《Python Cookbook》的作者David Beazley的课程PPT开源了,目标用户是希望从编写基础脚本过渡到编写更复杂程序的高级 Python 程序员,课程主题侧重于流行库和框架中使用的编程技术,主要目的是更好地理解 Python 语言本身,以便阅读他人的代码,并将新发现的知识应用到自己的项目中。内容组织的很棒,总共分为九个章节,我在阅读过程中顺便翻译整理下,用来查缺补漏了。翻译内容并非原版无对照翻译,有所增减,第一节内容是快速过了下Python基础知识,我这里直接跳过从第二节开始。更多硬核内容可以移步 LLM应用全栈开发
感兴趣可前往原课件进行阅读👉 https://github.com/dabeaz-course/python-mastery/blob/main/PythonMastery.pdf
数据结构
真正的程序必须处理复杂的数据,这里以持有股票为例探索了如何为对象选择合适的数据结构。100 shares of GOOG at $490.10
-
元组表示
-
s = (‘GOOG’, 100, 490.1)
-
可以像数组一样使用:name = s[0]
-
Unpacking并分配给单独的变量:name, shares, price = s
-
不可变:s[1] = 75 # TypeError. No item assignment
-
-
字典表示
-
s = { 'name' : 'GOOG', 'shares' : 100, 'price' : 490.1 } -
使用键访问:name = s[‘name’]
-
允许修改:s[‘shares’] = 75,s[‘date’] = '7/25/2015‘,del s[‘name’]
-
-
自定义类
-
class Stock: def __init__(self, name, shares, price): self.name = name self.shares = shares self.price = price -
使用对象进行操作
>>> s = Stock('GOOG', 100, 490.1) >>> s.name 'GOOG' >>> s.shares * s.price 49010.0 >>>
-
-
类的变体
-
Slots(插槽)
插槽是一种用于定义类的特殊属性,它可以用来限制实例的属性。通过使用插槽,你可以显式地指定一个类的实例应具有哪些属性,从而节省内存空间。当你定义了插槽时,每个实例只会为插槽中的属性分配内存,而不会为其他属性分配内存,这对于大量实例化的类或具有大量属性的类来说,可以显著减少内存消耗。
class Stock: __slots__ = ('name', 'shares', 'price') def __init__(self, name, shares, price): self.name = name self.shares = shares self.price = price -
Dataclasses(数据类)
数据类是Python 3.7及更高版本中的一个装饰器,用于简化创建带有属性的类的过程。
通过在类定义上添加
@dataclass装饰器,你可以自动获得一些常见的方法,如__init__、__repr__、__eq__等,而无需显式编写这些方法。数据类还提供了一种简洁的语法来定义属性,并可以自动生成属性的默认值和类型注解。这样可以减少编写样板代码的工作量,并使类定义更加简洁和易读。from dataclasses import dataclass @dataclass class Stock: name : str shares : int price: float -
Named Tuples(命名元组)
命名元组是一种具有命名字段的不可变(immutable)的数据结构,类似于元组(tuple)和字典(dictionary)的结合体。与普通的元组不同,命名元组的每个字段都有一个名称,可以通过名称进行访问,而不仅仅是通过索引。命名元组的字段是不可变的,这意味着一旦创建了命名元组的实例,就不能修改其字段的值。命名元组具有类似元组的性质,可以进行Unpacking操作、迭代和比较,但是字段的名称提供了更好的可读性和代码的自文档性。命名元组适用于表示简单的数据记录,其中字段的值不会发生变化。
import typing class Stock(typing.NamedTuple): name: str shares: int price: float>>> s = Stock('GOOG', 100, 490.1) >>> s[0] 'GOOG' >>> name, shares, price = s >>> print('%10s %10d %10.2f' % s) GOOG 100 490.10 >>> isinstance(s, tuple) True >>> s.name = 'ACME' Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute >>>
-
容器
-
列表
-
当数据顺序很重要时使用列表
-
元组列表
portfolio = [ ('GOOG', 100, 490.1), ('IBM', 50, 91.1), ('CAT', 150, 83.44) ] portfolio[0] ->('GOOG', 100, 490.1) portfolio[1] ->('IBM', 50, 91.1) -
列表可以排序和重新排列
-
-
集合
-
集合是唯一项的无序集合
-
集合消除重复
names = ['IBM','YHOO','IBM','CAT','MSFT','CAT','IBM'] unique_names = set(names) -
集合对于成员资格测试很有用
members = set() members.add(item) # Add an item members.remove(item) # Remove an item if item in members: # Test for membership ...
