接下来进行仲裁器 arbiter的设计。根据设计文档,我们知道从输入总共有3个通道,而这三个通道很有可能都接收到数据可以进行发送。而arbiter就是综合优先级、是否有包可以发送等因素,选择一个通道来进行发送。形象的可以将arbiter比喻成“一个多选1开关”,它来负责控制最后的整形模块formatter和哪个slave_FIFO接在一起,因此力求在设计时,如果arbiter选择了一个通道后,arbiter就是透明的,尽量不产生始终延迟,使选通的通道直接和formatter联通。
基于以上想法,结合arbiter的多选1开关结构,我先设计arbiter结构示意图,主要采用组合逻辑,只有优先级产生模块使用时序电路,最后用verilog参考结构示意图完成设计。
第一节 arbiter文档理解
文档相关内容部分引用如下
如果
formatter的发送数据请求信号f2a_id_req_i为高,则arbiter根据slave0_FIFO的发送请求信号slv0_req_i、slave1_FIFO发送请求信号slv1_req_i、slave2_FIFO发送请求信号slv2_req_i,按优先级确定响应通道的发送请求,并根据通道的编号(id=0, 1, 2)X产生以下信号送到formatter:
a2f_id_o = X(通道编号)
a2f_data_o = slvX_data_i
a2f_pkglen_sel_o = slvX_pkglen_i
a2f_val_o = slvX_val_i
将formatter的响应信号送往对应的slave通道:
a2sX_ack_o = f2a_ack_i
如果各通道的优先级相同,则按通道编号从低到高轮流发送。
综合优先级产生:
我们发现文档中优先级描述是文字化的,参考微机原理中学到“人工优先级”、“自然优先级”的相关知识,迁移到本模块中。文档中的意思是:控制寄存器为通道配置的寄存器占优先级中的dominant地位,而自然优先级处于优先级比较中的minimal地位。我们将这两者优先级结合的优先级暂时称之为综合优先级。
为了将综合优先级用表达式表达出来以便直接比较,这里采用直接按位组合的方法,因为二进制数高位自然地处于dominant地位。
c
h
x
_
p
r
i
o
_
s
y
n
=
s
l
v
x
_
p
r
i
o
_
i
∗
4
+
s
l
v
x
_
p
r
i
o
_
n
a
t
u
r
e
chx\_prio\_syn=slvx\_prio\_i*4+slvx\_prio\_nature
chx_prio_syn=slvx_prio_i∗4+slvx_prio_nature 将该表达式转换为verilog语言如下
assign ch0_prio_syn=({2'b0,slv0_prio_i}<<2)+'d0;//[3:2是设置prio][1:0是自然prio,3:2相等时才起作用]
assign ch1_prio_syn=({2'b0,slv1_prio_i}<<2)+'d1;
assign ch2_prio_syn=({2'b0,slv2_prio_i}<<2)+'d2;
有了自然优先级之后,我们便可以据此来判断选择哪个通道了。
综合优先级判断:
根据文档中的描述,优先级数值越小,优先级越高。综合优先级继承了这样的特性。但是对于3个优先级,不同于2个数值之间直接比较那么简单,这里采用的是嵌套if-else的方法实现最小值寻找。
//根据综合优先级得出最优先通道(数值最小)
always @(*) begin//综合优先级生成电路保证不可能相等
if(ch0_prio_syn>ch1_prio_syn)begin
if(ch1_prio_syn>ch2_prio_syn)
channel_prio<=6'b10_01_00;
else begin
if(ch0_prio_syn>ch2_prio_syn)
channel_prio<=6'b01_10_00;
else
channel_prio<=6'b01_00_10;
end
end
else begin
