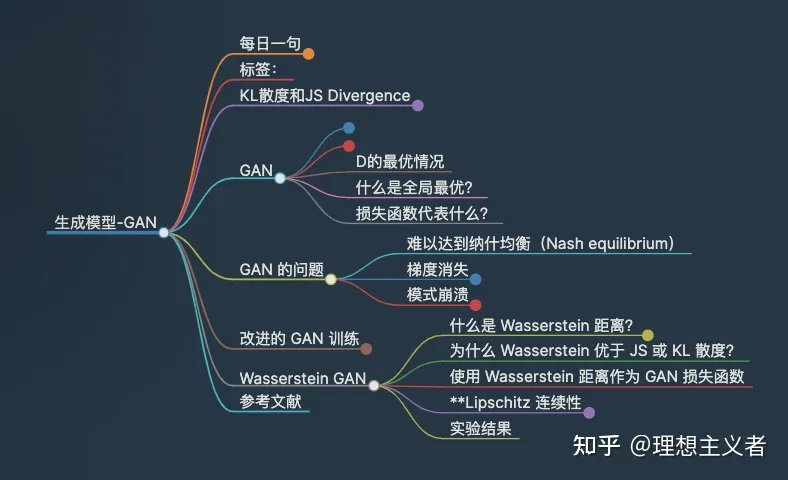
生成对抗网络 (GAN)在许多生成任务中显示出很好的结果,以复制真实世界的丰富内容,例如图像、文字和语音。它受到博弈论的启发:一个生成器和一个判别器,在互相竞争的同时让彼此变得更强大。然而,训练 GAN 模型相当具有挑战性,因为人们面临训练不稳定或无法收敛等问题。
KL散度和JS Divergence
首先回顾一下用于量化两个概率分布之间相似性的两个指标。
KL (Kullback-Leibler) 散度衡量一个概率分布如何p偏离第二个预期概率分布q.
D
K
L
(
p
∥
q
)
=
∫
x
p
(
x
)
log
p
(
x
)
q
(
x
)
d
x
D_{KL}(p \| q) = \int_x p(x) \log \frac{p(x)}{q(x)} dx
DKL(p∥q)=∫xp(x)logq(x)p(x)dx
当 p(x) == q(x) 时,D_{KL}达到最小值。 根据公式,很明显KL散度是不对称的。在这种情况下p(x)接近于零,但q(x)明显不为零,则q的影响被忽略。当我们只想测量两个同样重要的分布之间的相似性时,它可能会导致错误的结果。
Jensen-Shannon Divergence是两个概率分布之间相似性的另一种度量,其界限为[0,1]. JS 散度是对称且更平滑。如果您有兴趣关于 KL 散度和 JS 散度之间的比较的信息,请查看这篇Quora 帖子。
D_{JS}(p | q) = \frac{1}{2} D_{KL}(p | \frac{p + q}{2}) + \frac{1}{2} D_{KL}(q | \frac{p + q}{2}) \
