Sleuth链路追踪
- 系列博客
- 背景
- 一、 什么是链路追踪
- 二、为什么要有链路追踪
- 三、Sleuth与Zipkin
- Sleuth
- Zipkin
- Sleuth和Zipkin的关系是什么?
- 四、使用Sleuth+zipkin进行链路追踪
- 4.1下载zipkin
- 4.2案例说明
- 项目代码
- 服务提供者
- pom文件
- yml配置文件
- 项目启动类
- controller
- 抽离出来的common-api模块
- pom文件
- feign
- hystrix
- 服务消费者
- pom文件
- yml配置文件
- 启动类
- controller
- 启动服务
系列博客
【Spring Cloud一】微服务基本知识
【Spring Cloud 三】Eureka服务注册与服务发现
【Spring Cloud 四】Ribbon负载均衡
【Spring Cloud 五】OpenFeign服务调用
【Spring Cloud 六】Hystrix熔断
背景
目前开发的项目正是使用sleuth+zipkin的方式进行的链路追踪,为了对sleuth+zipkin这个技术点加深认识。博主对其进行了理论学习和实践。
一、 什么是链路追踪
链路追踪就是追踪微服务的调用路径。
二、为什么要有链路追踪
随着业务越来越复杂,以及微服务架构的兴起,在微服务架构中,一个由客户端发起的请求在后端往往会经过不同的服务节点调用协同完成一个请求。当请求出现问题(不可用,请求时间长等等),我们很难定位到具体是哪一个或者哪几个服务出现了问题,而链路追踪能够帮助我们快速精准的定位到是哪一个服务出现了问题。
三、Sleuth与Zipkin
Sleuth
Sleuth是Spring Cloud提供的一款分布式系统跟踪解决方案,Sleuth可以自动为每一个请求添加唯一的跟踪标识,以便在整个请求链路中跟踪与识别请求。
学习Sleuth之前必须了解它的几个概念,它们是实现链路追踪的基础:
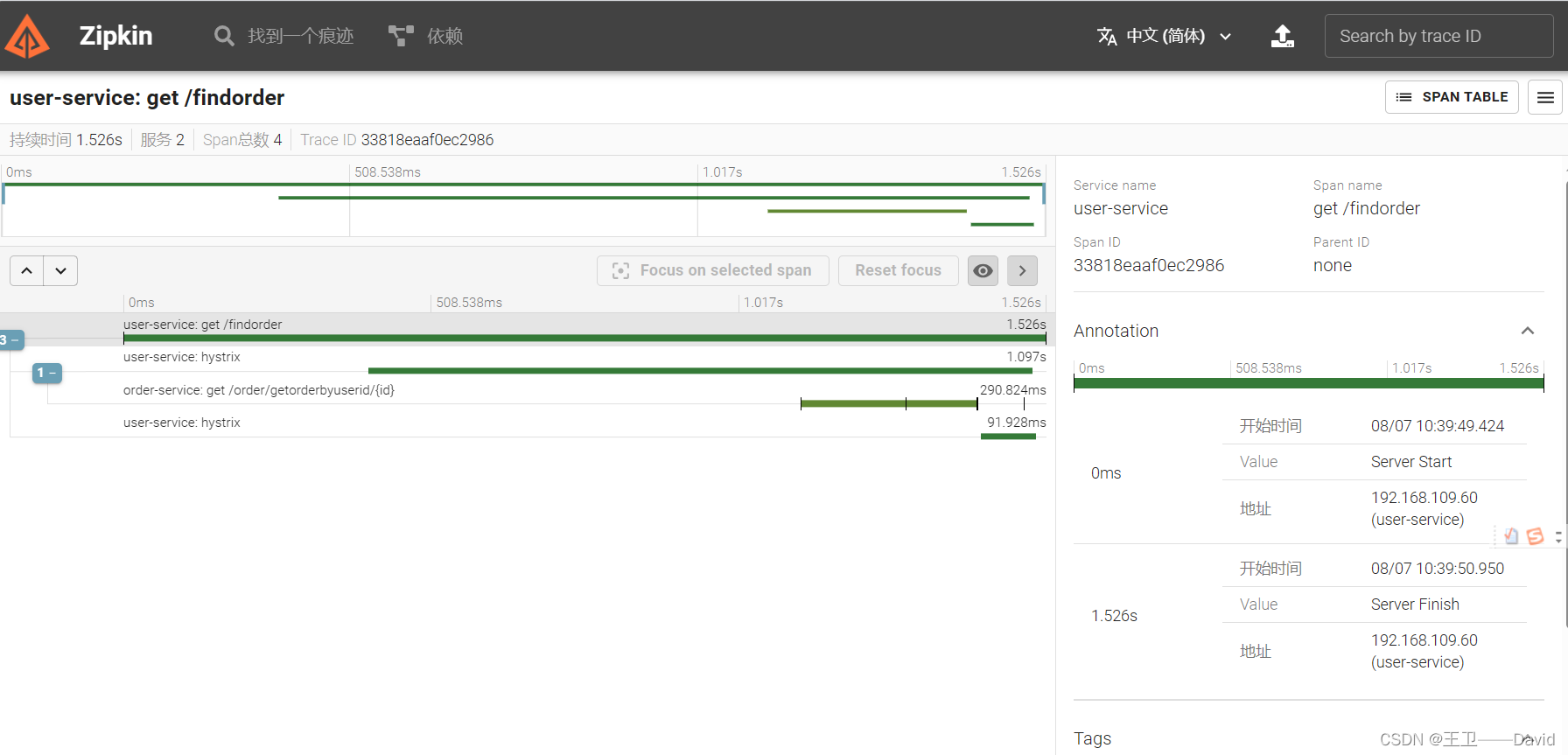
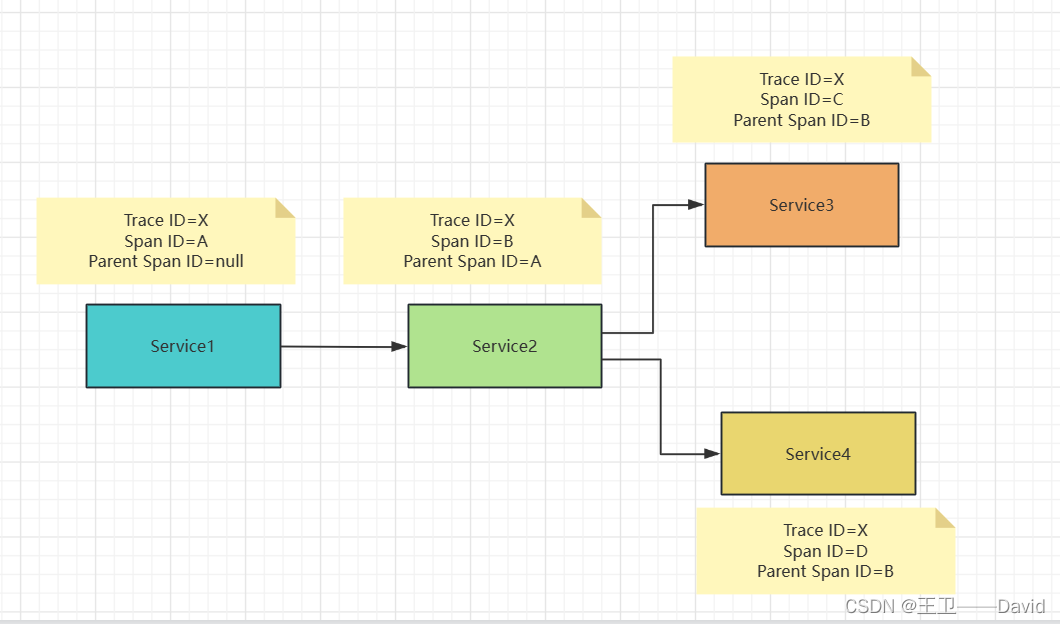
- Trace:它代表一个完整的请求链路。每个Trace都有一个全局唯一的Trace ID用于表示整个请求的跟踪信息。