if(ch1_prio_syn<ch2_prio_syn)
channel_prio<=6'b00_01_10;
else begin
if(ch0_prio_syn<ch2_prio_syn)
channel_prio<=6'b00_10_01;
else
channel_prio<=6'b10_00_01;
end
end
end
有了综合优先级生成和比较,这样我们就能找出优先级最高的通道了,每次arbiter或者更高级请求发送数据包时,我们只要比较一下当前优先级最高的通道(刷新综合优先级),然后直接选通对应通道,将各种信号按照文档中给的对应关系进行wire连接就可以了。
下面介绍结构设计,可以参考设计文档中的端口声明。
第二节 arbiter结构设计
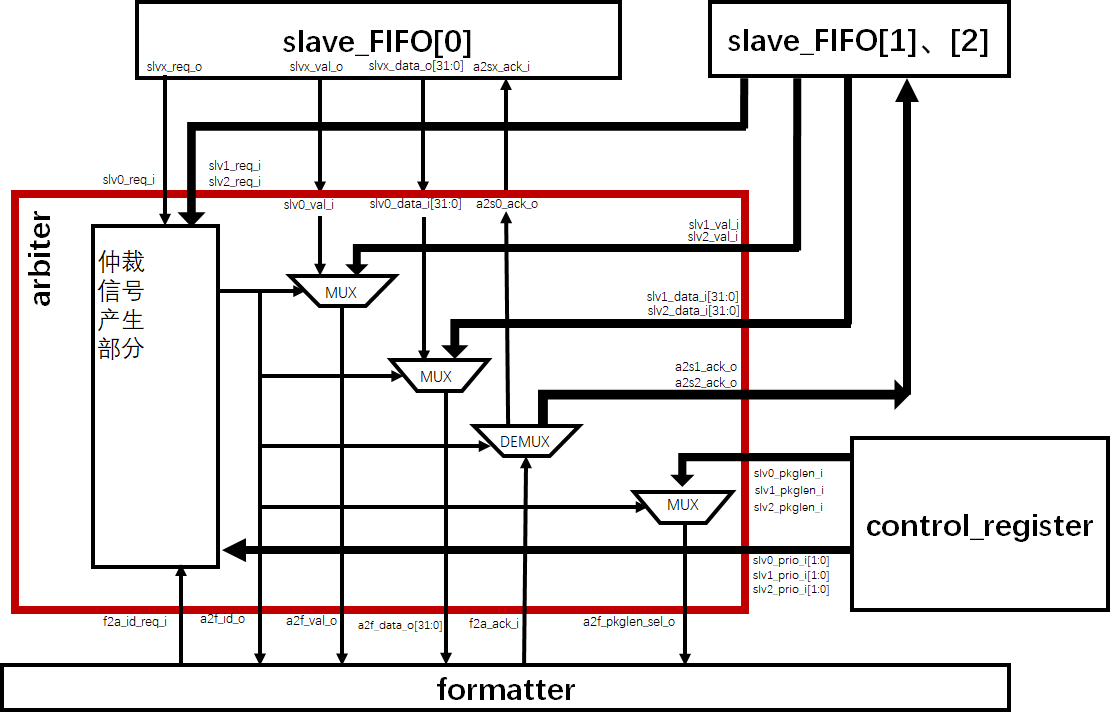
正如结构图所示,只有仲裁信号产生部分是时序电路,其余都是组合逻辑。因此当选通某一通道时,相当于formatter和slave_FIFO直连,而此时arbiter是透明的。
仲裁在formatter发来请求发送信号时进行运算,刷新出当前最优通道,在下一时钟周期的上升沿刷新选择器和分配器的使能端,完成选通任务。
值得一提的是,由于设计只有3个通道,分别用00、01、10表示,而考虑到复位情况不能选择任何一个通道(因为可能3个通道都没接收足够数据发送),并且对于这么多arbiter输出信号复位赋值语句较多,因此这里设置一个虚拟通道(图中未画出),编号是11。提前设定好虚拟通道各信号的值等于复位信号,当复位时,只需要把formatter和虚拟通道接通即可。
第三节 arbiter代码设计
根据上一节的结构图,可以很容易写出代码。
文件名称:arbiter.v
/*************************<MCDF仲裁器>*********************/
`timescale 1ns/100ps
/*************************<端口声明>*********************/
module arbiter
(
//Input
input wire clk_i,
rstn_i,
/*******************<control register 接口>*******/
input wire [1:0] slv0_prio_i,
slv1_prio_i,
slv2_prio_i,
input wire [2:0] slv0_pkglen_i,
slv1_pkglen_i,
slv2_pkglen_i,
/*******************<slave 接口>*********************/
input wire [31:0] slv0_data_i,
slv1_data_i,
slv2_data_i,
input wire slv0_req_i,
slv1_req_i,
slv2_req_i,
slv0_val_i,
slv1_val_i,
slv2_val_i,
input wire slv0_end_i, //!!!增加的信号
input wire slv1_end_i, //!!!增加的信号
input wire slv2_end_i, //!!!增加的信号
/*******************<formatter 接口>*********************/
input wire f2a_id_req_i, //formatter请求接收
f2a_ack_i,
//Output
/*******************<slave 接口>*********************/
output reg a2s0_ack_o, //[-slv]f2a_ack_i
a2s1_ack_o,
a2s2_ack_o,
/*******************<formatter 接口>*********************/
a2f_val_o, //[-slv]slvx_val_i,包有效包络信号
