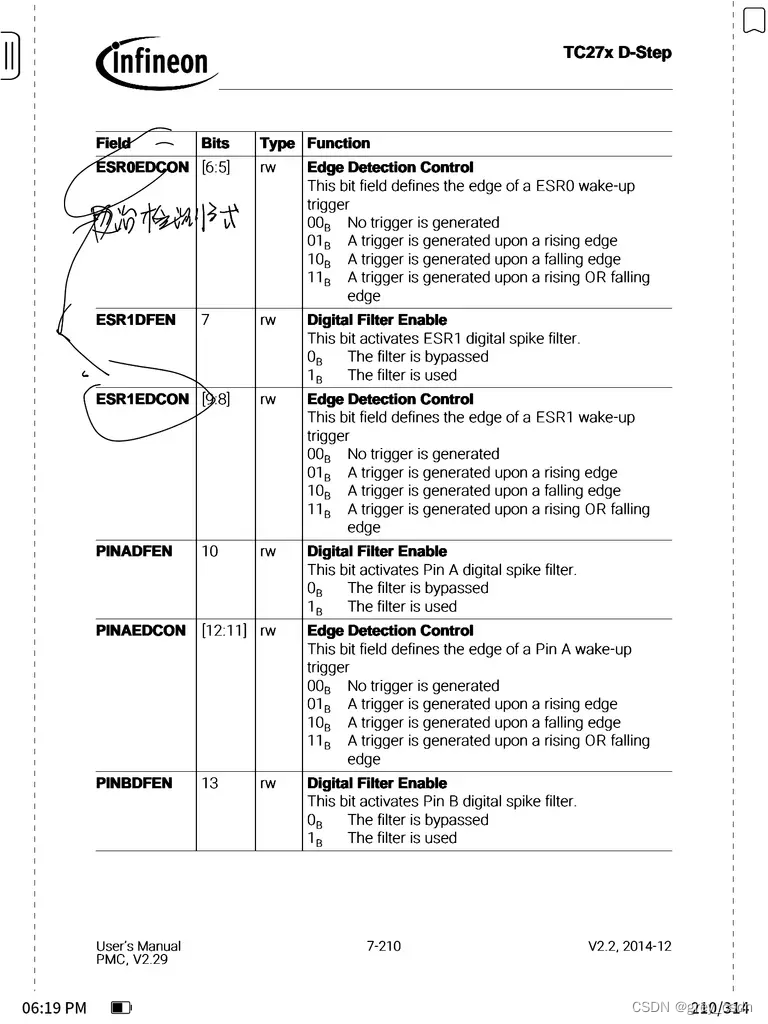
联合体
- 一.基本认识
- 1.一个联合体的基本样式
- 2.内部成员的访问
- 3.具体的内存分配
- 二.大小端对联合体的影响
- 三.一个问题

一.基本认识
1.一个联合体的基本样式


看得出来其实跟我们定义结构体是一样的(如果还不大了解结构体的可以看看这篇博客什么是结构体),事实上结构体和联合体也经常混在一起使用
想要认识联合体就得从它的内部空间分配开始
我们来看一个例子
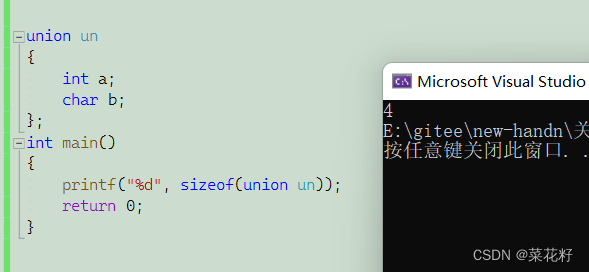
这里可能就发现有些不对了,一个int和一个char类型不应该是5个字节吗?为什么得出的结论却是4个字节呢?
这就引出了联合体的性质,联合体开辟空间的总大小是由最大的那个成员决定的。换言之,这里int是4个字节而char是1个字节,那么该空间大小就由int来决定,因为int更大(当然这里其实有点问题,并非它空间的大小就一定是最大成员的大小,我这里只说明一下现象)

