尽管随着AI的普及,我们在生活中越来越依赖于人工智能,但“人工智障”的相关调侃也从来没有消失过。
相信大家都知道,如果我们想要让AI准确识别出图中的鸟,我们需要在数据集中手动将这些照片标记为鸟,然后让算法和图像之间产生关联性的判断识别。
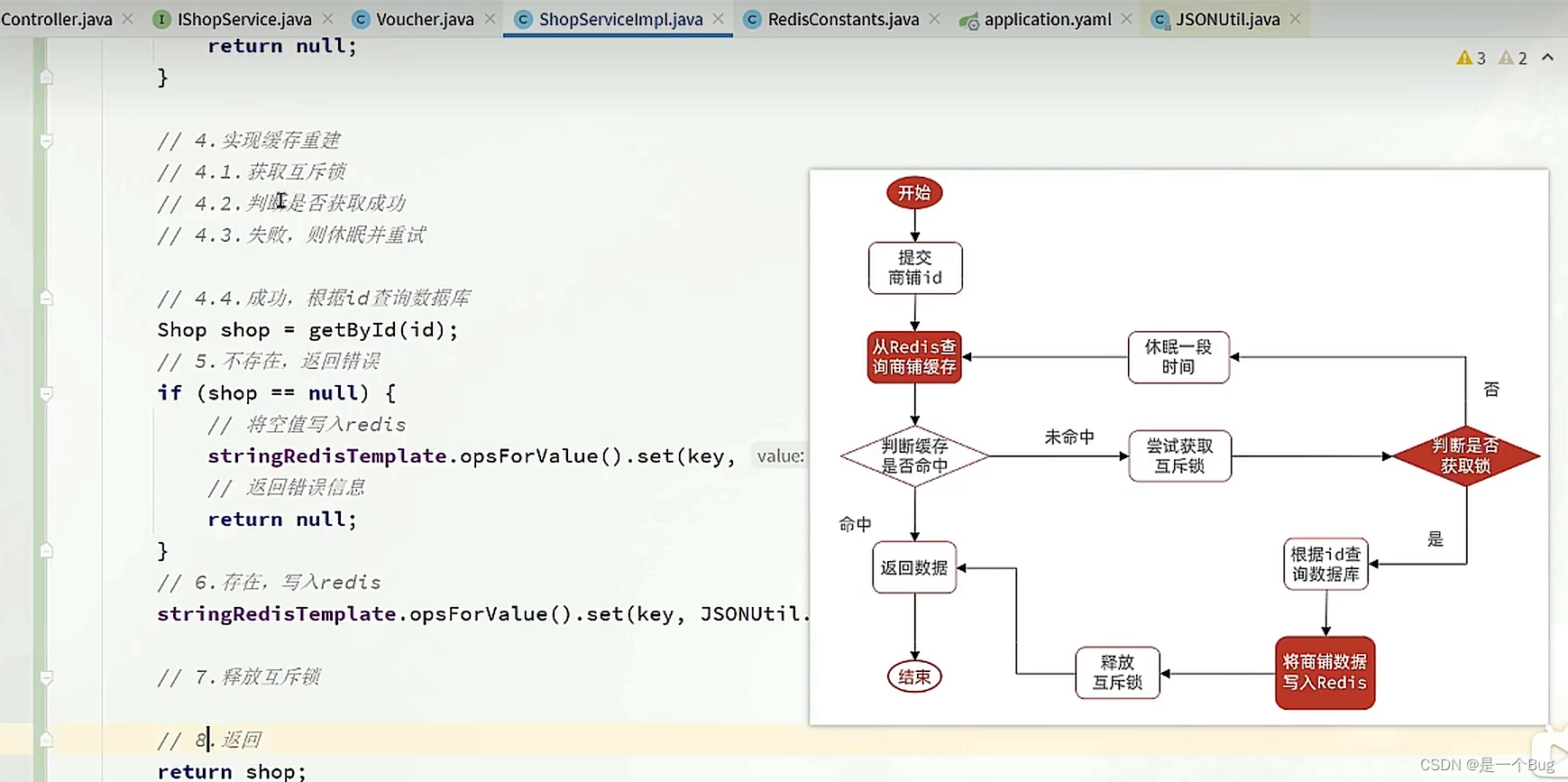
要是小规模的实验性数据还好,一旦遇到那种规模多达数百万个的标记需求,个中消耗的时间真是难以想象。
所谓“得数据者,得人工智能”,如今人工智能早已在我们的生活中屡见不鲜,像“指纹解锁”、“人脸识别”等等都属于人工智能的范畴,然而人工智能的上游基础产业,数据标注却鲜为人知。 什么是数据标注?
在了解数据标注之前,先来了解人工智能。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。
人工智能,其实是部分替代人的认知功能。人工智能算法是数据驱动型算法,也就是说,如果想实现人工智能,首先需要把人类理解和判断事物的能力教给计算机,让计算机学习到这种识别能力。
类比机器学习,我们要教它认识一只猫,直接给它一张猫的图片,它是完全不知道这是什么。

