
print(x) # tensor([1., 2., 3.], requires_grad=True)
print(y) # tensor([2., 3., 4.])3. 反向传播:使用tensor.backward()方法执行反向传播,从而计算张量的梯度。这个过程会自动计算每个张量对损失函数的梯度。例如:调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
4. 梯度:计算得到的梯度通过tensor.grad访问,这些梯度用于优化模型参数,以最小化损失函数。
1.2 计算梯度
使用tensor.backward()方法执行反向传播,从而计算张量的梯度。
1.2.1 标量梯度计算
示例:
import torch
def test001():
# 1. 创建张量:必须为浮点类型
x = torch.tensor(1.0, requires_grad=True)
# 2. 操作张量
y = x ** 2
# 3. 计算梯度,也就是反向传播
y.backward()
# 4. 读取梯度值
print(x.grad) # 输出: tensor(2.)
if __name__ == "__main__":
test001()1.2.2 向量梯度计算
示例:
def test003():
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 2. 操作张量
y = x ** 2
# 3. 计算梯度,也就是反向传播
y.backward()
# 4. 读取梯度值
print(x.grad)
if __name__ == "__main__":
test003() 错误预警:RuntimeError: grad can be implicitly created only for scalar outputs
由于 y 是一个向量,我们需要提供一个与 y 形状相同的向量作为 backward() 的参数,这个参数通常被称为 梯度张量(gradient tensor),它表示 y 中每个元素的梯度。
示例:
def test003():
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 2. 操作张量
y = x ** 2
# 3. 计算梯度,也就是反向传播
y.backward(torch.tensor([1.0, 1.0, 1.0]))
# 4. 读取梯度值
print(x.grad)
# 输出
# tensor([2., 4., 6.])
if __name__ == "__main__":
test003() 我们也可以将向量 y 通过一个标量损失函数(如 y.mean())转换为一个标量,反向传播时就不需要提供额外的梯度向量参数了。这是因为标量的梯度是明确的,直接调用 .backward() 即可。
示例:
import torch
def test002():
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 2. 操作张量
y = x ** 2
# 3. 损失函数
loss = y.mean()
# 4. 计算梯度,也就是反向传播
loss.backward()
# 5. 读取梯度值
print(x.grad)
if __name__ == "__main__":
test002() 调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
损失函数:,其中 n=3。
对于每个,其梯度为:
;
对于每个,其梯度为:
;
所以,x.grad 的值为:。
2.2.3 多标量梯度计算
示例:
import torch
def test003():
# 1. 创建两个标量
x1 = torch.tensor(5.0, requires_grad=True, dtype=torch.float64)
x2 = torch.tensor(3.0, requires_grad=True, dtype=torch.float64)
# 2. 构建运算公式
y = x1**2 + 2 * x2 + 7
# 3. 计算梯度,也就是反向传播
y.backward()
# 4. 读取梯度值
print(x1.grad, x2.grad)
# 输出:
# tensor(10., dtype=torch.float64) tensor(2., dtype=torch.float64)
if __name__ == "__main__":
test003()2.2.4 多向量梯度计算
示例:
import torch
def test004():
# 创建两个张量,并设置 requires_grad=True
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = torch.tensor([4.0, 5.0, 6.0], requires_grad=True)
# 前向传播:计算 z = x * y
z = x * y
# 前向传播:计算 loss = z.sum()
loss = z.sum()
# 查看前向传播的结果
print("z:", z) # 输出: tensor([ 4., 10., 18.], grad_fn=<MulBackward0>)
print("loss:", loss) # 输出: tensor(32., grad_fn=<SumBackward0>)
# 反向传播:计算梯度
loss.backward()
# 查看梯度
print("x.grad:", x.grad) # 输出: tensor([4., 5., 6.])
print("y.grad:", y.grad) # 输出: tensor([1., 2., 3.])