相信大家都会认为这个空间大小是5,因为5最大吗,但其实并不是
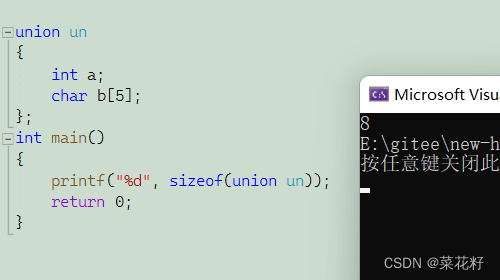
这是怎么一回事呢?这里有点复杂直接说结论:联合体内的总大小必须能整除里面每个成员的大小,换言之int是4,char是1,而它所需最大空间又是5,那么联合体空间大小必须大于5并且能整除1和4
联合体的本质是内部所有成员共用一个空间
2.内部成员的访问

与结构体一样,联合体既可以通过点操作符来访问,也可以用箭头操作符通过指针来访问
3.具体的内存分配

这里需要了解的是每一个字节都会有地址,而我们平时使用&操作符访问的其实是一个字节的地址(最低地址)
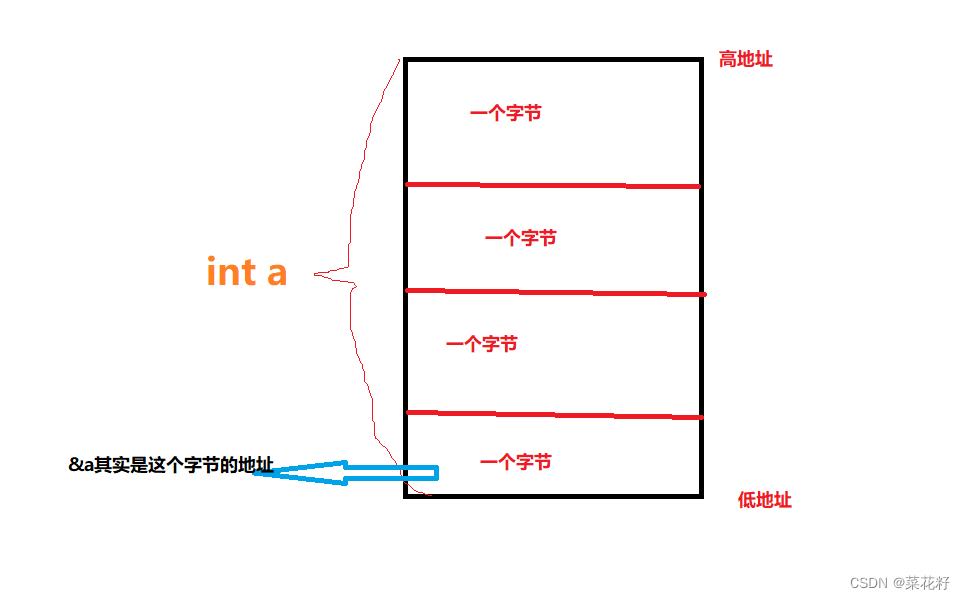
而整个联合体的地址也是该地址,换句话说,联合体的地址和该联合体内最大成员的地址在数值上是一样的

上文已经说到该联合体是4个字节(也就是a的空间大小),那么开辟b的时候又是怎么一回事呢?

