背景
最近订单表遇到大数据量的问题,并且表中随着时间的积累会变得更大,当数据量较大时,存储的物理文件会变得非常大、使用性能很差。
我们用的是GaussDB。为了提高查询效率,建议表大于500w进行分区,所以在规划阶段我们就进行分区。根据公司业务发展评估,按照年进行表分区。目的就是缓解磁盘io,提高查询效率。
解决方式
文件太大,常用思路是拆表、减少单表数据量,这样每个表文件变小、性能和维护都会更容易。
一般有两种拆分方式:
水平拆分。即同个结构的表建多个,按一定规则将不同的行放到不同的表。
按主键、数据所属用户或其他列,使用Hash、一致性Hash、Hash字典等方式
垂直拆分。将不同的表放到不同的数据库。
一般按业务模块拆分。
方式:MySQL partition
根据我的的需求,按照创建时间按照年分区
分区命令:
将表ar_sale_order_to_c 根据创建时间creation_date
创建时间格式为:(2023-07-04 04:30:29),需要用年,所以通过函数 YEAR(creation_date) 获取字段年,然后进行分区
ALTER TABLE ar_sale_order_to_c PARTITION BY RANGE (YEAR(creation_date)) (
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026),
PARTITION p2026 VALUES LESS THAN (2027),
PARTITION p2027 VALUES LESS THAN (2028),
PARTITION p2028 VALUES LESS THAN (2029),
PARTITION p2029 VALUES LESS THAN (2030),
PARTITION p202X VALUES LESS THAN (MAXVALUE)
);
常见问题
分区键(用来分区的列)须同时存在于所有的primary key和unique key中,这是最容易出现问题。
我的表结构:
CREATE TABLE `ar_sale_order_to_c` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`order_number` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '订单号',
`company_code` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '所属公司',
`sales_organization` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '销售组织(弃用)',
`batch_number` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '订单批次号',
`source_system` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '来源系统',
`order_type` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '订单类型',
`rcc_status` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '对账状态',
`rcc_date` datetime DEFAULT NULL COMMENT '对账完成时间',
`order_reason` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '订单原因',
`source_platform` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '来源平台',
`platform_order_number` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '来源平台订单号',
`currency` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '币种',
`client` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '客户(shop_code)',
`manual_orders_flag` varchar(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '是否为手工订单',
`source_number` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '关联订单编号',
`distribute_channel` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '分销渠道',
`interface_call_time` datetime DEFAULT NULL COMMENT '接口时间戳',
`statement_number` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '原始账单号',
