文章地址:https://arxiv.org/abs/1901.11365
代码地址: https://github.com/czbiohub-sf/noise2self
要点
Noise2Self方法不需要信号先验信息、噪声估计信息和干净的训练数据。唯一的假设就是噪声在测量的不同维度上表现出的统计独立性,而真实信号表现出一定的相关性。Noiser2Self根据J-invariant提出了一种噪声校正的方案,可以应用到一系列的去噪方法之中,提高这些去噪方法的效果。
文章目录
- 1. 方法原理
- 2. 实验结果
- 2.1 传统校正方法
- 2.2 高斯噪声
- 2.3 不同网络结构对比
- 3. 代码实现
- 3.1 J-invariant + 传统方法
- 3.1 J-invariant + 神经网络
- 4. 总结
1. 方法原理
如果所研究对象的空间的“潜在维度”远低于测量的维度,则可以隐式地学习该结构,对测量进行降噪,并在没有任何先验知识的情况下恢复信号,信号或噪声。
传统方法问题:
- 需要对噪声模式进行估计(如高斯噪声、结构性噪声),那么这些方法的效果就受限于对噪声模式的估计。
- 需要对信号数据的结构有先验估计,但是这会限制去噪方法迁移到其他数据集。
- 需要校准,因为平滑度、自相似性或矩阵的秩等超参数对去噪方法也会有影响
J-invariant 定义:
假设 j ∈ J j \in J j∈J, J J J是m维空间, 存在一个函数变换 f ( x ) J : R m ⇒ R m f(x)_J: R^m \Rightarrow R^m f(x)J:Rm⇒Rm。如果这个变换过程不依赖于输入的 x J x_J xJ,那么称这个函数是具有J不变性质。
换个能看懂的说法:信号本身是相关的,假设噪声是互不相关的(条件独立的),那么我们用一个方法对这个噪声图片的部分数据进行处理,这个处理结果应该是和处理全部数据效果相同的,也就是使用部分维度信息达到恢复全局的效果。(需要强调的是我自己这里也没有理解特别透彻,如果有错误可以提出大家讨论)

假设
x
x
x(噪声图片) 是
y
y
y(干净图片)的无偏估计(
E
[
x
∣
y
]
=
y
E[x|y] = y
E[x∣y]=y), 噪声是整个域内是条件独立的,那么有:
E
∣
∣
f
(
x
)
−
x
∣
∣
2
2
=
E
∣
∣
f
(
x
)
−
y
∣
∣
2
2
+
E
∣
∣
x
−
y
∣
∣
2
2
E||f(x) - x||_2^2 = E||f(x) - y||_2^2 + E||x - y||_2^2
E∣∣f(x)−x∣∣22=E∣∣f(x)−y∣∣22+E∣∣x−y∣∣22
可以看到这里的无监督学习的损失等于 传统的监督学习的损失 加上噪声带来的偏差。
用J不变性描述一下 Noise2Noise就变为
如果现在有两个观测的噪声数据
x
1
=
y
+
n
1
x_1 = y + n_1
x1=y+n1 ,
x
2
=
y
+
n
2
x_2 = y + n_2
x2=y+n2。
观测组合:
x
=
(
x
1
,
x
2
)
x = (x_1,x_2)
x=(x1,x2)
信号组合
y
=
(
y
,
y
)
∈
R
2
m
y = (y,y) \in R^{2m}
y=(y,y)∈R2m
如果存在
J
=
{
J
1
,
J
2
}
=
{
{
1
,
.
.
.
,
m
}
,
{
m
+
1
,
.
.
.
,
2
m
}
}
J = \{J_1,J_2\} = \{\{1,...,m\},\{m+1,...,2m\}\}
J={J1,J2}={{1,...,m},{m+1,...,2m}},那么有
f
J
∗
(
x
)
J
2
=
E
[
y
∣
x
1
]
f_{J}^*(x)_{J2} = E[y|x_1]
fJ∗(x)J2=E[y∣x1]
就个人理解:J-不变性就是一个假设:如果噪声是条件独立的,那么监督去噪等价于无监督去噪加上一个噪声的偏差影响。
2. 实验结果
2.1 传统校正方法
首先将J不变性应用到 传统方法中:
传统的 “median filter”是将半径范围内所有像素的点都替换为中值
这里对比的是一种“donut filter”中值滤波方法:用中值替换除了中心像素的所有位置
那么“median filter”和“donut”甜甜圈模式的滤波器,其自监督的损失分别为
∣
∣
g
r
(
x
)
−
x
∣
∣
2
||g_r(x) - x||^2
∣∣gr(x)−x∣∣2
∣ ∣ f r ( x ) − x ∣ ∣ 2 ||f_r(x) - x||^2 ∣∣fr(x)−x∣∣2
用图绘制出来:

从上图可以看出:median滤波器监督学习的损失随着半径的增加而线性增加,而donut滤波器在r = 3的时候其损失有一个最佳值。蓝色实线和蓝色虚线的垂直距离其实表征的是噪声带来的偏差,那么我们就发现了对于传统的滤波器,我们只能够更改输入来进行调整滤波效果,但是对于donut这类具有J-invariant性质的滤波器,我们可以通过一些原则来调整滤波效果(比如这里的距离r)
那么就可以给定一个比较通用的新滤波器形式了
f
θ
(
x
)
J
:
=
g
θ
(
1
J
.
s
(
x
)
+
1
J
c
.
x
)
J
f_{\theta}(x)_J := g_{\theta}(1_J . s(x) + 1_{Jc} . x)_J
fθ(x)J:=gθ(1J.s(x)+1Jc.x)J
这里的 g θ g_{\theta} gθ表示传统的滤波其, s ( x ) s(x) s(x)表示将一些像素替换为周围其他像素的值/均值的一个操作。
个人理解:和Noise2Void那种盲点去噪的感觉相同,都是将输入的某些值进行替换,然后恢复那个点的信息。如果将这种方法应用到传统方法中可以帮我们找到最佳的滤波参数。
2.2 高斯噪声

2.3 不同网络结构对比

3. 代码实现
相关代码参考: https://github.com/czbiohub-sf/noise2self
3.1 J-invariant + 传统方法
这里以使用 J-invariant 到 中值滤波为例
加载相关库和数据
import sys
sys.path.append("..")
import numpy as np
import matplotlib.pyplot as plt
from skimage.morphology import disk
from skimage.filters import gaussian, median
from skimage import data, img_as_float, img_as_ubyte
from skimage.color import gray2rgb
from skimage.util import random_noise
from skimage.metrics import structural_similarity as ssim
from skimage.metrics import peak_signal_noise_ratio as psnr
from skimage.metrics import mean_squared_error as mse
from util import plot_grid, plot_images, expand
# 加载原始数据
plt.rc('figure', figsize = (5,5))
show = lambda x: plt.imshow(x, cmap=plt.cm.gray)
image = data.camera()
show(image)
plt.show()
# 加噪原始数据
np.random.seed(3)
noisy_image = img_as_ubyte(random_noise(image, mode = 'gaussian', var=0.01))
show(noisy_image)
plt.show()

定义中值滤波和donut中值滤波方法(引入J-invariant)
def mask_center(x):
x[len(x)//2,len(x)//2] = 0
return x
plot_images([1-disk(4), 1-mask_center(disk(4))])

滤波并进行对比
radii = range(1, 7)
mask_med = np.array([median(noisy_image, mask_center(disk(i))) for i in radii])
med = np.array([median(noisy_image, disk(i)) for i in radii])
plt.figure(figsize=(18,6))
for i in range(1,7):
plt.subplot(2,6,i)
show(mask_med[i-1])
plt.title("r={}".format(radii[i-1]))
if i ==1:
plt.ylabel("donut")
for i in range(1,7):
plt.subplot(2,6,6+i)
show(med[i-1])
if i ==1:
plt.ylabel("median filter")
plt.show()

统计损失及相关参考指标
def stats(im_list, noisy_img, img):
img = img_as_float(img)
noisy_img = img_as_float(noisy_img)
im_list = [img_as_float(x) for x in im_list]
loss = [mse(x, noisy_img) for x in im_list]
mse_gt = [mse(x, img) for x in im_list]
psnr_gt = [psnr(x, img) for x in im_list]
return loss, mse_gt, psnr_gt
loss_med, mse_med, psnr_med = stats(med, noisy_image, image)
loss_mask_med, mse_mask_med, psnr_mask_med = stats(mask_med, noisy_image, image)
opt = radii[np.argmin(loss_mask_med)]
plt.figure(figsize=(7,5))
plt.plot(radii, loss_mask_med, label = 'self-supervised, donut median', color = 'C0')
plt.plot(radii, loss_med, label = 'self-supervised, ordinary median', color = 'C1')
plt.axvline(radii[np.argmin(loss_mask_med)], color='k', linestyle='--')
plt.title('Calibrating a Median Filter')
plt.plot(radii, mse_mask_med, label = 'reconstruction error, donut median', color = 'C0', linestyle='--')
plt.plot(radii, mse_med, label = 'reconstruction error, ordinary median', color = 'C1', linestyle='--')
plt.ylabel('MSE')
plt.xlabel('Radius of Median Filter')
plt.yticks([0.002, 0.012])
plt.ylim(0, 0.0143)
plt.legend(loc='center right')
plt.show()