- Span:Span是Trace的组成部分,它代表请求链路中的一个环节,一个请求可能经过多个服务,每个服务处理请求的过程就是一个Span。每个Span都有一个唯一的ID,用于标识该环节的跟踪信息。
- Trace ID(跟踪ID):
Trace ID是全局唯一的标识,用于连接整个请求链路。在Sleuth中,Trace ID会被添加到请求的Header中,并在请求经过多个服务时一直传递下去。 - Span ID(跨度ID):
Span ID是用于标识单个Span的唯一标识符。它会随着请求的流转在不同的服务之间传递,用于表示请求链路中的每个环节。 - Parent Span ID(父跨度ID):
Parent Span ID是用于标识当前Span的上一级Span。通过这种方式,Span之间就可以建立起父子关系,形成完整的请求链路。
一条完整的链路请求(Trace):
Zipkin
Zipkin是一个开源的分布式跟踪系统,它收集并存储跨多个服务的请求链路数据,并提供支援的Web界面吗用于查看和分析这些数据。帮助开发人员快速定位和解决分布式系统中的性能问题。
zipkin的运行关系图:
图片来自官网:https://zipkin.io/pages/architecture.html
zipkin的大致运行流程:
集成zipkin客户端服务通过几种传输(http,kafka,scribe)之一将数据发送到zipkin服务端,Collector将跟踪数据保存到Storage,之后Storage通过API向UI提供数据。
部分名词解释:
1.InstrumentedClient:使用了Zipkin客户端工具的服务调用方
2.InstrumentedServer:使用了Zipkin客户端工具的服务提供方
3.Non-InstrumentedServer:未使用Zipkin客户端工具的服务提供方
Sleuth和Zipkin的关系是什么?
Sleuth和Zipkin通常一起使用来实现分布式系统的请求链路跟踪和性能监控。 Sleuth主要负责为每个请求添加唯一的跟踪标识,并将跟踪信息传递给下游服务。而Zipkin主要负责负责收集和存储这些跟踪信息,并通过可视化界面展示整个请求链路的信息,包括请求的时间、调用的顺序以及每个调用的耗时等
补充:其实完全可以单独使用Zipkin进行链路追踪,但是为什么大多数都选择使用Sleuth+Zipkin?
- Sleuth的集成很便捷,通过添加依赖和配置,应用程序能够自动实现请求跟踪。