-
-
字典(无序键值数据)
-
适用于索引和查找表
-
将元组用于字典键
prices = { ('ACME','2017-01-01') : 513.25, ('ACME','2017-01-02') : 512.10, ('ACME','2017-01-03') : 512.85, ('SPAM','2017-01-01') : 42.1, ('SPAM','2017-01-02') : 42.34, ('SPAM','2017-01-03') : 42.87, }
-
-
常用操作示例etc,略过
collections 模块
提供常见数据结构的一些变体(对专业问题很有用)
-
defaultdict
defaultdict 是 Python 标准库 collections 模块中的一个类,它是一个字典(dict)的子类,具有与普通字典相同的功能,但是在访问不存在的键值时,不会抛出 KeyError 异常,而是返回指定的默认值。
defaultdict 接受一个参数 default_factory,它可以是一个函数、一个lambda表达式或一个类对象,用来指定默认值的类型。当访问一个不存在的键值时,如果存在 default_factory,则会调用它并返回其结果,如果不存在,则返回默认值类型的默认值。
>>> from collections import defaultdict >>> d = defaultdict(list) >>> d defaultdict(<class 'list'>, {}) >>> d['x'] [] >>> d defaultdict(<class 'list'>, {'x': []}) -
Counter
Counter是Python标准库collections模块中的一个类,使用Counter可以方便地统计可迭代对象(如列表、元组、字符串)中各个元素的出现次数。下面是Counter类的一些常用方法和示例用法:- 创建一个
Counter对象:
from collections import Counter my_list = [1, 2, 3, 2, 1, 3, 2, 1] my_counter = Counter(my_list)- 访问元素的计数:
print(my_counter[1]) # 输出 3,元素1出现了3次 print(my_counter[4]) # 输出 0,元素4未出现- 统计字符串中字符的出现次数:
my_string = "Hello, World!" string_counter = Counter(my_string) print(string_counter['l']) # 输出 3,字母'l'出现了3次- 统计可迭代对象中各元素的计数:
my_list = [1, 2, 3, 2, 1, 3, 2, 1] my_counter = Counter(my_list) print(my_counter) # 输出 Counter({1: 3, 2: 3, 3: 2})- 获取出现次数最多的元素:
print(my_counter.most_common(2)) # 输出 [(1, 3), (2, 3)],出现次数最多的两个元素及其计数-
deque
deque是双端队列(double-ended queue)的缩写。deque可以在两端进行高效的插入和删除操作,因此它非常适用于需要频繁在两端进行操作的场景,与列表(list)相比,deque在插入和删除元素时的性能更好,特别是当元素数量很大时。deque对象支持一系列方法,例如:append(x): 在队列的右侧添加元素x。 appendleft(x): 在队列的左侧添加元素x。 pop(): 移除并返回队列的最右侧的元素。 popleft(): 移除并返回队列的最左侧的元素。 extend(iterable): 在队列的右侧添加可迭代对象iterable中的元素。 extendleft(iterable): 在队列的左侧添加可迭代对象iterable中的元素。
-
保留最近 N 件事的历史记录
from collections import deque history = deque(maxlen=N) with open(filename) as f: for line in f: history.append(line) ...