if __name__ == "__main__":
test004()1.3 梯度上下文控制
梯度计算的上下文控制和设置对于管理计算图、内存消耗、以及计算效率至关重要。下面我们学习下Torch中与梯度计算相关的一些主要设置方式。
1.3.1 控制梯度计算
梯度计算是有性能开销的,有些时候我们只是简单的运算,并不需要梯度。示例:
import torch
def test001():
x = torch.tensor(10.5, requires_grad=True)
print(x.requires_grad) # True
# 1. 默认y的requires_grad=True
y = x**2 + 2 * x + 3
print(y.requires_grad) # True
# 2. 如果不需要y计算梯度-with进行上下文管理
with torch.no_grad():
y = x**2 + 2 * x + 3
print(y.requires_grad) # False
# 3. 如果不需要y计算梯度-使用装饰器
@torch.no_grad()
def y_fn(x):
return x**2 + 2 * x + 3
y = y_fn(x)
print(y.requires_grad) # False
# 4. 如果不需要y计算梯度-全局设置,需要谨慎
torch.set_grad_enabled(False)
y = x**2 + 2 * x + 3
print(y.requires_grad) # False
if __name__ == "__main__":
test001()1.3.2 累计梯度
默认情况下,当我们重复对一个自变量进行梯度计算时,梯度是累加的。示例:
import torch
def test002():
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 5.3], requires_grad=True)
# 2. 累计梯度:每次计算都会累计梯度
for i in range(3):
y = x**2 + 2 * x + 7
z = y.mean()
z.backward()
print(x.grad)
if __name__ == "__main__":
test002()1.3.3 梯度清零
大多数情况下是不需要梯度累加的,奇葩的事情还是需要解决的。示例:
import torch
def test002():
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 5.3], requires_grad=True)
# 2. 累计梯度:每次计算都会累计梯度
for i in range(3):
y = x**2 + 2 * x + 7
z = y.mean()
# 2.1 反向传播之前先对梯度进行清零
if x.grad is not None:
x.grad.zero_()
z.backward()
print(x.grad)
if __name__ == "__main__":
test002()1.3.4 求函数最小值
代码:
import torch
from matplotlib import pyplot as plt
import numpy as np
def test01():
x = np.linspace(-10, 10, 100)
y = x ** 2
plt.plot(x, y)
plt.show()
def test02():
# 初始化自变量X
x = torch.tensor([3.0], requires_grad=True, dtype=torch.float)
# 迭代轮次
epochs = 50
# 学习率
lr = 0.1
list = []
for i in range(epochs):
# 计算函数表达式
y = x ** 2
# 反向传播
y.backward()
# 梯度下降,不需要计算梯度,为什么?
with torch.no_grad():
x -= lr * x.grad
# 梯度清零
x.grad.zero_()
print('epoch:', i, 'x:', x.item(), 'y:', y.item())
list.append((x.item(), y.item()))
# 散点图,观察收敛效果
x_list = [l[0] for l in list]
y_list = [l[1] for l in list]
plt.scatter(x=x_list, y=y_list)
plt.show()
if __name__ == "__main__":
test01()
test02()部分代码解释:
# 梯度下降,不需要计算梯度
with torch.no_grad():
x -= lr * x.grad代码中去掉梯度控制会报异常:
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation. 因为代码中x是叶子节点(叶子张量),是计算图的开始节点,并且设置需要梯度。在pytorch中不允许对需要梯度的叶子变量进行原地操作。因为这会破坏计算图,导致梯度计算错误。
在代码中,x 是一个叶子变量(即直接定义的张量,而不是通过其他操作生成的张量),并且设置了 requires_grad=True,因此不能直接通过 -= 进行原地更新。
解决方法:
1. 使用 torch.no_grad() 上下文管理器:在更新参数时,使用 torch.no_grad() 禁用梯度计算,然后通过非原地操作更新参数。
with torch.no_grad():
a -= lr * a.grad2. 使用 data 属性或detach():通过 x.data 访问张量的数据部分(不涉及梯度计算),然后进行原地操作。
x.data -= lr * x.gradx.data返回一个与 a 共享数据的张量,但不包含计算图。
特点:
1. 返回的张量与原始张量共享数据;
2. 对 x.data 的操作是原地操作(in-place),可能会影响原始张量的梯度计算;
3. 不推荐使用 data,因为它可能会导致意外的行为(如梯度计算错误)。
能不能将代码修改为:
x = x - lr * x.grad答案是不能,以上代码中=左边的x变量是由右边代码计算得出的,就不是叶子节点了,从计算图中被剥离出来后没有了梯度,执行。
x.grad.zero_() 报错:AttributeError: 'NoneType' object has no attribute 'zero_'。
总结:以上方均不推荐,正确且推荐的做法是使用优化器,优化器后续会讲解。
1.3.5 函数参数求解
代码:
def test02():
# 定义数据
x = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)
y = torch.tensor([3, 5, 7, 9, 11], dtype=torch.float)
# 定义模型参数 a 和 b,并初始化
a = torch.tensor([1], dtype=torch.float, requires_grad=True)
b = torch.tensor([1], dtype=torch.float, requires_grad=True)
# 学习率
lr = 0.1
# 迭代轮次
epochs = 1000
for epoch in range(epochs):
# 前向传播:计算预测值 y_pred
y_pred = a * x + b
# 定义损失函数
loss = ((y_pred - y) ** 2).mean()
# 反向传播:计算梯度
loss.backward()
# 梯度下降
with torch.no_grad():
a -= lr * a.grad
b -= lr * b.grad
a.grad.zero_()
b.grad.zero_()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
print(f'a: {a.item()}, b: {b.item()}') 代码逻辑:在 PyTorch 中,所有的张量操作都会被记录在一个计算图中。
对于代码:
y_pred = a * x + b
loss = ((y_pred - y) ** 2).mean()计算图如下:
a → y_pred → loss
x ↗
b ↗ 1. a 和 b 是需要计算梯度的叶子张量(requires_grad=True);
2. y_pred 是中间结果,依赖于 a 和 b;
3. loss 是最终的标量输出,依赖于 y_pred。
当调用 loss.backward() 时,PyTorch 会从 loss 开始,沿着计算图反向传播,计算 loss 对每个需要梯度的张量(如 a 和 b)的梯度。
计算 loss 对 y_pred 的梯度:
求损失函数关于 y_pred 的梯度(即偏导数组成的向量)。由于 loss 是 y_pred 的函数,我们需要对每个求偏导数,并将它们组合成一个向量。
应用链式法则和常数求导规则,对于每个项,梯度向量的每个分量是:
将结果组合成一个向量,我们得到:
其中n=5,y_pred和y均为向量。
计算 y_pred 对 a 和 b 的梯度:y_pred = a * x + b
对 a 求导:,x为向量;
对 b 求导:。
根据链式法则,loss 对 a 的梯度为:
loss 对 b 的梯度为:
第一次迭代:前向传播
y_pred = a * x + b = [1*1 + 1, 1*2 + 1, 1*3 + 1, 1*4 + 1, 1*5 + 1] = [2, 3, 4, 5, 6]
loss = ((y_pred - y) ** 2).mean() = ((2-3)^2 + (3-5)^2 + (4-7)^2 + (5-9)^2 + (6-11)^2) / 5 = (1 + 4 + 9 + 16 + 25) / 5 = 11.0反向传播:
∂loss/∂y_pred = 2/5 * (y_pred - y) = 2/5 * [-1, -2, -3, -4, -5] = [-0.4, -0.8, -1.2, -1.6, -2.0]
a.grad = ∂loss/∂a = ∂loss/∂y_pred * x = [-0.4*1, -0.8*2, -1.2*3, -1.6*4, -2.0*5] = [-0.4, -1.6, -3.6, -6.4, -10.0]对 a.grad 求和(因为 a 是标量):a.grad = -0.4 -1.6 -3.6 -6.4 -10.0 = -22.0
b.grad = ∂loss/∂b = ∂loss/∂y_pred * 1 = [-0.4, -0.8, -1.2, -1.6, -2.0]对 b.grad 求和(因为 b 是标量):b.grad = -0.4 -0.8 -1.2 -1.6 -2.0 = -6.0