- 集成更多功能,Sleuth不仅仅生成和传递跟踪信息,它还提供了其他一些功能,如与日志集成、自定义采样率、整合Span的定制等。
- 多语言支持,Sleuth不仅仅生成和传递跟踪信息,它还提供了其他一些功能,如与日志集成、自定义采样率、整合Span的定制等。我们可以实现全链路跟踪
- 对Spring Cloud生态的更好支持。
四、使用Sleuth+zipkin进行链路追踪
4.1下载zipkin
Spring Cloud从F版本之后可以不需要自己构建Zipkin服务了,只需要调用jar就可以。
下载Zipkin jar包 https://repo1.maven.org/maven2/io/zipkin/zipkin-server/2.24.3/
下载之后直接在本机运行 java -jar +jar包所在路径
4.2案例说明
该项目总共有四个服务,一个Zipkin服务端、一个Eureka服务端、一个服务提供者,一个服务消费者。
如何搭建Eurka服务可以访问这篇博客【Spring Cloud 三】Eureka服务注册与服务发现
项目代码
服务提供者
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>feign-project</artifactId>
<groupId>com.wangwei</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>order-center</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.wangwei</groupId>
<artifactId>common-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
yml配置文件
server:
port: 8080
spring:
application:
name: order-service
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1 #配置采样率 默认的采样比例为0.1 即10%,所设置的值介于0到1之间,1表示全部采集
rate: 10 #为了使用速率限制采样器,选择每秒间隔接收的trace量,最小数字为0,最大值为2,147,483,647(最大int) 默认为10
eureka:
client:
service-url: #??????