- 创建一个
迭代
-
带Unpacking的迭代
portfolio = [ ('GOOG', 100, 490.1), ('IBM', 50, 91.1), ('CAT', 150, 83.44), ('IBM', 100, 45.23), ('GOOG', 75, 572.45), ('AA', 50, 23.15) ] for name, shares, price in portfolio: ... -
考虑不同大小的数据结构列表,通配符Unpacking(仅限 Python 3)
prices = [ ['GOOG', 490.1, 485.25, 487.5 ], ['IBM', 91.5], ['HPE', 13.75, 12.1, 13.25, 14.2, 13.5 ], ['CAT', 52.5, 51.2] ] for name, *values in prices: print(name, values) -
zip并行迭代多个序列columns = ['name','shares','price'] values = ['GOOG',100, 490.1 ] for colname, val in zip(columns, values): -
enumerate遍历一个可迭代对象并同时获取索引n和对应的元素namenames = ["Alice", "Bob", "Charlie"] for n, name in enumerate(names): print(f"Index: {n}, Name: {name}") -
Sequence Reductions
最大,最小,求和
>>> s = [1, 2, 3, 4] >>> sum(s) 10 >>> min(s) 1 >>> max(s) 4 >>>布尔测试
>>> s = [False, True, True, False] >>> any(s) True >>> all(s) False >>> -
Unpacking可迭代对象
a = (1, 2, 3) b = [4, 5] c = [ *a, *b ] # c = [1, 2, 3, 4, 5] (list) d = ( *a, *b ) # d = (1, 2, 3, 4, 5) (tuple) -
Unpacking字典
a = { 'name': 'GOOG', 'shares': 100, 'price':490.1 } b = { 'date': '6/11/2007', 'time': '9:45am' } c = { **a, **b } >>> c { 'name': 'GOOG', 'shares':100, 'price': 490.1, 'date': '6/11/2007,'time': '9:45am' } >>> -
参数传递
-
可迭代对象可以展开为位置参数
a = (1, 2, 3) b = (4, 5) func(*a, *b) # func(1,2,3,4,5) -
词典可以展开到关键字参数
c = {'x': 1, 'y': 2 } func(**c) func(x=1, y=2)