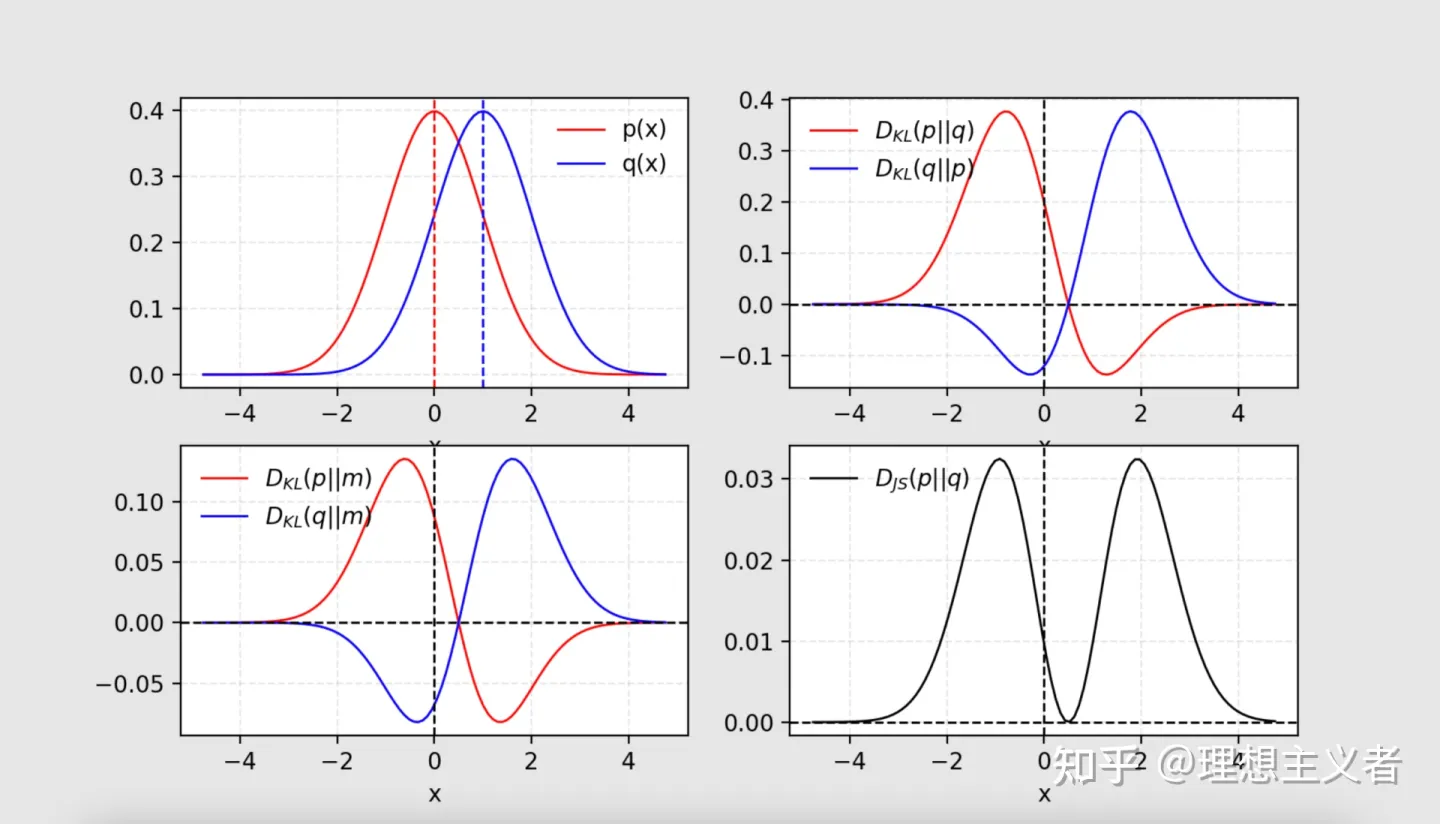
图 1. 给定两个高斯分布,p分布均值为0,标准差 1 ,q分布均值为1,标准差为1。两个分布的平均值标记为m=(p+q)/2. KL散度D_{KL}是不对称的,但 JS散度D_J{S}是对称的。
GAN 取得巨大成功的一个原因是将损失函数从传统最大似然方法中的不对称 KL 散度转换为对称 JS 散度。我们将在下一节中详细讨论这一点。
GAN
GAN 由两个模型组成:
判别器D估计给定样本来自真实数据集的概率。它作为一个分类器,并经过优化以区分假样本和真实样本。
生成器G在给定噪声变量输入的情况下输出合成样本z(z带来潜在的输出多样性)。它被训练来捕捉真实的数据分布,因此它的生成样本可以尽可能真实,或者换句话说,可以欺骗判别器以提供高概率。
这两个模型在训练过程中相互竞争:生成器G努力欺骗判别器,而判别模型D努力不被骗。两个模型之间的零和博弈促使二者进步。
p_{z} 噪声输入z上的数据分布 .
p_{g} 生成器在数据x上的分布 .
p_{r} 真实样本 x上的数据分布.
一方面,我们要确保判别器D对真实数据的估计 \mathbb{E}{x \sim p{r}(x)} [\log D(x)]是准确的. 同时,给定一个假样本 G(z), z \sim p_z(z), 判别器预计输出一个概率D(G(z)), 通过最大化 \mathbb{E}{z \sim p{z}(z)} [\log (1 - D(G(z)))]接近于零.
