前言
在日常工作中,日志查询是我们不可避免的业务场景,当项目访问量较小时,我们可以将日志存储在MySQL或其他行式数据库中,但是如果项目访问量很大,一次查询就会给数据库带来很大压力,也许你会采用elk等成熟的方案去处理日志,但是代价相对较高。下面,介绍一种列式数据库clickhouse,它能够快速处理大批量数据的查询,对于日中存储查询场景比较方便。先贴上一个官方文档https://clickhouse.com/docs/zh/
一、集群搭建
clickhouse集群搭建依赖jdk和zookeeper集群,这两个的搭建方式在前文中,请参考jdk配置和zookeeper集群搭建。先下载安装包,可以从上述官方文档下载,这里提供一个clickhouse21.9.7.2版本,提取码:6qpu。准备工作完成后,开始集群搭建,建议直接在xshell或其他工具开启命令同步功能,解压安装包到指定目录
tar -zxvf clickhouse-common-static-21.9.7.2.tgz -C /home/ysgs/tools/clickhouse/
tar -zxvf clickhouse-common-static-dbg-21.9.7.2.tgz -C /home/ysgs/tools/clickhouse/
tar -zxvf clickhouse-server-21.9.7.2.tgz -C /home/ysgs/tools/clickhouse/
tar -zxvf clickhouse-client-21.9.7.2.tgz -C /home/ysgs/tools/clickhouse/