梯度更新:
a -= lr * a.grad = 1 - 0.1 * (-22.0) = 1 + 2.2 = 3.2
b -= lr * b.grad = 1 - 0.1 * (-6.0) = 1 + 0.6 = 1.6代码运行结果:
Epoch [10/100], Loss: 3020.7896
Epoch [20/100], Loss: 1550043.3750
Epoch [30/100], Loss: 795369408.0000
Epoch [40/100], Loss: 408125767680.0000
Epoch [50/100], Loss: 209420457869312.0000
Epoch [60/100], Loss: 107459239932329984.0000
Epoch [70/100], Loss: 55140217861896667136.0000
Epoch [80/100], Loss: 28293929961149737992192.0000
Epoch [90/100], Loss: 14518387713533614273593344.0000
Epoch [100/100], Loss: 7449779870375595263567855616.0000
a: -33038608105472.0, b: -9151163924480.0 损失函数在训练过程中越来越大,表明模型的学习过程出现了问题。这是因为学习率(Learning Rate)过大,参数更新可能会“跳过”最优值,导致损失函数在最小值附近震荡甚至发散。解决方法:调小学习率,将lr=0.01。
代码运行结果:
Epoch [10/100], Loss: 0.0965
Epoch [20/100], Loss: 0.0110
Epoch [30/100], Loss: 0.0099
Epoch [40/100], Loss: 0.0092
Epoch [50/100], Loss: 0.0086
Epoch [60/100], Loss: 0.0081
Epoch [70/100], Loss: 0.0075
Epoch [80/100], Loss: 0.0071
Epoch [90/100], Loss: 0.0066
Epoch [100/100], Loss: 0.0062
a: 1.9492162466049194, b: 1.18334519863128662. 模型定义组件
模型(神经网络,深度神经网络,深度学习)定义组件帮助我们在 PyTorch 中定义、训练和评估模型等。
在进行模型训练时,有三个基础的概念我们需要颗粒度对齐下:
| 名词 | 定义 |
|---|---|
| Epoch | 使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练” |
| Batch | 使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据” |
| Iteration | 使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练” |
2.1 基本组件认知
先初步认知,他们用法基本一样的,后续在学习深度神经网络和卷积神经网络的过程中会很自然的学到更多组件。
官方文档:https://pytorch.org/docs/stable/nn.html
2.1.1 损失函数组件
PyTorch已内置多种损失函数,在构建神经网络时随用随取。文档:https://pytorch.org/docs/stable/nn.html#loss-functions
常用损失函数举例:
1. 均方误差损失(MSE Loss)
函数:torch.nn.MSELoss
公式:
适用场景:通常用于回归任务,例如预测连续值。
特点:对异常值敏感,因为误差的平方会放大较大的误差。
2. L1 损失(L1 Loss)(也叫做MAE(Mean Absolute Error,平均绝对误差))
函数:torch.nn.L1Loss
公式:
适用场景:用于回归任务,对异常值的敏感性较低。
特点:比 MSE 更鲁棒,但计算梯度时可能不稳定。
3. 交叉熵损失(Cross-Entropy Loss)
函数:torch.nn.CrossEntropyLoss
参数:reduction:mean-平均值,sum-总和
公式:
适用场景:用于多分类任务,输入是未经 softmax 处理的 logits。
特点:自带 softmax 操作,适合分类任务,能够有效处理类别不平衡问题。
4. 二元交叉熵损失(Binary Cross-Entropy Loss)
函数:torch.nn.BCELoss 或 torch.nn.BCEWithLogitsLoss
参数:reduction:mean-平均值,sum-总和
公式:
适用场景: 用于二分类任务。
特点: BCEWithLogitsLoss 更稳定,因为它结合了 Sigmoid 激活函数和 BCE 损失。
2.1.2 线性层组件
构建一个简单的线性层,后续还有卷积层(Convolution Layers)、池化层(Pooling layers)、激活(Non-linear Activations)、归一化等需要我们去学习和使用...