另一方面,对生成器进行训练以增加D产生高概率,从而最小化\mathbb{E}{z \sim p{z}(z)} [\log (1 - D(G(z)))].
将这两个方面结合在一起时,D和G正在玩一个极小极大游戏,我们应该优化以下损失函数:
\begin{aligned} \min_G \max_D L(D, G) & = \mathbb{E}{x \sim p{r}(x)} [\log D(x)] + \mathbb{E}{z \sim p_z(z)} [\log(1 - D(G(z)))] \ & = \mathbb{E}{x \sim p_{r}(x)} [\log D(x)] + \mathbb{E}_{x \sim p_g(x)} [\log(1 - D(x)] \end{aligned} \
(G在梯度下降更新期间\mathbb{E}{x \sim p{r}(x)} [\log D(x)] 没有影响.)
D的最优情况
现在我们有了一个定义明确的损失函数。让我们先来看看什么是zui y最优的D.
L(G, D) = \int_x \bigg( p_{r}(x) \log(D(x)) + p_g (x) \log(1 - D(x)) \bigg) dx \
因为我们感兴趣的最大话化L(G, D) 的最优D(x) ,
\tilde{x} = D(x), A=p_{r}(x), B=p_g(x) \
然后是积分里面的内容(我们可以放心地忽略积分,因为X对所有可能的值进行采样)是:
\begin{aligned} f(\tilde{x}) & = A log\tilde{x} + B log(1-\tilde{x}) \ \frac{d f(\tilde{x})}{d \tilde{x}} & = A \frac{1}{ln10} \frac{1}{\tilde{x}} - B \frac{1}{ln10} \frac{1}{1 - \tilde{x}} \ & = \frac{1}{ln10} (\frac{A}{\tilde{x}} - \frac{B}{1-\tilde{x}}) \ & = \frac{1}{ln10} \frac{A - (A + B)\tilde{x}}{\tilde{x} (1 - \tilde{x})} \ \end{aligned} \
因此,让 \frac{d f(\tilde{x})}{d \tilde{x}} = 0, 我们得到判别器的最佳值:D^(x) = \tilde{x}^ = \frac{A}{A + B} = \frac{p_{r}(x)}{p_{r}(x) + p_g(x)} \in [0, 1].
一旦生成器被训练到最佳状态, p_g 非常接近 p_{r}. 也就是说,当 p_g = p_{r}, D^*(x) 变成1/2.
什么是全局最优?
当两个G和D处于最佳值,我们有p_g = p_{r}和D^*(x) = 1/2损失函数变为:
\begin{aligned} L(G, D^) &= \int_x \bigg( p_{r}(x) \log(D^(x)) + p_g (x) \log(1 - D^*(x)) \bigg) dx \ &= \log \frac{1}{2} \int_x p_{r}(x) dx + \log \frac{1}{2} \int_x p_g(x) dx \ &= -2\log2 \end{aligned} \
损失函数代表什么?
根据之前的公式, p_{r} 和 p_g 的JS散度可以计算为:
\begin{aligned} D_{JS}(p_{r} | p_g) =& \frac{1}{2} D_{KL}(p_{r} || \frac{p_{r} + p_g}{2}) + \frac{1}{2} D_{KL}(p_{g} || \frac{p_{r} + p_g}{2}) \ =& \frac{1}{2} \bigg( \log2 + \int_x p_{r}(x) \log \frac{p_{r}(x)}{p_{r} + p_g(x)} dx \bigg) + \& \frac{1}{2} \bigg( \log2 + \int_x p_g(x) \log \frac{p_g(x)}{p_{r} + p_g(x)} dx \bigg) \ =& \frac{1}{2} \bigg( \log4 + L(G, D^*) \bigg) \end{aligned} \
因此,
L(G, D^*) = 2D_{JS}(p_{r} | p_g) - 2\log2 \
本质上,GAN 的损失函数量化了生成数据分布p_G和真实的样本分布p_r之间的相似性.