依次安装clickhouse-common-static、clickhouse-common-static-dbg和clickhouse-client,切换到对应目录下的install目录,执行doinst.sh,如下所示
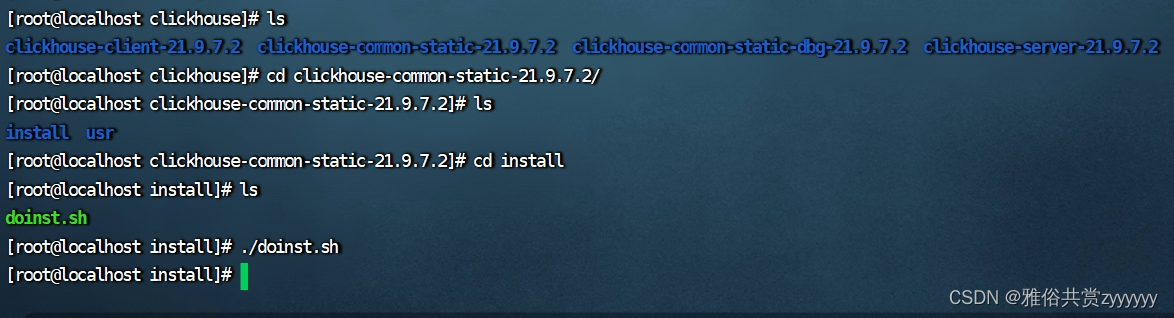
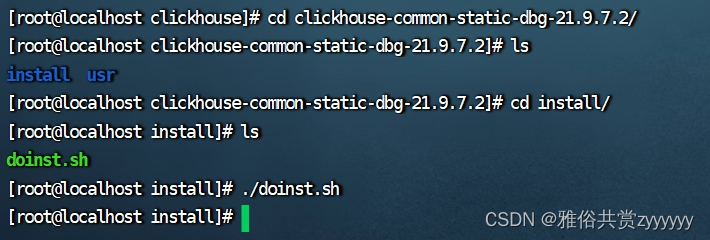
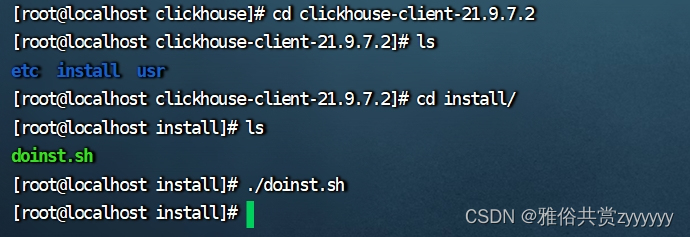
这三个安装完成,剩下最重要的clickhouse-server,先进行配置文件的修改,切换到如下目录/etc/clickhouse-server
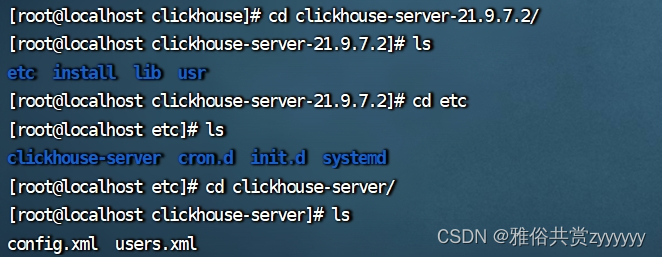
编辑config.xml文件,主要修改如下几处内容,搜索标签即可
日志存储
<log>/app/data/clickhouse/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/app/data/clickhouse/log/clickhouse-server/clickhouse-server.err.log</errorlog>
开放连接
<!-- <listen_host>::</listen_host> -->
<listen_host>::</listen_host>
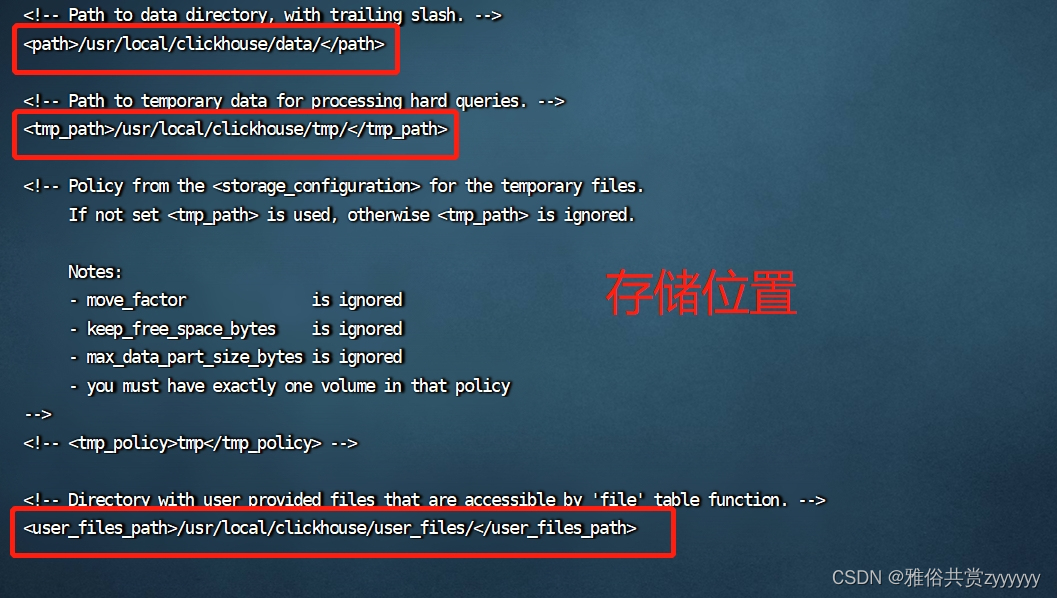
数据存储
<path>/app/data/clickhouse/data/</path>
<tmp_path>/app/data/clickhouse/tmp/</tmp_path>
<user_files_path>/app/data/clickhouse/user_files/</user_files_path>
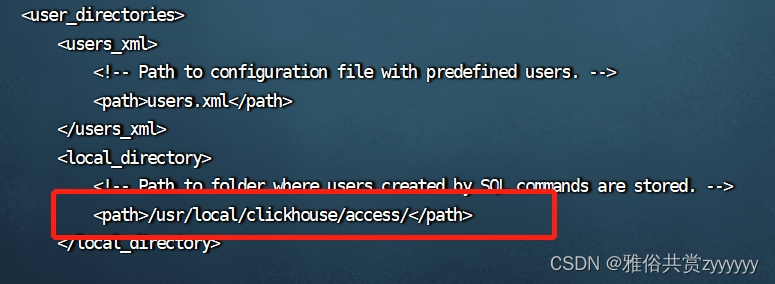
<path>/app/data/clickhouse/access/</path>
<top_level_domains_path>/app/data/clickhouse/top_level_domains/</top_level_domains_path>
<format_schema_path>/app/data/clickhouse/format_schemas/</format_schema_path>