可以看到b的地址竟然也和a一样,其实这也不难理解,因为b和a本质上是共用一个空间的
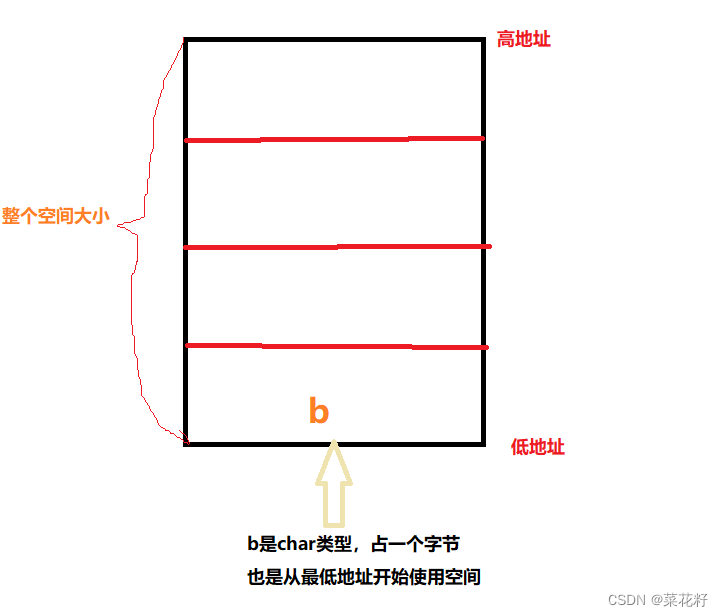
每个成员使用空间都是从最大成员的最低地址开始向上呈放射性开辟(你需要多大空间就向上开辟多少字节)
得出结论:联合体内所有成员的起始地址都是一样的!!
那么可能又有疑问了,又是a开辟地址,又是b开辟地址,那么它们的地址不是重合了吗?
这就又要提到联合体的本质了,上文已经说过所有成员共用同一地址。换言之,每个成员在开辟地址时虽然都从同一地址向上开辟,但它们都认为自己是唯一的元素(可以简单理解成每一个成员都认为自己是联合体内第一元素),这是联合体的性质
二.大小端对联合体的影响