GAN 的问题
尽管 GAN 在图像生成方面取得了巨大成功,但训练并不容易;众所周知,该过程缓慢且不稳定。
难以达到纳什均衡(Nash equilibrium)
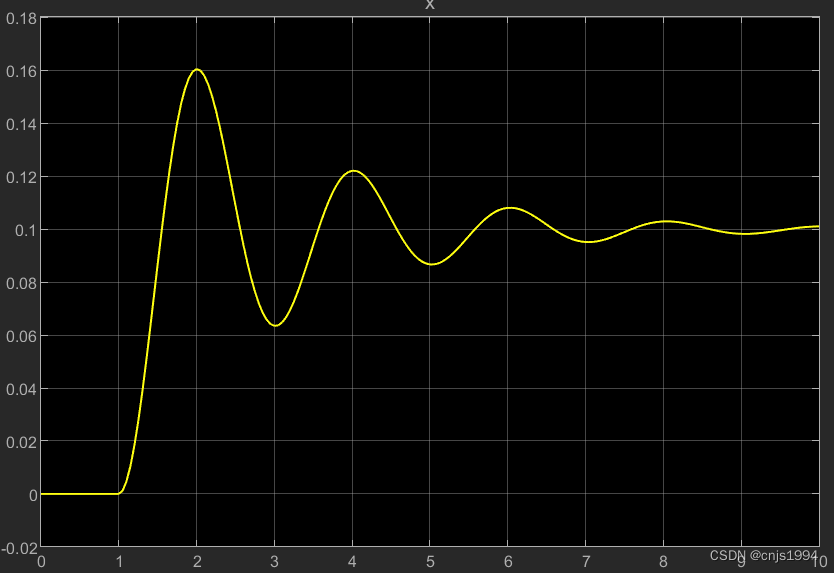
让我们看一个简单的例子,以更好地理解为什么在非合作博弈中很难找到纳什均衡。假设一名玩家控制 x 尽量减少 f_1(x) = xy, 而同时其他玩家不断更新 y 而同时其他玩家不断更新 f_2(y) = -xy.
因为 \frac{\partial f_1}{\partial x} = y , \frac{\partial f_2}{\partial y} = -x, 同一次迭代中我们用 x-\eta \cdot y 更新 x , 用y+ \eta \cdot x 更新y , 每一次x和y有不同的符号,每次梯度更新都会引起巨大的振荡,并且不稳定性会随着时间的推移而恶化,如图所示。
梯度消失
当判别器完美时,我们保证D(x) = 1, \forall x \in p_r 和 D(x) = 0, \forall x \in p_g. 因此损失函数大号下降到零,我们最终没有梯度来更新学习迭代期间的损失。下图展示了一个实验,当判别器变得更好时,梯度消失得很快。
因此,训练 GAN 面临两难境地:
如果判别器表现不佳,则生成器没有准确的反馈,损失函数无法代表现实。
如果判别器做得很好,损失函数的梯度下降到接近于零,学习变得超级慢甚至卡顿。 这种困境显然能够使 GAN 训练变得非常艰难。
模式崩溃
在训练期间,生成器可能会崩溃到它总是产生相同输出的设置。这是 GAN 的常见失败案例,通常称为Mode Collapse。即使生成器可能能够欺骗相应的判别器,它也无法学会表示复杂的现实世界数据分布,并且卡在了一个多样性极低的小空间中。
缺乏适当的评估指标
生成对抗网络缺少可以告知我们训练进度的函数。没有一个好的评估指标,就像在黑暗中工作。没有兆头告诉你什么时候停下来;同时也没有很好的指标来比较多个模型的性能。
改进的 GAN 训练
以下方法可以以帮助稳定和改进 GAN 的训练。前五种方法是实现 GAN 训练更快收敛的实用技术,在“Improve Techniques for Training GANs”中提出。最后两个是在“Towards principled methods for training generative adversarial networks”中提出的,以解决不相交分布的问题。
Feature Matching 特征匹配建议优化判别器以检查生成器的输出是否与真实样本的预期统计信息匹配。在这种情况下,新的损失函数定义为: | \mathbb{E}{x \sim p_r}f(x) - \mathbb{E}{z \sim p_z(z)}f(G(z)) |2^2 , f(x) 可以是特征统计的任何计算,例如均值或中值。
小批量判别 通过小批量判别,判别器能够学习一批训练数据点之间的关系,而不是独立处理每个点。
在一个小批量中,我们近似每对样本之间的接近度, c(x_i, x_j), 并通过总结它与同一批次中其他样本的接近程度来获得一个数据点的整体摘要, o(x_i) = \sum{j} c(x_i, x_j). 然后将 o(x_i) 显式添加到模型的输入中。
历史平均
对于这两个模型,添加 | \Theta - \frac{1}{t} \sum_{i=1}^t \Theta_i |^2 进入损失函数,其中 \Theta 是模型参数, \Theta_i是过去时刻 i模型参数. 这会惩罚训练速度,避免 \Theta变化太剧烈 .