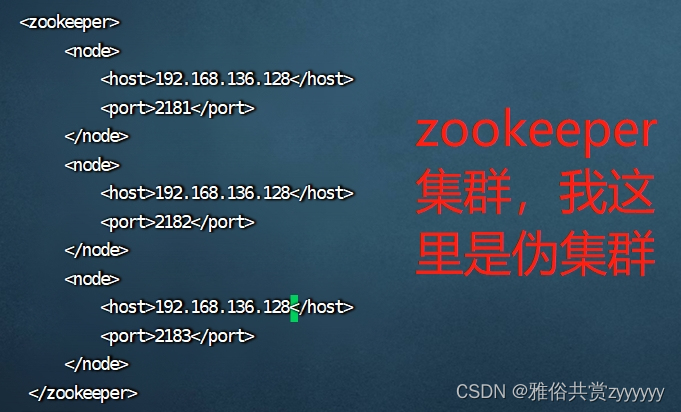
zookeeper集群设置
<zookeeper>
<node>
<host>192.168.136.128</host>
<port>2181</port>
</node>
<node>
<host>192.168.136.128</host>
<port>2182</port>
</node>
<node>
<host>192.168.136.128</host>
<port>2183</port>
</node>
</zookeeper>
分层分片设置
<macros>
<!--层级-->
<layer>01</layer>
<!--分片-->
<shard>01</shard>
<!--副本-->
<replica>rep-01-01</replica>
</macros>

<!-- <internal_replication>false</internal_replication> -->
<internal_replication>false</internal_replication>

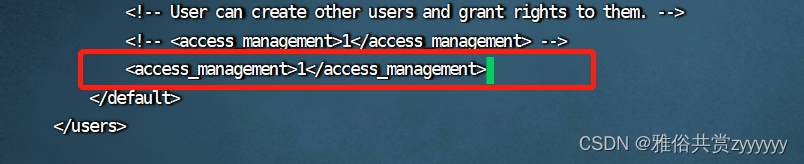
修改完成后,复制出一份cp -p config.xml config-master.xml作为master节点配置,然后修改users.xml配置,主要打开一行,用于创建用户
然后,再复制一份cp -p config.xml config-slave.xml作为从节点配置,修改该配置,将上述config.xml修改的文件路径加上-slave,将所有端口(用于与master区分,统一修改即可)和分片配置修改

<http_port>28123</http_port>
<tcp_port>29000</tcp_port>
<mysql_port>29004</mysql_port>
<postgresql_port>29005</postgresql_port>
<!-- <https_port>28443</https_port> -->
<!-- <tcp_port_secure>29440</tcp_port_secure> -->
<!-- <tcp_with_proxy_port>29011</tcp_with_proxy_port> -->
<interserver_http_port>29009</interserver_http_port>
<!-- <interserver_https_port>29010</interserver_https_port> -->
<!-- <grpc_port>29100</grpc_port> -->
分片配置
<macros>
<!--层级-->
<layer>01</layer>
<!--分片-->
<shard>03</shard>
<!--副本-->
<replica>rep-03-02</replica>
</macros>
下面先介绍一些概念:
分片:对数据分开进行存储,每个分片存储一部分数据,如shard01、shard02...
副本:同一个分片中的多个clickhouse进程实例互为副本,每一个clickhouse实例都是一个副本,也就是说分片名相同,副本名称不同的实例互为副本
我这里是三台机器,三个分片,每个分片两个副本。数据写入时使用replicatedMergetree引擎,数据自动在两个副本之间进行同步备份,同一个分片的两个副本部署在不同的两台服务器上,任一服务器发生故障,集群内都会留存3个分片中的某个副本,保证数据完整性。
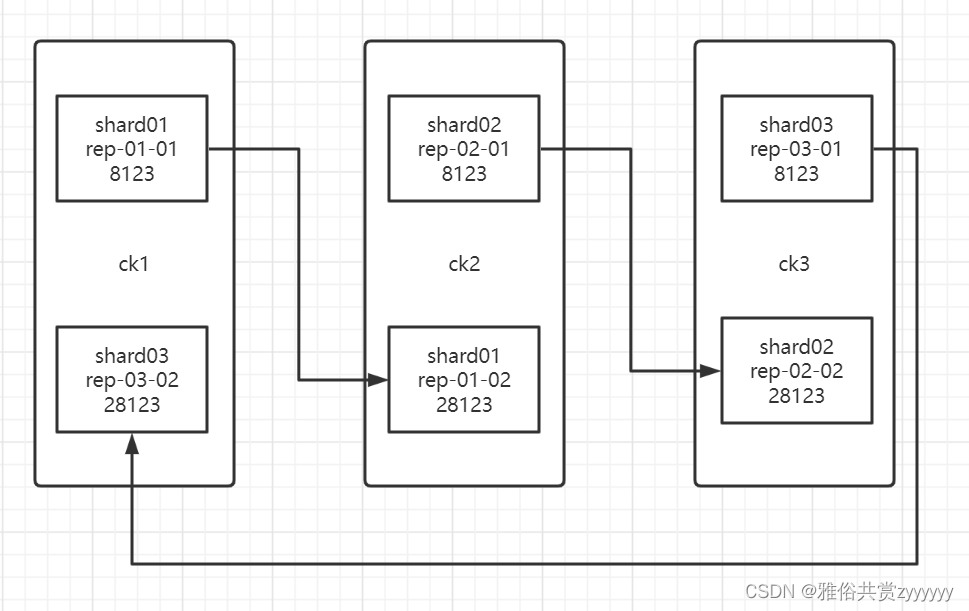
至此,配置文件修改完成,注意,分片的内容一定要对应好。然后切换到/etc/clickhouse-server/systemd/system文件夹下,复制一份服务cp -p clickhouse-server.service clickhouse-server-slave.service,然后编辑从服务,修改对应的配置文件和存储