output reg [1:0] a2f_id_o, //通道编号
output reg [31:0] a2f_data_o, //[-slv]slvx_data_i
output reg [2:0] a2f_pkglen_sel_o, //[-slv]slvx_pkglen_i
output reg a2f_end_o //!!!增加的信号
);
/*****************<中间信号>*********************/
wire [3:0] ch0_prio_syn,//各通道综合优先级,计算方法见下
ch1_prio_syn,
ch2_prio_syn;
reg [5:0] channel_prio;//通道优先级综合排序寄存器[5:4最高优先级通道序号][3:2次高优先级通道序号][1:0最低优先级通道序号]
wire [2:0] slvx_req;//输入请求集中,!!!写成向量比数组更好,向量可以查看值,防止出错
assign slvx_req[0]=slv0_req_i;
assign slvx_req[1]=slv1_req_i;
assign slvx_req[2]=slv2_req_i;
/*****************<综合优先级生成电路:组合逻辑>*********************/
assign ch0_prio_syn=({2'b0,slv0_prio_i}<<2)+'d0;//[3:2是设置prio][1:0是自有prio,3:2相等时才起作用]
assign ch1_prio_syn=({2'b0,slv1_prio_i}<<2)+'d1;
assign ch2_prio_syn=({2'b0,slv2_prio_i}<<2)+'d2;
/*****************<优先级整合逻辑>*********************/
//根据综合优先级得出最优先通道(数值最小)
always @(*) begin//综合优先级生成电路保证不可能相等
if(ch0_prio_syn>ch1_prio_syn)begin
if(ch1_prio_syn>ch2_prio_syn)
channel_prio<=6'b10_01_00;
else begin
if(ch0_prio_syn>ch2_prio_syn)
channel_prio<=6'b01_10_00;
else
channel_prio<=6'b01_00_10;
end
end
else begin
if(ch1_prio_syn<ch2_prio_syn)
channel_prio<=6'b00_01_10;
else begin
if(ch0_prio_syn<ch2_prio_syn)
channel_prio<=6'b00_10_01;
else
channel_prio<=6'b10_00_01;
end
end
end
/*****************<时序电路>*********************/
//用于产生仲裁信号 a2f_id_o !!!如果都没准备号,就发送11
always @(posedge clk_i or negedge rstn_i) begin
if(~rstn_i)begin//输出全部置0
a2f_id_o<=2'b11;//进入default间接置0
end
else if(f2a_id_req_i)begin//当上级(formatter)命令可以发送包!!!f2a_id_req_i应当时单周期信号,不能持续
if(slvx_req[channel_prio[5:4]])//先查看优先级最高的slave是否请求发送
a2f_id_o<=channel_prio[5:4];
else if(slvx_req[channel_prio[3:2]])
a2f_id_o<=channel_prio[3:2];
else if(slvx_req[channel_prio[1:0]])
a2f_id_o<=channel_prio[1:0];
else