单面标签平滑 输入鉴别器时,不要提供 1 和 0 标签,而是使用软化值,例如 0.9 和 0.1。它被证明可以减少网络的脆弱性。
虚拟批量标准化(VBN)
每个数据样本都基于固定批次数据进行标准化,而不是在其小批次内。参考批次在开始时选择一次,并在整个训练过程中保持不变。
添加噪声p_r和p_G在高维空间中是不相交的,它会导致梯度消失的问题。为增加两个概率分布创造更高的重叠机会,一种解决方案是在判别器的输入上添加连续噪声D.
使用更好的分布相似度度量 vanilla GAN的损失函数测量了p_r和p_G分布之间的JS散度. 当两个分布不相交时,该指标无法提供有意义的值。 Wasserstein 度量被提出来代替 JS 散度,因为它具有更平滑的值空间。
Wasserstein GAN
什么是 Wasserstein 距离?
Wasserstein 距离是两个概率分布之间距离的度量。它也被称为Earth Mover 距离,因为非正式地它可以解释为将一堆泥土从一种概率分布的形状移动并转换为另一种分布的形状的最小能量成本。成本量化为:移动的泥土 x 移动距离。
让我们首先看一个离散概率的简单情况。例如,假设我们有两个分布P和Q,每人四堆土,一共十铲土。每个土堆中的铲子数量分配如下:
P_1 = 3, P_2 = 2, P_3 = 1, P_4 = 4\ Q_1 = 1, Q_2 = 2, Q_3 = 4, Q_4 = 3 \
为了将P改变为Q,如图 所示,我们:
第一步, 从P_1 移动两铲到 P_2 => (P_1, Q_1) 配对.
第二步, 从 P_2 移动两铲到 P_3 => (P_2, Q_2) 配对.
第三步,从 Q_3 移动一铲到 Q_4 => (P_3, Q_3) \ (P_4, Q_4) 配对.
如果我们标明 P_i 和 Q_i 的制造成本为 \delta_i, 有 \delta_{i+1} = \delta_i + P_i - Q_i :
\begin{aligned} \delta_0 &= 0\ \delta_1 &= 0 + 3 - 1 = 2\ \delta_2 &= 2 + 2 - 2 = 2\ \delta_3 &= 2 + 1 - 4 = -1\ \delta_4 &= -1 + 4 - 3 = 0 \end{aligned} \
最后,移动的距离是 W = \sum \vert \delta_i \vert = 5.
在处理连续概率域时,距离公式变为:
W(p_r, p_g) = \inf_{\gamma \sim \Pi(p_r, p_g)} \mathbb{E}_{(x, y) \sim \gamma}[| x-y |] \
在上面的公式中, \Pi(p_r, p_g) 是所有p_r 和p_g可能的联合概率分布的集合。一次联合分布\gamma \in \Pi(p_r, p_g) 描述了一种泥土运输计划。将 x 视为起点, y 看作为目的地, 移动的污垢总量为 γ(x,y) , 行驶距离为 |x−y| ,因此成本是γ(x,y)⋅|x−y|. 平均预期成本(x,y)可以很容易地计算为:
\sum_{x, y} \gamma(x, y) | x-y | = \mathbb{E}_{x, y \sim \gamma} | x-y | \
最后,我们将所有泥土移动解决方案的成本中的最小值作为 EM 距离。
为什么 Wasserstein 优于 JS 或 KL 散度?