`discount_amount` decimal(20,6) DEFAULT NULL COMMENT '优惠金额',
`order_create_time` datetime DEFAULT NULL COMMENT '订单时间戳',
`merchant_remarks` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '商家备注',
`shipping_location` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '发货库位',
`sales_channel` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '销售渠道',
`sales_channel_des` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '销售渠道描述',
`delivery_gen_flag` varchar(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT 'N' COMMENT '是否生成为交货单确认信息',
`tenant_id` bigint NOT NULL DEFAULT '0' COMMENT '租户ID',
`object_version_number` bigint DEFAULT '1' COMMENT '行版本号,用来处理锁',
`creation_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`created_by` bigint NOT NULL DEFAULT '-1',
`last_update_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`last_updated_by` bigint NOT NULL DEFAULT '-1',
`partion_value` bigint DEFAULT NULL COMMENT '分库值',
PRIMARY KEY (`order_id`) USING BTREE,
UNIQUE KEY `ar_sale_order_to_c_u1` (`order_number`,`tenant_id`) USING BTREE,
KEY `ar_sale_order_to_c_n1` (`statement_number`,`tenant_id`) USING BTREE,
KEY `ar_sale_order_to_c_n3` (`source_platform`,`tenant_id`) USING BTREE,
KEY `ar_sale_order_to_c_n4` (`platform_order_number`,`tenant_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=5299 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='订单头(C端)';
因为我的分区键(用来分区的列)没有同时存在于所有的primary key和unique key中。所以创建分区键会报错
1、分区键不在primary key
报错提示:
A PRIMARY KEY must include all columns in the table's partitioning function
解决方式:
在 primary key中增加分区键creation_date
alter table ar_sale_order_to_c drop primary key,add primary key (`order_id`,`creation_date`);
2、分区键不在unique key
报错提示:
A UNIQUE INDEX must include all columns in the table's partitioning function
解决方式
在unique key中增加分区键creation_date
alter table ar_sale_order_to_c drop index `ar_sale_order_to_c_u1`;
alter table ar_sale_order_to_c add unique key `ar_sale_order_to_c_u1` (`order_number`,`tenant_id`,`creation_date`);
最后:在重新执行以上得创建分区命令。
验证
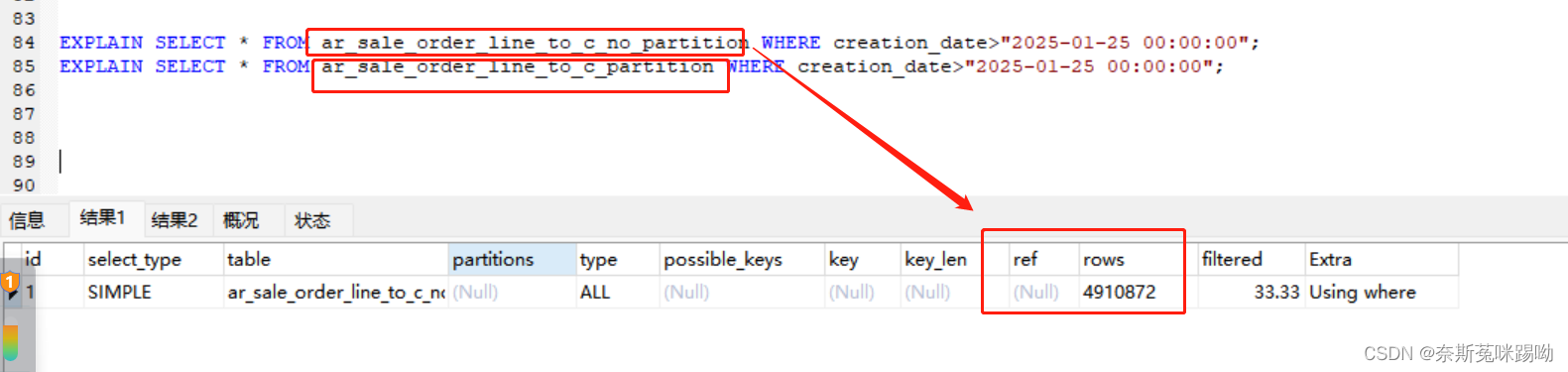
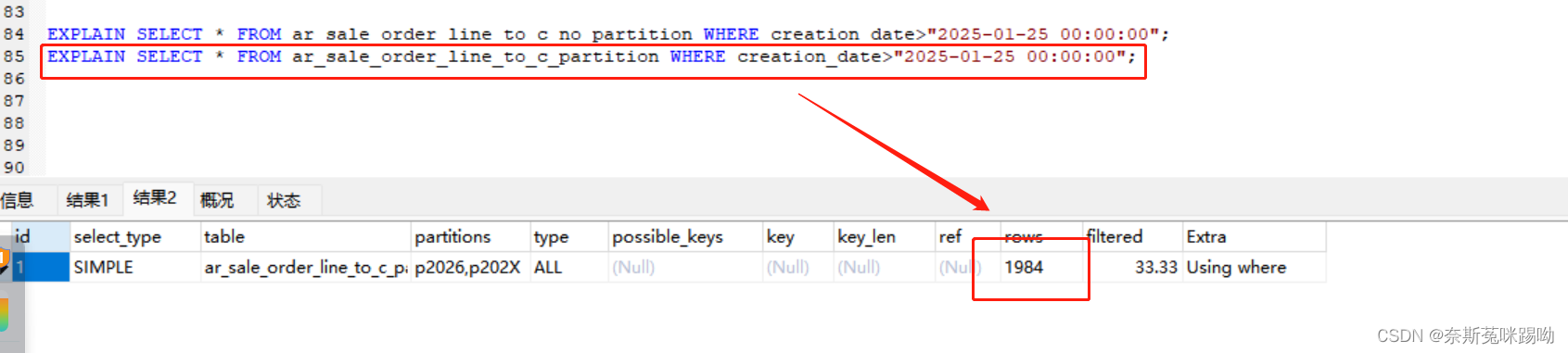
为了验证以下两张表一个分区一个没有分区,数据都是一样得
ar_sale_order_line_to_c_no_partition(为分区)
ar_sale_order_line_to_c_partition(已分区)
未分区得表示例查询扫描4910872条数据
分区后表查询示例扫描:1984
执行时间:
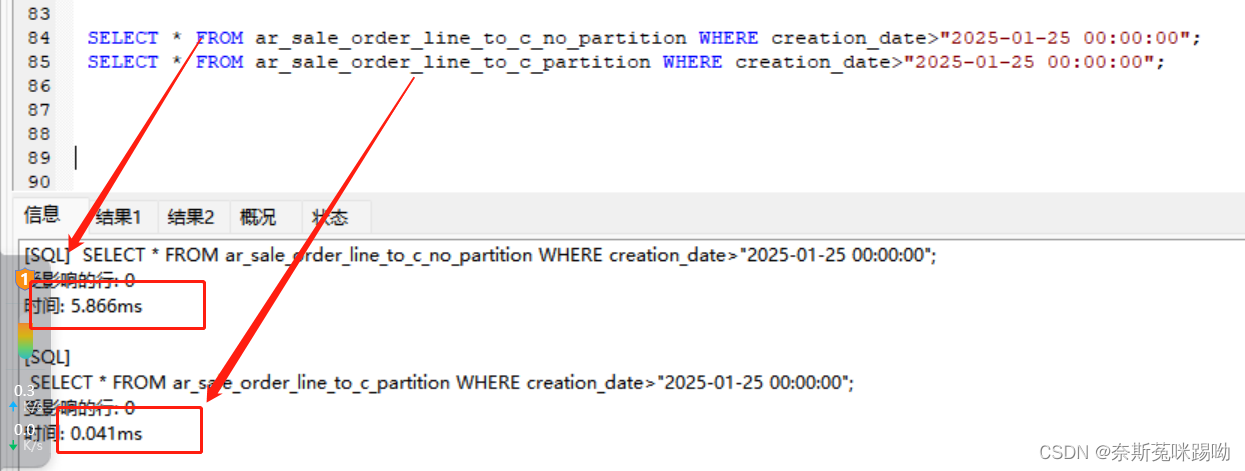
结论
分区后,查询效率极大得提升