加入J-invariant之后可以帮助我们找到最佳的滤波参数(此处r = 3)
3.1 J-invariant + 神经网络
加载库及数据
from util import show, plot_images, plot_tensors
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import Dataset
mnist_train = MNIST(root='/data/mnist/', download = True,
transform = transforms.Compose([
transforms.ToTensor(),
]), train = True)
mnist_test = MNIST('/data/mnist/', download = True,
transform = transforms.Compose([
transforms.ToTensor(),
]), train = False)
定义加噪方法
from torch import randn
def add_noise(img):
return img + randn(img.size())*0.4
class SyntheticNoiseDataset(Dataset):
def __init__(self, data, mode='train'):
self.mode = mode
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
img = self.data[index][0]
return add_noise(img), img
noisy_mnist_train = SyntheticNoiseDataset(mnist_train, 'train')
noisy_mnist_test = SyntheticNoiseDataset(mnist_test, 'test')
noisy, clean = noisy_mnist_train[0]
plot_tensors([noisy[0], clean[0]], ['Noisy Image', 'Clean Image'])

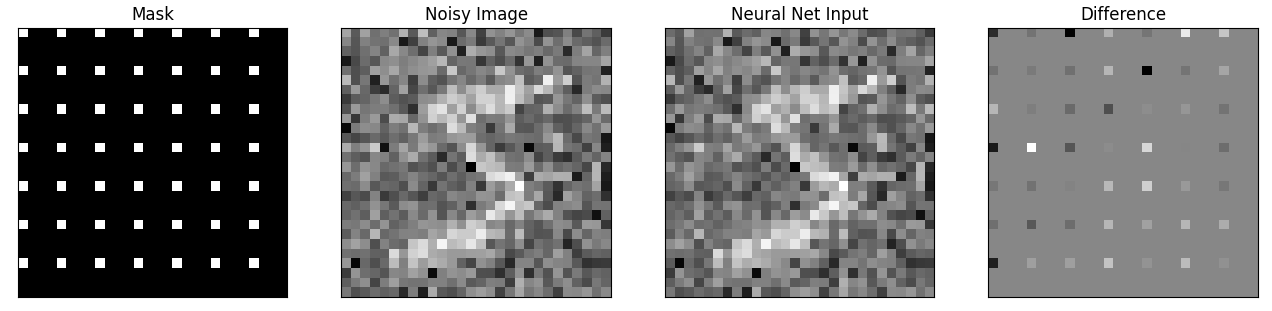
加mask也就是加盲点,需要恢复的也是这些盲点的信息
class Masker():
"""Object for masking and demasking"""
def __init__(self, width=3, mode='zero', infer_single_pass=False, include_mask_as_input=False):
self.grid_size = width
self.n_masks = width ** 2
self.mode = mode
self.infer_single_pass = infer_single_pass
self.include_mask_as_input = include_mask_as_input
def mask(self, X, i):
phasex = i % self.grid_size
phasey = (i // self.grid_size) % self.grid_size
mask = pixel_grid_mask(X[0, 0].shape, self.grid_size, phasex, phasey)
mask = mask.to(X.device)
mask_inv = torch.ones(mask.shape).to(X.device) - mask
if self.mode == 'interpolate':
masked = interpolate_mask(X, mask, mask_inv)
elif self.mode == 'zero':
masked = X * mask_inv
else:
raise NotImplementedError
if self.include_mask_as_input:
net_input = torch.cat((masked, mask.repeat(X.shape[0], 1, 1, 1)), dim=1)
else:
net_input = masked
return net_input, mask
def __len__(self):
return self.n_masks
def infer_full_image(self, X, model):
if self.infer_single_pass:
if self.include_mask_as_input:
net_input = torch.cat((X, torch.zeros(X[:, 0:1].shape).to(X.device)), dim=1)
else:
net_input = X
net_output = model(net_input)
return net_output
else:
net_input, mask = self.mask(X, 0)
net_output = model(net_input)
acc_tensor = torch.zeros(net_output.shape).cpu()
for i in range(self.n_masks):
net_input, mask = self.mask(X, i)
net_output = model(net_input)
acc_tensor = acc_tensor + (net_output * mask).cpu()
return acc_tensor
def pixel_grid_mask(shape, patch_size, phase_x, phase_y):
A = torch.zeros(shape[-2:])
for i in range(shape[-2]):
for j in range(shape[-1]):
if (i % patch_size == phase_x and j % patch_size == phase_y):
A[i, j] = 1
return torch.Tensor(A)
def interpolate_mask(tensor, mask, mask_inv):
device = tensor.device
mask = mask.to(device)
kernel = np.array([[0.5, 1.0, 0.5], [1.0, 0.0, 1.0], (0.5, 1.0, 0.5)])
kernel = kernel[np.newaxis, np.newaxis, :, :]