torch.nn.Linear(in_features, out_features, bias=True)参数说明:
in_features:
-
输入特征的数量(即输入数据的维度)。
-
例如,如果输入是一个长度为 100 的向量,则 in_features=100。
out_features:
-
输出特征的数量(即输出数据的维度)。
-
例如,如果希望输出是一个长度为 50 的向量,则 out_features=50。
bias:
-
是否使用偏置项(默认值为 True)。
-
如果设置为 False,则不会学习偏置项。
nn.Linear 的作用
nn.Linear 执行以下线性变换:output=input⋅W^T+b
其中:
-
input是输入数据,形状为 (batch_size, in_features)。
-
W是权重矩阵,形状为 (out_features, in_features)。
-
b是偏置项,形状为 (out_features,)。
-
output是输出数据,形状为 (batch_size, out_features)。
import torch
import torch.nn as nn
def test002():
model = nn.Linear(20, 60)
# input数据形状为:(batch_size,in_features),其中in_features要和Linear中的数量一致
input = torch.randn(128, 20)
output = model(input)
print(output.size())
if __name__ == "__main__":
test002()2.1.3 优化器方法
官方文档:https://pytorch.org/docs/stable/optim.html
这里牵涉到的API有:
1. optim.SGD():优化器方法;是 PyTorch 提供的随机梯度下降(Stochastic Gradient Descent, SGD)优化器。
2. model.parameters():模型参数获取;是一个生成器,用于获取模型中所有可训练的参数(权重和偏置)。
3. optimizer.zero_grad():梯度清零;
4. optimizer.step():参数更新;是优化器的核心方法,用于根据计算得到的梯度更新模型参数。优化器会根据梯度和学习率等参数,调整模型的权重和偏置。
import torch
import torch.nn as nn
import torch.optim as optim
# 优化方法SGD的学习
def test003():
model = nn.Linear(20, 60)
criterion = nn.MSELoss()
# 优化器:更新模型参数
optimizer = optim.SGD(model.parameters(), lr=0.01)
input = torch.randn(128, 20)
output = model(input)
# 计算损失及反向传播
loss = criterion(output, torch.randn(128, 60))
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新模型参数
optimizer.step()
print(loss.item())
if __name__ == "__main__":
test003()注意:这里只是组件认识和用法演示,没有具体的模型训练功能实现
2.2 数据加载器
2.2.1 构建数据类
1. Dataset类:
Dataset是一个抽象类,是所有自定义数据集应该继承的基类。它定义了数据集必须实现的方法。
必须实现的方法:1. __len__: 返回数据集的大小;2. __getitem__: 支持整数索引,返回对应的样本。
在 PyTorch 中,构建自定义数据加载类通常需要继承 torch.utils.data.Dataset 并实现以下几个方法:
__init__ 方法:用于初始化数据集对象:通常在这里加载数据,或者定义如何从存储中获取数据的路径和方法。
def __init__(self, data, labels):
self.data = data
self.labels = labels__len__ 方法:返回样本数量:需要实现,以便 Dataloader加载器能够知道数据集的大小。
def __len__(self):
return len(self.data)__getitem__ 方法:根据索引返回样本:将从数据集中提取一个样本,并可能对样本进行预处理或变换。
def __getitem__(self, index):
sample = self.data[index]
label = self.labels[index]
return sample, label如果你需要进行更多的预处理或数据变换,可以在__getitem__方法中添加额外的逻辑。
示例:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# 定义数据加载类
class CustomDataset(Dataset):
def __init__(self, data, labels):
"""
初始化数据集
:data: 样本数据(例如,一个 NumPy 数组或 PyTorch 张量)
:labels: 样本标签
"""
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, index):
index = min(max(index, 0), len(self.data) - 1)
sample = self.data[index]
label = self.labels[index]
return sample, label
def test001():
# 简单的数据集准备
data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)
data_y = torch.randn(data_x.shape[0], 1, dtype=torch.float32)
dataset = CustomDataset(data_x, data_y)
# 随便打印个数据看一下
print(dataset[0])
if __name__ == "__main__":
test001()2. TensorDataset类
TensorDataset是Dataset的一个简单实现,它封装了张量数据,适用于数据已经是张量形式的情况。
特点:
1. 简单快捷:当数据已经是张量形式时,无需自定义Dataset类;
2. 多张量支持:可以接受多个张量作为输入,按顺序返回;
3. 索引一致:所有张量的第一个维度必须相同,表示样本数量。
源码:
class TensorDataset(Dataset):
def __init__(self, *tensors):
# size(0)在python中同shape[0],获取的是样本数量
# 用第一个张量中的样本数量和其他张量对比,如果全部相同则通过断言,否则抛异常
assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)
self.tensors = tensors
def __getitem__(self, index):
return tuple(tensor[index] for tensor in self.tensors)
def __len__(self):
return self.tensors[0].size(0)示例:
def test03():
torch.manual_seed(0)
# 创建特征张量和标签张量
features = torch.randn(100, 5) # 100个样本,每个样本5个特征
