Go实现Redis集群
这章的内容是将我们之前实现的单机版的Redis扩充成集群版,给Redis增加集群功能,在增加集群功能之前,我们先学习一下在分布式系统中引用非常广泛的技术一致性哈希,一致性哈希在我们项目里就应用在我们Redis集群的搭建这块
详解一致性哈希
Redis集群需求背景
单台服务器的CPU和内存等资源总是有限的,随着数据量和访问量的增加单台服务器很容易遇到瓶颈。利用多台机器建立分布式系统,分工处理是提高系统容量和吞吐量的常用方法。在Redis中当单节点请求的计算能力、单节点的吞吐量、单节点的容量不足的时候就有了Redis集群的需求
Redis集群的效果
多个节点在逻辑上等同于一个Redis核心库,当客户端想要保存一个kv时,客户端不知道这kv存到哪个节点,客户端只会把这个kv发送到他连接的节点,所有节点就负责把key应该去的节点识别出来,然后把key转发到他要去的节点
一致性哈希算法
我们是根据什么规则规定key去指定他要去的节点呢,就是我们之前我们学到的哈希,哈希函数对key哈希再取余,这种传统哈希的弊端是当我们新增节点后,再对key哈希取余时前面节点保存的键值就都有问题了,放置的节点号就不对了,此时我们就需要对所有的节点里的kv重新取余,重新分配新的节点,这样做的开销非常巨大,于是为了增删节点数量时数据迁移的便利性就引出了一致性哈希算法
算法原理
一致性 hash 算法的目的是在节点数量 n 变化时, 使尽可能少的 key 需要进行节点间重新分布。一致性 hash 算法将数据 key 和服务器地址 addr 散列到 2^32 的空间中。我们将 2^32 个整数首尾相连形成一个环,首先计算服务器地址 addr 的 hash 值放置在环上。然后计算 key 的 hash 值放置在环上,顺时针查找,将数据放在找到的的第一个节点上
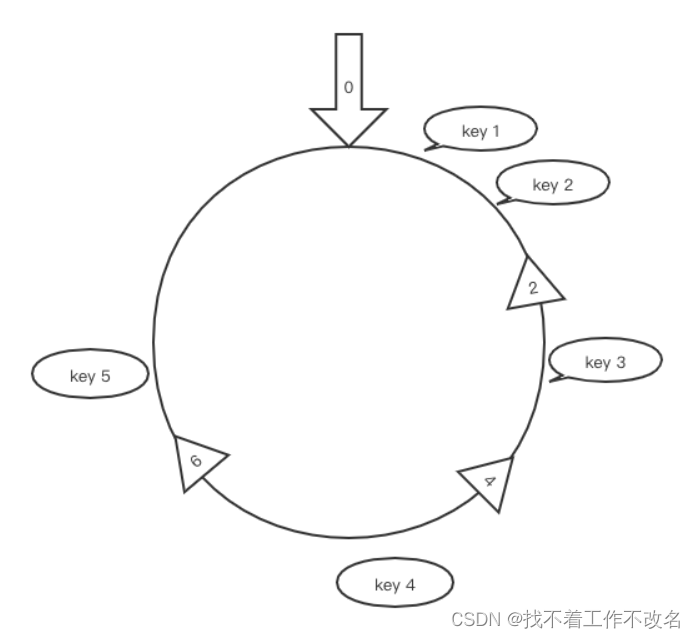
- key1, key2 和 key5 在 node2 上,key 3 在 node4 上,key4 在 node6 上
在增加或删除节点时只有该节点附近的数据需要重新分布,从而解决了上述问题
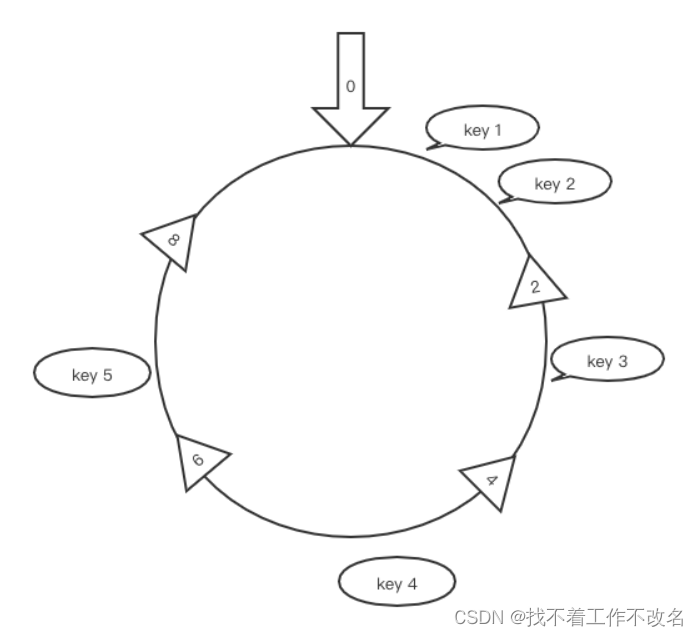
- 新增 node8 后,key 5 从 node2 转移到 node8。其它 key 不变
实现一致性哈希
在lib包中新建consistenthash包,在consistenthash.go中定义一致性哈希处理器NodeMap结构体,它存储的是我们所有节点的一致性哈希的信息,首先是存储我们要用到的哈希函数,第二个成员是各个节点的哈希值,按顺序存储,第三个成员是map,key是第二个成员哈希值,value是nodeA这种字符串或者是端口地址,他记录的是这个哈希节点在哪
type HashFunc func(data []byte) uint32
type NodeMap struct {
hashFunc HashFunc
nodeHashs []int //12343,59898
nodehashMap map[int]string //节点 hash 值到物理节点地址的映射
}
然后是New方法,他的入参是我们自定义的哈希函数
func NewNodeMap(fn HashFunc) *NodeMap {
m := &NodeMap{
hashFunc: fn,
nodehashMap: make(map[int]string),
}
if m.hashFunc == nil {
m.hashFunc = crc32.ChecksumIEEE
}
return m
}接下来定义一个IsEmpty方法用来判断一致性哈希或者整个Redis集群为空,还没有被初始化
func (m *NodeMap) IsEmpty() bool {
return len(m.nodeHashs) == 0
}再就是AddNode方法将新的节点加入到一致性哈希这个环中,该函数的业务逻辑首先是把我们加进来节点的名称做一个哈希放到切片里面去,然后对哈希值排序,接下来将哈希值和节点名称对应的kv放到上面的map中去
func (m *NodeMap) AddNode(keys ...string) {
for _, key := range keys {
if key == "" {
continue
}
hash := int(m.hashFunc([]byte(key)))
m.nodeHashs = append(m.nodeHashs, hash)
m.nodehashMap[hash] = key
}
sort.Ints(m.nodeHashs)
}最后要实现的方法是PickNode,也就是最终的目的,明确每个key要去哪个节点,通过传入的key返回value节点,需要注意的是Search方法,他的入参是切片的长度和一个方法,这个方法是用来判断符不符合我们自定义的条件,return的就是条件判断,这个Search方法返回的是就是我们要找的节点的序号,根据节点序号就可以找到节点哈希值
![Tecnomatix Plant Simulation 2302切换本地帮助的方法[2302]](https://img-blog.csdnimg.cn/3cbd009a783d4a7297a136024605d861.png)