defaultZone: http://localhost:8761/eureka
register-with-eureka: true #设置为fasle 不往eureka-server注册
fetch-registry: true #应用是否拉取服务列表到本地
registry-fetch-interval-seconds: 10 #为了缓解服务列表的脏读问题,时间越短脏读越少 性能相应的消耗回答
instance: #实例的配置
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
hostname: localhost #主机名称或者服务ip
prefer-ip-address: true #以ip的形式显示具体的服务信息
lease-renewal-interval-in-seconds: 10 #服务实例的续约时间间隔
项目启动类
@SpringBootApplication
@EnableEurekaClient
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class,args);
}
}
controller
@RestController
public class OrderController {
@GetMapping("order/getOrderByUserId/{id}")
Order getOrderByUserId (@PathVariable("id")Integer id){
System.out.println(id);
Order order=Order.builder()
.name("青椒肉丝盖饭")
.price(15D)
.orderId(1)
.build();
return order;
}
}
抽离出来的common-api模块
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>feign-project</artifactId>
<groupId>com.wangwei</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>common-api</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.wangwei</groupId>
<artifactId>project-domain</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
</project>
feign
@FeignClient(value = "order-service",fallback = UserOrderFeignHystrix.class)
public interface UserOrderFeign {
@GetMapping("order/getOrderByUserId/{id}")
Order getOrderByUserId (@PathVariable("id")Integer id);
}
hystrix
@Component
public class UserOrderFeignHystrix implements UserOrderFeign {
/**
* 一般远程调用的熔断可以直接返回null
* @param id
* @return
*/
@Override
public Order getOrderByUserId(Integer id) {
return null;
}
}
服务消费者
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>feign-project</artifactId>
<groupId>com.wangwei</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>user-center</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!--暴露自身检查端点-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>com.wangwei</groupId>
<artifactId>common-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
</project>
yml配置文件
server:
port: 8081
spring:
application:
name: user-service
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1 #配置采样率 默认的采样比例为0.1 即10%,所设置的值介于0到1之间,1表示全部采集
