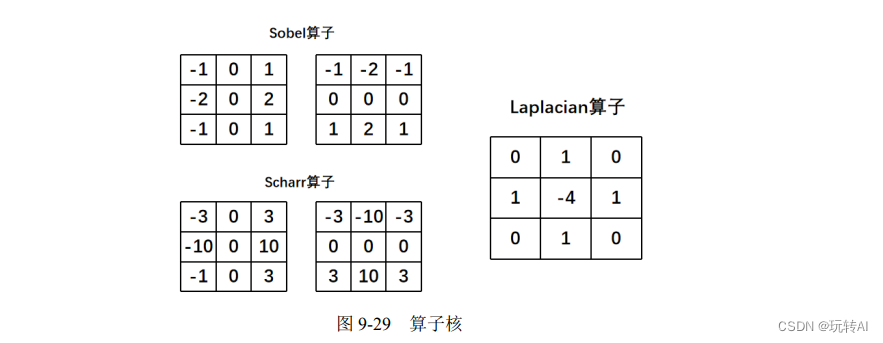
目录标题
- 筛选日志时间
- 示例
- 编写1.awk文件
- 准备一个需要筛选时间的日志
- 执行awk命令
筛选日志时间
grep/sed/awk用正则去筛选日志时,如果要精确到小时、分钟、秒,则非常难以实现。
但是awk提供了mktime()函数,它可以将时间转换成epoch时间值。
# 2019-11-10 03:42:40转换成epoch为1970-01-01 00:00:00
$ awk 'BEGIN{print mktime("2019 11 10 03 42 40")}'

借此,可以取得日志中的时间字符串部分,再将它们的年、月、日、时、分、秒都取出来,然后放入mktime()构建成对应的epoch值。因为epoch值是数值,所以可以比较大小,从而决定时间的大小。
示例
下面strptime2()实现的是将10/Nov/2019:23:53:44+08:00格式的字符串转换成epoch值,然后和which_time比较大小即可筛选出精确到秒的日志。
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2023 11 08 03 42 40")
}
{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
print
}
}
# 构建的时间字符串格式为:"08/Nov/2023:03:42:40+08:00"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}
编写1.awk文件
将上面的代码复制到1.awk中
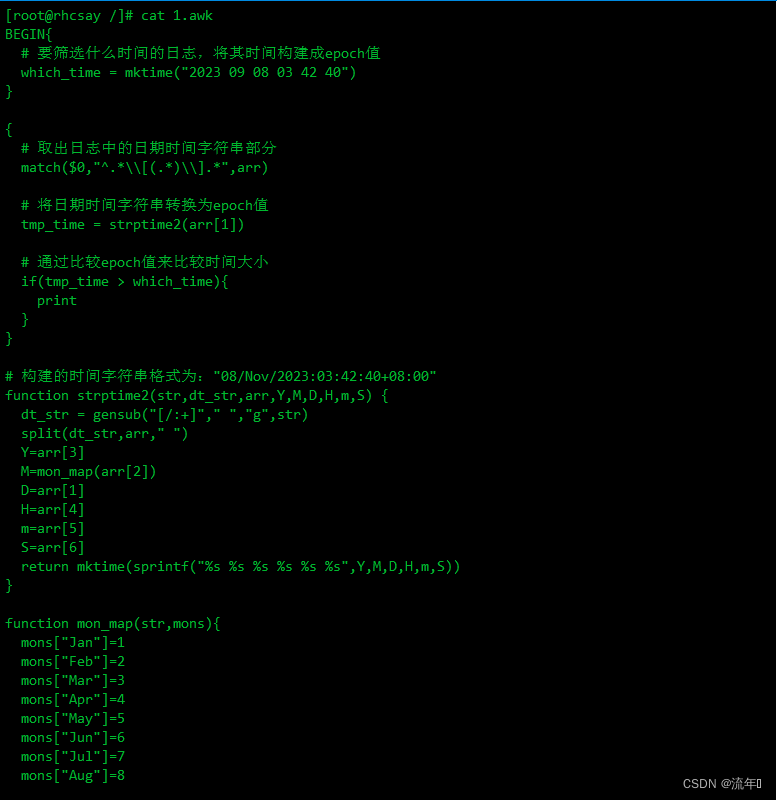

准备一个需要筛选时间的日志
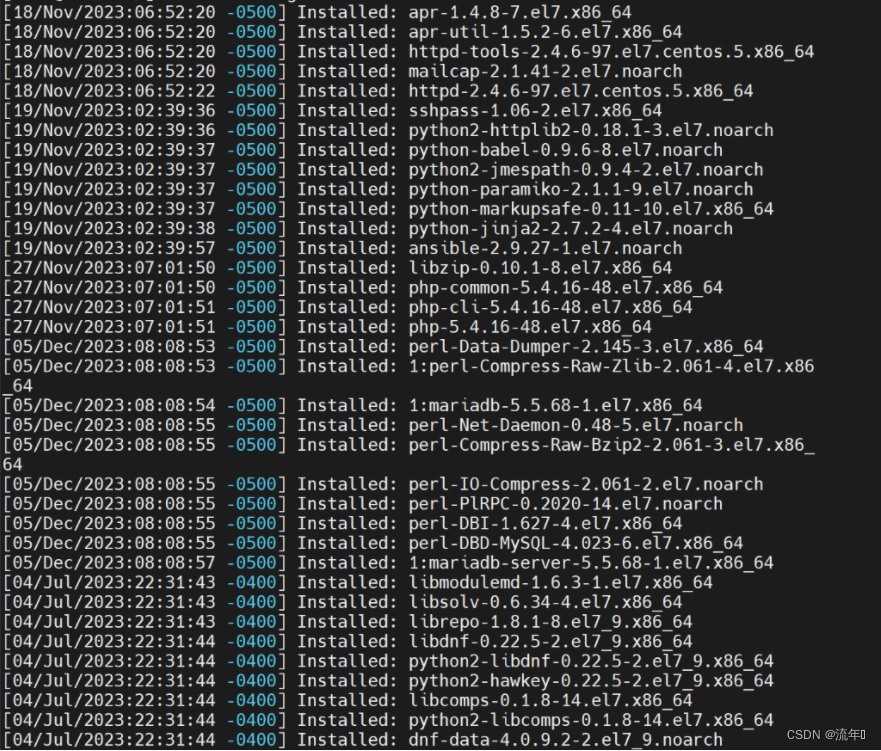
执行awk命令
awk -f 脚本文件 需要读取的文件
这样就能帅选出9月8号的日志了。