本文讲解postgres中元组的插入流程,深入了解其实现原理。同时此过程涉及元组xmin/xmax与标识位的设置细节,与事务的可见性部分密切相关相关,借此复习一下。
heappage结构

执行流程框架图
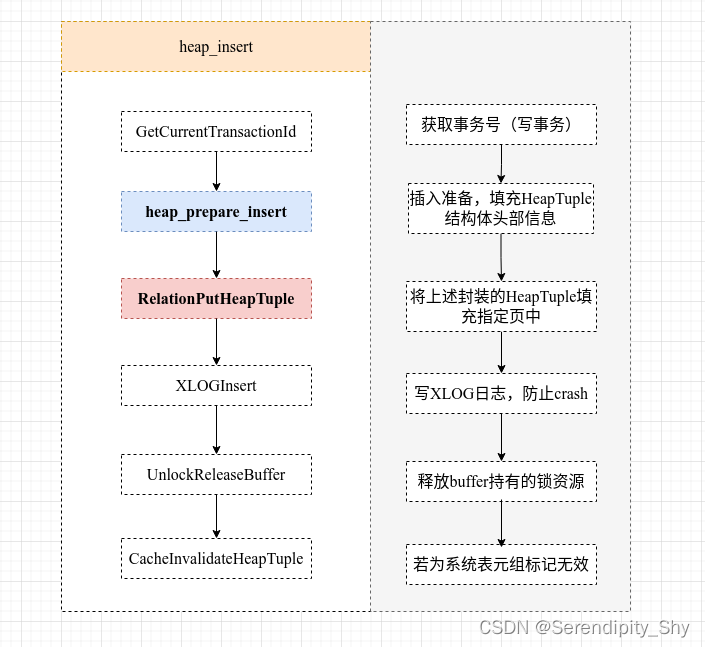
heap_prepare_insert
该函数执行内容较为简单,主要是设置HeapTuple结构体的头信息,包括标识位和xmin/xmax
/*
* Subroutine for heap_insert(). Prepares a tuple for insertion. This sets the
* tuple header fields and toasts the tuple if necessary. Returns a toasted
* version of the tuple if it was toasted, or the original tuple if not. Note
* that in any case, the header fields are also set in the original tuple.
*/
static HeapTuple
heap_prepare_insert(Relation relation, HeapTuple tup, TransactionId xid,
CommandId cid, int options)
{
/*
* To allow parallel inserts, we need to ensure that they are safe to be
* performed in workers. We have the infrastructure to allow parallel
* inserts in general except for the cases where inserts generate a new
* CommandId (eg. inserts into a table having a foreign key column).
*/
if (IsParallelWorker())
ereport(ERROR,
(errcode(ERRCODE_INVALID_TRANSACTION_STATE),
errmsg("cannot insert tuples in a parallel worker")));
tup->t_data->t_infomask &= ~(HEAP_XACT_MASK);
tup->t_data->t_infomask2 &= ~(HEAP2_XACT_MASK);
tup->t_data->t_infomask |= HEAP_XMAX_INVALID; // 先设置 XMAX_INVALID信息
HeapTupleHeaderSetXmin(tup->t_data, xid); // 设置xim
if (options & HEAP_INSERT_FROZEN)
HeapTupleHeaderSetXminFrozen(tup->t_data);
HeapTupleHeaderSetCmin(tup->t_data, cid); // 设置cid
HeapTupleHeaderSetXmax(tup->t_data, 0); /* for cleanliness */ // 设置 xmax
tup->t_tableOid = RelationGetRelid(relation); // 元组对应的表信息 OID
/*
* If the new tuple is too big for storage or contains already toasted
* out-of-line attributes from some other relation, invoke the toaster.
*
* 如果该元组超过TOAST元组阈值时,需要进行 toast元组的插入工作
*/
if (relation->rd_rel->relkind != RELKIND_RELATION &&
relation->rd_rel->relkind != RELKIND_MATVIEW)
{
/* toast table entries should never be recursively toasted */
Assert(!HeapTupleHasExternal(tup));
return tup;
}
else if (HeapTupleHasExternal(tup) || tup->t_len > TOAST_TUPLE_THRESHOLD)
return heap_toast_insert_or_update(relation, tup, NULL, options);
else
return tup;
}
RelationPutHeapTuple
该函数的功能是将上述准备的元组插入到指定页中,并更新该元组在页内的偏移量信息
/*
* RelationPutHeapTuple - place tuple at specified page
*
* !!! EREPORT(ERROR) IS DISALLOWED HERE !!! Must PANIC on failure!!!