a2f_id_o<=2'b11;
end
else
a2f_id_o<=a2f_id_o;
end
/*****************<多路选择器部分>*********************/
always @(*) begin
case(a2f_id_o)
2'b00:begin
a2f_val_o=slv0_val_i;
a2f_data_o=slv0_data_i;
a2f_pkglen_sel_o=slv0_pkglen_i;
a2s0_ack_o=f2a_ack_i;
a2s1_ack_o=0;
a2s2_ack_o=0;
a2f_end_o=slv0_end_i;
end
2'b01:begin
a2f_val_o=slv1_val_i;
a2f_data_o=slv1_data_i;
a2f_pkglen_sel_o=slv1_pkglen_i;
a2s0_ack_o=0;
a2s1_ack_o=f2a_ack_i;
a2s2_ack_o=0;
a2f_end_o=slv1_end_i;
end
2'b10:begin
a2f_val_o=slv2_val_i;
a2f_data_o=slv2_data_i;
a2f_pkglen_sel_o=slv2_pkglen_i;
a2s0_ack_o=0;
a2s1_ack_o=0;
a2s2_ack_o=f2a_ack_i;
a2f_end_o=slv2_end_i;
end
2'b11:begin//default
a2f_val_o=0;
a2f_data_o=0;
a2f_pkglen_sel_o=0;
a2s0_ack_o=0;
a2s1_ack_o=0;
a2s2_ack_o=0;
a2f_end_o=0;
end
endcase
end
endmodule
第四节 arbitertestbench实现
文件名称:arbiter_tb.v
`timescale 1ns/1ns
`include "arbiter.v"
/*************************<端口声明>*********************/
module arbiter_tb;
reg clk_i,
rstn_i;
/********<control register 接口>*******/
reg [1:0] slv0_prio_i,
slv1_prio_i,
slv2_prio_i;
reg [2:0] slv0_pkglen_i,
slv1_pkglen_i,
slv2_pkglen_i;
/********<slave 接口>*********************/
reg [31:0] slv0_data_i,
slv1_data_i,
slv2_data_i;
reg slv0_req_i,
slv1_req_i,
slv2_req_i,
slv0_val_i,
slv1_val_i,
slv2_val_i,
slv0_end_i,
slv1_end_i,
slv2_end_i;
/********<formatter 接口>*********************/
reg f2a_id_req_i, //formatter请求接收
f2a_ack_i;
/********<slave 接口>*********************/
wire a2s0_ack_o, //[-slv]f2a_ack_i
a2s1_ack_o,
a2s2_ack_o,
/********<formatter 接口>*********************/
a2f_val_o; //[-slv]slvx_val_i,包有效包络信号
wire [1:0] a2f_id_o; //通道编号
wire [31:0] a2f_data_o; //[-slv]slvx_data_i
wire [2:0] a2f_pkglen_sel_o; //[-slv]slvx_pkglen_i
/********************<实例化arbiter>*********************/