即使两个分布位于没有重叠的低维流形中,Wasserstein 距离仍然可以提供有意义且平滑的中间距离表示。 WGAN 论文用一个简单的例子来说明这个想法。假设我们有两个概率分布,P & Q:
\forall (x, y) \in P, x = 0 \text{ and } y \sim U(0, 1)\ \forall (x, y) \in Q, x = \theta, 0 \leq \theta \leq 1 \text{ and } y \sim U(0, 1)\ \
当 \theta \neq 0时:
\begin{aligned} D_{KL}(P | Q) &= \sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{0} = +\infty \ D_{KL}(Q | P) &= \sum_{x=\theta, y \sim U(0, 1)} 1 \cdot \log\frac{1}{0} = +\infty \ D_{JS}(P, Q) &= \frac{1}{2}(\sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{1/2} + \sum_{x=0, y \sim U(0, 1)} 1 \cdot \log\frac{1}{1/2}) = \log 2\ W(P, Q) &= |\theta| \end{aligned} \
但当 θ=0 时, 两个分布完全重叠:
\begin{aligned} D_{KL}(P | Q) &= D_{KL}(Q | P) = D_{JS}(P, Q) = 0\ W(P, Q) &= 0 = \lvert \theta \rvert \end{aligned} \
当两个分布不相交时D_{KL} 为无穷大. D_{JS} 会有突然的跳跃,在 \theta = 0处不可导. 只有 Wasserstein 度量提供了平滑的度量,这对于使用梯度下降的稳定学习过程非常有帮助。
使用 Wasserstein 距离作为 GAN 损失函数
穷尽\Pi(p_r, p_g) 所有可能的联合分布计算 \inf_{\gamma \sim \Pi(p_r, p_g)}是很困难的. 因此,作者提出了基于 Kantorovich-Rubinstein 对偶的公式的智能转换:
W(p_r, p_g) = \frac{1}{K} \sup_{| f |L \leq K} \mathbb{E}{x \sim p_r}[f(x)] - \mathbb{E}_{x \sim p_g}[f(x)] \
\sup是 inf反面; 我们想要测量最小的上界,或者更简单地说,最大值。
**Lipschitz 连续性
函数 f 在新形式的 Wasserstein 度量中,要求满足| f |_L \leq K, 意味着它应该是K-Lipschitz 连续的。
实值函数 f: \mathbb{R} \rightarrow \mathbb{R} 被称作K-Lipschitz 连续,如果存在实常数K \geq 0,对所有 x_1, x_2 \in \mathbb{R}, 有
\lvert f(x_1) - f(x_2) \rvert \leq K \lvert x_1 - x_2 \rvert \
K 被称为函数 f(.)的 Lipschitz 常数。处处连续可微的函数是 Lipschitz 连续的, 因为导数估计为\frac{\lvert f(x_1) - f(x_2) \rvert}{\lvert x_1 - x_2 \rvert}, 是有界的。 然而,Lipschitz 连续函数可能并非处处可微,例如 f(x) = \lvert x \rvert.
解释如何在 Wasserstein 距离公式上发生转换本身就值得一长篇文章,所以我在这里跳过细节。如果您对如何使用线性规划计算 Wasserstein 度量,或者如何根据 Kantorovich-Rubinstein Duality 将 Wasserstein 度量转换为对偶形式感兴趣,请阅读这篇文章。
假设函数 f 来自一个 K-Lipschitz 连续函数族 { f_w }_{w \in W}。在修改后的 Wasserstein-GAN 中,“判别器”模型用于学习 w 找到一个好的 f_w ,并且损失函数被设置为测量 p_r 和 p_g之间的 Wasserstein 距离.