*
* Note - caller must hold BUFFER_LOCK_EXCLUSIVE on the buffer.
*/
void
RelationPutHeapTuple(Relation relation,
Buffer buffer,
HeapTuple tuple,
bool token)
{
Page pageHeader;
OffsetNumber offnum;
/*
* A tuple that's being inserted speculatively should already have its
* token set.
*/
Assert(!token || HeapTupleHeaderIsSpeculative(tuple->t_data));
/*
* Do not allow tuples with invalid combinations of hint bits to be placed
* on a page. This combination is detected as corruption by the
* contrib/amcheck logic, so if you disable this assertion, make
* corresponding changes there.
*/
Assert(!((tuple->t_data->t_infomask & HEAP_XMAX_COMMITTED) &&
(tuple->t_data->t_infomask & HEAP_XMAX_IS_MULTI)));
/* Add the tuple to the page */
// 从buffer中获取对应物理页地址
pageHeader = BufferGetPage(buffer);
// 在页中获取指定空间位置并填充相关数据,细节在此处
offnum = PageAddItem(pageHeader, (Item) tuple->t_data,
tuple->t_len, InvalidOffsetNumber, false, true);
if (offnum == InvalidOffsetNumber)
elog(PANIC, "failed to add tuple to page");
/* Update tuple->t_self to the actual position where it was stored */
// 更新项指针的偏移量 ItemPointerData
ItemPointerSet(&(tuple->t_self), BufferGetBlockNumber(buffer), offnum);
/*
* Insert the correct position into CTID of the stored tuple, too (unless
* this is a speculative insertion, in which case the token is held in
* CTID field instead)
* 填充 heaptupleHeader CTID信息
*/
if (!token)
{
ItemId itemId = PageGetItemId(pageHeader, offnum);
HeapTupleHeader item = (HeapTupleHeader) PageGetItem(pageHeader, itemId);
item->t_ctid = tuple->t_self;
}
}
PageAddItemExtended
向page中增加一个Item,并按照heap页的结构插入对应位置,如果含有空闲项指针但未足够多的空间空间,则返回无效的 InvalidOffsetNumber,反之返回Item结构在page中偏移量。
/*
* PageAddItemExtended
*
* Add an item to a page. Return value is the offset at which it was
* inserted, or InvalidOffsetNumber if the item is not inserted for any
* reason. A WARNING is issued indicating the reason for the refusal.
*
* offsetNumber must be either InvalidOffsetNumber to specify finding a
* free line pointer, or a value between FirstOffsetNumber and one past
* the last existing item, to specify using that particular line pointer.
*
* If offsetNumber is valid and flag PAI_OVERWRITE is set, we just store
* the item at the specified offsetNumber, which must be either a
* currently-unused line pointer, or one past the last existing item.
*
* 如果offsetNumber有效且设置 PAI_OVERWRITE标识,需判断item是否使用,如使用则打印warnin日志,
* 返回InvalidOffsetNumber;
*
* If offsetNumber is valid and flag PAI_OVERWRITE is not set, insert
* the item at the specified offsetNumber, moving existing items later
* in the array to make room.
*
* 如果offsetNumber有效但未设置 PAI_OVERWRITE标识,则插入指定位置,并将原位置后的item向后移动
* If offsetNumber is not valid, then assign a slot by finding the first
* one that is both unused and deallocated.
*
* 如果offsetNumber无效,则分配第一个未使用的item槽
*
* If flag PAI_IS_HEAP is set, we enforce that there can't be more than
* MaxHeapTuplesPerPage line pointers on the page.
*
* 如果设置 PAI_IS_HEAP,则 offsetNumber 不许超过页内最大元组数
* !!! EREPORT(ERROR) IS DISALLOWED HERE !!!
*/
OffsetNumber
PageAddItemExtended(Page page,
Item item,
Size size,
OffsetNumber offsetNumber,
int flags)
{
PageHeader phdr = (PageHeader) page;
Size alignedSize;
int lower;
int upper;
ItemId itemId;
OffsetNumber limit;
bool needshuffle = false;
/*
* Be wary about corrupted page pointers
*/
if (phdr->pd_lower < SizeOfPageHeaderData ||
phdr->pd_lower > phdr->pd_upper ||
phdr->pd_upper > phdr->pd_special ||
phdr->pd_special > BLCKSZ)
ereport(PANIC,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("corrupted page pointers: lower = %u, upper = %u, special = %u",
phdr->pd_lower, phdr->pd_upper, phdr->pd_special)));
/*
* Select offsetNumber to place the new item at
*/
limit = OffsetNumberNext(PageGetMaxOffsetNumber(page));
/* was offsetNumber passed in? */
if (OffsetNumberIsValid(offsetNumber))
{
/* yes, check it */
if ((flags & PAI_OVERWRITE) != 0)
{
if (offsetNumber < limit)
{
itemId = PageGetItemId(phdr, offsetNumber);
if (ItemIdIsUsed(itemId) || ItemIdHasStorage(itemId))
{
elog(WARNING, "will not overwrite a used ItemId");
return InvalidOffsetNumber;
}
}
}
else
{
if (offsetNumber < limit)
needshuffle = true; /* need to move existing linp's */
}
}
else
{
/* offsetNumber was not passed in, so find a free slot */
/* if no free slot, we'll put it at limit (1st open slot) */
if (PageHasFreeLinePointers(phdr))
{
/*
* Scan line pointer array to locate a "recyclable" (unused)
* ItemId.