我们得先有猫的图片,上面标注着“猫”这个字,然后机器通过学习了大量的图片中的特征,这时候再给机器任意一张猫的图片,它就能认出来这是猫了。

训练集和测试集都是标注过的数据,以猫为例,假设我们有1000张标注着“猫”的图片,那么我们可以拿800张作为训练集,200张作为测试集。机器从800张猫的图片中学习得到一个模型,然后将剩下的200张机器没有见过的图片去给它识别,然后我们就能够得到这个模型的准确率了。
所以目前人工智能需要标注大量数据,即对原始信息进行数据标注。
数据标注为通过分类、画框、标注、注释等,对图片、语音、文本等数据进行处理,标记对象的特征,以作为机器学习基础素材的过程。
数据标注是大部分人工智能算法得以有效运行的关键环节。数据标注是把需要机器识别和分辨的数据贴上标签,然后让计算机不断地学习这些数据的特征,最终实现计算机能够自主识别。 数据标注的应用场景
1.智能安防 智能安防是人工智能与信息技术结合的关键领域,对于城市与民生发展有重要的意义。通过生物识别、行为监测等技术手段,广泛地应用于城市道路监控、车辆人流监测、公共安全防范等领域。
人脸标注在智能安防中主要应用于人脸识别与身份识别。

人脸识别也称人像识别、面部识别,是基于人的脸部特征信息进行多年龄段、多角度、多表情、多光线的人脸图像采集,从而完成身份识别的一种生物识别技术。人脸识别涉及的技术主要包括计算机视觉、图像处理等。

人脸识别(视觉识别技术的一种应用)在国内的应用大致经历从公共安全领域扩展到商业领域的过程。最初,机场、高铁站以及酒店等场景使用这项技术对个人身份进行验证,随后商业银行也开始采用人脸识别实现远程开户。再之后,刷脸支付、刷脸门禁也相继出现,人脸识别逐渐从少数有限场景渗透到人们的日常生活之中,目前,人脸识别技术已广泛应用于多个领域,除了智能安防之外,还应用于金融、司法、公安、边检、航天、电力、教育、医疗等众多领域。
此外,物品标注在智能安防应用中,物品标注需要和行为标注结合。

2.智能交通 近年来,随着人工智能浪潮的兴起,无人驾驶、智能交通安全系统一度走进我们的生活,国内许多公司纷纷投入到自动驾驶和无人驾驶的研究,例如百度启动的“百度无人驾驶汽车”计划,其自主研发的无人驾驶汽车Apollo还曾亮相2018年央视春晚。
在汽车自动驾驶的过程中,想要让汽车本身的算法做到处理更多、更复杂的场景,背后就需要有海量的真实道路数据做支撑。而这就需要依靠数据标注。

此外还有智慧停车,这些也都要依赖于人工智能数据标注的介入,对于行车视频进行采集,路况进行提取,停车点进行标注,包括D点云障碍物、红绿灯、车道灯及高精地图。为行人识别、车辆识别、红绿灯识别、车道线识别等技术提供精确训练数据,为智能交通保驾护航。
3.智能医疗 智能医疗是通过打造健康档案区域医疗信息平台,利用最先进的物联网技术,实现患者与医务人员、医疗机构、医疗设备之间的互动,逐步达到信息化。AI与医疗行业的结合将有望迎来跨越式发展。
医疗影像标注是对医疗影像进行区域标注及分类标注,多应用于辅助临床诊断。人工智能通过学习大量的医疗影像标注数据集,将会很好的辅助医生进行临床诊断以及提出治疗方案。
得数据者,得人工智能 人工智能主要算法应用领域集中在计算机视觉、语音识别/语音合成,以及自然语言处理三个方面。
图像方面:一个新研发的计算机视觉算法需要上万张到数十万张不等的标注图片训练,新功能的开发需要近万张图片训练,而定期优化算法也有上千张图片的需求,一个用于智慧城市的算法应用,每年都有数十万张图片的稳定需求。
语音方面:头部公司累计应用的标注数据集已达百万小时以上,每年需求仍以20%-30%的增速上升,要求数据服务商不仅要掌握专业的声学知识、数据标注经验,还要拥有语音合成的算法能力。
自然语言处理方面:随着工业、医疗、教育的AI应用产品进一步爆发,将会有更多交互方式出现,自然语义数据处理的需求将会持续增长,有望成为继图像、语音之后的第三大增量市场。
有多少智能,就有多少人工
这些海量的数据几乎全部依赖数据标注师手工进行标注,数据标注行业的缺口十分可观,并且数据标注已经在各行业产生了极广的应用,行业也开始逐渐升级,走向产业化。

在数据标注行业流行着一句话,“有多少智能,就有多少人工”。
近日,来自普林斯顿大学、康奈尔大学、蒙特利尔大学以及美国国家统计科学研究院共同发表的最新论文指出,这部分手动标记工作大多在美国及其他西方国家之外完成,并对全球各地的工人施以残酷剥削。
以 Sama(原 Samasource)、Mighty AI 以及 Scale AI 等数据标记公司为例,他们主要使用来自撒哈拉以南非洲以及东南亚地区的劳动力,每天支付给员工的薪酬仅为 8 美元(折合成人民币为 51.6 元)。但与此同时,这些企业每年却能赚取数千万美元的巨额收益。
现代人工智能依赖各种算法处理规模达数百万的示例、图像或文本素材。但在此之前,首先需要由工作人员在图片数据集中手动标记出对象,再将标记完成的大量图像交付给算法以学习模式,掌握如何准确识别对象。这类工作量极大、过程极其枯燥且耗时的手动数据标记过程,已经成为 AI 经济体系中的重要组成部分。
未来,随着AI应用场景逐渐多领域化,在数据标注行业内部,从业者也必将随着AI行业而一同进入细分市场追逐阶段,可谓机遇与挑战并行。