rate: 10 #为了使用速率限制采样器,选择每秒间隔接收的trace量,最小数字为0,最大值为2,147,483,647(最大int) 默认为10
eureka:
client:
service-url: #??????
defaultZone: http://localhost:8761/eureka
register-with-eureka: true #设置为fasle 不往eureka-server注册
fetch-registry: true #应用是否拉取服务列表到本地
registry-fetch-interval-seconds: 10 #为了缓解服务列表的脏读问题,时间越短脏读越少 性能相应的消耗回答
instance: #实例的配置
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
hostname: localhost #主机名称或者服务ip
prefer-ip-address: true #以ip的形式显示具体的服务信息
lease-renewal-interval-in-seconds: 10 #服务实例的续约时间间隔
feign:
hystrix:
enabled: true #开启熔断
management:
endpoints:
web:
exposure:
include: '*'
启动类
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class,args);
}
}
controller
@RestController
public class UserController {
@Autowired
private UserOrderFeign userOrderFeign;
@GetMapping("findOrder")
public Order findOrder(){
return userOrderFeign.getOrderByUserId(1);
}
}
启动服务
先启动Eureka服务端在启动zipkin服务端,再启动服务提供者最后启动服务消费者。
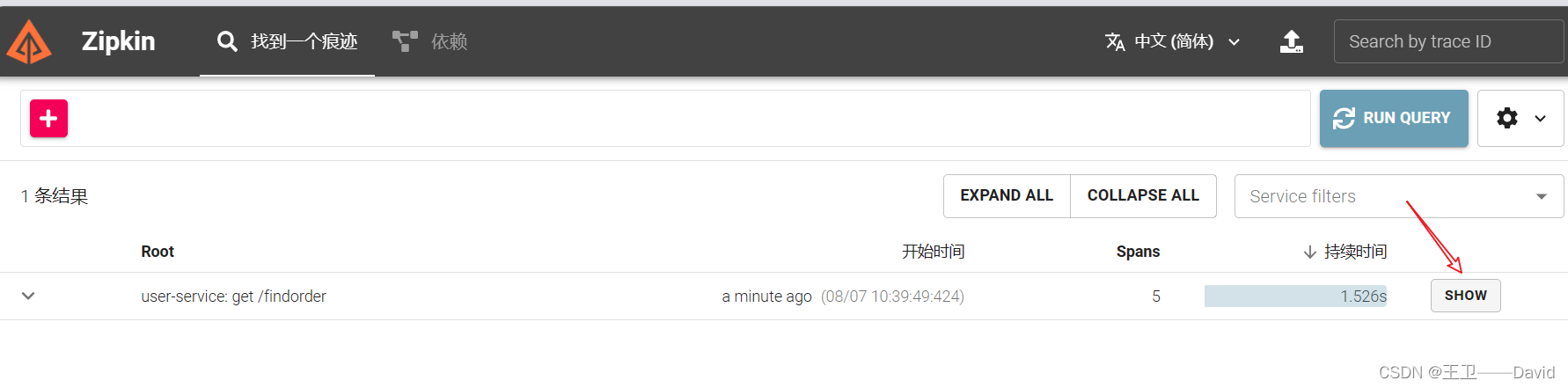
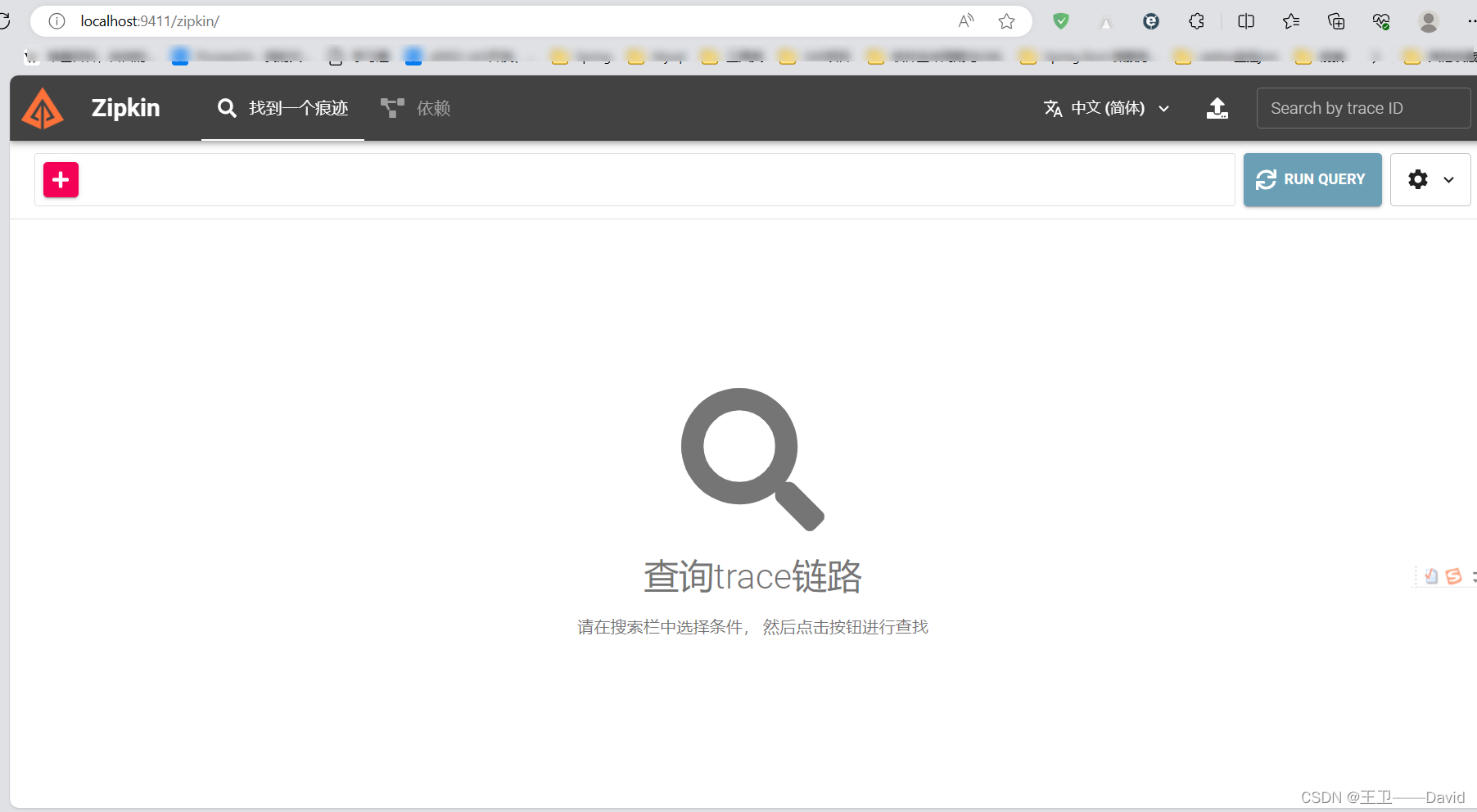
访问zipkin服务端:
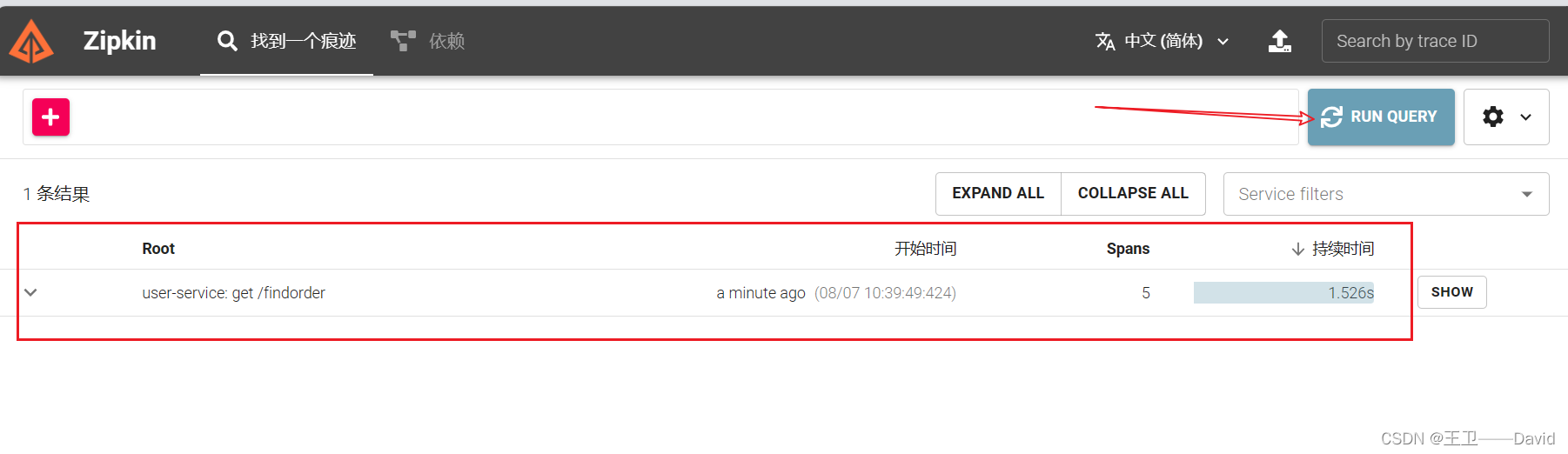
服务消费者调用服务提供者之后再次访问zipkin服务端
查看详细信息