-
-
生成器表达式
列表推导的一种变体,通过迭代生成结果。一个生成器只能被遍历一次
>>> nums = [1,2,3,4] >>> squares = (x*x for x in nums) >>> for n in squares: print(n, end=' ') 1 4 9 16 >>> for n in squares: print(n, end=' ') >>>生成器在结果是一个中间步骤的情况下非常有用
def process_data(data): for item in data: # 执行一些处理操作 processed_item = item * 2 yield processed_item # 生成器作为中间步骤 intermediate_result = process_data([1, 2, 3, 4, 5]) # 在中间结果上继续操作 final_result = sum(intermediate_result) print(final_result) # 输出:30
Python 内置特性
什么是内置?属于 Python 解释器一部分的对象,通常完全用 C 语言实现,从某种意义上说,您可以在程序中使用的最原始的对象。
引擎盖下
所有对象都有一个 id(内存地址)、类(type类型)和一个引用计数(用于垃圾回收)
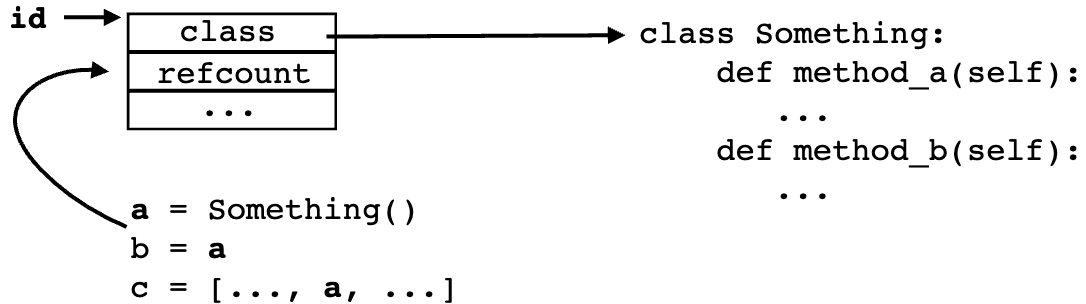
内置操作
内置类型根据预定义的 “协议”(特殊方法)运行
>>> a = 2
>>> b = 3
>>> a + b
5
>>> a.__add__(b) # Protocol
5
>>> c = 'hello'
>>> len(c)
5
>>> c.__len__() # Protocol
5
>>>
对象协议被嵌入到解释器的非常低层(字节码)中
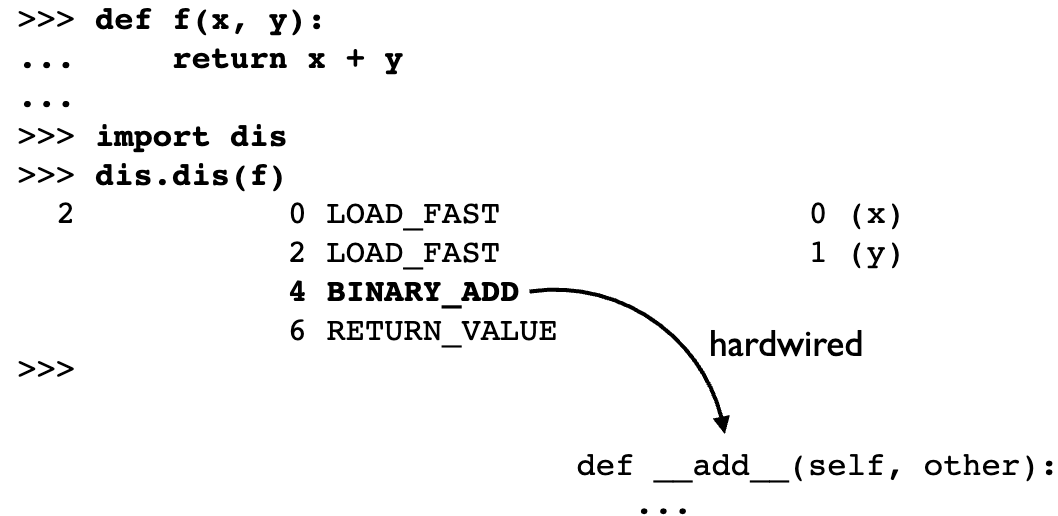
扩展Python的内置功能,并根据特定的领域或需求创建出行为类似于内置对象的新对象。
Python的fractions模块允许你创建和操作分数对象;Decimal模块提供了高精度的十进制运算,Decimal对象可以像内置的整数和浮点数一样进行操作,但它的运算结果更准确。
>>> from fractions import Fraction
>>> a = Fraction(2, 3)
>>> b = Fraction(1, 2)
>>> a + b
Fraction(7, 6)
>>> a > 0.5
True
>>>
Container Representation
容器(可以是数组、列表、集合、字典等数据结构,它们可以存储和管理多个元素)的表示方式通常包括容器的内部结构、访问元素的方法、迭代元素的方式以及对容器进行添加、删除、搜索等操作的接口。
-
容器对象仅保存对其存储值的引用(指针)

-
涉及容器内部的所有操作仅操作指针(而不是对象)
-
所有可变容器(列表、字典、集合)都倾向于过度分配内存,以便始终有一些可用插槽可用,这是一种性能上的优化方式,额外的空间意味着大多数追加和插入操作都非常快(空间已经可用,不需要内存分配)