L(p_r, p_g) = W(p_r, p_g) = \max_{w \in W} \mathbb{E}{x \sim p_r}[f_w(x)] - \mathbb{E}{z \sim p_r(z)}[f_w(g_\theta(z))] \
因此,“判别器”不再直接将假样本与真实样本区分开来。相反,它被用来学习K-Lipschitz 连续函数,帮助计算 Wasserstein 距离。随着训练中损失函数的减小,Wasserstein 距离变小,生成器模型的输出越来越接近真实数据分布。
一个大问题是维护f_w 在训练期间的K-Lipschitz 连续性。该论文提出了一个简单但非常实用的技巧:在每次梯度更新后,将权重w设定到一个小窗口,例如[-0.01,0.01],导致紧凑的参数空间W, 因此F_w获得其下界和上界以保持 Lipschitz 连续性。
与原始 GAN 算法相比,WGAN 进行了以下更改:
在critic函数的每次梯度更新后,将权重限制在一个小的固定范围内,[-C,C].
使用从 Wasserstein 距离推导出的新损失函数,不再使用对数。“判别器”模型不作为判断者,而是作为估计真实数据分布和生成数据分布之间的 Wasserstein 度量的帮助者。
根据经验,作者建议在判别器上使用RMSProp优化器,而不是Adam这样可能导致模型训练不稳定的基于动量的优化器。
实验结果
作者设置了一个小实验来展示 GAN 和 WGAN 之间的区别。有两个一维高斯分布,蓝色代表真实,绿色代表虚假。将 GAN 判别器和 WGAN 判别器训练到最优,然后在空间上绘制它们的值。红色曲线是 GAN 判别器输出,青色曲线是 WGAN 判别器输出。
两者都可以识别哪个分布是真实的,哪个是假的,但是 GAN 鉴别器这样做的方式是使梯度在大部分空间中消失。相比之下,WGAN 中的权重在所有内容上都提供了相当不错的梯度。 在卧室数据集上的 DCGAN 基线相比,性能也差不多。上图:具有与 DCGAN 相同架构的 WGAN。底部:DCGAN
具有 DCGAN 架构的 DCGAN
如果我们从生成器中删除批范数,WGAN 仍然会生成好的样本,但 DCGAN 完全失败了
最后,使用前馈网络而不是卷积网络作为生成器。参数的数量保持不变,同时消除了卷积模型中的归纳偏差。WGAN 样本更详细,并且不会像标准 GAN 那样崩溃。事实上,他们报告说 WGAN 根本不会遇到模式崩溃!
具有 MLP 架构的 WGAN
具有 MLP 架构的 DCGAN
顶部:具有 MLP 架构的 WGAN。底部:相同架构的标准 GAN。
但是,Wasserstein GAN 并不完美。WGAN 仍然存在训练不稳定、权重裁剪后收敛缓慢(裁剪窗口太大)和梯度消失(裁剪窗口太小)等问题。
参考文献
[1] Goodfellow, Ian, et al. “Generative adversarial nets." NIPS, 2014.
[2] Tim Salimans, et al. “Improved techniques for training gans." NIPS 2016.
[3] Martin Arjovsky and Léon Bottou. “Towards principled methods for training generative adversarial networks." arXiv preprint arXiv:1701.04862 (2017).
[4] Martin Arjovsky, Soumith Chintala, and Léon Bottou. “Wasserstein GAN." arXiv preprint arXiv:1701.07875 (2017).
[5] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville. Improved training of wasserstein gans. arXiv preprint arXiv:1704.00028 (2017).
[6] Computing the Earth Mover’s Distance under Transformations
[7] Wasserstein GAN and the Kantorovich-Rubinstein Duality
[8] zhuanlan.zhihu.com/p/25071913
[9] Ferenc Huszár. “How (not) to Train your Generative Model: Scheduled Sampling, Likelihood, Adversary?." arXiv preprint arXiv:1511.05101 (2015).
参考资料:
生成模型(一):GAN

![[附源码]Node.js计算机毕业设计电商后台管理系统Express](https://img-blog.csdnimg.cn/b2e4bac576bb428d8f529f547a7e13e5.png)




![[1.2.0新功能系列:二] Apache Doris 1.2.0 JDBC外表 及 Mutil Catalog](https://img-blog.csdnimg.cn/img_convert/89057697ab6d9a07f92e99a8dfad955b.png)