labels = torch.randint(0, 2, (100,)) # 100个二进制标签
# 创建TensorDataset
dataset = TensorDataset(features, labels)
# 使用方式与自定义Dataset相同
print(len(dataset)) # 输出: 100
print(dataset[0]) # 输出: (tensor([...]), tensor(0))2.2.2 数据加载器
在训练或者验证的时候,需要用到数据加载器批量的加载样本。
DataLoader 是一个迭代器,用于从 Dataset 中批量加载数据。它的主要功能包括:
1. 批量加载:将多个样本组合成一个批次;
2. 打乱数据:在每个 epoch 中随机打乱数据顺序;
3. 多线程加载:使用多线程加速数据加载。
创建DataLoader:
# 创建 DataLoader
dataloader = DataLoader(
dataset, # 数据集
batch_size=10, # 批量大小
shuffle=True, # 是否打乱数据
num_workers=2 # 使用 2 个子进程加载数据
)遍历:
# 遍历 DataLoader
# enumerate返回一个枚举对象(iterator),生成由索引和值组成的元组
for batch_idx, (samples, labels) in enumerate(dataloader):
print(f"Batch {batch_idx}:")
print("Samples:", samples)
print("Labels:", labels)示例:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# 定义数据加载类
class CustomDataset(Dataset):
#略......
def test01():
# 简单的数据集准备
data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)
data_y = torch.randn(data_x.size(0), 1, dtype=torch.float32)
dataset = CustomDataset(data_x, data_y)
# 构建数据加载器
data_loader = DataLoader(dataset, batch_size=8, shuffle=True)
for i, (batch_x, batch_y) in enumerate(data_loader):
print(batch_x, batch_y)
break
if __name__ == "__main__":
test01()2.2.3 重构线性回归
示例:
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import random
from sklearn.datasets import make_regression
# 定义特征数
n_features = 5
"""
使用 sklearn 的 make_regression 方法来构建一个模拟的回归数据集。
make_regression 方法的参数解释:
- n_samples: 生成的样本数量,决定了数据集的规模。
- n_features: 生成的特征数量,决定了数据维度。
- n_informative: 对目标变量有影响的特征数量(默认 10)。
- n_targets: 目标变量的数量(默认 1,单输出回归)。
- bias: 目标变量的偏置(截距),默认 0.0。
- noise: 添加到目标变量的噪声标准差,用于模拟真实世界数据的不完美。
- coef: 如果为 True, 会返回生成数据的真实系数(权重),用于了解特征与目标变量间的真实关系。
- random_state: 随机数生成的种子,确保在多次运行中能够复现相同的结果。
返回:
- X: 生成的特征矩阵。X 的维度是 (n_samples, n_features)
- y: 生成的目标变量。y 的维度是(n_samples,) 或 (n_samples, n_targets)
- coef: 如果在调用时 coef 参数为 True,则还会返回真实系数(权重)。coef 的维度是 (n_features,)
"""
def build_dataset():
noise = random.randint(1, 3)
bias = 14.5
X, y, coef = make_regression(
n_samples=1000,
n_features=n_features,
bias=bias,
noise=noise,
coef=True,
random_state=0
)
# 数据转换为张量
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32)
coef = torch.tensor(coef, dtype=torch.float32)
bias = torch.tensor(bias, dtype=torch.float32)
return X, y, coef, bias
# 训练函数
def train():
# 0. 构建模型
model = nn.Linear(n_features, 1)
# 1. 构建数据集
X, y, coef, bias = build_dataset()
dataset = TensorDataset(X, y)
# 2. 定义训练参数
learning_rate = 0.1
epochs = 50
batch_size = 16
# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 3. 开始训练
for epoch in range(epochs):
# 4. 构建数据集加载器
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
epoch_loss = 0
num_batches = 0
for train_X, train_y in data_loader:
num_batches += 1
# 5. 前向传播
y_pred = model(train_X)
# 6. 计算损失,注意y_pred, train_y的形状保持一致
loss = criterion(y_pred, train_y.reshape(-1, 1))
# 7. 梯度清零
optimizer.zero_grad()
# 8. 反向传播:会自动计算梯度
loss.backward()
# 9. 更新参数
optimizer.step()
# 10. 训练批次及损失率
epoch_loss += loss.item()
print(f"Epoch: {epoch}, Loss: {epoch_loss / num_batches}")
# 获取训练好的权重和偏置
w = model.weight.detach().flatten() # 将 weight 转换为一维张量
b = model.bias.detach().item()
return coef, bias, w, b
if __name__ == "__main__":
coef, bias, w, b = train()
print(f"真实系数: {coef}")
print(f"预测系数: {w}")
print(f"真实偏置: {bias}")
print(f"预测偏置: {b}")
# 训练结果
'''
Epoch: 0, Loss: 515.9365651872423
Epoch: 1, Loss: 17.0213944949801
......