切换到/lib/systemd/system下,同上操作。接下来,安装clickhouse-server。
先用config-slave.xml覆盖config.xml文件,先安装slave节点。然后用config-master.xml覆盖config.xml文件,安装master节点,切换到install目录下,执行doinst.sh命令行
然后,输入密码(一定记住)
安装成功之后,刷新服务,启动主节点和从节点
systemctl daemon-reload
systemctl status clickhouse-server.service
systemctl start clickhouse-server.service
systemctl status clickhouse-server.service


通过clickhouse-client --host 192.168.136.128 --port 9000 --database default --user default --password 'root'连接测试一下。然后,修改config.xml和confi-slave.xml配置,增加集群配置
在</test_unalivable这个标签后添加
<ck_cluster>
<shard>
<replica>
<host>192.168.136.131</host>
<port>9000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
<replica>
<host>192.168.136.132</host>
<port>29000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
</shard>
<shard>
<replica>
<host>192.168.136.132</host>
<port>9000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
<replica>
<host>192.168.136.133</host>
<port>29000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
</shard>
<shard>
<replica>
<host>192.168.136.133</host>
<port>9000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
<replica>
<host>192.168.136.131</host>
<port>29000</port>
<user>default</user>
<password>1qaz!QAZ</password>
</replica>
</shard>
</ck_cluster>
都配置完成后,重新安装./instal.sh加载下配置,然后重启服务。连接ck,查看集群
clickhouse-client --host 192.168.136.131 --port 9000 --database default --user default --password 'root'
select * from system.clusters;
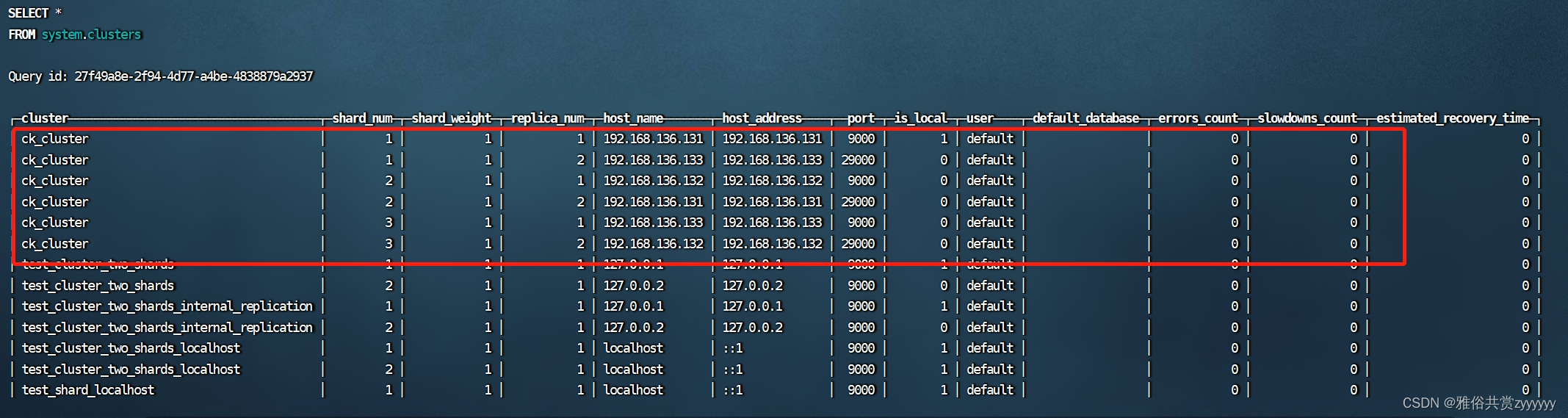
至此,clickhouse集群搭建完成,由于搭建了三个节点,我们通过一个nginx配置设置转发,在nginx.conf配置文件增加如下配置
upstream clickhouse_server_write{
server 192.168.136.131:8123;
server 192.168.136.132:8123;
server 192.168.136.133:8123;
}
server {
listen 8123;
server_name localhost;
location / {
proxy_pass http://clickhouse_server_write;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
upstream clickhouse_server_read{
server 192.168.136.131:28123;
server 192.168.136.132:28123;
server 192.168.136.133:28123;
}
server {
listen 28123;
server_name localhost;
location / {
proxy_pass http://clickhouse_server_read;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
可以看到,配置了8123为写数据的端口,28123为读数据的端口,做了读写分离。然后,创建一个测试用的表,做一下测试。
本地表:在某个clickhouse节点(单个实例)中创建的表为本地表
CREATE TABLE IF NOT EXISTS default.test ON CLUSTER 'ck_cluster'(id Int32, name String)ENGINE = ReplicatedMergeTree('/clickhouse/database/tables/{layer}-{shard}/test ', '{replica}') ORDER BY id PARTITION BY id PRIMARY KEY id;