首先在这里普及一下大小端的概念,将低权重数字放在低地址就是小端,将低权重数字放在高地址就是大端
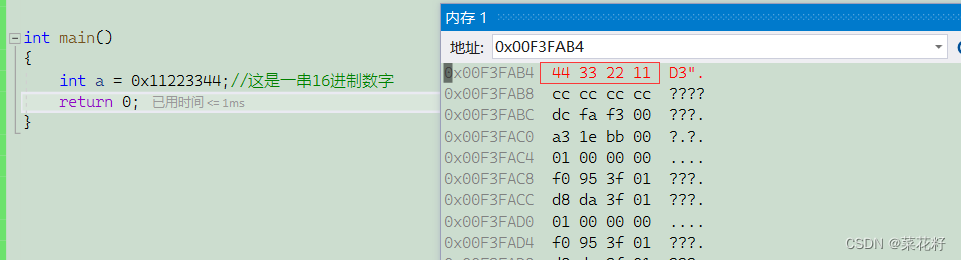
这里通过我们的内存监视可以看到,VS将权重低的数字(44)放在了高地址处,所有VS是使用的小端存放
好,进行完前置工作后,我们来看下一段代码
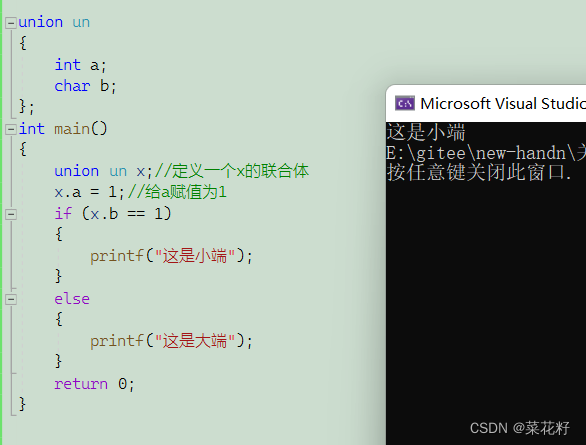
可以看到我们通过这一段代码可以不用通过内存监视直接判断编译器是大端还是小端,它究竟是怎么做到的呢?接下来一一解析
首先要了解的是int是4个字节32个比特位,那么1在内存中应当是31个0+最后一个1
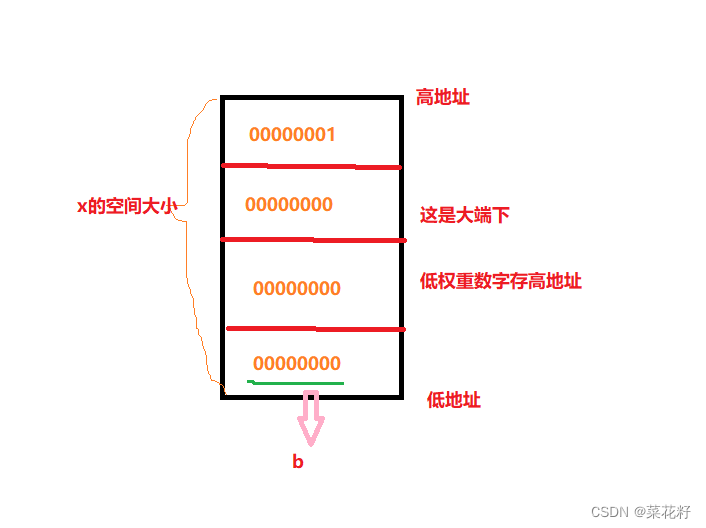
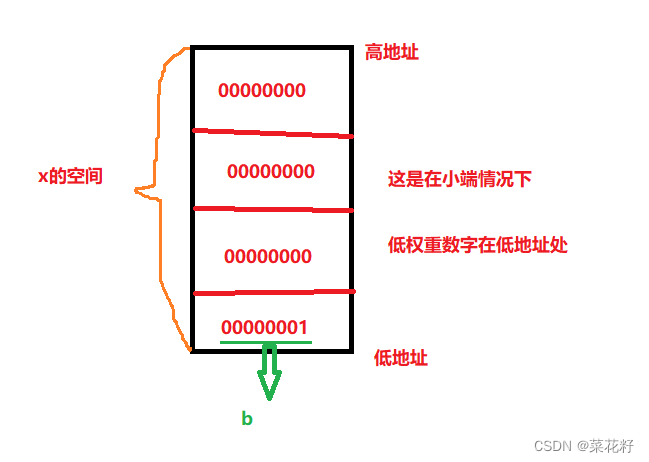
b是char类型,只有1个字节,而根据上文联合体的空间起始地址都是一样的。那么可以知道b所开辟的空间永远是在最低地址。而又因为我们并未给b赋值,所以b一直是a用“剩下的”。换言之,如果是大端,那么b的值就是0;如果是小端,那么b的值就是1
如果理解了上面的演示,那么相信就能明白为什么联合体可以用来判断编译器是大端还是小端啦
三.一个问题

这个程序打印出来的是什么呢?

接下来进行解析
p=&u是让*p指向该联合体。p->a[0]=0x36,是指将a[0]赋值为16进制的36。p->i是说明我们打印的是i的值,打印i的值就是将这4个字节当成一个整体来访问,如下图我们用数组将每个字节分别赋值,但我们直接打印一个整体(也就是4个字节)
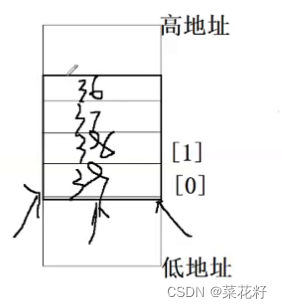
而我们的VS是小端,低权值数字放在低地址处,那么我们拿出来低地址的数据就该放到最后,也就是39放到最后。那么我们由下依次向上读取,最终就打印出来36373839啦

![[附源码]计算机毕业设计港口集团仓库管理系统Springboot程序](https://img-blog.csdnimg.cn/fcd06f6f2ef149a6b11440f5555f4000.png)

![[附源码]Node.js计算机毕业设计电商后台管理系统Express](https://img-blog.csdnimg.cn/b2e4bac576bb428d8f529f547a7e13e5.png)




![[1.2.0新功能系列:二] Apache Doris 1.2.0 JDBC外表 及 Mutil Catalog](https://img-blog.csdnimg.cn/img_convert/89057697ab6d9a07f92e99a8dfad955b.png)