Epoch: 99, Loss: 16.81899456750779
真实系数: tensor([41.2059, 66.4995, 10.7145, 60.1951, 25.9615])
预测系数: tensor([41.2794, 67.1859, 11.3169, 59.5126, 25.6431])
真实偏置: 14.5
预测偏置: 14.348488807678223
'''2.3 数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
2.3.1 加载csv数据集
示例:
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pd
class MyCsvDataset(Dataset):
def __init__(self, filename):
df = pd.read_csv(filename)
# 删除文字列
df = df.drop(["学号", "姓名"], axis=1)
# 转换为tensor
data = torch.tensor(df.values)
# 最后一列以前的为data,最后一列为label
self.data = data[:, :-1]
self.label = data[:, -1]
self.len = len(self.data)
def __len__(self):
return self.len
def __getitem__(self, index):
idx = min(max(index, 0), self.len - 1)
return self.data[idx], self.label[idx]
def test001():
excel_path = r"./大数据答辩成绩表.csv"
dataset = MyCsvDataset(excel_path)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for i, (data, label) in enumerate(dataloader):
print(i, data, label)
if __name__ == "__main__":
test001()示例:上述示例数据构建器改成TensorDataset
def build_dataset(filepath):
df = pd.read_csv(filepath)
df.drop(columns=['学号', '姓名'], inplace=True)
data = df.iloc[..., :-1]
labels = df.iloc[..., -1]
x = torch.tensor(data.values, dtype=torch.float)
y = torch.tensor(labels.values)
dataset = TensorDataset(x, y)
return dataset
def test001():
filepath = r"./大数据答辩成绩表.csv"
dataset = build_dataset(filepath)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for i, (data, label) in enumerate(dataloader):
print(i, data, label)2.3.2 加载图片数据集
参考代码如下:只是用于文件读取测试
import torch
from torch.utils.data import Dataset, DataLoader
import os
# 导入opencv
import cv2
class MyImageDataset(Dataset):
def __init__(self, folder):
# 文件存储路径列表
self.filepaths = []
# 文件对应的目录序号列表
self.labels = []
# 指定图片大小
self.imgsize = (112, 112)
# 临时存储文件所在目录名
dirnames = []
# 递归遍历目录,root:根目录路径,dirs:子目录名称,files:子文件名称
for root, dirs, files in os.walk(folder):
# 如果dirs和files不同时有值,先遍历dirs,然后再以dirs的目录为路径遍历该dirs下的files
# 这里需要在dirs不为空时保存目录名称列表
if len(dirs) > 0:
dirnames = dirs
for file in files:
# 文件路径
filepath = os.path.join(root, file)
self.filepaths.append(filepath)
# 分割root中的dir目录名
classname = os.path.split(root)[-1]
# 根据目录名到临时目录列表中获取下标
self.labels.append(dirnames.index(classname))
self.len = len(self.filepaths)
def __len__(self):
return self.len
def __getitem__(self, index):
# 获取下标
idx = min(max(index, 0), self.len - 1)
# 根据下标获取文件路径
filepath = self.filepaths[idx]
# opencv读取图片
img = cv2.imread(filepath)
# 图片缩放,图片加载器要求同一批次的图片大小一致
img = cv2.resize(img, self.imgsize)
# 转换为tensor
img_tensor = torch.tensor(img)
# 将图片HWC调整为CHW
img_tensor = torch.permute(img_tensor, (2, 0, 1))
# 获取目录标签
label = self.labels[idx]
return img_tensor, label
def test02():
path = os.path.join(os.path.dirname(__file__), 'dataset')
# 转换为相对路径
path = os.path.relpath(path)
dataset = MyImageDataset(path)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
for img, label in dataloader:
print(img.shape)
print(label)
if __name__ == "__main__":
test02()1.重写上述代码,如果不对图片进行缩放会产生什么结果?2.在遍历图片的代码中打印图片查看图片效果(打印一批次即可)
# 导入opencv
import cv2
class MyDataset(Dataset):
def __init__(self, folder):
dirnames = []
self.filepaths = []
self.labels = []
for root, dirs, files in os.walk(folder):
if len(dirs) > 0:
dirnames = dirs
for file in files:
filepath = os.path.join(root, file)
self.filepaths.append(filepath)
classname = os.path.split(root)[-1]
if classname in dirnames:
self.labels.append(dirnames.index(classname))
else:
print(f'{classname} not in {dirnames}')
self.len = len(self.filepaths)
def __len__(self):
return self.len
def __getitem__(self, index):
idx = min(max(index, 0), self.len - 1)
filepath = self.filepaths[idx]
img = cv2.imread(filepath)
print(img.shape)
# 不做图片缩放,报:RuntimeError: stack expects each tensor to be equal size, but got [3, 1333, 2000] at entry 0 and [3, 335, 600] at entry 1
img = cv2.resize(img, (112, 112))
t_img = torch.tensor(img)
t_img = torch.permute(t_img, (2, 0, 1))
label = self.labels[idx]
return t_img, label
def test02():
path = os.path.join(os.path.dirname(__file__), 'dataset')
dataset = MyDataset(path)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for img, label in dataloader:
print(img.shape, label)
for i in range(img.shape[0]):
im = torch.permute(img[i], (1, 2, 0))
plt.imshow(im)
plt.show()
break
if __name__ == "__main__":
test02()ImageFolder会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。例如,一个典型的文件夹结构如下:
root/
class1/
img1.jpg
img2.jpg
...
class2/
img1.jpg
img2.jpg
...
...在这个结构中:
-
root是根目录。 -
class1、class2等是类别名称。 -
每个类别文件夹中的图像文件会被加载为一个样本。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)参数解释:
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。
示例:
import torch
from torchvision import datasets, transforms
import os
from torch.utils.data import DataLoader
from matplotlib import pyplot as plt
torch.manual_seed(42)
def load():
path = os.path.join(os.path.dirname(__file__), 'dataset')
print(path)
transform = transforms.Compose([
transforms.Resize((112, 112)),
transforms.ToTensor()
])
dataset = datasets.ImageFolder(path, transform=transform)
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
for x,y in dataloader:
x = x.squeeze(0).permute(1, 2, 0).numpy()
plt.imshow(x)
plt.show()
print(y[0])
break
if __name__ == '__main__':
load()2.3.3 加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:https://pytorch.org/vision/stable/datasets.html
常见数据集:
1. MNIST:手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像;
2. CIFAR10:包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像;
3. CIFAR100:包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像;
4. COCO:通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
示例:
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import transforms, datasets
def test():
transform = transforms.Compose(
[
transforms.ToTensor(),
]
)
# 训练数据集
data_train = datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform,
)
trainloader = DataLoader(data_train, batch_size=8, shuffle=True)
for x, y in trainloader:
print(x.shape)
print(y)
break
# 测试数据集
data_test = datasets.MNIST(
root="./data",
train=False,
download=True,
transform=transform,
)
testloader = DataLoader(data_test, batch_size=8, shuffle=True)
for x, y in testloader:
print(x.shape)
print(y)
break
def test006():
transform = transforms.Compose(
[
transforms.ToTensor(),
]
)
# 训练数据集
data_train = datasets.CIFAR10(
root="./data",
train=True,
download=True,
transform=transform,
)
trainloader = DataLoader(data_train, batch_size=4, shuffle=True, num_workers=2)
for x, y in trainloader:
print(x.shape)
print(y)
break
# 测试数据集
data_test = datasets.CIFAR10(
root="./data",
train=False,
download=True,
transform=transform,
)
testloader = DataLoader(data_test, batch_size=4, shuffle=False, num_workers=2)
for x, y in testloader:
print(x.shape)
print(y)
break
if __name__ == "__main__":
test()
test006()