*
* Always use earlier items first. PageTruncateLinePointerArray
* can only truncate unused items when they appear as a contiguous
* group at the end of the line pointer array.
*/
for (offsetNumber = FirstOffsetNumber;
offsetNumber < limit; /* limit is maxoff+1 */
offsetNumber++)
{
itemId = PageGetItemId(phdr, offsetNumber);
/*
* We check for no storage as well, just to be paranoid;
* unused items should never have storage. Assert() that the
* invariant is respected too.
*/
Assert(ItemIdIsUsed(itemId) || !ItemIdHasStorage(itemId));
if (!ItemIdIsUsed(itemId) && !ItemIdHasStorage(itemId))
break;
}
if (offsetNumber >= limit)
{
/* the hint is wrong, so reset it */
PageClearHasFreeLinePointers(phdr);
}
}
else
{
/* don't bother searching if hint says there's no free slot */
offsetNumber = limit;
}
}
/* Reject placing items beyond the first unused line pointer */
if (offsetNumber > limit)
{
elog(WARNING, "specified item offset is too large");
return InvalidOffsetNumber;
}
/* Reject placing items beyond heap boundary, if heap */
if ((flags & PAI_IS_HEAP) != 0 && offsetNumber > MaxHeapTuplesPerPage)
{
elog(WARNING, "can't put more than MaxHeapTuplesPerPage items in a heap page");
return InvalidOffsetNumber;
}
/*
* Compute new lower and upper pointers for page, see if it'll fit.
*
* Note: do arithmetic as signed ints, to avoid mistakes if, say,
* alignedSize > pd_upper.
*/
if (offsetNumber == limit || needshuffle)
lower = phdr->pd_lower + sizeof(ItemIdData);
else
lower = phdr->pd_lower;
alignedSize = MAXALIGN(size);
upper = (int) phdr->pd_upper - (int) alignedSize;
if (lower > upper)
return InvalidOffsetNumber;
/*
* OK to insert the item. First, shuffle the existing pointers if needed.
*/
itemId = PageGetItemId(phdr, offsetNumber);
if (needshuffle)
memmove(itemId + 1, itemId,
(limit - offsetNumber) * sizeof(ItemIdData));
/* set the line pointer */
ItemIdSetNormal(itemId, upper, size);
/*
* Items normally contain no uninitialized bytes. Core bufpage consumers
* conform, but this is not a necessary coding rule; a new index AM could
* opt to depart from it. However, data type input functions and other
* C-language functions that synthesize datums should initialize all
* bytes; datumIsEqual() relies on this. Testing here, along with the
* similar check in printtup(), helps to catch such mistakes.
*
* Values of the "name" type retrieved via index-only scans may contain
* uninitialized bytes; see comment in btrescan(). Valgrind will report
* this as an error, but it is safe to ignore.
*/
VALGRIND_CHECK_MEM_IS_DEFINED(item, size);
/* copy the item's data onto the page */
memcpy((char *) page + upper, item, size);
/* adjust page header */
phdr->pd_lower = (LocationIndex) lower;
phdr->pd_upper = (LocationIndex) upper;
return offsetNumber;
}
以重用item为例【ItemIdData结构体为4字节,大小固定 重用的依据】:
如图所示:由于经过更新或者删除操作,项指针 item3空闲
- 首先会遍历页内已有的所有item,找到第一个未使用的item进行分配
2)重用的话空闲下边界不变(pd_lower),上边界会发生改变 (pd_upper - sizelen); - 调用memcpy进行数据的拷贝,并更新pageheader结构体信息




![[ Linux ] 一篇带你理解Linux下线程概念](https://img-blog.csdnimg.cn/img_convert/83909507702c18c57defc37117c5b017.png)