kernel = torch.Tensor(kernel).to(device)
kernel = kernel / kernel.sum()
filtered_tensor = torch.nn.functional.conv2d(tensor, kernel, stride=1, padding=1)
return filtered_tensor * mask + tensor * mask_inv
masker = Masker(width = 4, mode='interpolate')
net_input, mask = masker.mask(noisy.unsqueeze(0), 0)
plot_tensors([mask, noisy[0], net_input[0], net_input[0] - noisy[0]],
["Mask", "Noisy Image", "Neural Net Input", "Difference"])
加载网络模型和进行训练
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import MSELoss
from torch.optim import Adam
from torch.utils.data import DataLoader
from tqdm import tqdm
from models.modules import ConvBlock
class BabyUnet(nn.Module):
def __init__(self, n_channel_in=1, n_channel_out=1, width=16):
super(BabyUnet, self).__init__()
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.up1 = lambda x: F.interpolate(x, mode='bilinear', scale_factor=2, align_corners=False)
self.up2 = lambda x: F.interpolate(x, mode='bilinear', scale_factor=2, align_corners=False)
self.conv1 = ConvBlock(n_channel_in, width)
self.conv2 = ConvBlock(width, 2*width)
self.conv3 = ConvBlock(2*width, 2*width)
self.conv4 = ConvBlock(4*width, 2*width)
self.conv5 = ConvBlock(3*width, width)
self.conv6 = nn.Conv2d(width, n_channel_out, 1)
def forward(self, x):
c1 = self.conv1(x)
x = self.pool1(c1)
c2 = self.conv2(x)
x = self.pool2(c2)
x = self.conv3(x)
x = self.up1(x)
x = torch.cat([x, c2], 1)
x = self.conv4(x)
x = self.up2(x)
x = torch.cat([x, c1], 1)
x = self.conv5(x)
x = self.conv6(x)
return x
model = BabyUnet()
loss_function = MSELoss()
optimizer = Adam(model.parameters(), lr=0.001)
data_loader = DataLoader(noisy_mnist_train, batch_size=32, shuffle=True)
pbar = tqdm(data_loader)
for i, batch in enumerate(pbar):
noisy_images, clean_images = batch
net_input, mask = masker.mask(noisy_images, i)
net_output = model(net_input)
loss = loss_function(net_output*mask, noisy_images*mask)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_description("Iter:{},loss:{}".format(i,loss.item()))
# if i % 10 == 0:
# print("Loss (", i, "): \t", round(loss.item(), 4))
if i == 100:
break
测试训练效果
test_data_loader = DataLoader(noisy_mnist_test,
batch_size=32,
shuffle=False,
num_workers=3)
i, test_batch = next(enumerate(test_data_loader))
noisy, clean = test_batch
simple_output = model(noisy)
invariant_output = masker.infer_full_image(noisy, model)
idx = 3
plot_tensors([clean[idx], noisy[idx], simple_output[idx], invariant_output[idx]],
["Ground Truth", "Noisy Image", "Single Pass Inference", "J-Invariant Inference"])

盲点网络训练后使用不同的输入(加盲点或者不加)得到的效果有些许差别,但是整体的去噪效果还可以。
4. 总结
- 引入J-invariant的概念到去噪工作之中,通过测试对比发现这种方法的自监督比传统方法有更好的效果,可以帮助传统方法寻找最佳的调整参数
- J-invariant的思路可以应用到传统去噪方法中或者先前的无监督、自监督学习工作之中,提高效果。(对比了Noise2Noiser和Noiser2Void方法)
- 和Noise2Void有异曲同工之妙,分析原理都是使用盲点网络的思想对输入数据进行mask,然后使用网络恢复这些盲点位置的信息。所以也存在和盲点网络相同的问题
- 损失了盲点位置的信息
- 盲点网络的假设:噪声是条件不相关的,信号是相关的;对于结构性的噪声的效果会较差。
- 噪声零均值假设等假设限制了该方法应用到实际数据之中。