arbiter ar1(
clk_i,
rstn_i,
slv0_prio_i,
slv1_prio_i,
slv2_prio_i,
slv0_pkglen_i,
slv1_pkglen_i,
slv2_pkglen_i,
slv0_data_i,
slv1_data_i,
slv2_data_i,
slv0_req_i,
slv1_req_i,
slv2_req_i,
slv0_val_i,
slv1_val_i,
slv2_val_i,
slv0_end_i,
slv1_end_i,
slv2_end_i,
f2a_id_req_i,
f2a_ack_i,
a2s0_ack_o,
a2s1_ack_o,
a2s2_ack_o,
a2f_val_o,
a2f_id_o,
a2f_data_o,
a2f_pkglen_sel_o,
a2f_end_o
);
initial begin
/*********<初始化>**********/
clk_i<=0;
rstn_i<=0;//
slv0_end_i<=0;
slv1_end_i<=0;
slv2_end_i<=0;
slv0_prio_i<=2'b11;//
slv1_prio_i<=2'b01;//这个是最优先通道
slv2_prio_i<=2'b01;//次优先通道
slv0_pkglen_i<=2'b10;//
slv1_pkglen_i<=2'b01;//数据长8
slv2_pkglen_i<=2'b00;//数据长4
slv0_data_i<=$random;
slv1_data_i<=$random;
slv2_data_i<=$random;
slv0_req_i<=0;
slv1_req_i<=0;
slv2_req_i<=0;
slv0_val_i<=0;
slv1_val_i<=0;
slv2_val_i<=0;
f2a_id_req_i<=0;//短时信号,在slvx_req_i就绪之后
f2a_ack_i<=0;//在slvx_req_i就绪之后
$dumpfile("arbiter.vcd");
$dumpvars;
/*********<生成波形>**********/
#25 rstn_i<=1;
#20 slv0_req_i<=1;
slv1_req_i<=1;
slv2_req_i<=1;
@(posedge clk_i)begin
f2a_id_req_i<=1;//两个短时信号
end
@(posedge clk_i)begin
f2a_id_req_i<=0;
f2a_ack_i<=1;
end
@(posedge clk_i)begin
f2a_ack_i<=0;
end
repeat(8)begin
@(posedge clk_i)begin
slv0_data_i<=$random;
slv1_data_i<=$random;
slv2_data_i<=$random;
slv0_val_i<=0;
slv1_val_i<=1;
slv2_val_i<=0;
end
end
slv0_end_i<=1;
slv1_end_i<=1;
slv2_end_i<=1;
@(posedge clk_i)begin
slv0_data_i<=$random;
slv1_data_i<=$random;
slv2_data_i<=$random;
slv0_end_i<=0;
slv1_end_i<=0;
slv2_end_i<=0;
slv0_val_i<=0;
slv1_val_i<=0;
slv2_val_i<=0;
slv0_req_i<=0;
slv1_req_i<=0;
slv2_req_i<=0;
end
#2000 $finish;
end
always #10 clk_i<=~clk_i;
endmodule
波形如图
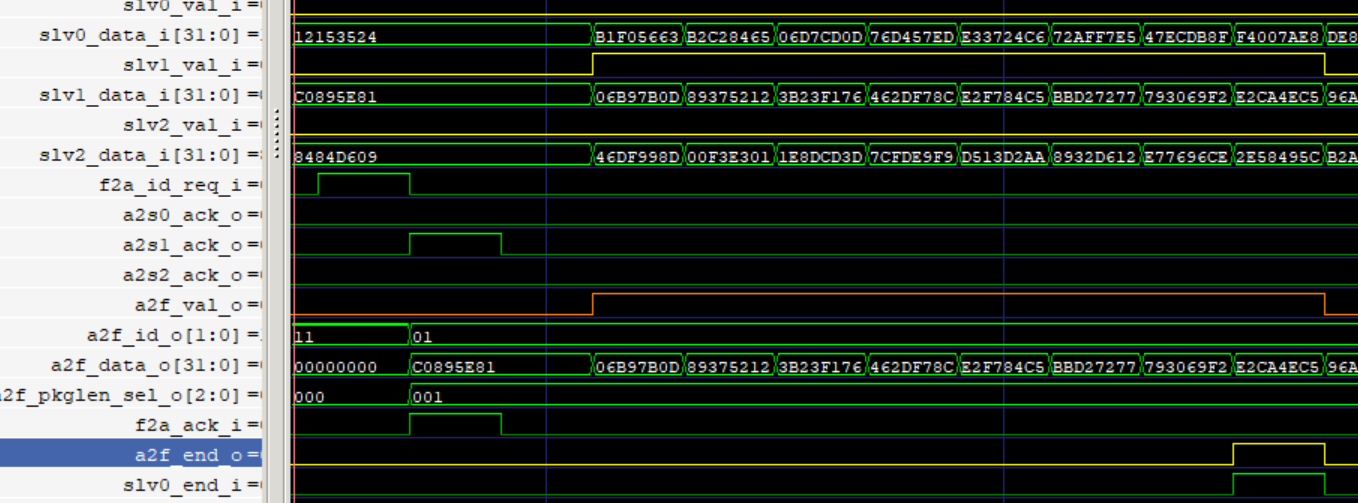
本例中由于存在一些握手机制,统一在MCDF最后的波形仿真中进行分析