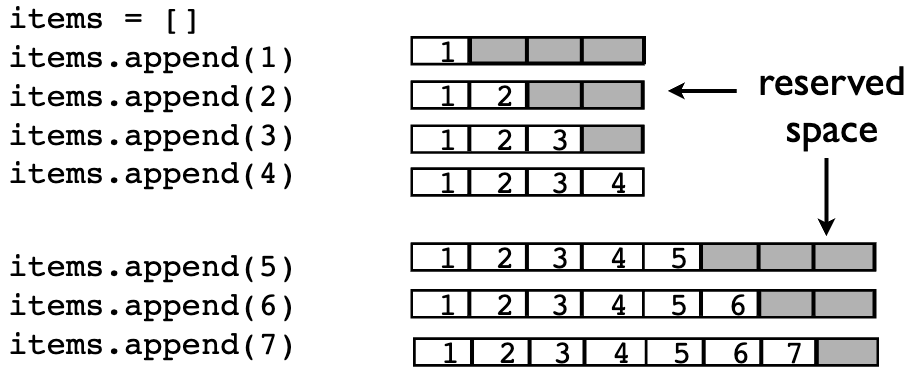 ]
] -
根据存储的值的数量增长,容器所占用的内存也相应增加,具体如下:
- 列表的内存使用量在满时约增加12.5%。
- 集合的内存使用量在 2/3 满时增加4倍。
- 字典的内存使用量在 2/3 满时增加2倍
集合/字典哈希
-
集合和字典基于哈希
-
键用于确定“哈希值”(__ hash__ () 方法)
a = 'Python' b = 'Guido' c = 'Dave' >>> a.__hash__() -539294296 >>> b.__hash__() 1034194775 >>> c.__hash__() 2135385778 -
仅限于使用“可哈希”对象(字符串、数字或元组)设置/字典键
>>> a = {'IBM','AA','AAPL'} >>> b = {[1,2],[3,4]} Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list' -
哈希图示
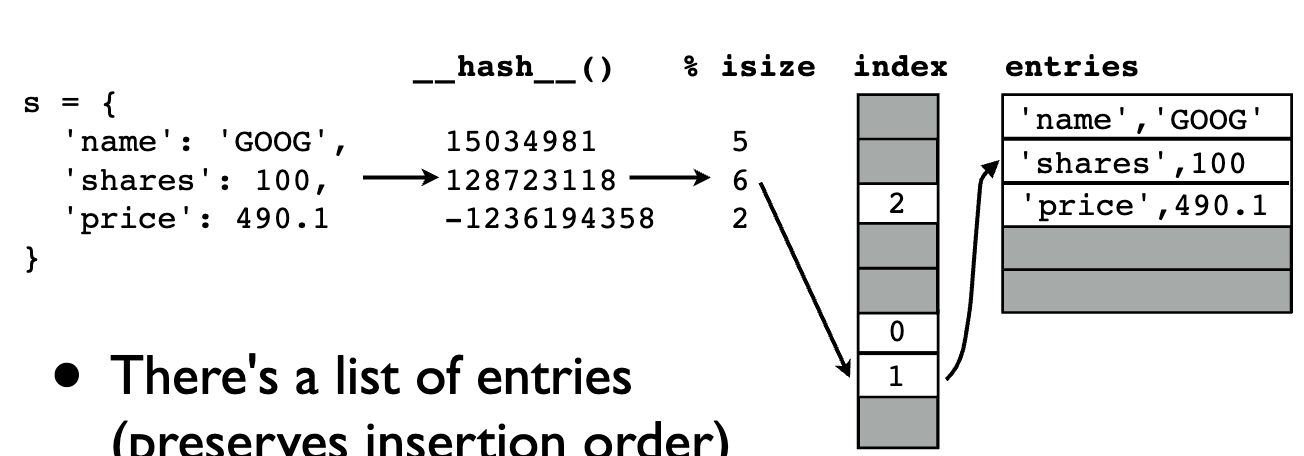
-
解决哈希碰撞,最终会尝试每个slot
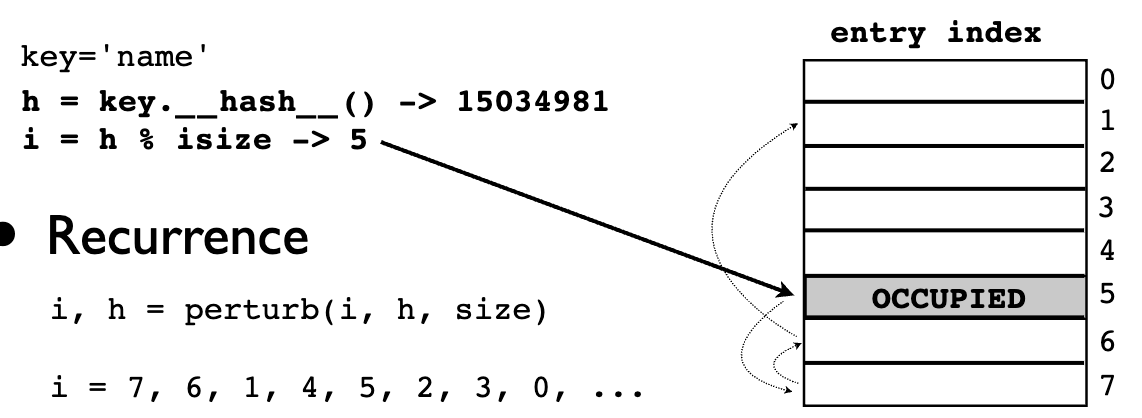
容器协议
>>> a = ['x','y','z']
>>> a[1]
'y'
>>> a.__getitem__(1) # Protocol
'y'
>>> 'z' in a
True
>>> a.__contains__('z') # Protocol
True
新容器:可以通过实现所需的方法来创建自定义容器对象
Mapping, MutableMapping
Sequence, MutableSequence
Set, MutableSet
class MyContainer(collections.abc.MutableMapping):
...
赋值操作详解
赋值操作实际上是将一个变量与一个值关联起来。当我们执行赋值操作时,变量只是引用了内存中存储值的位置,而不是对值本身进行复制。
- 对于可变的数据类型,赋值操作会直接修改对象的值,而不会创建新的对象。
a = [1,2,3]
b = a
c = [a,b]
>>> a.append(999)
>>> a
[1,2,3,999]
>>> b
[1,2,3,999]
>>> c
[[1,2,3,999], [1,2,3,999]]
>>>
- 对于不可变的数据类型,赋值操作实际上会创建一个新的对象,并将变量与该新对象关联起来。这是因为不可变对象的值无法更改,所以在修改时需要创建一个新的对象。
- 列表的浅copy与深copy话题







![Tecnomatix Plant Simulation 2302切换本地帮助的方法[2302]](https://img-blog.csdnimg.cn/3cbd009a783d4a7297a136024605d861.png)