分布式表:分布式表本身不存储数据,但是可以在多个分片上进行分布式并行查询,查询时会根据每个分片上副本的健康程度选择其中的一个副本进行查询
CREATE TABLE IF NOT EXISTS default.test_all ON CLUSTER 'ck_cluster' AS default.test ENGINE = Distributed(ck_cluster, default, test, hiveHash(id));
数据:
insert into `default`.test values(1,'张三');
insert into `default`.test values(2,'李四');
insert into `default`.test values(3,'王五');
insert into `default`.test values(4,'赵六');
insert into `default`.test values(5,'沈七');
insert into `default`.test values(6,'王八');
连接之后,我们先查询test表,也就是本地表,随着多次查询发现,是随机到某个节点的数据,如下所示
然后再查看test_all表,也就是分布式表(实际是一个视图),多次查询,是所有的数据
因此,在实际应用时,写数据配置8123端口,随机写到一个节点,查数据时,配置28123端口,查询分布式表。至此,集群搭建测试完毕。PS:上述的可视化工具为DBeaver,DBeaver,提取码:vwm2。
二、SpringBoot集成
1、依赖&配置
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.28</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
spring.datasource.type = com.alibaba.druid.pool.DruidDataSource
spring.datasource.url = jdbc:clickhouse://192.168.136.128:8123/default?useSSL=false
spring.datasource.driver-class-name = ru.yandex.clickhouse.ClickHouseDriver
spring.datasource.username = default
spring.datasource.password = root
2、测试连接
package com.example.clickhouse.clickhouse.ctrl;
import com.example.clickhouse.clickhouse.service.TestService;
import lombok.Data;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author zy
* @version 1.0.0
* @ClassName TestController.java
* @Description TODO
* @createTime 2022/12/12
*/
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
private TestService testService;
@Data
public class Test{
private String id;
private String name;
}
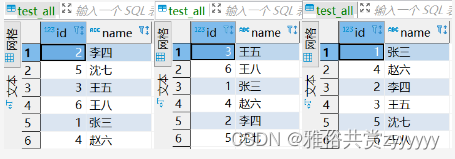
@RequestMapping("/write")
public String write(){
Test test = new Test();
test.setId("7");
test.setName("詹姆斯");
testService.insert(test);
return "插入成功";
}
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.clickhouse.clickhouse.mapper.TestMapper">
<insert id="insert">
insert into `default`.test values(#{id},#{name})
</insert>
</mapper>

![对DataFrame中元素进行定位并修改的DataFrame.iat[]方法](https://img-blog.csdnimg.cn/img_convert/ac6d931974911df3e5544374ed70754f.png)



![[附源码]Python计算机毕业设计电子病历系统Django(程序+LW)](https://img-blog.csdnimg.cn/984d64c5da654364bec30609a6eb9c92.png)


![[附源码]Node.js计算机毕业设计点餐系统设计Express](https://img-blog.csdnimg.cn/4a79625961404147810db8af70dd1f39.png)